一、前言
我们将库存快照数据导入ES后发现要分页查询10000条以后的记录会报错,这是因为ES通过index.max_result_window这个参数控制能够获取数据总数from+size最大值,默认限制是10000条,因为ES考虑到数据要从其它节点上报到协调节点如果搜索请求的数据越多,会导致ES协调节点占用的堆内存和搜索排序时间越大,但是我们又有这样的需求,虽然页面展示不需要翻到10000条记录后,但在导出XLS是需要将20万条数据一次性导出,本文介绍如何实现。
二、问题重现
1、创建映射

2、构造5万条数据导入ES
搭建SpringBoot工程使用ES官方Client构造测试数据(注:ES的Client实在是太乱了,N套SDK然后不同版本差别又很大,真是折腾)。
配置依赖包

创建客户端连接

注:因为ES的连接其实走HTTP的,但是采用的是持久连接还是多路复用HTTP2是由SDK底层实现(待研究),自己应该是不用管理连接池。
批量写入数据
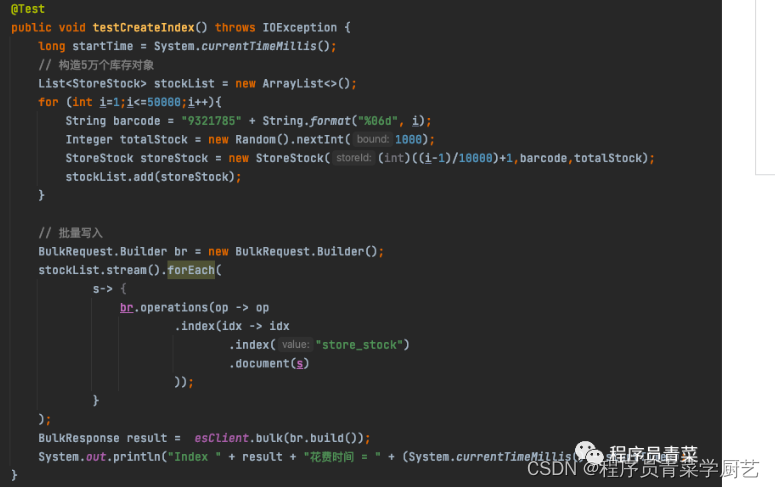
注:使用fluent DSL批量导入5万条数据,20秒就完成导入,一般批量写入每次1000~5000条记录,数据量大小在5M~15M之间效率会比较高。
3、查询
get /store_stock/_search

注:返回文档数量为10000,而不是50000
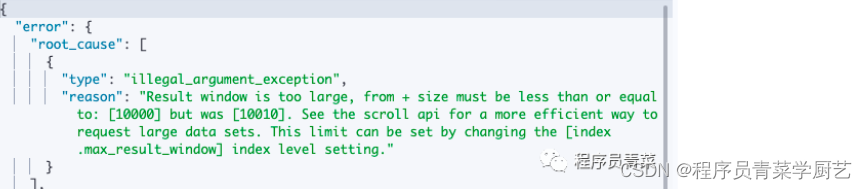
分页查询10000后的10条记录

报错信息如下,告诉你只能查10000条数据.
用ESClient查询
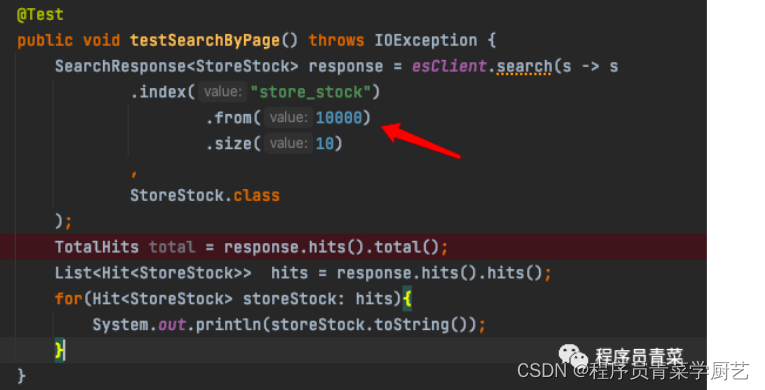
同样会报错如下
三、解决方案
1、调大index.max_result_window

然后再次查询

返回结果如下:发现已经可以查出10001~10010这些数据,但返回的总数total值还是10000.使用ESClient也同样能够查出数据。但这种方式特别占用内存.

2、ES深度分页
深度分页原理如下图所示,图片来源于网络。
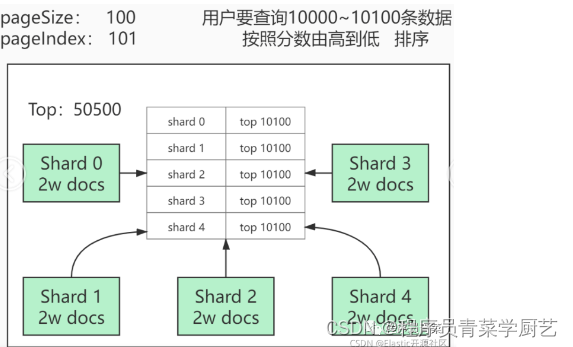
注:因为写入分片的数据是无序的,但你分页查询结果是要排序的,这个时候在每个每片要查出的数量都是你需要查出的数据总数,然后所有分片整合在一起进行排序,再取出你所需要的数量。
这里产生二次排序,如果查询的数据越靠后,越容易造成OOM,这也是ES为了避免产生频繁FGC,默认设置max_result_window的值为10000的原因。
另外像Google、Baidu等分页查询在产品功能上都做成不能跳到某一页来做限制。它们分页的组件如下,从产品层面避免了深度分页。

3、滚动查询
但我们在导出或者做数据分析时总是需要查询10000条以后的数据,那怎么办,这里可以使用滚动查询 Scroll(类似于数据库的游标)。
使用方法
1、首次查询加上scroll参数,5m表示返回的scrollId 在5分钟内有效

返回的数据:查询出了10000条数据,total的数量显示50000,并且返回了一个_scroll_id
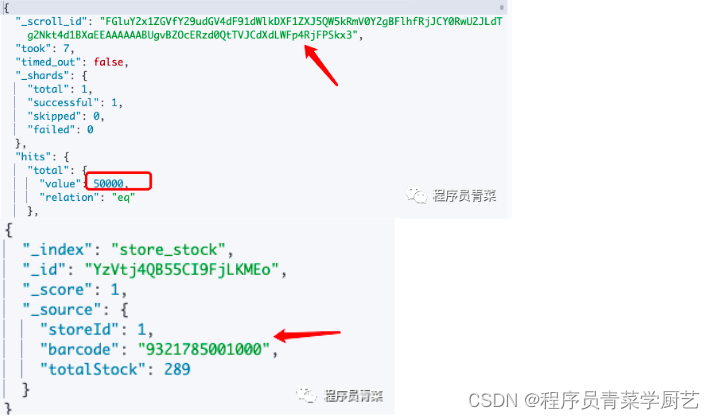
然后用scroll_id往后查

返回结果:可以继续往后查

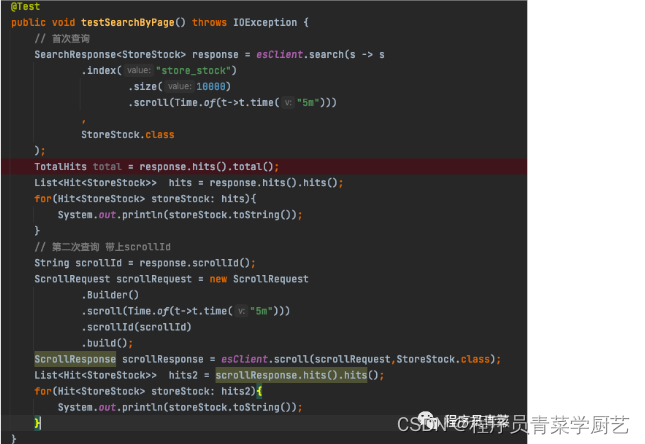
ESClient代码如下
4、Scroll查询原理
ES搜索分两个阶段:Query阶段和Fetch阶段
Query阶段:比较轻量级,通过查询倒排索引获取满足查询结果的文档ID列表。
Fetch阶段:需要将每个shard的结果取回,在协调结点进行全局排序。
Scroll查询,先做轻量级的Query阶段以后,免去了繁重的全局排序过程。它只是将查询结果集,也就是doc id列表保留在一个上下文里, 之后每次分批取回的时候,只需根据设置的size,在每个shard内部按照一定顺序(默认doc_id续), 取回这个size数量的文档即可。(注:没搞懂,需要再深入分析一下)。