一、分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用 () 表示的就是要提取的分组(Group)
例如:
^(\d{3})-(\d{3,8})$ 分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
print(m)
print(m.group(0))
print(m.group(1))
print(m.group(2))

如果正则表达式中定义了组,就可以在 Match 对象上用 group() 方法提取出子串来。
注意到 group(0) 永远是原始字符串, group(1) 、 group(2) ......表示第 1、2、......个子串。提取子串非常有用。
二、贪婪匹配
需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。
举例如下,匹配出数字后面的 0 :
import re s = re.match(r'^(\d+)(0*)$', '102300') print(s.groups())
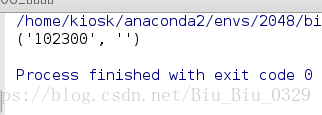
由于 \d+ 采用贪婪匹配,直接把后面的 0 全部匹配了,结果 0* 只能匹配空字符串了。
必须让 \d+ 采用非贪婪匹配(也就是尽可能少匹配),才能把后面的 0 匹配出来,加个 ? 就可以让 \d+ 采用非贪婪匹配;
例如:
import re s = re.match(r'^(\d+?)(0*)$', '102300') print(s.groups())
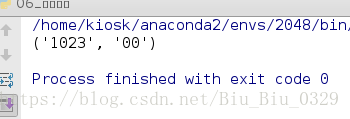
三、切分字符串
用正则表达式切分字符串比用固定的字符更灵活,请看正常的切分代码:
print('a b c'.split(' '))
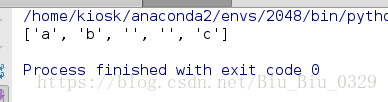
无法识别连续的空格,用正则表达式试试:
import re print(re.split(r'\s+','a b c'))

无论多少个空格都可以正常分割。加入 , 试试:
import re print(re.split(r'[\s\,]+','a , , b , c'))

再加入 ; 试试:
import re print(re.split(r'[\s\,\;]+','a; ,b;,c'))

如果用户输入了一组标签,下次记得用正则表达式来把不规范的输入转化成正确的数组。
四、应用案例--在贴吧上爬取邮箱
1、使用协程from concurrent.futures import ThreadPoolExecutor
from urllib import request
import re
from gevent import monkey
import threading
# 打补丁, 自动修改协程中需要的一些标准库;
monkey.patch_socket()
import gevent
from mytime import timeit
url = 'http://tieba.baidu.com/p/2314539885'
EmailLi = []
def get_content(url):
"""获取网页源代码"""
# 1. 下载网页源代码到本地, 获取帖子总页数;
# urlObj = request.urlopen(url, timeout=60)
# content = urlObj.read().decode('utf-8')
with request.urlopen(url, timeout=60) as urlObj:
content = urlObj.read().decode('utf-8')
return content
def get_page(url):
content = get_content(url)
# <a href="/p/2314539885?pn=31">尾页</a>
pattern = r'<a href="/p/.*pn=(\d+)">尾页</a>'
page = re.findall(pattern, content)[0]
return int(page)
def get_all_url(url, page):
"""生成所有页的帖子url地址"""
url_li = []
# page: 31 0,1,2,3,4.....30
for i in range(page):
new_url = url + '?pn=%d' %(i+1)
url_li.append(new_url)
return url_li
def get_email(url):
content = get_content(url)
pattern = r'[a-zA-Z0-9_]+@\w+\.com'
EmailLi.extend(re.findall(pattern, content))
print(re.findall(pattern, content))
# 结论:
# 1. 如果代码是IO密集型, 建议选择多线程;
# 2. 如果是计算密集型, 建议选用多进程;
@timeit
def geventMain():
# url = 'http://tieba.baidu.com/p/2314539885'
page = get_page(url)
url_li = get_all_url(url, page)
gevents = [gevent.spawn(get_email, url) for url in url_li]
gevent.joinall(gevents)
geventMain()
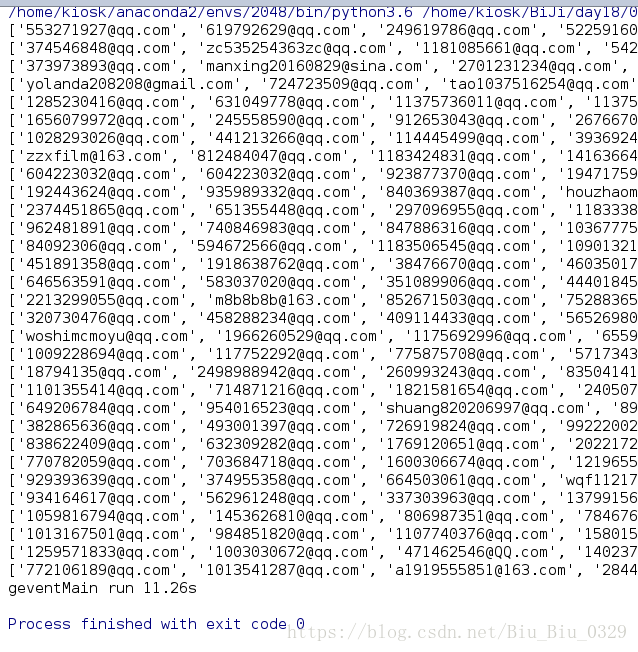
2、一般方式
from urllib import request
import re
url = 'http://tieba.baidu.com/p/2314539885'
#爬取每个页面上的所有内容
def get_content(url):
with request.urlopen(url) as f:
content = f.read().decode('utf-8')
return content
#抓取需要的页面信息,这里要的是页面的总页码
def get_page(url):
content = get_content(url)
# < a href = "/p/2314539885?pn=31" >尾页 < / a >
pattern = r'<a href="/p/.*?pn=(.*)">尾页</a>'
return int(re.findall(pattern, content)[0])
#生成新的每一页的网络地址,等同于重新构造了网址
def create_url(url, page):
url_li = []
for i in range(page):
# print("第%s页" %(i+1))
new_url = url+'?pn=%d' %(i+1)
url_li.append(new_url)
return url_li
#利用正则匹配每一页中合法的邮箱地址
def get_email(url):
content = get_content(url)
pattern = r"[a-zA-Z0-9_]+@\w+\.com"
return re.findall(pattern, content)
page = get_page(url)
print("贴吧总共有%d页, 正在爬取中......."%(page))
url_li = create_url(url,page)
for url in url_li:
print(get_email(url))
五、爬取银行信息
要求:我们需要http://www.cbrc.gov.cn/chinese/jrjg/index.html 网站的所有银行的信息 ,并且保存在文件中;
注意:下面的爬取也许会被封掉你的IP,所以你需要检查好你的代码进行尽量少的爬取动作,其次可以把它的被荣爬取并且现保存在你的文件中,方便我们后续的操作;
下面是我们爬取网站内容的代码:
def get_content(url):
# 1. ???????;
headers = {'User-agent': 'FireFox/12.0'}
req = request.Request(url, headers=headers)
with urlopen(req) as urlObj:
content = urlObj.read().decode('utf-8')
with open('bank.txt', 'w') as f:
f.write(content)
print('write success')
get_content(url)
下面的是我们通过正则过滤网页中我们需要的信息:
import re
url = 'http://www.cbrc.gov.cn/chinese/jrjg/index.html'
def get_file_content(filName):
with open(filName) as f:
content = f.read().replace('\t', '')
return content
# print(get_file_content('bank.txt'))
def get_bank_info(content):
#<a href="http://www.homecreditcfc.cn/zh/DefaultTianJin.aspx" target="_blank" style="color:#08619D">xxxx</a>
# pattern = r'<a href="(http://www(?:\.\w*){1,3})>\s*(.*)\s*</a>"'
pattern = r'<a href="(http://www.*)" target="_blank" style="color:#08619D">\s*(.*)\s*'
c = re.findall(pattern,content)
return c
# a = get_bank_info(get_file_content('bank.txt'))
# print(len(a))
# for i in a:
# print(i)
def write_to_file(filename, bank_li):
with open(filename, 'w') as f:
f.write("银行名称\tURL\n")
for url,name in bank_li:
f.write("%s\t%s\n" %(name.strip(), url))
print("写入成功!")
bank_li = get_bank_info(get_file_content('bank.txt'))
for ur, name in bank_li:
print(ur, '\t', name)
write_to_file('bank1.txt', bank_li)

