案例背景
上了两个月班的社畜博主最近终于有空来总结一下最近写的代码了。
因为上班都是文职工作,天天不是word就是excel就是PPT和pdf....这和什么机器学习还有数据科学不一样,任务更多的是处理实在的文字和表格等格式,按照领导要求来完成,数据什么都是次要的,主要是格式要求,数据运算最多都是加减乘除,都很简单。但是怎么呈现给领导看就会让代码过程变得复杂。
本次就是对一些固定资产进行一个分类汇总,比如领导想看我们固定资产里面有什么呀,有几台车,几个房屋,几台电脑,他们原值都是多少钱,折旧了多少钱....需要每一类的汇总,然后汇总了还不够,他还想看看每一类的明细.....总之就是很麻烦,如果没有python的话,那就是excel筛选,然后对每一类都进行复制,最后一行写一个sum()函数....再把所有的sum()行复制到一起,来一个整体的sum......
这种重复性的工作还是给代码来吧,所实话,类别多的情况下,写代码的时间都比复制粘贴的时间快,而且代码还能一直用,下次再来个什么别的东西进行分类汇总也是很方便的.....
明确目标
上面也说了,就是格式要求麻烦,对这样一个资产的表进行分类统计:
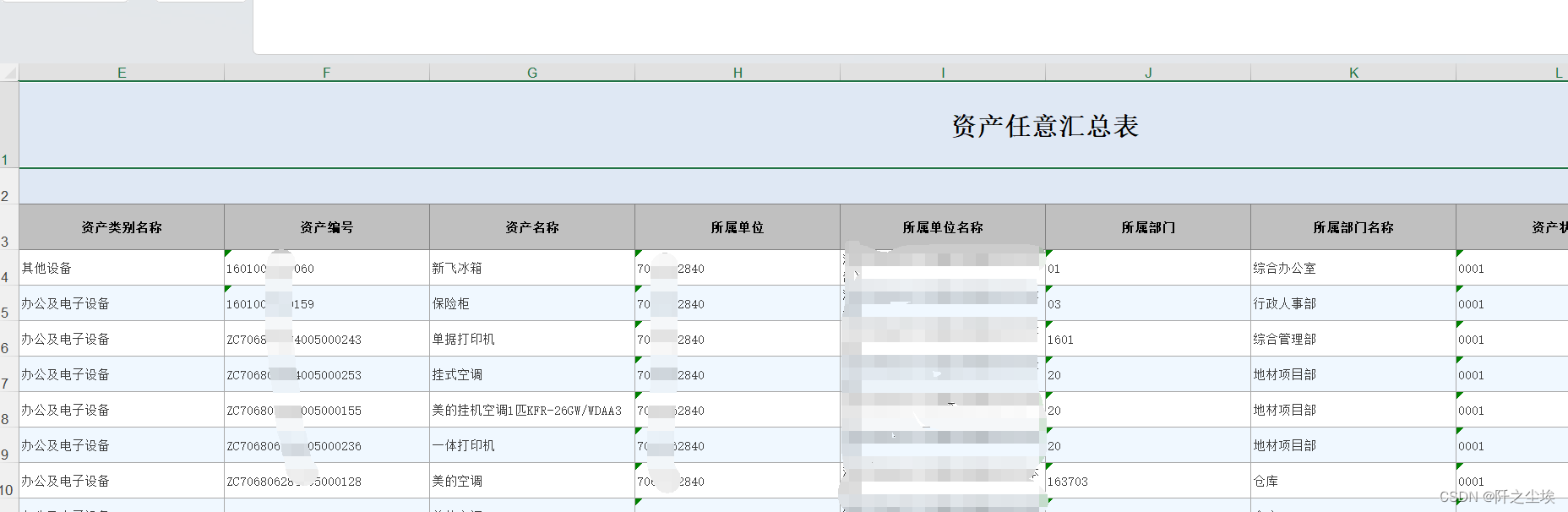
我们需要对每种类别的资产都分开写入不同的sheet里面,后面都加上一行汇总项,然后还需要做一个总的汇总表。
(有些位置和数值都打了马赛克.....当然是怕信息泄露...)
代码实现
先导入包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号
import xlrd,openpyxl还是数据分析四件套,但可能这个案例不需要,,,另外我现在习惯导入xlrd,openpyxl这两个处理excel表的包,虽然这个案例没用到,后面会用的。这个案例只依靠pandas就行。
读取数据,可以看到上面的表前两行没什么用,就跳过读取,然后把资产类别这一列变为字符串型进行读取,因为它有‘03’这种读取的话会默认变成数值型就变成‘3’了.....还进行了筛选,在用的资产都拿出来,报废的资产就不做统计了。
df=pd.read_excel('资产任意汇总表.xls',converters={'资产类别': str},skiprows=2)
df=df.iloc[:,2:].query("资产状态名称=='在用'").reset_index(drop=True)
df.head(2)
可以看到数据大概有哪些变量。我们主要是对资产类别名称这一列进行分类。然后再统计汇总,
我这里还做了一点小处理,主要是有的资产类别不对,需要进行替换映射一下,采用编号相同的情况下进行替换
df_change=pd.read_excel('资产变动台账.xls',converters={'资产编号': str},skiprows=2)
df_change[['新类别编号', '新类别名称']] = df_change['资产类别-变后值'].str.split('_', expand=True)
for num in df_change['资产编号'].unique():
df.loc[df['资产编号'] == num, '资产类别'] = df_change.loc[df_change['资产编号'] == num, '新类别编号'].to_numpy()[0]
df.loc[df['资产编号'] == num, '资产类别名称'] = df_change.loc[df_change['资产编号'] == num, '新类别名称'].to_numpy()[0]查看资产类别数量统计:
df['资产类别'].value_counts()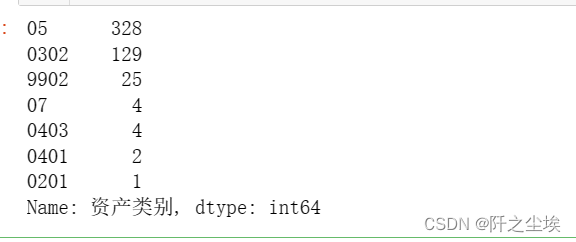
这些事类别的代号,然后写个字典,让代号和名称一一对应:
asset_category={'01': '公路及构筑物', '02': '房屋及建筑物', '03': '机械设备', '04': '运输设备', '05': '办公及电子设备', '06': '仪器及实验设备', '07': '安全设施', '08': '收费设施', '09': '通信监控设施', '10': '融资租赁及改良支出', '98': '土地', '99': '其他','0201': '办公用房','0202': '职工用房','0203': '仓库','0204': '客运站房屋','0205': '厂房','0206': '服务区','0207': '站所用房','02101': '非生产用房','02102': '建筑物及附属设施','02103': '房屋建筑物','0299': '其他','0301': '施工机械','0302': '生产及动力设备','0399': '其他','0401': '生产车辆','0402': '营运车辆','0403': '办公用车','0499': '其他','9901':'广告牌','9902':'其他设备'}
(df['资产类别'].map(asset_category)==df['资产类别名称']).all()
这里的true表示数据里面的代号和名称都是一致的。
资产分类计算导出
开始正式的分类汇总的代码:
查看类型:
df['资产类别名称'].unique()
直接计算汇总表,并且在最后一行加上汇总项:
df_sums=df.groupby('资产类别名称').sum(numeric_only=True).T.assign(汇总=lambda x:x.sum(1)).T
df_sums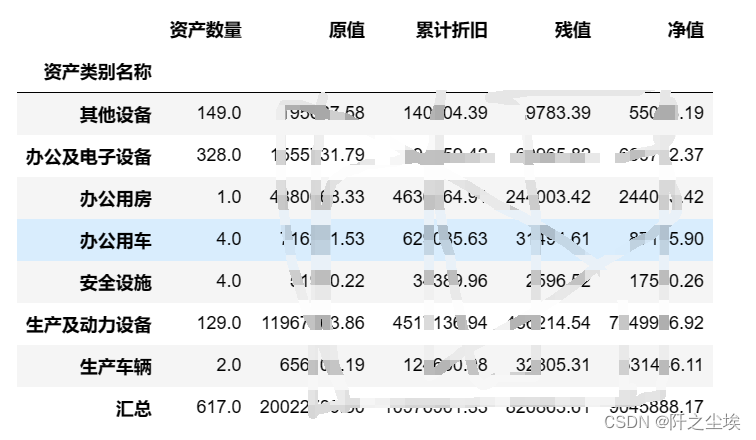
可以看到最后一行是汇总行,这是只保留的数值型数据的汇总,文字型数据都不见了。
如果需要明细,这种只保留数值是不行的。
我们自定义一个函数,可以对数据框加一行汇总,数值型数据就求和,字符串就为空:
def add_summary_row(df):
numeric_df = df.select_dtypes(include=['number'])
summary = numeric_df.sum()
for col in df.columns.difference(numeric_df.columns):
summary[col] = None
result_df = pd.concat([df, pd.DataFrame(summary).T])
result_df.index = list(range(len(df.index))) + ['汇总']
return result_df然后把每一类资产都进行这个函数的处理,写入excel不同的sheet里面,再加上一个汇总项表:
sheets = {'办公用房': '房屋建筑物','办公及电子设备': '办公及电子设备', '生产及动力设备': '生产及动力设备',
'办公用车': '办公车辆', '生产车辆': '生产车辆', '安全设施': '安全设施', '其他设备': '家具和其他','汇总':'汇总'}
with pd.ExcelWriter('汇总.xlsx') as writer:
for key, value in sheets.items():
df_temp=df[df['资产类别名称'] == key] #取出每一类框
df_temp=add_summary_row(df_temp) #添加汇总项
df_temp.to_excel(writer, sheet_name=f'{value}{len(df_temp)-1:.0f}') #写入sheet,名称+数量
df_sums.index=df_sums.index.map(sheets)
df_sums.to_excel(writer, sheet_name='汇总') #写入汇总表完成!!看看效果:

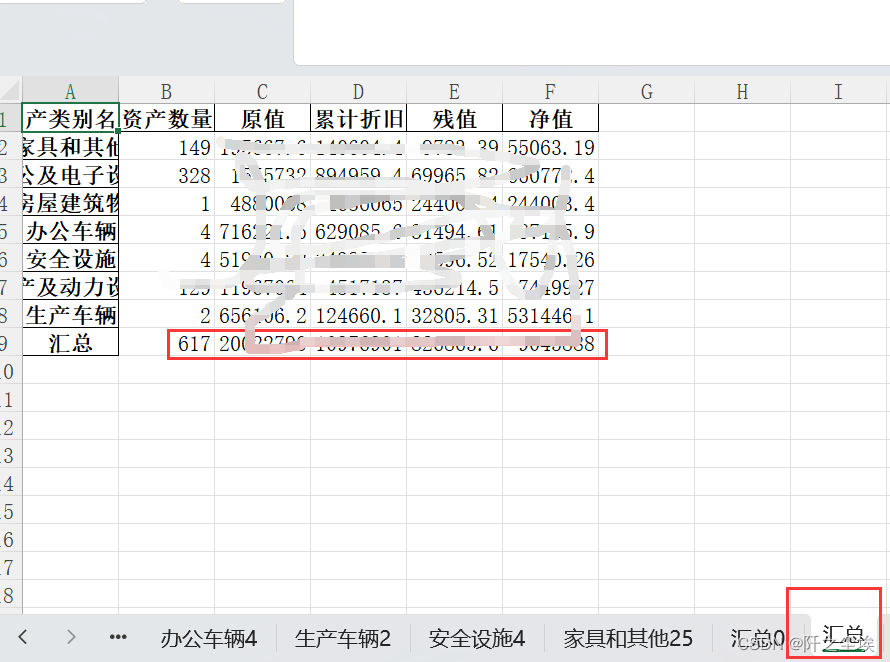
可以看到下面很多sheet,分门别类了,数字是这个类型的资产有多少个。最后都有汇总,还有总汇总表。