内存管理
---
在计算机编程中,内存管理是一项关键任务,用于在程序运行时正确分配和释放内存。一个有效的内存管理系统可以帮助程序提高性能,减少内存泄露和访问错误等问题。
内存管理涉及以下几个方面:
1. 内存分配:为程序中的变量、对象和数据结构分配所需的内存空间。
2. 内存释放:当变量、对象或数据结构不再使用时,将其占用的内存空间释放回操作系统。
3. 内存回收:识别和释放程序中没有被引用的内存块,以便重新分配给其他需要的部分。
4. 内存泄漏:当程序在使用完内存后没有正确释放它,导致内存资源的浪费。
内存管理的方法可以有很多种,包括手动管理和自动管理。手动管理需要程序员显式地跟踪和释放内存。而自动管理则由编程语言或运行时环境提供的垃圾回收机制负责释放不再使用的内存。
在选择适当的内存管理策略时,需要考虑程序的性能要求、内存使用模式和资源限制等因素。
Say Goodbye to OOM Crashes 英文看起来脑壳痛,翻译了一下
还有遇到了实际的问题

---------------------------------------------------------------------
是什么保证了大数据查询任务中的系统稳定性?保证大型数据查询任务的系统稳定性的是有效的内存分配和监控机制。这涉及加速计算、避免内存热点、及时响应内存不足并尽量减少OOM错误。

从数据库用户的角度来看,他们会因为糟糕的内存管理而遭受以下问题:
- OOM错误导致后端进程崩溃。引用我们社区成员的一句话:“嗨,Apache Doris,当你内存不足时慢点或失败一些任务都没关系,但是完全宕机就不酷了。”
- 后端进程占用过多内存空间,但无法找到具体的任务来定位问题或限制单个查询的内存使用。
- 很难为每个查询设置适当的内存大小,所以即使有足够的内存空间,查询也可能会被取消。
- 高并发查询速度明显偏慢,而且很难定位内存热点。
- 在创建HashTable过程中,无法将中间数据刷新到磁盘,因此在两个大型表之间进行的连接查询经常因为OOM而失败。
幸运的是,那些黑暗的日子已经过去了,因为我们从底层改进了内存管理机制。现在准备好,事情将会变得更加高效。
Memory Allocation
内存分配方面,在Apache Doris中,我们有一个独特的内存分配接口:Allocator。它会根据需要进行调整,以保持内存使用的高效和可控。此外,MemTrackers会跟踪已分配或释放的内存大小,并且有三种不同的数据结构负责操作执行中的大内存分配(我们将立即介绍它们)。

内存中的数据结构
由于不同的查询在执行中具有不同的内存热点模式,ApacheDoris提供了三种不同的内存内数据结构:Arena、HashTable和PODArray。他们都在分配者的统治之下。
Apache Doris 是一个 MPP(Massive Parallel Processing,大规模并行处理)架构的快速、稳定、可靠的开源分析型数据库。它的设计旨在解决大数据环境下的分析查询问题。对于你的问题,关于Apache Doris中的内存数据结构,以下是你的问题的一些基本背景信息。
- Arena: Arena 是一种内存分配器,它负责在内存中分配和释放内存块。在 Doris 中,它主要用于存储 HashTable 和 PODArray 的数据。在 Arena 中,内存的管理是非常重要的,因为它需要有效地分配和释放内存,以避免内存泄漏或碎片化。
- HashTable: HashTable 是一种数据结构,它允许我们通过键(key)快速查找值(value)。在 Doris 中,HashTable 主要用于存储和检索查询结果。HashTable 的设计需要考虑如何有效地使用内存,同时还需要考虑到查询性能和准确性。
- PODArray: PODArray(Plain Old Data Array)是一个简单的、连续的、固定长度的数组结构。在 Doris 中,PODArray 主要用于存储查询结果,特别是在处理复杂查询时。PODArray 的设计旨在提供高效的内存使用和快速的查询性能。
所有这些数据结构都由 Allocator 管理,Allocator 负责分配和管理内存资源。在 Doris 中,Allocator 的设计需要考虑到如何有效地满足各种查询的需求,同时还需要管理内存的使用,避免内存泄漏和碎片化。
这些数据结构和内存管理策略的设计都是为了在处理大规模数据时提供高效和稳定的性能。

- Arena
Arena是一个内存池,维护一个块列表,这些块在从Allocator请求时进行分配。这些块支持内存对齐,它们在整个Arena的寿命期间存在,并在销毁时(通常在查询完成时)被释放。这些块主要在Shuffle期间用于存储序列化或反序列化的数据,或在HashTables中用于存储序列化的Keys。
初始的块大小为4096字节。如果当前块小于请求的内存大小,将会添加一个新的块到列表中。如果当前块小于128M,新块的大小将会翻倍;如果它大于128M,新块的大小最多只会比所需的大128M。较小的旧块将不会被分配给新的请求。有一个游标标记已分配块和未分配块的分界线。
- HashTable
HashTables适用于Hash连接、聚合、集合操作和窗口函数。PartitionedHashTable结构支持最多16个子HashTables,还支持HashTables的并行合并,每个子HashJoin可以独立扩展。这样可以减少整体内存使用,并降低扩展引起的延迟。
如果当前的HashTable小于8M,将以4的因子进行扩展;
如果它大于8M,将以2的因子进行扩展;
如果它小于2G,当它满50%时将会扩展;
如果它大于2G,当它满75%时将会扩展。
新创建的HashTables将根据它将要拥有的数据量进行预扩展。我们还为不同的情况提供不同类型的HashTables。例如,对于聚合,可以应用PHmap。
- PODArray
PODArray,就如其名,是一个POD(Plain Old Data,简单旧式数据)类型的动态数组。它与std::vector的区别在于,PODArray不会初始化元素。它支持内存对齐,并拥有一些与std::vector类似的接口。它是通过2的因子来进行扩展的。在销毁时,它不是对每个元素都调用析构函数,而是释放整个PODArray的内存。PODArray主要用于保存列中的字符串,并且适用于许多函数计算和表达式过滤。
内存接口
作为协调Arena、PODArray和HashTable的唯一接口,Allocator执行大于64M的请求的内存映射(MMAP)分配。小于4K的请求将直接通过malloc/free从系统分配;介于两者之间的请求将由通用缓存的ChunkAllocator加速,这根据我们的基准测试结果带来了10%的性能提升。ChunkAllocator将尝试以无锁的方式从当前核心的FreeList获取一块指定大小的内存块;如果不存在这样的块,它将尝试以基于锁的方式从其他核心获取;如果仍然失败,它将从系统请求指定大小的内存并将其封装到一个块中。
我们在经验丰富之后选择了Jemalloc而不是TCMalloc。在我们的高并发测试中,我们尝试使用TCMalloc,并且注意到CentralFreeList中的Spin Lock占用了总查询时间的40%。禁用“aggressive memory decommit”使事情变得更好,但这带来了更多的内存使用,因此我们不得不使用单独的线程定期回收缓存。另一方面,Jemalloc在高度并发的查询中表现更好、更稳定。在针对其他场景进行微调后,它提供了与TCMalloc相同性能但消耗更少的内存。
内存重用
Apache Doris在执行层广泛执行内存重用。例如,在整个查询执行期间,数据块将被重用。在Shuffle期间,发送端将有两个块并且它们交替工作,一个接收数据而另一个进行RPC传输。在读取一个表时,Doris将重用谓词列,实现循环读取、过滤,将过滤后的数据复制到上层的块中然后进行清除。当将数据摄取到一个聚合键表中时,一旦缓存数据的MemTable达到一定的大小,它将被预先聚合然后更多的数据将被写入。
内存重用也在数据扫描中执行。在扫描开始之前,将为扫描任务分配一定数量的空闲块(取决于扫描器数量和线程数 )。在每个扫描器调度期间,其中一个空闲块将被传递到存储层进行数据读取。在数据读取之后,该块将被放入生产者队列供后续计算中的上层操作符使用。一旦一个上层的操作符从该块复制了计算数据,该块将返回到空闲块中供下一个扫描器调度使用。预分配空闲块的线程也将在数据扫描后负责释放它们,因此不会有多余的开销。空闲块的数量在某种程度上决定了数据扫描的并发性。
内存跟踪
Apache Doris使用MemTrackers来跟踪内存的分配和释放情况,同时分析内存热点。MemTrackers记录每个数据查询、数据摄取、数据压缩任务以及每个全局对象的内存大小,例如Cache和TabletMeta。它同时支持手动计数和MemHook自动跟踪。用户可以在Doris后端的一个Web页面上查看实时的内存使用情况。
MemTrackers的结构
在Apache Doris 1.2.0之前的MemTracker系统是一个层次树结构,包括process_mem_tracker、query_pool_mem_tracker、query_mem_tracker、instance_mem_tracker、ExecNode_mem_tracker等。相邻两层的MemTrackers之间是父子关系,因此子级MemTracker中的任何计算错误都会一路积累并导致更大范围的不可信。

在Apache Doris 1.2.0及更高版本中,我们简化了MemTrackers的结构。MemTrackers仅根据其角色分为两种类型:MemTracker Limiter和其他类型的MemTrackers。MemTracker Limiter监控内存使用情况,每个查询/摄取/压缩任务和全局对象中都是唯一的;其他类型的MemTrackers跟踪查询执行中的内存热点,例如Join/Aggregation/Sort/Window函数中的HashTables和序列化中的中间数据,以了解不同操作符如何使用内存或为数据刷新中的内存控制提供参考。
MemTracker Limiter和其他类型的MemTrackers之间的父子关系仅在快照打印中有所体现。你可以将这种关系视为符号链接。它们不会同时被消耗,并且一个的生命周期不会影响另一个的生命周期。这使得开发人员更容易理解和使用它们。
将MemTrackers(包括MemTracker Limiter和其他类型的MemTrackers)放入一组Maps中。这允许用户打印整体MemTracker类型的快照、查询/加载/压缩任务快照,并找出使用内存最多或内存过度使用的查询/加载。

MemTracker的工作原理
为了计算某个执行过程的内存使用情况,将一个MemTracker添加到当前线程的线程本地堆栈中。通过重新加载Jemalloc或TCMalloc中的malloc/free/realloc,MemHook获取分配或释放的内存的实际大小,并将其记录在当前线程的线程本地堆栈中。当执行完成后,将相关的MemTracker从堆栈中移除。堆栈底部的MemTracker记录整个查询/加载执行过程中的内存使用情况。
接下来让我用简化的查询执行过程来解释一下。
Doris后端节点启动后,所有线程的内存使用情况都记录在进程MemTracker中。
当提交查询时,将在片段执行线程的线程本地存储(TLS)堆栈中添加一个Query MemTracker。
一旦调度ScanNode,将在片段执行线程的TLS堆栈中添加一个ScanNode MemTracker。此后,该线程中分配或释放的任何内存都将记录到Query MemTracker和ScanNode MemTracker中。
调度Scanner后,Scanner线程的TLS堆栈中将添加一个Query MemTracker和一个Scanner MemTracker。
扫描完成后,Scanner线程TLS堆栈中的所有MemTrackers将被移除。当ScanNode调度完成后,从片段执行线程TLS堆栈中移除ScanNode MemTracker。同样地,当调度聚合节点时,将在片段执行线程TLS堆栈中添加一个AggregationNode MemTracker,并在调度完成后移除它。
如果查询已完成,从片段执行线程TLS堆栈中移除Query MemTracker。此时,此堆栈应该为空。然后,您可以从查询配置文件中查看整个查询执行过程中以及各个阶段(扫描、聚合等)的峰值内存使用情况。

使用MemTracker的方法
Doris后端网页展示了实时内存使用情况,这些使用情况被划分为四种类型:查询/加载/压缩/全局。展示内容为当前内存消耗情况和峰值消耗情况。
 全局类型包括缓存和TabletMeta的MemTrackers。
全局类型包括缓存和TabletMeta的MemTrackers。

从查询类型中,您可以观察当前查询及所关联操作(通过标签可以看出关联关系)的当前内存消耗和峰值内存消耗情况。要查看历史查询的内存统计信息,您可以通过DorisFrontend的审计日志或Backend的INFO日志进行检查。

内存限制
在Doris后端广泛实施内存跟踪之后,我们离消除OOM这一导致后端停机和大规模查询失败的原因又近了一步。下一步是优化查询和进程的内存限制,以控制内存使用情况。
查询的内存限制
用户可以为每个查询设置内存限制。如果执行过程中该限制被超过,查询将被取消。但从1.2版本开始,我们已经允许内存超配(Memory Overcommit),这是一种更灵活的内存限制控制。如果有足够的内存资源,查询可以消耗比限制更多的内存而不会被取消,因此用户不必过多关注内存使用情况;如果没有,查询将等待新的内存空间被分配;只有当新释放的内存不足以供查询使用时,查询才会被取消。
而在Apache Doris 2.0中,我们已经实现了查询的异常安全性。这意味着任何内存分配不足将立即导致查询被取消,从而省去了后续步骤中检查“取消”状态的麻烦。
进程的内存限制
Doris后端会定期从系统中检索进程的物理内存和当前可用内存大小。同时,它收集所有查询/加载/压缩任务的MemTracker快照。如果后端进程超过了其内存限制或内存不足,Doris将通过清除缓存和取消一些查询或数据摄取任务来释放一些内存空间。这些将由单独的GC线程定期执行。
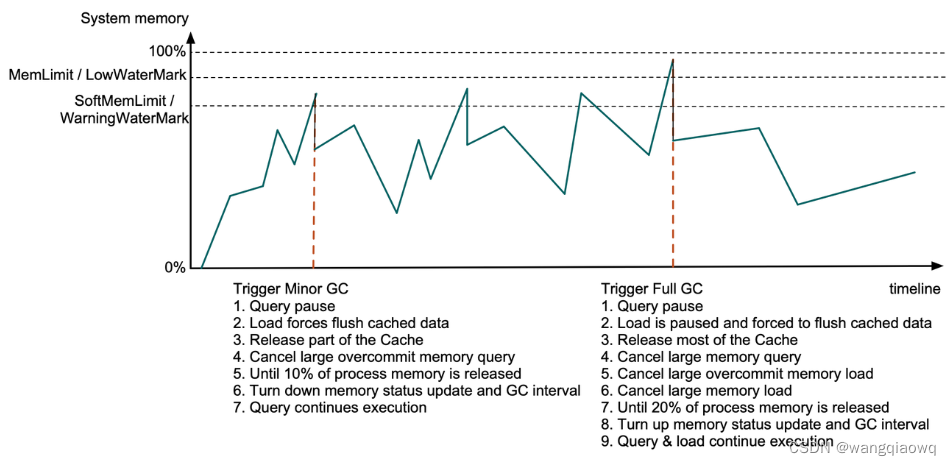
如果进程消耗的内存超过了软内存限制(默认情况下为系统内存的81%),或者可用系统内存下降到警告水位线(小于3.2GB),将触发小垃圾回收(Minor GC)。此时,查询执行将在内存分配步骤暂停,数据摄取任务中的缓存数据将被强制清空,部分数据页缓存和过期的段缓存将被释放。如果新释放的内存不足以覆盖进程内存的10%,并且已启用内存超配,Doris将开始取消最大的“超配者”查询,直到达到10%的目标或所有查询都被取消。然后,Doris将缩短系统内存检查间隔和GC间隔。在有更多可用内存后,查询将继续。
如果进程消耗的内存超过了硬内存限制(默认情况下为系统内存的90%),或者可用系统内存下降到低水位线(小于1.6GB),将触发全面垃圾回收(Full GC)。此时,数据摄取任务将停止,所有数据页缓存和大多数其他缓存将被释放。如果经过所有这些步骤后,新释放的内存仍不足以覆盖进程内存的20%,Doris将查看所有MemTrackers并找到最耗费内存的查询和摄取任务,并逐个取消它们。只有当达到20%的目标后,系统内存检查间隔和GC间隔才会延长,查询和摄取任务才会继续。(一次垃圾回收操作通常需要数百到数十毫秒。)
影响与成果
在进行了内存分配、内存跟踪和内存限制的优化之后,我们显著提高了Apache Doris作为实时分析型数据仓库平台的稳定性和高并发性能。现在,后端出现OOM(内存不足)崩溃的情况已经很少见了。即使出现OOM,用户也可以根据日志定位问题的根源并进行修复。此外,由于查询和数据摄取的内存限制更加灵活,所以在内存空间充足的情况下,用户不必花费额外的精力来处理内存问题。
在下一个阶段,我们计划确保在内存超配情况下查询的完成,这意味着更少的查询将因为内存不足而被取消。我们将这个目标细化为具体的工作方向,包括异常安全性、资源组之间的内存隔离和中途数据的刷新机制。如果你想与我们的开发人员进行交流,可以在这些方面寻找我们的身影。