目录
开发环境
作者:嘟粥yyds
时间:2023年6月21日
集成开发工具:PyCharm Professional 2021.1
集成开发环境:Python 3.10.6
第三方库:tensorflow-gpu 2.10.0、numpy、matplotlib、opencv-python 4.7.0.72
引言
MNIST 数据集介绍


全连接神经网络详解
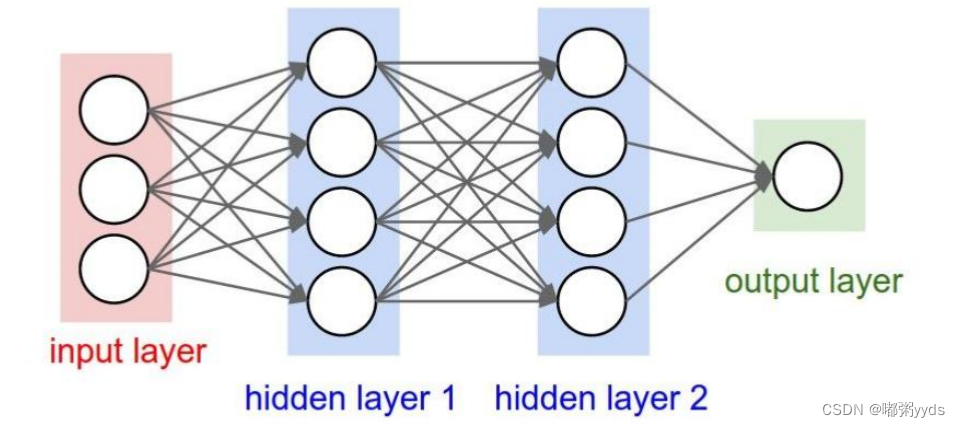
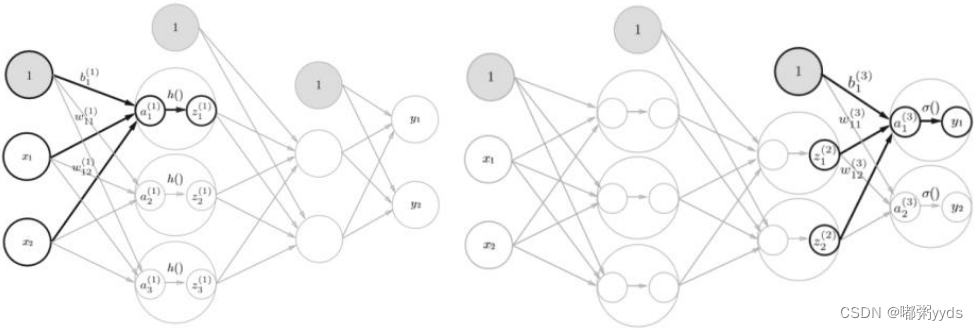
代码实现
import tensorflow as tf
from tensorflow.keras import layers, losses, optimizers
import cv2
import numpy as np
import os
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.use('TKAgg')
save_dir = 'save_model/mnist_classifier_model'
if not os.path.exists(save_dir):
gpus = tf.config.experimental.list_physical_devices("GPU")
if gpus:
try:
# 设置GPU显存占用为按需分配,增长式
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
print(e)
# 数据加载和预处理
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
batch_size = 128
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(batch_size)
test_dataset = test_dataset.batch(batch_size)
# 构建模型
class MNISTClassifier(tf.keras.Model):
def __init__(self):
super(MNISTClassifier, self).__init__()
self.flatten = layers.Flatten()
self.fc1 = layers.Dense(256, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.001))
self.dropout = layers.Dropout(0.2)
self.fc2 = layers.Dense(128, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.001))
self.output_layer = layers.Dense(10)
def call(self, inputs, training=None):
x = self.flatten(inputs)
x = self.fc1(x)
x = self.dropout(x, training=training)
x = self.fc2(x)
x = self.output_layer(x)
return x
model = MNISTClassifier()
# 定义优化器和损失函数
optimizer = optimizers.Adam(learning_rate=0.001)
loss_fn = losses.SparseCategoricalCrossentropy(from_logits=True)
# 定义评估指标
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
# 定义TensorBoard回调函数
log_dir = './MNIST_Classifier_logs'
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# build一次网络模型,输入形状为(28, 28)
model.build(input_shape=(batch_size, 28, 28))
# 查看模型结构
model.summary()
# 编译模型
model.compile(optimizer=optimizer, loss=loss_fn, metrics=[train_accuracy, test_accuracy])
# 开始训练
epochs = 10
model.fit(train_dataset, epochs=epochs, validation_data=test_dataset, callbacks=[tensorboard_callback])
# 保存模型为TensorFlow SavedModel格式
model.save('save_model/mnist_classifier_model')
print("模型保存成功")
模型讲解
- 输入的手写数字图像经过展平层,从二维形式转换为一维向量。
- 一维向量作为输入进入第一个全连接层(fc1),通过权重和偏置进行线性变换,并通过ReLU激活函数进行非线性处理。
- 经过第一个全连接层后,得到一个具有128个元素的向量。
- 第一个全连接层的输出再传递给第二个全连接层(fc2),进行线性变换但没有激活函数。
- 最终的输出是一个具有10个元素的向量,代表了输入图像属于每个数字类别的概率。
本文所有的评测指标的可视化均在TensorBoard中完成。
图 5: 模型的权重和偏差直方图。
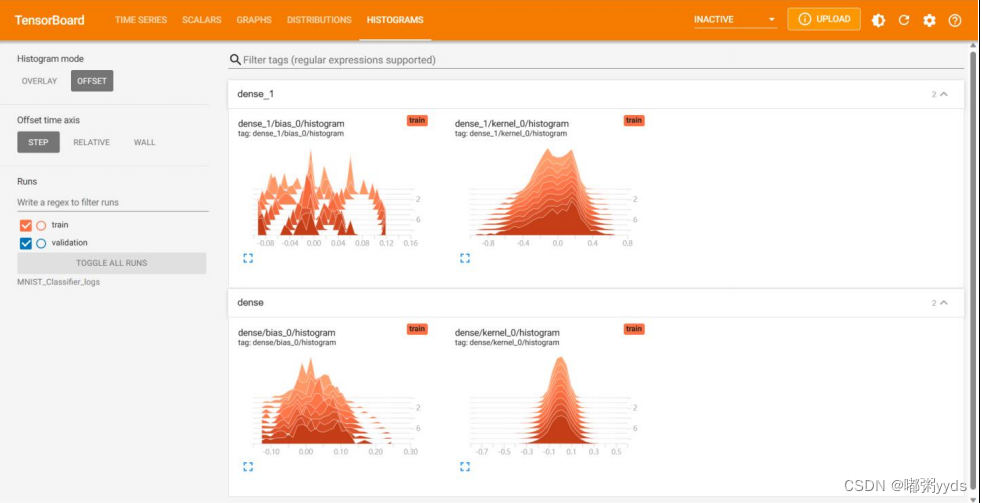 图 6: 模型在训练集和测试集上的训练准确率。
图 6: 模型在训练集和测试集上的训练准确率。
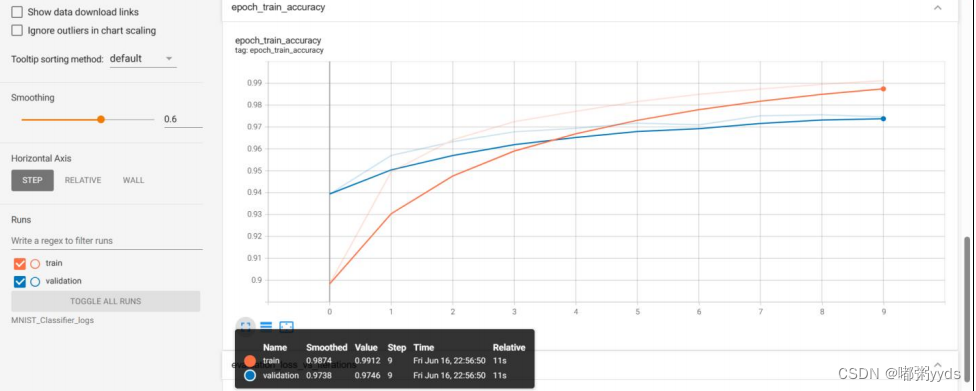
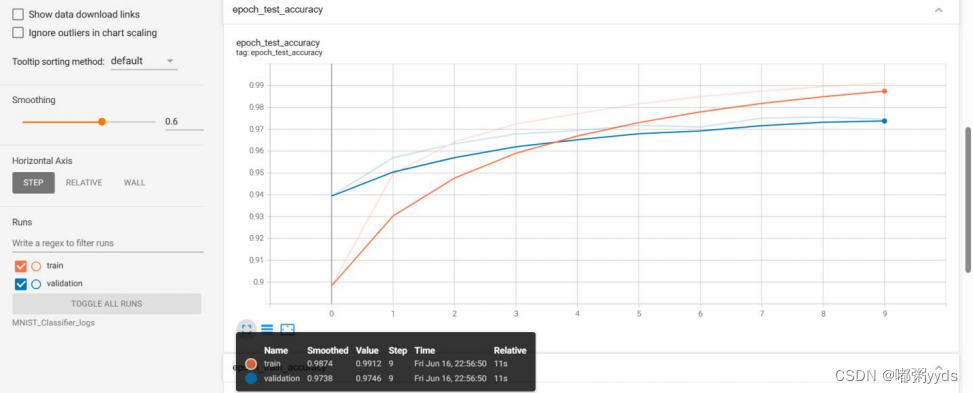 图7 :模型结构图
图7 :模型结构图
 卷积神经网络
卷积神经网络
-
卷积层(Convolutional Layer):卷积层是CNN的核心组成部分。它使用卷积核(滤波器)对输入 图像进行卷积操作,提取不同位置的特征。卷积层可以通过设置多个卷积核来提取多个不同的特征图。 卷积操作可以有效地捕捉局部特征,同时减少模型参数。
-
池化层 (Pooling Layer):池化层用于降低特征图的空间维度,减少计算量。常见的池化操作有最 大池化 (Max Pooling) 和平均池化 (Average Pooling) 。池化层通过对特征图进行下采样,保留主要特征并减少噪声干扰。
-
激活层 (Activation Layer):激活层引入非线性变换,增加模型的表达能力。常用的激活函数有 ReLU(Rectified Linear Unit) 、 Sigmoid 和 Tanh 等。
图8: 常见卷积核及其效果。

- 局部感知:CNN 通过卷积操作来实现局部感知,即将卷积核(也称为滤波器)应用于输入数据的局部区域,从而提取特征。卷积核的大小通常小于输入数据的尺寸,因此它可以在不同位置进行滑动, 并对每个位置进行局部特征提取。通过卷积操作,CNN 能够捕捉到图像中的边缘、纹理等局部特征。
- 参数共享:CNN 利用参数共享来减少模型的参数数量。在卷积层中,卷积核的参数被共享使用, 即同一卷积核在不同位置的应用使用相同的参数。这样做的好处是减少了需要训练的参数数量,提高了模型的泛化能力。参数共享还使得 CNN 对平移、旋转和缩放等图像变化具有一定的不变性。

图10:原LeNet-5模型结构。 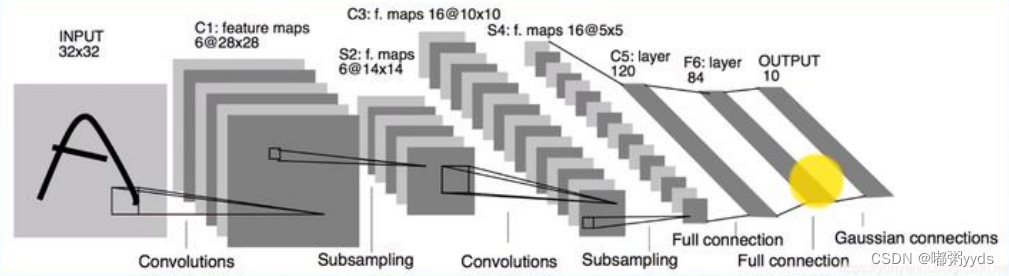
而本文实现的LeNet-5模型在原LeNet-5的基础上进行了些许调整,使得它更容易在现代深度学习框架上实现。首先我们将输入X的形状由32x32调整为28 x 28,然后将2个下采样层实现为最大池化层(用于降低特征图的高、宽),最后利用全连接层替换掉Gaussian Connections层。
图11:针对MNIST数据集调整后LeNet-5模型结构。

代码实现
import tensorflow as tf
import tensorflow.keras
from tensorflow.keras import layers, Sequential, losses, datasets, losses, optimizers
import cv2
import numpy as np
import os
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.use('TKAgg')
if not os.path.exists('save_model/mnist_LeNet-5_model'):
gpus = tf.config.experimental.list_physical_devices("GPU")
if gpus:
try:
# 设置GPU显存占用为按需分配,增长式
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
print(e)
# 数据预处理
def preprocess(x, y):
x = tf.expand_dims(x, axis=-1) # 添加通道维度
x = 2 * tf.cast(x, dtype=tf.float32) / 255. - 1
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
# 训练集 验证集
(x, y), (x_val, y_val) = tf.keras.datasets.mnist.load_data()
x_train, x_test = tf.split(x, num_or_size_splits=[45000, 15000], axis=0)
y_train, y_test = tf.split(y, num_or_size_splits=[45000, 15000], axis=0)
print(
f"datasets:\nx_train:{x_train.shape} x_test:{x_test.shape} x_val:{x_val.shape}\ny_train:{y_train.shape} y_test:{y_test.shape} y_val:{y_val.shape}")
# 训练数据集
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_db = train_db.map(preprocess).shuffle(45000).batch(128)
# 验证数据集
ds_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
ds_val = ds_val.map(preprocess).batch(128)
# 测试数据集
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.map(preprocess).batch(128)
# 创建TensorBorad环境
log_dir = './MNIST_LeNet-5_logs'
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
network = Sequential([
layers.Conv2D(6, kernel_size=3, strides=1), # 第一个卷积层,6个 3x3 卷积核
layers.MaxPooling2D(pool_size=2, strides=2), # 高宽各减半的池化层
layers.ReLU(), # 激活函数
layers.Conv2D(16, kernel_size=3, strides=1), # 第二个卷积层,16个 3x3 卷积核
layers.MaxPooling2D(pool_size=3, strides=1), # 高宽各减半的池化层
layers.ReLU(), # 激活函数
layers.Flatten(), # 打平层,方便全连接层处理
# 全连接层
layers.Dense(120, activation='relu'),
layers.Dense(84, activation='relu'),
layers.Dense(10)
])
# 创建损失函数的类,在实际计算时直接调用类实例即可
criteon = losses.CategoricalCrossentropy(from_logits=True)
optimizer = tf.keras.optimizers.RMSprop(0.01)
# build一次网络模型,给输入X的形状,其中128为随意给的batch_size
network.build(input_shape=(128, 28, 28, 1))
network.summary()
# 编译模型
network.compile(optimizer=optimizer, loss=criteon, metrics=['accuracy'])
# 开始训练
epochs = 10
network.fit(train_db, epochs=epochs, validation_data=ds_val, callbacks=[tensorboard_callback])
# 保存模型为TensorFlow SavedModel格式
network.save('save_model/mnist_LeNet-5_model')
print("模型保存成功")
模型讲解
- 卷积层:使用`Conv2D`层进行卷积操作。第一个卷积层有6个3x3大小的卷积核,第二个卷积层有16个3x3大小的卷积核。这些卷积核将提取输入图像的不同特征。
- 池化层:使用`MaxPooling2D`层进行最大池化操作。第一个池化层的池化窗口大小为2x2,步幅为2,将图像的高度和宽度各减半。第二个池化层的池化窗口大小为3x3,步幅为1。
- ReLU激活层:使用`ReLU`层作为激活函数,对卷积层的输出进行非线性映射,增加网络的表达能力。
- 打平层:使用`Flatten`层将多维的输入数据转换为一维,以便后续的全连接层处理。
- 全连接层:使用`Dense`层进行全连接操作。第一个全连接层有120个神经元,第二个全连接层有84个神经元。最后一层是一个有10个神经元的全连接层,用于输出对应10个类别的概率分布。
图12:模型的训练准确率和损失值。
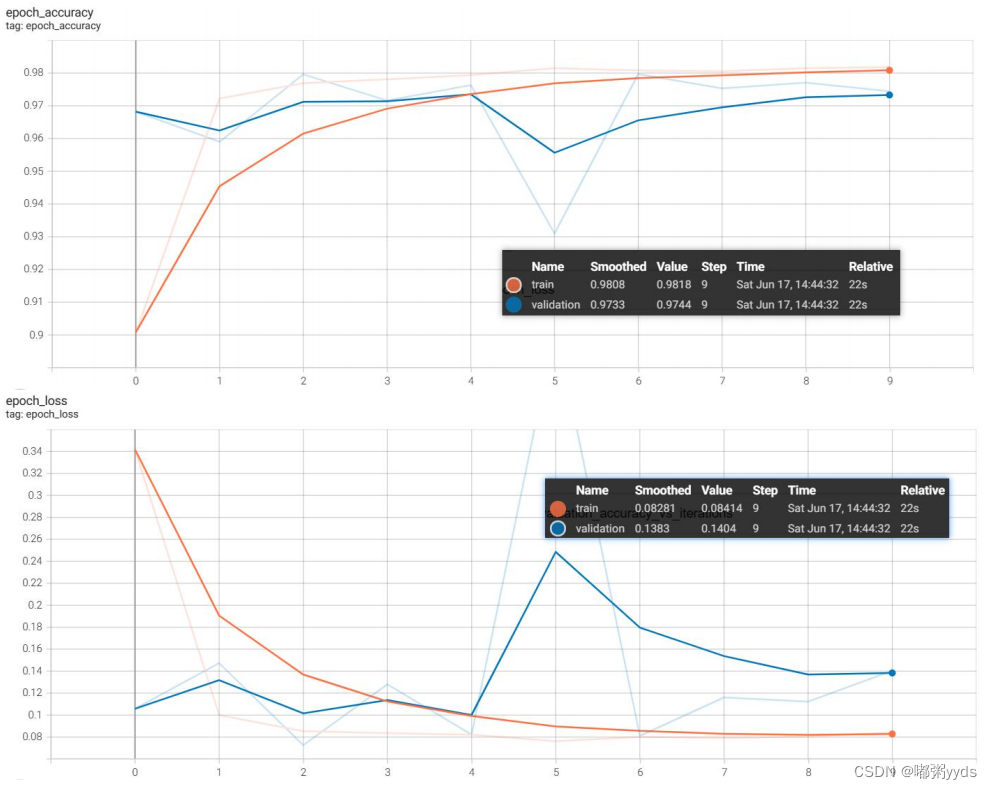
图13:模型结构图
深度残差网络
代码实现
import tensorflow as tf
from tensorflow.keras import layers, Sequential, losses, optimizers
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.use('TKAgg')
# 动态分配GPU内存
gpus = tf.config.experimental.list_physical_devices("GPU")
if gpus:
try:
# 设置GPU显存占用为按需分配,增长式
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
print(e)
# 首先实现中间两个卷积层,Skip Connection 1x1 卷积层的残差模块
class BasicBlock(tf.keras.layers.Layer):
# 残差模块
def __init__(self, filter_num, stride=1):
super(BasicBlock, self).__init__()
# 第一个卷积单元
self.conv1 = layers.Conv2D(filter_num, (3, 3), strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.Activation('relu')
# 第二个卷积单元
self.conv2 = layers.Conv2D(filter_num, (3, 3), strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
if stride != 1: # 通过 1x1 卷积完成 shape 匹配
self.downsample = Sequential()
self.downsample.add(layers.Conv2D(filter_num, (1, 1), strides=stride))
else: # shape 匹配,直接短接
self.downsample = lambda x: x
def call(self, inputs, training=None):
# 前向计算函数
# [b, h, w, c],通过第一个卷积单元
out = self.conv1(inputs)
out = self.bn1(out)
out = self.relu(out)
# 通过第二个卷积单元
out = self.conv2(out)
out = self.bn2(out)
# 通过 identity 模块
identity = self.downsample(inputs)
# 2 条路径输出直接相加
output = layers.add([out, identity])
output = tf.nn.relu(output) # 通过激活函数
return output
# 实现ResNet网络模型
class ResNet(tf.keras.Model):
# 通用的 ResNet 实现类
def __init__(self, layer_dims, num_classes=10): # [2, 2, 2, 2]
super(ResNet, self).__init__()
# 根网络,预处理
self.stem = Sequential([
layers.Conv2D(64, (3, 3), strides=(1, 1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding='same')
])
# 堆叠 4 个 Block,每个 Block 包含了多个 BasicBlock,设置步长不一样
self.layer1 = self.build_resblock(64, layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1], stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# 通过 Pooling 层将高宽降低为 1x1
self.avgpool = layers.GlobalAveragePooling2D()
# 最后连接一个全连接层分类
self.fc = layers.Dense(num_classes)
def call(self, inputs, training=None):
x = self.stem(inputs)
# 一次通过 4 个模块
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
# 通过池化层
x = self.avgpool(x)
# 通过全连接层
x = self.fc(x)
return x
def build_resblock(self, filter_num, blocks, stride=1):
# 辅助函数,堆叠 filter_num 个 BasicBlock
res_blocks = Sequential()
# 只有第一个 BasicBlock 的步长可能不为 1,实现下采样
res_blocks.add(BasicBlock(filter_num, stride))
for _ in range(1, blocks): # 其他 BasicBlock 步长都为 1
res_blocks.add(BasicBlock(filter_num, stride=1))
return res_blocks
def resnet18():
# 通过调整模块内部BasicBlock的数量和配置实现不同的ResNet
return ResNet([2, 2, 2, 2])
def resnet34():
# 通过调整模块内部BasicBlock的数量和配置实现不同的ResNet
return ResNet([3, 4, 6, 3])
# 数据预处理
def preprocess(x, y):
# 将x缩放到区间[-1, 1]上
x = 2 * tf.cast(x, dtype=tf.float32) / 255. - 1
y = tf.cast(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
return x, y
if __name__ == '__main__':
save_dir = 'save_model/mnist_ResNet-18_model'
if not os.path.exists(save_dir):
# 训练集 验证集
(x, y), (x_val, y_val) = tf.keras.datasets.mnist.load_data()
x_train, x_test = tf.split(x, num_or_size_splits=[45000, 15000], axis=0)
y_train, y_test = tf.split(y, num_or_size_splits=[45000, 15000], axis=0)
print(
f"datasets:\nx_train:{x_train.shape} x_test:{x_test.shape} x_val:{x_val.shape}\ny_train:{y_train.shape} y_test:{y_test.shape} y_val:{y_val.shape}")
# 训练数据集
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_db = train_db.map(preprocess).shuffle(45000).batch(128)
# 验证数据集
ds_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
ds_val = ds_val.map(preprocess).batch(128)
# 测试数据集
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.map(preprocess).batch(128)
# 采样一个样本
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
# 创建TensorBorad环境(保存路径因人而异)
log_dir = './MNIST_ResNet18_logs'
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
optimizer = optimizers.Adam(learning_rate=1e-4)
loss_fn = losses.CategoricalCrossentropy(from_logits=True,
reduction=tf.keras.losses.Reduction.SUM_OVER_BATCH_SIZE)
train_accuracy = tf.keras.metrics.CategoricalAccuracy(name='train_accuracy')
test_accuracy = tf.keras.metrics.CategoricalAccuracy(name='test_accuracy')
model = resnet18()
model.build(input_shape=(None, 28, 28, 1)) # 输入尺寸改为28x28x1
# 打印网络参数信息
model.summary()
# 编译模型
model.compile(optimizer=optimizer, loss=loss_fn, metrics=[train_accuracy, test_accuracy])
# 开始训练
epochs = 5
model.fit(train_db, epochs=epochs, validation_data=ds_val, callbacks=[tensorboard_callback])
# 保存模型为TensorFlow SavedModel格式
model.save('save_model/mnist_ResNet-18_model')
print("模型保存成功")
模型讲解
-
Stem 部分: ResNet-18以一个卷积层作为模型的初始部分,用于对输入图像进行特征提取。该 卷积层后面跟着批归一化层、 ReLU激活函数和最大池化层,以减小特征图的大小。
-
Layer 部分: ResNet-18 共包含4个 Layer ,每个 Layer 由若干个 BasicBlock 组成。第一个 Layer的BasicBlock 输出通道数为64,后续的 Layer 依次翻倍,分别为 128 、 256 和 512。
-
全局平均池化层:在经过4个 Layer 后, ResNet-18使用全局平均池化层将特征图转换为一维向 量,以便进行分类。
-
全连接层:最后, ResNet-18 使用全连接层将特征向量映射到预测类别的输出。
图14: 模型的训练准确率和损失值。

图15:模型结构图。
总结
图 16: 仿真数据集图片。

图17: 三个模型的预测成功率汇总对比。