目录标题
拼接和合并在视频处理中有所不同,:
-
拼接 (Concatenation):
- 指的是将两个或多个视频文件按照时间顺序连接在一起,形成一个连续的视频文件。例如,您有两个视频文件,一个是5分钟长,另一个是10分钟长。拼接它们会得到一个15分钟长的视频文件。
- 通常用于将多个视频片段组合成一个完整的视频,例如将多个家庭录像片段组合成一个完整的家庭录像。
-
合并 (Merging):
- 指的是将两个或多个视频流的内容叠加在一起,形成一个新的视频流。这通常涉及到将一个视频的画面与另一个视频的画面合并在一起,可能是为了制作画中画效果或双摄像头录制的效果。
- 通常用于将多个视频流的内容叠加在一起,例如在新闻报道中,将现场直播的画面与录播的画面叠加在一起。
为了帮助您更直观地理解,我将为您绘制一个简单的图表来展示这两种操作的区别。
以下是一个简单的图表,展示了视频拼接和视频合并的区别:
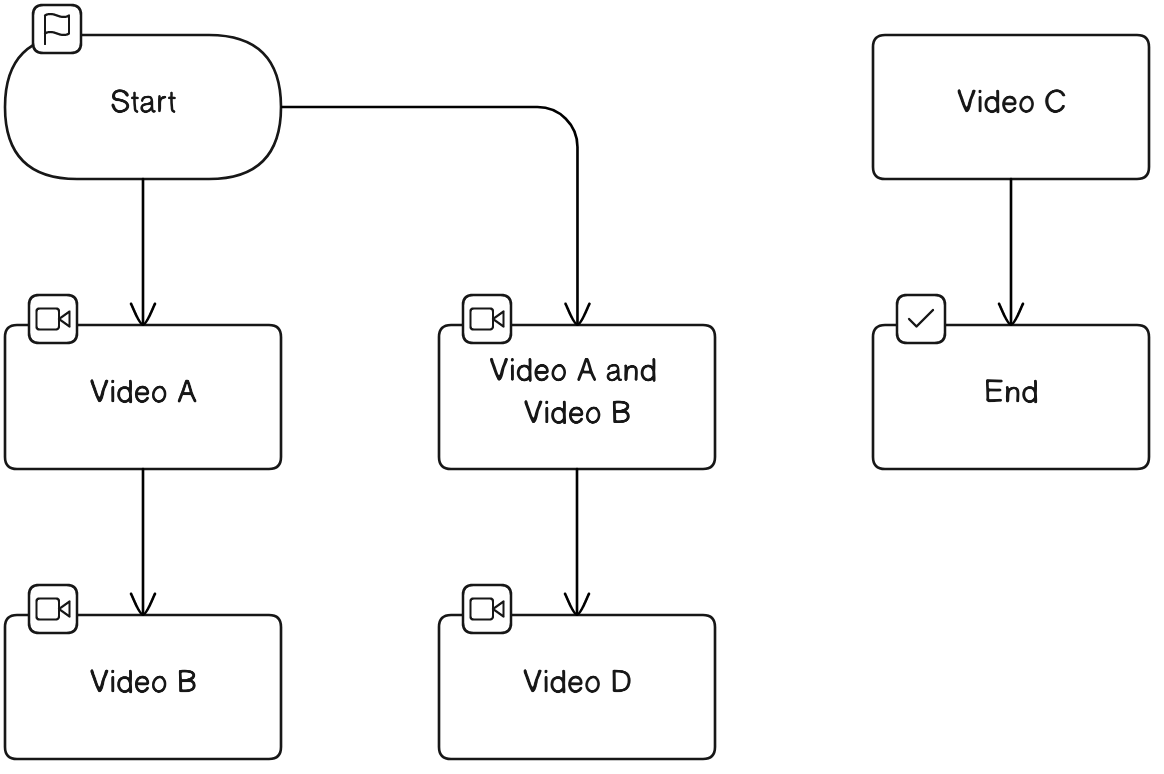
- 视频拼接:将视频A和视频B按时间顺序连接在一起,形成视频C。
- 视频合并:将视频A和视频B的内容叠加在一起,形成视频D。
1. 视频流画面合并 (Merging Video Frames with FFmpeg API)
在处理视频流时,我们经常需要将多个视频帧合并成一个。这在制作特效、添加水印或将多个视频片段组合成一个时尤为重要。在本章中,我们将深入探讨如何使用FFmpeg API进行视频帧的合并。
1.1 获取视频流的帧 (Fetching frames from a video stream)
在开始合并之前,我们首先需要从视频流中获取帧。这可以通过av_read_frame函数实现,它从输入文件中读取下一帧。
AVPacket pkt;
av_init_packet(&pkt);
pkt.data = NULL;
pkt.size = 0;
if (av_read_frame(pFormatCtx, &pkt) >= 0) {
// 处理帧数据
}
1.2 使用av_frame_alloc和av_frame_copy进行帧合并
要合并视频帧,我们需要为新的合并帧分配内存,并将原始帧的数据复制到新帧中。这可以通过av_frame_alloc和av_frame_copy函数实现。
AVFrame *frame1 = av_frame_alloc();
AVFrame *frame2 = av_frame_alloc();
// ... 初始化frame1和frame2 ...
AVFrame *mergedFrame = av_frame_alloc();
av_frame_copy(mergedFrame, frame1);
av_frame_copy(mergedFrame, frame2);
在这里,我们首先为两个要合并的帧和一个新的合并帧分配内存。然后,我们使用av_frame_copy函数将两个帧的数据复制到新的合并帧中。
正如《C++ Primer》中所说:“复制是一种基本的编程操作,它允许我们创建对象的多个实例。”这在处理视频帧时尤为重要,因为我们经常需要在不修改原始数据的情况下创建新的帧。
1.3 示例代码与解析
以下是一个简单的示例,展示了如何使用FFmpeg API合并两个视频帧:
extern "C" {
#include <libavformat/avformat.h>
#include <libavcodec/avcodec.h>
}
int main() {
AVFormatContext *pFormatCtx = NULL;
// ... 初始化pFormatCtx ...
AVPacket pkt;
av_init_packet(&pkt);
pkt.data = NULL;
pkt.size = 0;
if (av_read_frame(pFormatCtx, &pkt) >= 0) {
AVFrame *frame1 = av_frame_alloc();
AVFrame *frame2 = av_frame_alloc();
// ... 初始化frame1和frame2 ...
AVFrame *mergedFrame = av_frame_alloc();
av_frame_copy(mergedFrame, frame1);
av_frame_copy(mergedFrame, frame2);
// ... 使用合并帧 ...
}
return 0;
}
在这个示例中,我们首先初始化了一个AVFormatContext,然后从视频流中读取帧。接下来,我们为两个要合并的帧和一个新的合并帧分配内存,并使用av_frame_copy函数进行合并。
这种方法的优点是它允许我们在不修改原始帧数据的情况下创建新的合并帧。这在制作特效或添加水印时尤为重要,因为我们不希望修改原始视频的内容。
正如《哲学家的石头》中所说:“真实的知识不仅仅是知道事物的存在,还要知道它们是如何工作的。”通过深入了解FFmpeg API的工作原理,我们可以更好地理解视频处理的复杂性,并为读者提供更深入的洞察。
在Linux系统中,FFmpeg的源码可以在/usr/src/ffmpeg目录下找到。例如,av_frame_copy函数的实现可以在libavutil/frame.c文件中找到。这为我们提供了一个深入了解这些函数如何工作的机会,并帮助我们更好地理解其设计的精妙之处。
1.4 av_frame_copy函数深度解析
av_frame_copy是一个用于复制视频帧数据的函数。但在使用它之前,我们需要深入了解其工作原理和可能遇到的问题。
1.4.1 av_frame_copy函数的基本工作原理
av_frame_copy函数的主要目的是将一个帧的数据复制到另一个帧。它不仅复制图像和声音数据,还复制帧的所有属性,如时间戳、持续时间等。
int av_frame_copy(AVFrame *dst, const AVFrame *src);
其中,dst是目标帧,src是源帧。
1.4.2 合并不同大小的帧
当我们尝试合并两个大小不同的帧时,av_frame_copy会按照目标帧dst的大小进行复制。这意味着,如果src帧的大小大于dst帧,那么只有dst帧大小的数据会被复制。反之,如果src帧的大小小于dst帧,那么dst帧的剩余部分将不会被修改。
这可能会导致一些问题,例如,当我们尝试合并两个分辨率不同的视频帧时,可能会得到一个不完整或扭曲的图像。
1.4.3 时间戳:PTS和DTS
PTS(Presentation Time Stamp)和DTS(Decoding Time Stamp)是视频帧的两个重要属性。它们分别表示帧应该被显示和解码的时间。
当我们使用av_frame_copy函数复制帧时,PTS和DTS也会被复制。这意味着,如果我们不小心合并了两个帧,它们可能会有相同的PTS和DTS,导致播放时出现问题。
为了避免这种情况,我们需要确保在合并帧之前正确设置PTS和DTS。例如,我们可以使用av_rescale_q函数来调整时间戳,确保它们在合并后仍然是连续的。
1.4.4 其他可能的问题
除了上述问题外,使用av_frame_copy函数还可能遇到其他问题。例如,如果源帧和目标帧的像素格式不同,复制可能会失败。此外,如果帧的引用计数不正确,也可能导致内存泄漏或其他错误。
为了避免这些问题,我们需要确保在使用av_frame_copy函数之前,源帧和目标帧都已经正确初始化,并且它们的属性(如像素格式、时间戳等)是兼容的。
正如《C++编程思想》中所说:“复制是一种基本操作,但它也可能是一种危险操作。我们需要确保在复制时不破坏原始数据,并且正确处理所有相关的属性和状态。”
在Linux系统中,av_frame_copy函数的实现可以在libavutil/frame.c文件中找到。通过深入研究这些源代码,我们可以更好地理解这个函数的工作原理,并避免可能的问题。
2. 视频拼接 (Video Concatenation with FFmpeg API)
视频拼接是一个常见的需求,无论是为了制作高亮片段,还是将多个视频片段组合成一个完整的视频。在这一章节中,我们将深入探讨如何使用FFmpeg API进行视频拼接。
2.1 API函数介绍
2.1.1 av_read_frame
av_read_frame是一个用于从输入文件中读取一个完整的帧的函数。它返回一个已填充的AVPacket结构体,该结构体包含了解码帧所需的数据。
int av_read_frame(AVFormatContext *s, AVPacket *pkt);
2.1.2 av_interleaved_write_frame
av_interleaved_write_frame是一个用于将帧写入输出文件的函数。它确保帧按照正确的时间顺序(交错)写入,这对于某些容器格式(如MP4或MKV)来说是必要的。
int av_interleaved_write_frame(AVFormatContext *s, AVPacket *pkt);
2.2 示例代码与解析
以下是一个简单的示例,展示如何使用上述函数进行视频拼接:
AVFormatContext *input_format_context = NULL, *output_format_context = NULL;
AVPacket pkt;
// 打开输入文件
avformat_open_input(&input_format_context, "input1.mp4", NULL, NULL);
avformat_open_input(&input_format_context, "input2.mp4", NULL, NULL);
// 打开输出文件
avformat_alloc_output_context2(&output_format_context, NULL, NULL, "output.mp4");
avio_open(&output_format_context->pb, "output.mp4", AVIO_FLAG_WRITE);
// 从输入文件中读取帧,并写入输出文件
while (av_read_frame(input_format_context, &pkt) >= 0) {
av_interleaved_write_frame(output_format_context, &pkt);
av_packet_unref(&pkt);
}
// 关闭输入和输出文件
avformat_close_input(&input_format_context);
avio_closep(&output_format_context->pb);
avformat_free_context(output_format_context);
在这个示例中,我们首先打开两个输入文件和一个输出文件。然后,我们使用av_read_frame从输入文件中读取帧,并使用av_interleaved_write_frame将它们写入输出文件。最后,我们关闭所有打开的文件。
正如《C++编程思想》中所说:“代码是写给人看的,顺便给机器执行的。”这段代码不仅展示了如何使用FFmpeg API进行视频拼接,还体现了代码的简洁和易读性。
视频拼接的过程就像是将两部电影的片段组合成一部新的电影。每一帧都是一个独立的故事片段,而我们的任务就是确保这些片段按照正确的顺序组合在一起,形成一个连贯的故事。
在进行视频拼接时,我们需要确保视频的时间戳是连续的,否则可能会导致视频播放时出现跳跃。这就像是在编辑电影时,需要确保每一个镜头都与前一个镜头和后一个镜头无缝衔接,形成一个连贯的故事线。
总的来说,视频拼接是一个既简单又复杂的过程。简单在于它只涉及到读取和写入帧的操作;复杂在于我们需要确保视频的连贯性和流畅性。但只要我们掌握了正确的方法和工具,就可以轻松地完成这一任务。
2.3 创建新的视频流
在FFmpeg中,视频文件是由多个流组成的,例如视频流、音频流等。当我们想要将两个或多个视频拼接成一个新的视频流时,我们需要创建一个新的视频流,并将所有的帧按照正确的顺序添加到这个新的流中。
2.3.1 创建新的视频流
要创建一个新的视频流,我们可以使用avformat_new_stream函数。这个函数会在给定的AVFormatContext中创建一个新的AVStream。
AVStream *avformat_new_stream(AVFormatContext *s, const AVCodec *c);
2.3.2 添加帧到新的视频流
一旦我们创建了一个新的视频流,我们就可以开始向其中添加帧了。为了确保帧按照正确的顺序被添加,我们需要为每个帧设置正确的时间戳。
AVPacket pkt;
while (av_read_frame(input_format_context, &pkt) >= 0) {
// 设置正确的时间戳
pkt.pts = av_rescale_q_rnd(pkt.pts, input_format_context->streams[pkt.stream_index]->time_base, new_stream->time_base, AV_ROUND_NEAR_INF|AV_ROUND_PASS_MINMAX);
pkt.dts = av_rescale_q_rnd(pkt.dts, input_format_context->streams[pkt.stream_index]->time_base, new_stream->time_base, AV_ROUND_NEAR_INF|AV_ROUND_PASS_MINMAX);
pkt.duration = av_rescale_q(pkt.duration, input_format_context->streams[pkt.stream_index]->time_base, new_stream->time_base);
pkt.pos = -1;
pkt.stream_index = new_stream->index;
// 将帧添加到新的视频流中
av_interleaved_write_frame(output_format_context, &pkt);
av_packet_unref(&pkt);
}
在这个示例中,我们首先读取输入文件中的每个帧。然后,我们使用av_rescale_q_rnd函数来重新计算每个帧的时间戳,以确保它们在新的视频流中按照正确的顺序被添加。最后,我们使用av_interleaved_write_frame函数将帧添加到新的视频流中。
正如《C++ Primer》中所说:“编程不仅仅是关于写代码,更多的是关于解决问题。”在这个过程中,我们面临的主要挑战是确保帧按照正确的顺序被添加到新的视频流中。但只要我们掌握了正确的方法和工具,就可以轻松地解决这个问题。
2.4 拼接的细节处理
当我们谈论视频拼接时,不能简单地将两个视频流的帧按顺序放在一起。为了确保拼接后的视频流的连贯性和流畅性,我们需要对帧的大小、帧率、时间戳等进行一定的处理。
2.4.1 帧大小和比例
当两个视频的分辨率或宽高比不同时,直接拼接可能会导致视频的突然变化,影响观看体验。为了解决这个问题,我们可以:
- 将所有视频调整为相同的分辨率。
- 使用黑边或白边填充,使视频具有相同的宽高比,但保持原始分辨率。
2.4.2 帧率处理
不同的视频可能有不同的帧率。为了确保拼接后的视频流的连贯性,我们需要:
- 将所有视频的帧率调整为相同的值。
- 使用帧插值技术,根据需要增加或减少帧,以匹配目标帧率。
2.4.3 时间戳(PTS)处理
当我们拼接视频时,需要确保每个帧的时间戳是连续的。为了实现这一点,我们可以:
- 为第二个视频的每个帧添加第一个视频的最后一个帧的时间戳。
- 使用
av_rescale_q_rnd函数重新计算每个帧的时间戳,以确保它们在新的视频流中按照正确的顺序被添加。
2.4.4 示例代码
以下是一个简单的示例,展示如何处理上述的细节问题:
AVPacket pkt;
int64_t last_pts = 0;
// 读取第一个视频的帧
while (av_read_frame(input_format_context1, &pkt) >= 0) {
av_interleaved_write_frame(output_format_context, &pkt);
last_pts = pkt.pts;
av_packet_unref(&pkt);
}
// 读取第二个视频的帧,并处理时间戳
while (av_read_frame(input_format_context2, &pkt) >= 0) {
pkt.pts += last_pts;
pkt.dts += last_pts;
av_interleaved_write_frame(output_format_context, &pkt);
av_packet_unref(&pkt);
}
在这个示例中,我们首先读取第一个视频的帧,并记录最后一个帧的时间戳。然后,我们读取第二个视频的帧,并为每个帧添加第一个视频的最后一个帧的时间戳,以确保时间戳的连续性。
3. 视频裁剪 (Cropping Videos with FFmpeg API)
在处理视频时,裁剪是一个常见的需求。裁剪可以帮助我们去除视频中不必要的部分,或者将焦点集中在某个特定区域。在本章中,我们将详细介绍如何使用FFmpeg API进行视频裁剪。
3.1 使用av_frame_make_writable确保帧可写
在裁剪视频之前,我们需要确保视频帧是可写的。这是因为在FFmpeg中,视频帧可能是只读的,尤其是当它们来自解码器时。为了确保我们可以修改帧,我们使用av_frame_make_writable函数。
AVFrame *frame;
// ... 获取帧的代码 ...
if (av_frame_make_writable(frame) < 0) {
// 错误处理
}
这段代码确保了帧是可写的,如果帧不可写,它会创建一个新的帧并复制原始帧的内容。
3.2 使用av_picture_crop进行视频裁剪
FFmpeg提供了一个名为av_picture_crop的函数,用于裁剪视频帧。这个函数需要一个目标帧、一个源帧和裁剪的区域。
AVFrame *src_frame, *dst_frame;
// ... 初始化帧的代码 ...
int ret = av_picture_crop(dst_frame, src_frame, AV_PIX_FMT_YUV420P, top, left);
if (ret < 0) {
// 错误处理
}
在这里,top和left定义了裁剪区域的起始点。函数会从这个点开始,裁剪与目标帧大小相同的区域。
正如《C++编程思想》中所说:“代码是写给人看的,只是恰好机器也能执行。”这段代码不仅展示了如何使用API,还强调了代码的可读性和清晰性的重要性。
3.3 API参数优化与配置
当我们裁剪视频时,可能会遇到一些问题,例如裁剪的区域超出了原始视频的边界。为了避免这种情况,我们可以使用av_frame_get_buffer函数来获取帧的实际大小,并据此调整裁剪区域。
int width = av_frame_get_buffer(src_frame, 0);
int height = av_frame_get_buffer(src_frame, 1);
// 根据实际大小调整裁剪区域
此外,为了获得更好的裁剪效果,我们还可以调整一些其他的参数,例如裁剪的质量和速度。这些参数可以通过AVCodecContext结构体进行配置。
在Linux内核源码中,我们可以在libavcodec/avcodec.h文件中找到AVCodecContext的定义。这个结构体包含了大量的字段,用于配置编解码器的行为。通过深入研究这个结构体,我们可以更好地理解FFmpeg的工作原理。
3.4 总结
视频裁剪是一个看似简单,但实际上涉及许多细节的过程。通过使用FFmpeg API,我们可以轻松地实现这一功能。但是,为了获得最佳的效果,我们还需要深入了解API的工作原理和相关的参数配置。
正如哲学家庄子所说:“知之为知之,不知为不知,是知也。”当我们深入研究一个问题时,我们不仅会获得知识,还会对自己的无知有所认识。这种认识是真正的智慧的开始。
4. API参数优化与配置
在进行视频处理时,我们经常需要对视频的各种参数进行优化和配置,以达到最佳的效果。这一章节将详细介绍如何使用FFmpeg API进行这些操作。
4.1 设置视频裁剪的边界
在进行视频裁剪时,我们需要确定裁剪的起始点和结束点。这通常是通过设置视频的时间戳来实现的。
// 设置裁剪的起始时间和结束时间
int64_t start_time = av_rescale_q(10, AV_TIME_BASE_Q, video_stream->time_base); // 从第10秒开始
int64_t end_time = av_rescale_q(20, AV_TIME_BASE_Q, video_stream->time_base); // 在第20秒结束
// 使用av_seek_frame函数跳转到指定的起始时间
av_seek_frame(format_ctx, video_stream_index, start_time, AVSEEK_FLAG_ANY);
在上述代码中,我们首先使用av_rescale_q函数将我们想要的裁剪时间转换为视频流的时间基准。然后,使用av_seek_frame函数跳转到指定的起始时间。
正如《C++编程思想》中所说:“代码不仅仅是给机器看的,更重要的是给人看的。”这段代码展示了如何使用FFmpeg API进行视频裁剪的基本步骤,同时也体现了代码的可读性和易于理解的重要性。
4.2 调整合并和拼接的视频质量
当我们进行视频合并或拼接时,可能会遇到视频质量下降的问题。为了解决这个问题,我们可以使用FFmpeg API提供的参数进行优化。
// 设置编码器的参数
AVCodecContext *codec_ctx = video_stream->codec;
codec_ctx->bit_rate = 400000; // 设置比特率为400kbps
codec_ctx->gop_size = 12; // 设置GOP大小为12
codec_ctx->max_b_frames = 2; // 设置B帧的最大数量为2
在这段代码中,我们设置了编码器的比特率、GOP大小和B帧的最大数量,以优化视频的质量。这些参数的设置需要根据实际的需求进行调整。
如哲学家庄子所说:“工欲善其事,必先利其器。”这段代码不仅展示了如何使用FFmpeg API进行视频质量的优化,还体现了工具和方法在解决问题时的重要性。
4.2.1 深入理解比特率
比特率是视频质量的关键参数之一。它决定了视频的清晰度和大小。一般来说,比特率越高,视频的质量越好,但文件的大小也越大。
在std库的源码中,我们可以看到很多与数据处理和优化相关的函数。这些函数为我们提供了处理大量数据时的便利,同时也体现了C++语言的强大和灵活。
通过合理地设置比特率,我们可以在保证视频质量的同时,控制视频的大小,达到最佳的效果。
4.3 总结
在这一章节中,我们详细介绍了如何使用FFmpeg API进行视频参数的优化和配置。通过合理地设置参数,我们可以达到最佳的视频处理效果。同时,我们也结合了C++和哲学的知识,为读者提供了更深入的洞察。
5. 常见问题与解决策略
在进行视频流处理时,我们可能会遇到各种问题。本章将探讨这些常见问题及其解决策略,并结合代码示例进行说明。
5.1 处理不同分辨率的视频流合并
当我们尝试合并两个或多个不同分辨率的视频流时,可能会遇到一些问题。例如,一个视频是720p,而另一个是1080p。直接合并这两个视频可能会导致输出视频的质量下降或者画面变形。
解决方法:
- 使用FFmpeg API的
av_rescale_q函数来调整视频帧的时间基准,确保两个视频流的帧率相同。 - 使用
sws_getContext和sws_scale函数来调整视频帧的分辨率,使其与目标输出视频的分辨率相匹配。
// 示例代码
SwsContext* sws_ctx = sws_getContext(src_width, src_height, src_pix_fmt,
dst_width, dst_height, dst_pix_fmt,
SWS_BILINEAR, NULL, NULL, NULL);
if (!sws_ctx) {
// 错误处理
}
// 调整分辨率
sws_scale(sws_ctx, src_data, src_linesize, 0, src_height, dst_data, dst_linesize);
这样,无论输入视频的分辨率如何,输出视频都会有一个统一的分辨率。
5.2 解决视频拼接时的音频不同步问题
在拼接视频时,如果两个视频的音频帧率不同,可能会导致输出视频的音频和视频不同步。
解决方法:
- 使用
av_rescale_q函数调整音频帧的时间基准,确保两个视频的音频帧率相同。 - 如果需要,还可以使用
av_samples_alloc和swr_convert函数来转换音频格式和采样率。
// 示例代码
SwrContext* swr_ctx = swr_alloc_set_opts(NULL, dst_channel_layout, dst_sample_fmt, dst_sample_rate,
src_channel_layout, src_sample_fmt, src_sample_rate, 0, NULL);
if (!swr_ctx || swr_init(swr_ctx) < 0) {
// 错误处理
}
// 转换音频格式和采样率
int dst_nb_samples = av_rescale_rnd(swr_get_delay(swr_ctx, src_sample_rate) + src_nb_samples,
dst_sample_rate, src_sample_rate, AV_ROUND_UP);
swr_convert(swr_ctx, dst_data, dst_nb_samples, (const uint8_t**)src_data, src_nb_samples);
通过上述方法,我们可以确保拼接后的视频音频同步。
正如《C++ Primer》中所说:“代码是写给人看的,只是恰好机器也能执行。”这句话强调了代码的可读性和清晰性的重要性。在处理视频流时,我们不仅要考虑效率,还要确保代码的可读性和可维护性。
在Linux内核源码中,我们可以在drivers/media目录下找到与多媒体设备交互的相关代码。这部分代码为我们提供了与视频设备交互的底层接口,帮助我们更好地理解视频流处理的内部工作原理。
| 问题 | 原因 | 解决方法 |
|---|---|---|
| 不同分辨率的视频流合并 | 视频分辨率不匹配 | 调整视频帧的分辨率 |
| 视频拼接时的音频不同步 | 音频帧率不匹配 | 调整音频帧的时间基准 |
在处理这些问题时,我们不仅要关注技术细节,还要思考为什么会出现这些问题。正如哲学家庄子所说:“道生一,一生二,二生三,三生万物。”这句话告诉我们,万事万物都有其根源和原因,只有深入探究,才能真正理解其本质。
结语
在我们的编程学习之旅中,理解是我们迈向更高层次的重要一步。然而,掌握新技能、新理念,始终需要时间和坚持。从心理学的角度看,学习往往伴随着不断的试错和调整,这就像是我们的大脑在逐渐优化其解决问题的“算法”。
这就是为什么当我们遇到错误,我们应该将其视为学习和进步的机会,而不仅仅是困扰。通过理解和解决这些问题,我们不仅可以修复当前的代码,更可以提升我们的编程能力,防止在未来的项目中犯相同的错误。
我鼓励大家积极参与进来,不断提升自己的编程技术。无论你是初学者还是有经验的开发者,我希望我的博客能对你的学习之路有所帮助。如果你觉得这篇文章有用,不妨点击收藏,或者留下你的评论分享你的见解和经验,也欢迎你对我博客的内容提出建议和问题。每一次的点赞、评论、分享和关注都是对我的最大支持,也是对我持续分享和创作的动力。
阅读我的CSDN主页,解锁更多精彩内容:泡沫的CSDN主页
