前情提要
这一个月来干了啥事情呢?AI 绘画搞了2周左右,SD 建筑绘图,训练 LORA ,模型控制基本也上手了,可以按照预期生成自己想要的东西,那种控制感是挺开心的,不然你输入一句话生成 AI 图片完全凭天意,这叫无效沟通好不啦;突发奇想要搞 AI 歌曲合成,为了不引发版权诉讼问题,用自己的声音合成了些歌曲,因为不是在录音棚录音的,并且声音数据比较少,所以训练效果还是有点差强人意,不过相较我自己唱的而言已经好到天上去了;AI 语言的实践完成以后,我又开始对 AI 人工智能对话开始下手了,这个才是和大脑思考最接近的一项技术了,应用面也很广泛的,所以一定要搞下来。
那这些小玩意实践过之后,怎么玩呢,其实 AI 的话行业应用就两个层面了,一个是 AI 算法和应用,还有就是 AI 算力调度,因为去年参与过移动云的"东数西算"架构设计,AI 算力调度这块应该还好(去年算力资源真心浪费了),算法逻辑那块勉强看下吧,况且老子下半年还有考试呢,不能在这上面浪费太多时间,最近两个月的周末都耗在这上面了,不能这么沉沦下去了。
搭建部署
环境信息
**
OS:Win11
GPU:3070-RTX 32G
PYTHON:3.10
**
| 量化等级 | 最低GPU(对话) | 最低GPU(微调) |
|---|---|---|
| FP16(标准) | 13GB | 14GB |
| INT8 | 8GB | 9GB |
| INT4 | 6GB | 7GB |
安装依赖
项目下载
# 下载
git clone https://github.com/THUDM/ChatGLM2-6B
# 安装相关依赖
cd ChatGLM2-6B
pip install -r requirements.txt -i https://pypi.douban.com/simple
模型下载
云盘链接:https://pan.baidu.com/s/1AIerQMpvw7yO34Gq9BFxAQ
提取码:5uzo
将下载的模型放到 THUDM 文件夹下:

显卡驱动
# 查看本机显卡信息
nvidia-smi

安装 cuda-toolkit 工具: https://developer.nvidia.com/cuda-toolkit-archive
备注: 选择不高于上述CUDA的版本,建议版本为 11.8;
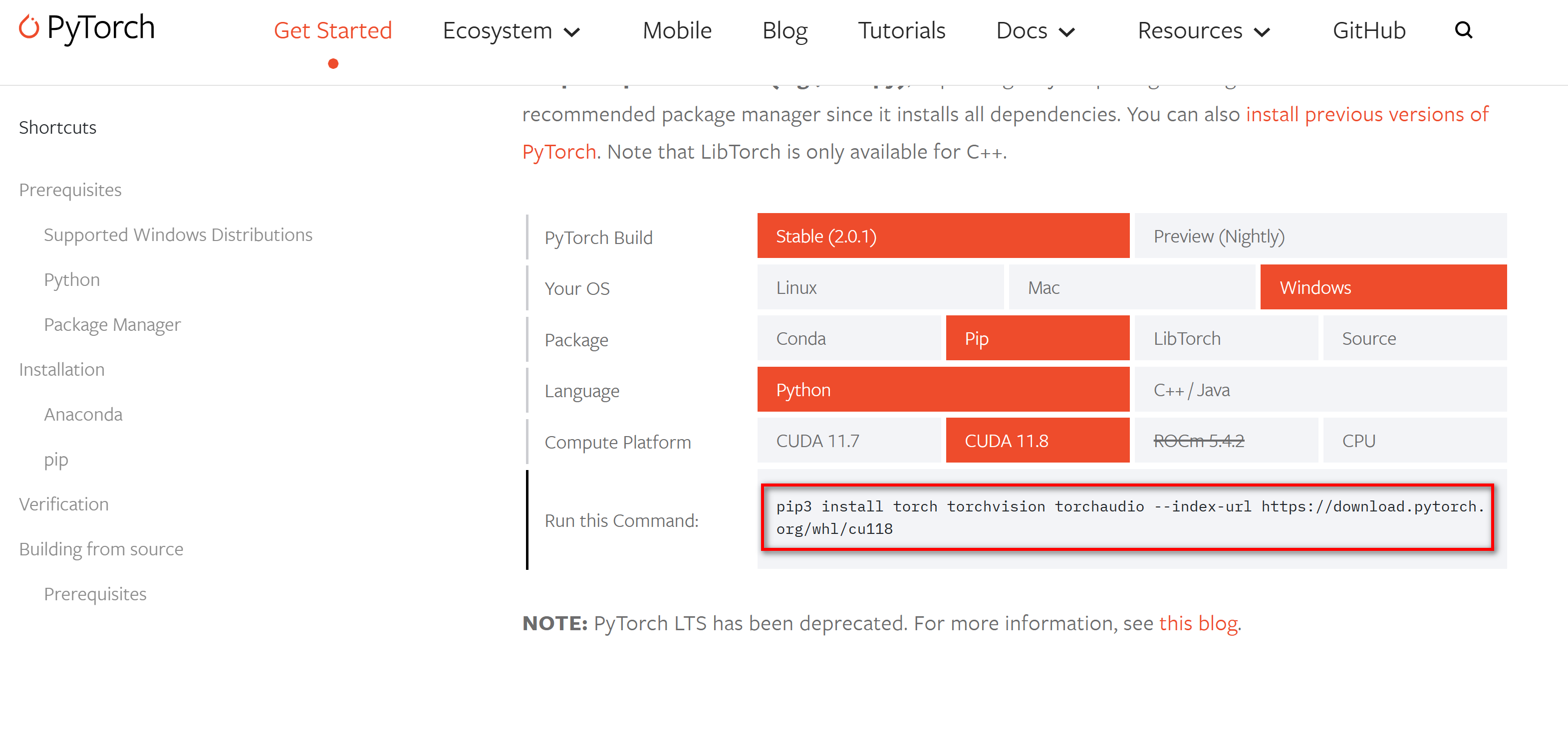
** Pytorch 依赖**
# 下载对应版本的 Pytorch
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
** CUDA 校验**
# cuda 可用校验(返回 True 则表示可用)
python -c "import torch; print(torch.cuda.is_available());"
配置选择
** 精度选择 **
在 api.py cli_demo.py web_demo.py web_demo.py 等脚本中,命令如下:
# 模型默认以 FP16 精度加载,运行模型需要大概 13GB 显存
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
# 如果 GPU 显存有限,按需修改,目前只支持 4/8 bit 量化
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).quantize(4).cuda()
# 如果内存不足,可以直接加载量化后的模型
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).cuda()
# 如果没有 GPU 硬件的话,也可以在 CPU 上进行对话,但是对话速度会很慢,需要32GB内存(量化模型需要5GB内存)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).float()
# 如果内存不足,可以直接加载量化后的模型
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).float()
在 CPU 上运行量化后的模型,还需要安装 gcc 与 openmp。多数 Linux 发行版默认已安装。对于 Windows ,可在安装 TDM-GCC 时勾选 openmp。
启动运行
** 控制台 **
# 控制台运行
python cli_demo.py

** 网页版 **
# 方式一
python web_demo.py
# 方式二
# 安装 streamlit_chat 模块
pip install streamlit_chat -i https://pypi.douban.com/simple
streamlit run web_demo2.py
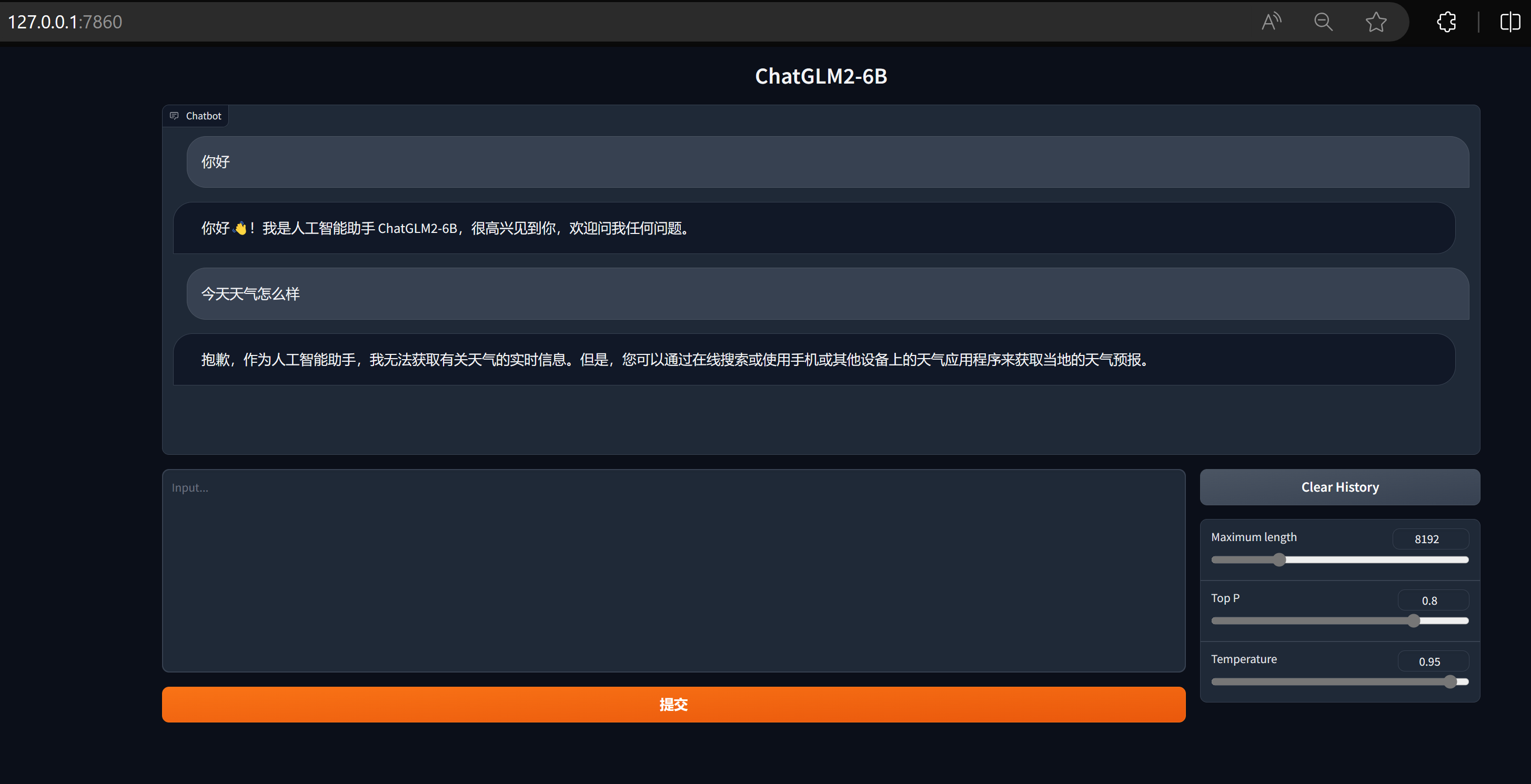
说明: 由于国内 Gradio 的网络访问较为缓慢,启用 demo.queue().launch(share=True, inbrowser=True) 时所有网络会经过 Gradio 服务器转发,导致打字机体验大幅下降,现在默认启动方式已经改为 share=False,如有需要公网访问的需求,可以重新修改为 share=True 启动。
** API **
# 安装 fastapi uvicorn 模块
pip install fastapi uvicorn -i https://pypi.douban.com/simple
# 运行 api
python api.py
默认部署在本地的 8000 端口,通过 POST 方法进行调用。
curl -X POST "http://127.0.0.1:8000" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
总结
附录
参考:https://juejin.cn/post/7250348861238870053