随着以图像和文本为基础的视觉语言预训练研究日益增长,许多其他有趣的研究主题也应运而生。以下,我们对每个单独的主题进行简要讨论,例如大模型、小样本学习、统一建模、鲁棒性评估等。
1. 大模型
规模被认为是实现最先进性能和构建通用基础模型的重要因素。正如在自然语言处理领域观察到的那样,越来越多的大型语言模型被预训练,从340M大小的BERT-large模型到具有1750B参数的GPT-3,再到最近的具有540B参数的PaLM。在视觉语言预训练领域也观察到了类似的趋势。如下表,我们总结了一些最近的大型视觉语言预训练模型,包括模型大小、预训练数据集大小和预训练任务。以下是一些观察结果:
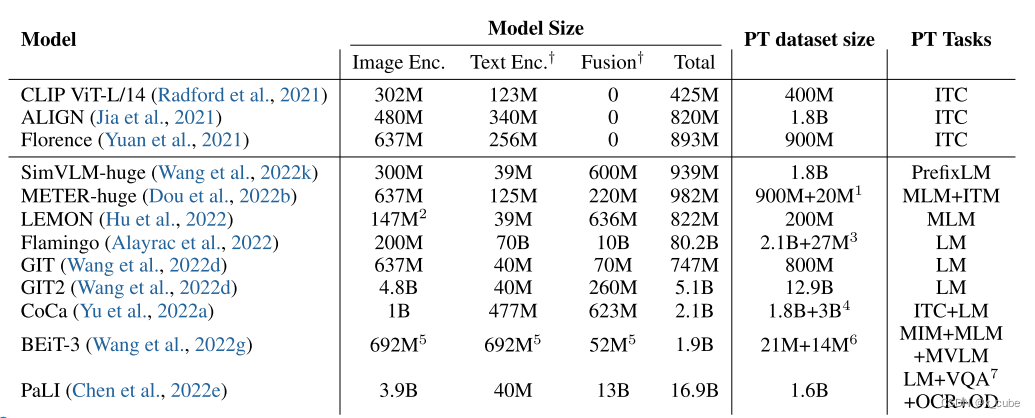
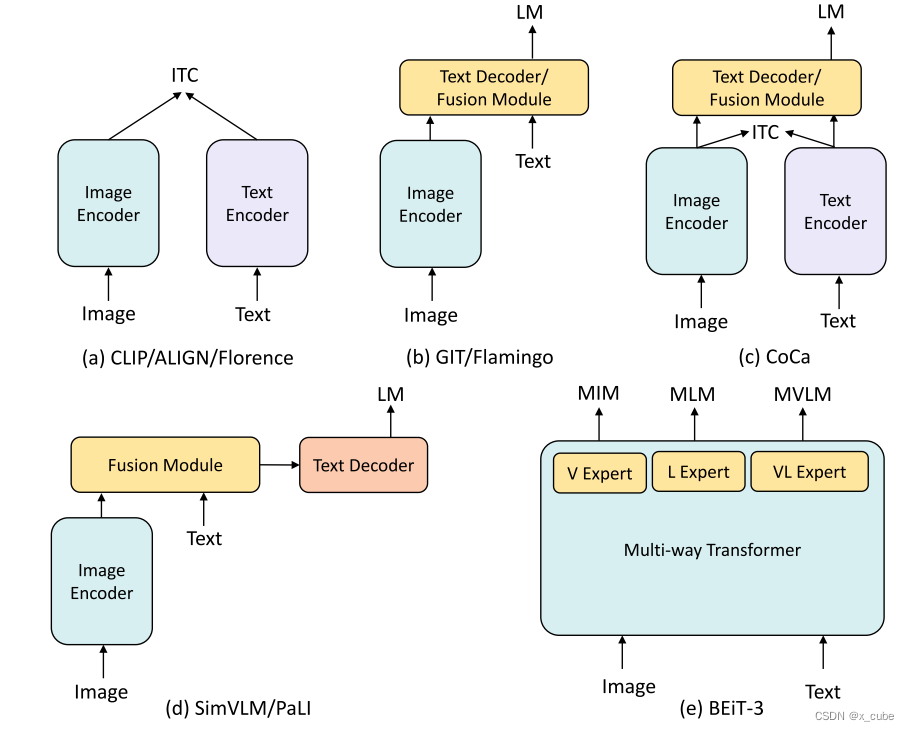
• 大多数大型视觉语言预训练模型是通过对比式预训练或生成式预训练,或两者的结合而获得的。使用图像-文本对比训练(ITC)可以实现快速的图文检索和开放域图像分类,而在融合模块后使用掩码语言模型(MLM)或语言模型(LM)则可以支持图像解释生成和视觉问答等多模态理解任务。
• 当前的大型视觉语言预训练模型通常包含大约10亿个参数,并在大约10亿到100亿个图文对上进行预训练。
• Flamingo采用了一个大型固定的语言模型(70B大小),以保持继承自预训练语言模型的上下文少样本学习能力,而GIT则采用了一个大型对比预训练的图像编码器,配合一个相对较小的文本解码器。
• Flamingo和GIT都是首先通过对比学习预训练图像编码器,然后进行生成式预训练。然而,在Flamingo中,图像编码器和文本解码器都被保持冻结状态;而在GIT中,文本解码器是随机初始化的,且图像编码器在生成式预训练阶段不保持冻结状态。
• CoCa不同于分别进行对比式和生成式预训练,它在一个阶段中同时进行对比式和生成式预训练。
• BEiT-3通过仅使用掩码数据建模和多通道Transformer设计,在VQA和其他视觉语言任务上实现了最先进的性能。
2. 基于上下文的少样本学习
通过完整模型微调来实现最先进的性能是很好的。更理想的是训练一个模型,通过提供一些上下文示例就可以快速适应不同的下游任务。在语言模型预训练的背景下,GPT-3 展示了这种能力,通过对大规模文本语料进行广泛预训练。受此启发,研究人员也开始探索多模态的上下文少样本学习。以下我们主要讨论三个工作:Frozen 、PICa 和Flamingo 。
• Frozen (Tsimpoukelli et al., 2021) 是这个领域的开创性研究。它表明,通过使用一个大型冻结的语言模型,并通过一个简单的图像字幕任务学习一个图像编码器来对齐图像和文本的嵌入空间,可以获得强大的上下文少样本学习性能。然而,该方法只使用两个全局向量对图像进行编码,无法捕捉到图像的所有视觉信息。另外,冻结语言模型只有7B的模型大小,可能不够大。
• 为了保留175B规模的GPT-3 (Brown et al., 2020) 强大的上下文少样本学习能力,PICa (Yang et al., 2022d) 提议通过使用图像字幕来提示GPT-3,以进行多模态少样本学习,因为GPT-3只能读取文本而不能读取图像。这种简单的方法已经可以在具有挑战性的OK-VQA基准测试中胜过监督式最先进方法,该基准测试需要外部知识才能正确回答关于输入图像的问题。然而,它在VQAv2数据集上的性能改进有限,因为字幕无法捕捉图像的每一个细节,细粒度的视觉信息可能会丢失。最近,在类似的思路下,还提出了VidIL (Wang et al., 2022j),它通过从GPT-3继承上下文学习能力来进行少样本视频-语言学习。
• 为了解决上述挑战,Flamingo 提出同时使用一个对比预训练的冻结图像编码器和一个大型冻结语言模型,并插入门控交叉注意力模块来连接这两个冻结模型。通过大规模预训练和使用70B规模的冻结语言模型,Flamingo报告了在上下文少样本学习方面的最新成果。
总的来说,这些工作通过利用多模态方法和大规模预训练展示了上下文少样本学习的潜力。对这一领域的进一步研究可以产生更先进的模型,具有增强的上下文适应能力。
除了依赖于大型语言模型,研究人员还探索了其他用于少样本学习的方法。在FewVLM (Jin et al., 2022)中,作者提出使用PrefixLM和MLM训练类似VL-T5的模型 (Cho et al., 2021),发现PrefixLM对于零/少样本图像字幕任务很有帮助,而MLM对于零/少样本的VQA任务效果较好。在TAP-C (Song et al., 2022)中,作者展示了CLIP (Radford et al., 2021) 可以作为VQA和视觉蕴涵任务的少样本学习器。对于VQA任务,作者将其重新定义为图像-文本检索任务;而对于视觉蕴涵任务,在训练中使用了标题和假设(文本-文本对),而在推理中使用了图像和假设(图像-文本对)。
零样本图像解释。训练大型VLP模型的一个重要优势是可以实现零样本泛化。在图像-文本任务中,尽管零样本检索可以通过在预训练过程中使用对比损失来轻松实现,但零样本图像字幕的评估很少见,主要是因为模型在网络规模噪声图像-文本对上进行了预训练,导致零样本性能较差。在SimVLM (Wang et al., 2022k) 和 FewVLM (Jin et al., 2022)中提供了对零样本字幕的定量评估,而LEMON (Hu et al., 2022) 和CM3 (Aghajanyan et al., 2022)提供了定性的视觉示例。通过在MAGIC (Su et al., 2022)和ZeroCap (Tewel et al., 2022)中讨论的CLIP和GPT-2的联合使用也可以实现零样本图像字幕。
3. 统一的图像-文本模型
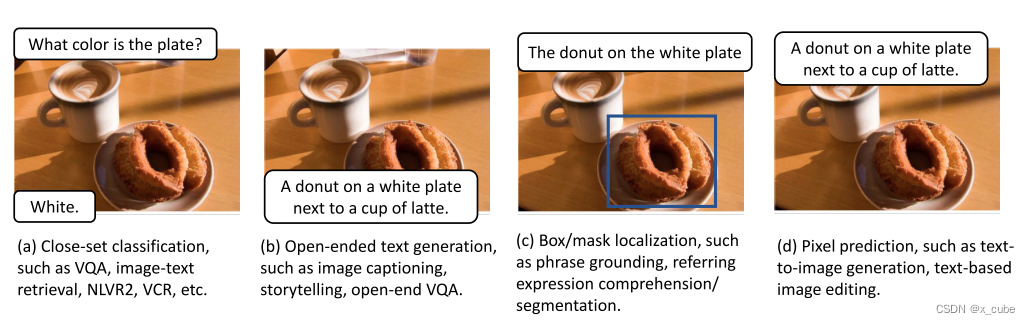
图像-文本任务大致可分为四类:
(i)封闭式分类,例如VQA、图像-文本检索和视觉推理;
(ii)开放式文本生成,例如图像描述、视觉叙事和自由开放式VQA;
(iii)框/掩蔽局部化,例如短语基础、引用表达理解/分割和基于场景的描述;
(iv)像素预测,例如文本-图像生成和基于文本的图像编辑。如何设计一个可以支持所有这些下游任务的统一的图像-文本模型成为一个越来越重要的话题。我们在下面简要总结了当前朝着这个目标努力的一些尝试。
- • 将图像-文本任务作为文本生成进行统一。VL-T5 (Cho等人,2021)借鉴了T5 (Raffel等人,2020)和BART (Lewis等人,2020a)的思想,提出使用序列到序列(seq2seq)编码器-解码器框架将不同的VL任务统一为文本生成,使得不同的任务可以直接支持而不需要引入特定任务的头部。由于预训练目标检测器被用于(预-)提取边界框及其相应的区域特征,因此在短语基础和引述表达理解中的框预测任务变成了一个区域索引分类问题。然而,模型不能进行端到端预训练的事实导致了下游性能的不佳。SimVLM (Wang等人,2022k)提出了一个简单的端到端seq2seq学习框架,将VQA视为文本生成任务,就像VL-T5一样,并进行大规模的预训练。
- • 将文本生成和框预测作为语言建模进行统一。上述方法已经将某些图像-文本任务(例如VQA、视觉推理和图像描述)统一为文本生成。然而,边界框坐标不能直接预测。通过将边界框坐标量化为离散标记,Pix2Seq (Chen等人,2022c)和Pix2SeqV2 (Chen等人,2022d)提出使用seq2seq框架将目标检测(OD)作为语言建模任务。在这一基础上,UniTAB (Yang等人,2021c)尝试将文本生成和边界框预测统一到单一的Transformer编码器-解码器架构中,通过使用一组离散标记表示每个边界框,使UniTAB能够使用一组参数处理不同的VL任务,同时生成所需的文本和框输出,并检测单词和框之间的对齐关系。
- • 将文本生成和图像生成作为语言建模进行统一。通过使用VQ-VAE (van den Oord等人,2017;Razavi等人,2019),图像也可以表示为一系列离散的图像标记。因此,图像生成可以自然地被视为一项语言建模任务。近期的工作,例如Taming Transformer (Esser等人,2021b)、DALL-E (Ramesh等人,2021)和Parti (Yu等人,2022b)已经展示了这种方法可以生成高质量逼真的图像。受此启发,最近的工作表明图像生成和文本生成(例如图像描述)可以统一,例如ERINE-ViLG张等人(2021a)、L-Verse (Kim等人,2022)和DU-VLG (Huang等人,2022)。此外,DaVinci (Diao等人,2022)将前缀图像建模任务和前缀语言建模(如SimVLM中使用的)相结合进行预训练。Aghajanyan等人(2022)推出CM3,这是一个在结构化多模态文档的大语料库上预训练的因果蒙版生成模型,可以包含文本和图像标记(从预训练的VQVAE-GAN中获得)。经过预训练后,作者展示了该模型可以在无条件、有条件的情况下生成图像,并学习在零-shot设置下执行图像描述任务。
- • 将文本生成、框预测和图像生成统一到一起。OFA (Wang等人,2022e)提出将文本生成、框预测和图像生成统一起来,通过结合Pix2Seq (Chen等人,2022c)和VQ-VAE (van den Oord等人,2017)的思想实现。利用相同的思路,Unified-IO (Lu等人,2022a)进一步支持多样化的模态,例如图像、掩蔽、关键点、边界框和文本以及多样化的任务,例如深度估计、修复、语义分割、字幕和阅读理解。但是,目前Unified-IO在下游任务中的表现不尽如人意。
- • 将定位和VL理解进行统一。将边界框序列化为标记序列可以设计一个统一的模型来处理所有任务而不需要引入特定任务的头部,这是非常吸引人的。然而,下游的目标检测(OD)性能要么没有被评估,要么仍然远远落后于最先进技术。还有另一种工作线路尝试将定位和VL理解进行统一,但仍然使用附加的OD头部来输出边界框。这包括GPV-1 (Gupta等人,2022a)、MDETR (Kamath等人,2021)、UniT (Hu和Singh,2021)、GLIPv2 (Zhang等人,2022b)和FIBER (Dou等人,2022a)。具体而言,GPV-1 (Gupta等人,2022a)和GPV-2 (Kamath等人,2022)提倡通用视觉系统的概念。MDETR (Kamath等人,2021)和GLIP (Li等人,2022h)提出将目标检测和短语基础统一为基于场景的预训练,这进一步启发了GLIPv2 (Zhang等人,2022b)将定位和VL理解进行统一。FIBER (Dou等人,2022a)提供了另一种解决方案,以处理定位和VL理解任务,通过设计一种新的融合于主干的结构和一种新的预训练策略来实现,即首先在图像-文本数据上进行粗粒度预训练,然后在图像-文本-框数据上进行细粒度预训练。
除了在一个框架内统一不同的任务外,还有关于设计统一Transformer的工作。例如,UFO (Wang等人,2021a)开发了一个可以灵活用作双重编码器和融合编码器的统一Transformer。VLMo (Wang等人,2021c)提出引入附加的模态专家,并且它的规模增大版本BEiT-3 (Wang等人,2022g)最近在VQA和其他VL任务上取得了最先进的结果。
4 . 知识
我们主要关注需要外部知识来正确回答问题的知识需求型VQA任务。以下,我们将讨论分为三个部分。
• 数据集。最早的显式知识型VQA数据集是KB-VQA (Wang等人,2017b)和FVQA (Wang等人,2017a)。然而,这些数据集中所需的知识都保留在用于生成数据集的知识图中。KVQA (Shah等人,2019b)基于维基百科文章中的图像。OK-VQA (Marino等人,2019)是一个最近流行的VQA数据集,需要使用外部的开放领域知识来回答给定输入图像的问题。最近,WebQA (Chang等人,2022)是使用网络查询收集的数据集,A-OKVQA (Schwenk等人,2022)是一个众包数据集,由一系列需要更广泛的常识和世界知识来回答的问题组成。
• 知识来源。知识源可以分为两类:(i)显式结构化符号知识库,例如维基百科、ConceptNet、WordNet和谷歌图像;以及(ii)隐式非结构化知识库,即大规模预训练的语言模型,如GPT-3 (Brown等人,2020),其中包含了丰富的百科全书和常识知识。
• 方法。大多数研究采用两步法来解决知识型VQA任务,即首先从外部资源中检索知识,然后对所选知识、输入图像和问题进行推理以进行答案预测。下面,我们主要讨论针对OK-VQA设计的方法。具体而言,Shevchenko等人(2021)提出使用知识嵌入构建知识库,然后将这些知识嵌入注入到VLP模型中。KRISP (Marino等人,2021)提出从预训练语言模型中检索存储的隐式知识作为结构化知识库的补充知识资源。MAVEx (Wu等人,2022c)提出了一种答案验证方法,以更好地利用噪声检索到的知识。最近,PICa (Yang等人,2022d)通过使用图像字幕和上下文少样本学习来促使GPT-3,展示了可以获得最先进的结果。这种方法在KAT (Gui等人,2022)中进一步增强,通过从显式知识库中检索知识来补充。
除了明确要求使用外部知识解决任务的知识型VQA之外,还存在一些模型,如ERINE-ViL 和ROSITA (Cui等人,2021),它们使用内嵌在场景图中的知识来提高标准VL任务 (如VQAv2和图像-文本检索) 的性能。通过在大规模的图像-文本数据上进行预训练,最近的GIT工作 (Wang等人,2022d)表明,关于视觉世界的丰富多模态知识已经编码在模型权重中,预训练的模型可以方便地识别场景中的文本、表格/图表、食物、标志、地标、角色、产品等,并在对TextCaps数据集 (Sidorov等人,2020)进行微调时以自然语言形式输出这些知识。关于知识密集型NLP任务的相关调查是Yin等人(2022)。
5. 稳健性与探索性分析
在大多数视觉语言预训练(VLP)的文献中,模型通常会在诸如VQAv2(Goyal et al., 2017b)、图像字幕、NLVR2(Suhr et al., 2019)、视觉蕴含(Xie et al., 2019)、图像文本检索、指代表达理解(Yu et al., 2018a)等标准基准数据集上进行评估。这些基准数据集推动了该领域的巨大进展(例如见图3.2),甚至一些大型VLP模型在某些任务上超越了人类表现。虽然这种进展是有意义且令人兴奋的,但我们不应仅关注排行榜的排名,而应避免过度宣称或低估模型所学能力(下面将详细讨论)。迄今为止,这些预训练模型的鲁棒性还不清楚。接下来,我们将从以下多个维度回顾鲁棒性分析的常见方法:(i) 诊断测试;(ii) 检验模型在分布之外的泛化能力的挑战性数据集;(iii) 人为对抗攻击;(iv) 探索性分析。
诊断测试。诊断测试旨在验证VLP模型的某一特定能力或某一特定类型的鲁棒性。例如,Li et al.(2020c)对基于OD的VLP模型进行了大量评估,包括:(i)通过VQA-Rephrasings(Shah et al., 2019a)对抗语言变异的鲁棒性;(ii)通过VQA-LOL(Gokhale et al., 2020)对抗逻辑推理的鲁棒性;(iii)通过IV-VQA和CV-VQA(Agarwal et al., 2020)对抗视觉内容操纵的鲁棒性。CLEVR(Johnson et al., 2017a)是一个用于测试组合视觉推理的诊断数据集。GQA(Hudson and Manning, 2019b)提供了大规模的基于规则的问题集,其中包含来自真实世界图像的场景图,用于测试VQA模型在位置推理和关系推理方面的能力。Winoground(Thrush et al., 2022)是一个精心策划的数据集,用于探测VLP模型在图像-文本匹配任务中的视觉语言组合性。此外,Parcalabescu等人(2020)还提出在计数任务中测试VL模型。Visual Commonsense Tests(ViComTe)数据集(Zhang et al., 2022a)旨在测试单模态(仅语言)和多模态(图像与语言)模型对广泛视觉显著属性的捕获程度。VALSE(Parcalabescu et al., 2021)旨在测试以语言现象为中心的VLP模型。CARET(Jimenez et al., 2022)旨在通过六项细粒度能力测试系统地衡量现代VQA模型的一致性和鲁棒性。
分布之外的泛化能力。通常,VL模型通过在与训练数据相同分布的未见数据上进行性能测量来评估其性能。然而,在实际部署VL系统时,这个假设是不成立的。一个最流行的用于测试VL模型分布之外泛化能力的VQA数据集是VQA-CP(Agrawal et al., 2018)。它是通过对VQAv2中的示例进行重新洗牌构建的。GQA-OOD(Kervadec et al., 2021)是在GQA数据集基础上改进的,旨在评估在分布内和分布外数据集上性能的差异。除了VQA,VLUE(Zhou et al., 2022d)还针对其他VL任务(包括图像文本检索、图像字幕和视觉定位)创建了分布之外的测试集。Gupta等人(2022b)引入了GRIT基准,旨在测试视觉系统在7个视觉和VL任务、多个数据源和不同概念上的性能、鲁棒性和校准。最近,Agrawal等人(2022)通过进行跨数据集评估,对现代VLP模型的分布之外泛化能力进行了全面研究。
人为对抗攻击。为了构建一个能够随着时间有机演化的基准,Li等人(2021b)、Sheng等人(2021)通过一种对抗的人机与模型的迭代过程(Nie et al., 2020)收集了对抗性VQA数据集。有趣的是,他们发现在数据集收集过程中,非专家标注者可以轻易地成功攻击现代VLP模型。这些VLP模型在新基准上的表现也远远低于在标准VQAv2数据集上的表现。最近,Bitton等人(2022)引入了WinoGAViL,这是一个在线游戏,用于收集VL关联,作为评估最先进VLP模型的动态基准。一方面,这些基准很有价值,因为它们成功地展示了SoTA VLP模型的弱点,并为社区中的鲁棒性研究提供了新的视角。另一方面,我们也需要小心,不要低估模型学习到的能力,因为这些数据集是特别收集用于欺骗这些模型。
探测性分析。除了在各种基准数据集上测试VLP模型的鲁棒性分析之外,还存在一系列工作旨在探索和理解VLP模型中所学内容(Cao et al., 2020; Li et al., 2020d; Salin et al., 2022),例如跨模态输入剔除测试(Frank et al., 2021)、动词理解(Hendricks and Nematzadeh, 2021)、偏差分析(Srinivasan and Bisk, 2022)以及在VLP模型中数据、注意力和损失角色的解耦(Hendricks et al., 2021)等等。
6. VL用于语言、模型压缩、多语言VLP及其他
语言视觉学习(VL)是一种利用图像和文本数据进行深度学习的方法。近年来,随着VLP模型(如CLIP和ALIGN)的出现,人们逐渐接受了这种方法的有效性。这些模型可以从零开始学习强大的图像编码器,并实现零样本图像分类能力。与此同时,人类语言的理解也离不开视觉知识,比如颜色、大小和形状等。因此一个自然的问题是,图像与文本数据是否也能够帮助更好地学习语言表示。
为了丰富学习到的语言表示,Vokenization和iACE提出了将图像与对应的标记拼接起来作为"voken"的方法。在VidLanKD中,作者通过视频蒸馏的知识传递方法来改善涉及世界知识、物理推理和时间推理等语言理解任务。VaLM则提出使用从CLIP中检索到的相关图像来增强文本标记,并使用视觉知识融合层实现多模态的基于视觉的语言建模。在模型压缩方面,MiniVLM研究了如何设计紧凑的视觉-语言模型,并提出使用高效低成本的离线对象检测器来替代常用的对象检测器。DistilVLM提出对VLP进行知识蒸馏。VL-Adapter和ladder side-tuning则提出了有效适应大型语言模型的方法。
多语言VLP是一个相对较少研究的领域。UC2和M3P提出添加多语言文本编码器,同时使用英语和多语种数据进行联合预训练。MURAL通过引入大量的翻译对扩展了ALIGN到多语种场景。CCLM介绍了一种跨语言跨模态的跨视图语言建模方法,具有优于英语VL模型的零样本跨语言转移能力。
在无监督的VLP中,Li et al.探索了在无平行图片-文本数据的情况下如何进行强化学习。他们提出在仅文本数据和仅图像数据上进行遮蔽建模预训练,并利用目标检测模型检测到的物体标签作为桥梁来连接两种模态。Zhou et al.认为仅使用标签是不够的,他们提出使用基于检索的方法构建弱对齐的图像-文本语料库,并应用一组多粒度对齐的预训练任务来缩小两种模态之间的差距。
"Socratic Models"是一种将不同领域基础模型以零样本或少样本方式进行组合的概念,用语言作为表示方式共同推理。PICa、MAGIC、BEST和PaLI等模型属于这一类别。
除了标准的VL任务,VLP还可以应用于TextVQA、TextCaps、visual dialog、时尚领域任务和视觉-语言导航等应用领域。
总而言之,VLP在各个领域都有广泛的应用和研究,涵盖了表示丰富性、模型压缩、多语言、无监督学习和Socratic Models等方面。
7. 图文生成
本章还没有涵盖的另一个重要的图文任务是文本到图像(T2I)生成,其目标是产生一张正确反映文本描述意思的图像,也可以看作是图像字幕生成的逆过程(Chen等人,2015)。在VLP出现之前,Mansimov等人(2016)是T2I生成的先驱工作,他们展示了循环变分自编码器可以生成条件于图像描述的新颖视觉场景,但是生成的图像质量不尽如人意。T2I生成的研究随着生成敌对网络的繁荣而得到极大发展。Reed等人(2016)将有条件的GAN推广到T2I生成,并已经证明可以在较小的图像分辨率(64x64)下使用受限数据集(例如Oxford-102花卉和CUB-200鸟类)。近年来,由于改进的多模态编码(例如StackGAN(Zhang等人,2017),StackGAN ++(Zhang等人,2018c))、新颖的注意力机制(例如AttnGAN(Xu等人,2018),SEGAN(Tan等人,2019),ControlGAN(Li等人,2019a))、循环结构的使用(例如MirrorGAN(Qiao等人,2019))等,该领域取得了显着进展。
为了将GAN的成功扩展到有限数据分区,通常会使用预训练,即通过在一些大型数据集上预训练的GAN模型初始化优化过程(Grigoryev等人,2022)。然而,大多数基于GAN的预训练仅针对图像数据集进行,没有利用用于视觉语言预训练(VLP)的图像-文本对,除了最近使用CLIP模型在基于GAN的方法中进行的工作(例如LAFITE(Zhou等人,2022f)),该方法证明了在不明确使用文本数据的情况下训练T2I生成模型的第一个工作。
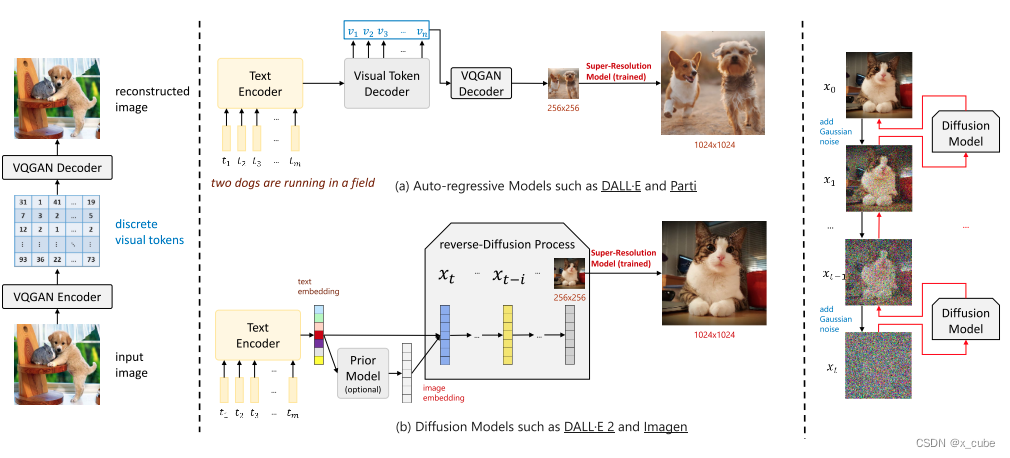
在VLP的背景下,虽然基于GAN的方法仍然流行于图像合成领域,但是T2I生成正在出现新的范式转变。在VLP的背景下,我们将这些方法分类为两类:(i)基于VQ-token的自回归方法(例如DALL-E(Ramesh等人,2021)和Parti(Yu等人,2022b)),以及(ii)基于扩散的方法(例如DALL-E 2(Ramesh等人,2022)和Imagen(Saharia等人,2022))。这些方法的示例如图3.11所示。以下是对这些最新工作的简要回顾。
7.1 基于VQ-token的自回归方法
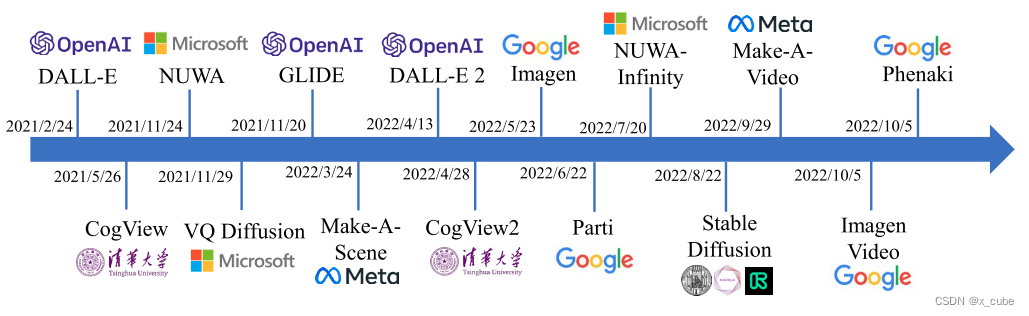
离散的Token表示。2017年,提出了VQ-VAE(van den Oord等,2017),它提供了一个简单而强大的生成模型,可以学习用于高质量图像重建的离散表示。随后,在VQ-VAE-2(Razavi等,2019)中,研究人员展示了可以生成高保真度和高分辨率图像。随着Transformer模型(Vaswani等,2017)的普及,该模型在语言模型(Devlin等,2019)和图像生成预训练(Chen等,2020b)等领域取得了令人印象深刻的改进,对于VQ token序列的建模也自然地由Transformer处理(Esser等,2021b)。 自回归建模。Transformer带来的这些最新进展为T2I生成提供了可能的途径,并有可能从大规模的VLP中受益。具体而言,DALL-E(Ramesh等,2021)证明了在大量图像-文本对上训练大规模自回归Transformer可以产生具有可控合成结果的高保真度生成模型。NUWA(Wu等,2022b)提出了一个统一的多模态预训练模型,可以借助3D Transformer编码器-解码器框架和3D近邻注意力(3DNA)机制生成或操作视觉数据(即图像和视频)。在NUWA-Inifinity(Wu等,2022a)中,作者进一步提出了一种自回归的过自回归生成方法,用于高分辨率无限视觉合成,能够生成任意宽高比的图像。Parti(Yu等,2022b)采用了类似的基于Transformer的编码器-解码器架构,并以规模方式训练模型,并展示了令人印象深刻的图像生成结果。Make-A-Scene(Gafni等,2022)建议在图像生成过程中使用附加的分割地图(可以生成或不生成)作为额外的输入,进一步辅助图像生成过程。其他例子包括CogView(Ding等,2021)和CogView2(Ding等,2022a),这也类似于DALL-E(Ramesh等,2021)。 双向的图文生成。ERINE-ViLG(Zhang等,2021a)、L-Verse(Kim等,2022)和OFA(Wang等,2022f)证明了可以进行大规模的生成式联合预训练,同时针对文本和图像标记(来自VQ-VAE)进行微调,用于多样的下游任务,例如风格学习(特定领域的文本到图像生成)、超分辨率(图像到图像)、图像字幕生成(图像到文本)甚至文本-图像检索等。
7.2 基于扩散的方法
连续扩散。最近,扩散模型,如去噪扩散概率模型(DDPM)(Ho等,2020),在图像生成任务中取得了巨大的成功。最近的研究(Dhariwal和Nichol,2021)表明,与基于VQ-token的模型和GAN相比,图像合成的质量更高。此外,最新的去噪扩散隐式模型(DDIM)(Song等,2021)进一步加速了采样过程,并实现了几乎完美的反演。关于扩散模型的全面调查,请参阅Yang等人的论文(2022c)。 为了将基于扩散的方法扩展到T2I生成,GLIDE(Nichol等,2021)采用了连续扩散,并比较了扩散模型中的CLIP引导和无分类器引导,并得出结论:在人类评估方面,具有35亿参数且无分类器引导的扩散模型优于DALL-E。最近,DALL-E 2(Ramesh等,2022)、Imagen(Saharia等,2022)和稳定扩散(Latent Diffusion的一个放大版本)(Rombach等,2022)将这一领域推向了一个新的水平,尤其是稳定扩散的开源工作。Latent Diffusion模型(Rombach等,2022)提议在连续潜变空间中进行扩散,而不是像DALL-E 2(Ramesh等,2022)和Imagen(Saharia等,2022)中那样在像素空间中进行扩散。 离散扩散。通过结合VQ-token-based和基于扩散的方法,最近的研究,如ImageBART(Esser等,2021a)和VQ-Diffusion(Gu等,2022c),提出通过使用条件化的DDPM的参数模型来对VQ-VAE(Razavi等,2019)的潜变离散编码空间进行建模,用于T2I生成的任务。 文本到视频生成。领域正在以飞快的速度发展。近期的研究不仅满足于文本到图像生成,如Make-A-Video(Singer等,2022)、Imagen Video(Ho等,2022)和Phenaki(Villegas等,2022)大大提升了文本到视频生成的质量,达到了一个新的水平。
参考:Vision-Language Pre-training: Basics, Recent Advances, and Future Trends