概述
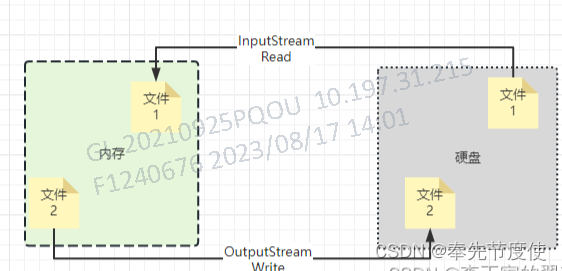
- I/O表示Input/Output,即数据传输过程中的输入/输出,并且输入和输出都是相对于内存来讲
- Java IO(输入/输出)流是Java用于处理数据读取和写入的关键组件
- 常见的I|O介质包括
- 文件(输入|输出)
- 网络(输入|输出)
- 键盘(输出)
- 显示器(输出)
- 使用场景
- 文件拷贝(File)
- 文件上传下载
- Excel导入导出
- 网络程序中数据传输(聊天工具)
分类
概述
Java中几乎所有的IO操作都需要使用java.io包;流可以通过如下方式进行分类
- 按流向分(输入输出过程通常都是站在程序角度考虑)
- 输入流(Input)
- 输出流(Output)
- 按流的处理类型分
- 字节流(byte): 字节是计算机存储容量的基本单位(Byte),1B=8b,二进制中占8位
- 字符流(char): 字符是文字或符号的统称
注意:字节流对于什么类型的文件都可以读取,如二进制类型的文件(图片,视频,音频,压缩 文件等),而字符流用于读取文本类型文件
- 按流的功能来分
- 节点流(直接跟输入输出源交互)
- 处理流(对其他流包装的流:包装流)
字节流(InputStream && OutputStream)
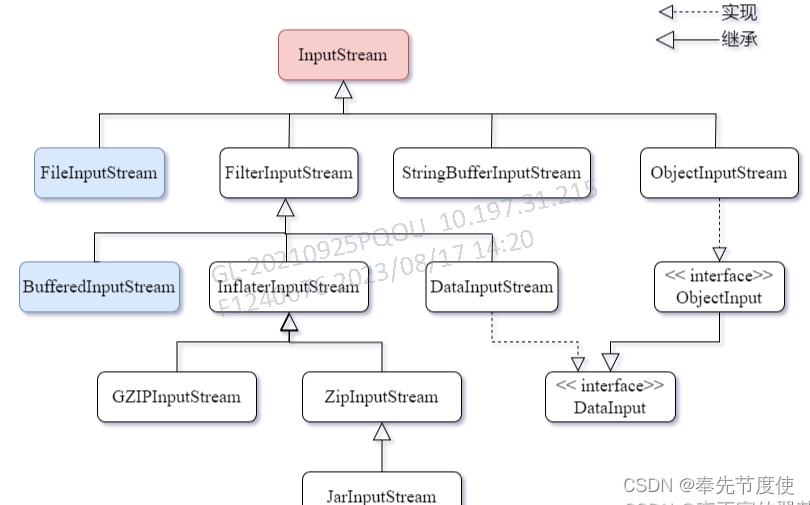
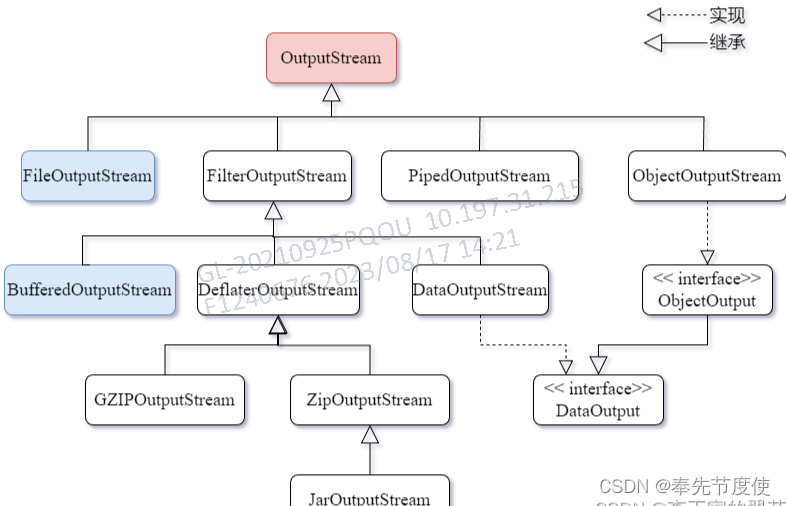
日常开发过程中常用的字节流:
FileInputStream && FileOutputStream: 常用来实现文件复制/拷贝
BufferedInputStream && BufferedOutputStream: 为了减少IO次数,提高读取效率
PrintStream:源自OutputStream,标准字节的打印输出流(日志框架的实现原理)
ZipOutputStream && ZipInputStream:用来进行文件压缩/文件解压
字符流(Reader && Writer)
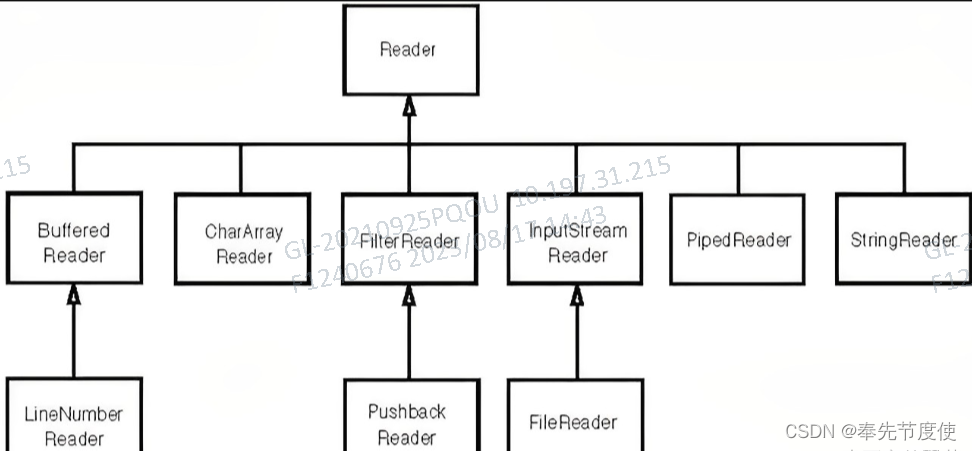
日常开发过程中常用的字符流:
FileReader&&FileWriter:作用同FileInputStream && FileOutputStream
BufferedReader&&BufferedWriter:作用同BufferedInputStream && BufferedOutputStream,同时BufferedReader提供了按行读取文本的方法,方便文本处理
扩展: 我们知道字节流可以读取任意文件,为什么还要设计出字符流呢?
- 对于字符文件,先作为字节传输->再转成字符,比较耗时
- 对于字符文件,如果其中为中文,则容易乱码
设计模式
在IO流中使用了多种设计模式,包括如下:
适配器模式
适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
Java IO中为了实现字符流和字节流之间的相互转换,设计了两个适配器的类,
InputStreamReader和OutputStreamWriter
InputStreamReader isr = new InputStreamReader(new FileInputStream(fileName), "UTF-8");
BufferedReader bufferedReader = new BufferedReader(isr);
装饰器模式
装饰器模式可以将新功能动态地附加于现有对象而不改变现有对象的功能。InputStream的子类FilterInputStream,OutputStream 的子类 FilterOutputStream,Reader 的子类 BufferedReader 以及 FilterReader,还有Writer的子类BufferedWriter、FilterWriter 以及 PrintWriter等,它们都是抽象装饰类。增强了子类对象的功能。
实践
ZipOutputStream&&FileOutputStream&&FileInputStream实现文件压缩
/**
* 功能: 通过ZipOutputStream压缩文件,最后返回压缩包
* @param files
* @param fileName
* @return
*/
public File zipFiles(File[] files,String fileName) {
File zipFile = null;
FileOutputStream fosZipFile = null;
ZipOutputStream zosZipFile = null; //压缩文件输出流
try {
zipFile = downloadAttachmentService.createFile("", fileName); //创建一个空的文件目录
fosZipFile = new FileOutputStream(zipFile); //以文件流从内存中输出
zosZipFile = new ZipOutputStream(fosZipFile); //以压缩流从内存中输出
for (File file : files) {
FileInputStream fis = new FileInputStream(file); //对每个文件创建输入流,读取文件到内存
ZipEntry zipEntry = new ZipEntry(file.getName()); //ZipEntry用来创建压缩文件
zosZipFile.putNextEntry(zipEntry); //加入需要压缩的文件
byte[] bytes = new byte[1024];
int length;
while((length = fis.read(bytes)) >= 0) { //读取文件到内存
zosZipFile.write(bytes, 0, length); //文件写入压缩流
}
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
} finally { //关闭流
try {
zosZipFile.close();
fosZipFile.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return zipFile; //返回压缩包
}
/**
* @Title: createFile
* @Description: 创建下载目录文件
* @author Bierce
* @param rootPath
* @param filename
* @return
* @throws IOException
*/
public File createFile(String rootPath, String filename) throws IOException {
// Default root path
if (rootPath.isEmpty()) {
rootPath = "download-cache";
}
File fRoot = new File(rootPath);
if (!fRoot.exists() || !fRoot.isDirectory()) {
fRoot.mkdirs();
}
// job sub path
String uuid = UUID.randomUUID().toString();
String directoryJob = rootPath + File.separator + getClass().getSimpleName() + File.separator + uuid;//文件名称随机生成保证唯一
File dirJob = new File(directoryJob);
if (!dirJob.exists() || !dirJob.isDirectory()) {
dirJob.mkdirs();
}
String filePath = directoryJob + File.separator + filename;
File file = new File(filePath);
if (!file.exists()) {
file.createNewFile();
}
return file;
}
//-----------------扩展方法-文件名去重保证唯一-----------------
/**
* @Title: snFileName_noUIID
* @Description: 去除sn文件UUID以及解决sn文件名重复问题
* @author Bierce
* @return file
*/
public File snFileName_noUIID(String fileParentPath,String snFileName,File file){
//snFileName:完整文件名 sn-xx..UUID..xx.xlsx
//snFileName_delUIID: sn.xlsx
//snFileName_prefix: sn
//suffix:xlsx
//文件名:如sn.xlsx
String snFileName_delUIID = snFileName.substring(0,snFileName.length() - 42) + ".xlsx";//42是固定长度:UUID+.xlsx
String snFileName_prefix = snFileName.substring(0,snFileName.length() - 42);//文件前缀
String suffix = snFileName.substring(snFileName.lastIndexOf("."));//文件后缀:.xlsx
try {
file = new File(fileParentPath + snFileName_delUIID);//设置sn文件所在目录为计划交接文件目录下
int i = 1;
//对于同名SN文件情况重新命名
while(file.exists()) {//保证文件夹下不存在同名文件
String newFileName = snFileName_prefix + "(" + i + ")" + suffix;
String parentPath = file.getParent();
file = new File(parentPath + File.separator + newFileName);
i++;
}
file.createNewFile();//new File 只是创建了一个File对象,还需要调用createNewFile()方法才能实现文件的成功创建
} catch (Exception e) {
}
return file;
}