一:介绍
将YOLOv5结合分割任务并进行TensorRT部署,是一项既具有挑战性又令人兴奋的任务。分割(Segmentation)任务要求模型不仅能够检测出目标的存在,还要精确地理解目标的边界和轮廓,为每个像素分配相应的类别标签,使得计算机能够对图像进行更深入的理解和解释。而TensorRT作为一种高性能的深度学习推理引擎,能够显著加速模型的推理过程,为实时应用提供了强大的支持。
在本文中,我们将探讨如何将YOLOv5与分割任务相结合,实现同时进行目标检测和像素级别的语义分割。我们将详细介绍模型融合的技术和步骤,并深入讨论如何利用TensorRT对模型进行优化,以实现在嵌入式设备和边缘计算环境中的高效部署。通过阐述实验结果和性能指标,我们将展示这一方法的有效性和潜力,为读者带来关于结合YOLOv5、分割任务和TensorRT部署的全面认识。
二:python
- 打开pycharm,终端输入pip install labelme
- 为了方便我们之后标注的工作,需要打开C盘->用户->用户名->.labelmerc文件
 打开之后,将第一行的auto_save改为true,方便标框需要将create_polygon改为W,方便修改标注框将edit_polygon改为J
打开之后,将第一行的auto_save改为true,方便标框需要将create_polygon改为W,方便修改标注框将edit_polygon改为J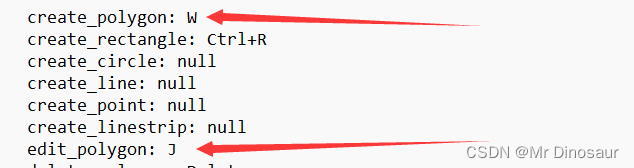
- 下载结束后,pycharm终端输入labelme,打开你数据集的文件夹,进行标注即可,这里不放图片演示了
- 标注完之后我们需要将json文件转换为txt文件,下面放上所需要的代码
import json import os import argparse from tqdm import tqdm def convert_label_json(json_dir, save_dir, classes): json_paths = os.listdir(json_dir) classes = classes.split(',') for json_path in tqdm(json_paths): # for json_path in json_paths: path = os.path.join(json_dir, json_path) with open(path, 'r') as load_f: json_dict = json.load(load_f) h, w = json_dict['imageHeight'], json_dict['imageWidth'] # save txt path txt_path = os.path.join(save_dir, json_path.replace('json', 'txt')) txt_file = open(txt_path, 'w') for shape_dict in json_dict['shapes']: label = shape_dict['label'] label_index = classes.index(label) points = shape_dict['points'] points_nor_list = [] for point in points: points_nor_list.append(point[0] / w) points_nor_list.append(point[1] / h) points_nor_list = list(map(lambda x: str(x), points_nor_list)) points_nor_str = ' '.join(points_nor_list) label_str = str(label_index) + ' ' + points_nor_str + '\n' txt_file.writelines(label_str) if __name__ == "__main__": """ python json2txt_nomalize.py --json-dir my_datasets/color_rings/jsons --save-dir my_datasets/color_ringsts --classes "cat,dogs" """ parser = argparse.ArgumentParser(description='json convert to txt params') parser.add_argument('--json-dir', type=str, default=r'json', help='json path dir') parser.add_argument('--save-dir', type=str, default=r'txt',help='txt save dir') parser.add_argument('--classes', type=str,default="1", help='classes') args = parser.parse_args() json_dir = args.json_dir save_dir = args.save_dir classes = args.classes convert_label_json(json_dir, save_dir, classes) -
转换为txt文件后,划分一下数据集,进行训练(此步骤有手就行,在此不演示了)
-
将你训练得到的best.pt通过gen_wts.py转换为wts文件,为了方便操作,将best.pt放入目录下,终端输入:python gen_wts.py -w best.pt

gen_wts.py的代码如下
import sys import argparse import os import struct import torch from utils.torch_utils import select_device def parse_args(): parser = argparse.ArgumentParser(description='Convert .pt file to .wts') parser.add_argument('-w', '--weights', required=True, help='Input weights (.pt) file path (required)') parser.add_argument( '-o', '--output', help='Output (.wts) file path (optional)') parser.add_argument( '-t', '--type', type=str, default='detect', choices=['detect', 'cls'], help='determines the model is detection/classification') args = parser.parse_args() if not os.path.isfile(args.weights): raise SystemExit('Invalid input file') if not args.output: args.output = os.path.splitext(args.weights)[0] + '.wts' elif os.path.isdir(args.output): args.output = os.path.join( args.output, os.path.splitext(os.path.basename(args.weights))[0] + '.wts') return args.weights, args.output, args.type pt_file, wts_file, m_type = parse_args() print(f'Generating .wts for {m_type} model') # Initialize device = select_device('cpu') # Load model print(f'Loading {pt_file}') model = torch.load(pt_file, map_location=device) # load to FP32 model = model['ema' if model.get('ema') else 'model'].float() if m_type == "detect": # update anchor_grid info anchor_grid = model.model[-1].anchors * model.model[-1].stride[..., None, None] # model.model[-1].anchor_grid = anchor_grid delattr(model.model[-1], 'anchor_grid') # model.model[-1] is detect layer # The parameters are saved in the OrderDict through the "register_buffer" method, and then saved to the weight. model.model[-1].register_buffer("anchor_grid", anchor_grid) model.model[-1].register_buffer("strides", model.model[-1].stride) model.to(device).eval() print(f'Writing into {wts_file}') with open(wts_file, 'w') as f: f.write('{}\n'.format(len(model.state_dict().keys()))) for k, v in model.state_dict().items(): vr = v.reshape(-1).cpu().numpy() f.write('{} {} '.format(k, len(vr))) for vv in vr: f.write(' ') f.write(struct.pack('>f', float(vv)).hex()) f.write('\n')
三、TensorRT
- 下载与YOLOv5-7.0对应的tensorrt分割版本wang-xinyu/tensorrtx: Implementation of popular deep learning networks with TensorRT network definition API (github.com)
- 使用cmake解压,嫌麻烦直接自己配置也行
- TensorRT的配置我之前文章里面有写,不清楚的可以去看一下Windows YOLOv5-TensorRT部署_tensorrt在windows部署_Mr Dinosaur的博客-CSDN博客
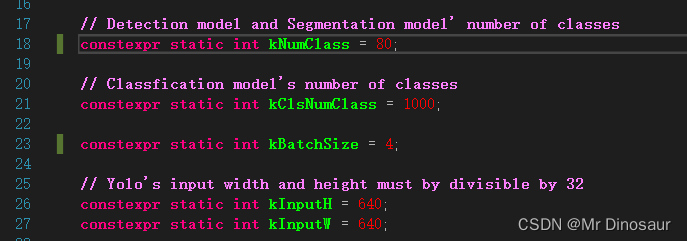
- 打开config.h,修改一下自己的检测类别和图片大小
- 打开yolov5_seg.cpp,找到主函数进行文件路径修改

- 如果你显源码运行麻烦(我就是),当然也可以自行修改去生成它的engine引擎文件,引擎文件生成后即可进行分割测试

- 分割结果
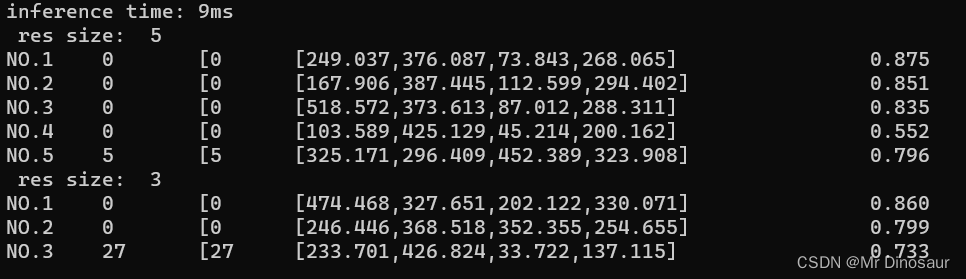 推理速度一般吧,比检测要慢一些
推理速度一般吧,比检测要慢一些


四、总结
- 部署的话基本就这些操作,可以将接口进行封装,方便之后调用,需要的话我之后再更新吧
- 分割的速度要比检测慢了快有10ms左右,对速度有要求的话需要三思
- 分割对大目标比较友好,如果你想检测小目标的话还是使用目标检测吧
半年多没更新了,对粉丝们说声抱歉,之后会不定时进行更新!