原文出处:https://www.yii666.com/blog/393941.html
什么是Milvus
Milvus 是一款云原生向量数据库,它具备高可用、高性能、易拓展的特点,用于海量向量数据的实时召回。
Milvus 基于 FAISS、Annoy、HNSW 等向量搜索库构建,核心是解决稠密向量相似度检索的问题。在向量检索库的基础上,Milvus 支持数据分区分片、数据持久化、增量数据摄取、标量向量混合查询、time travel 等功能,同时大幅优化了向量检索的性能,可满足任何向量检索场景的应用需求。通常,建议用户使用 Kubernetes 部署 Milvus,以获得最佳可用性和弹性。
Milvus 采用共享存储架构,存储计算完全分离,计算节点支持横向扩展。从架构上来看,Milvus 遵循数据流和控制流分离,整体分为了四个层次,分别为接入层(access layer)、协调服务(coordinator service)、执行节点(worker node)和存储层(storage)。各个层次相互独立,独立扩展和容灾。
为什么需要Milvus
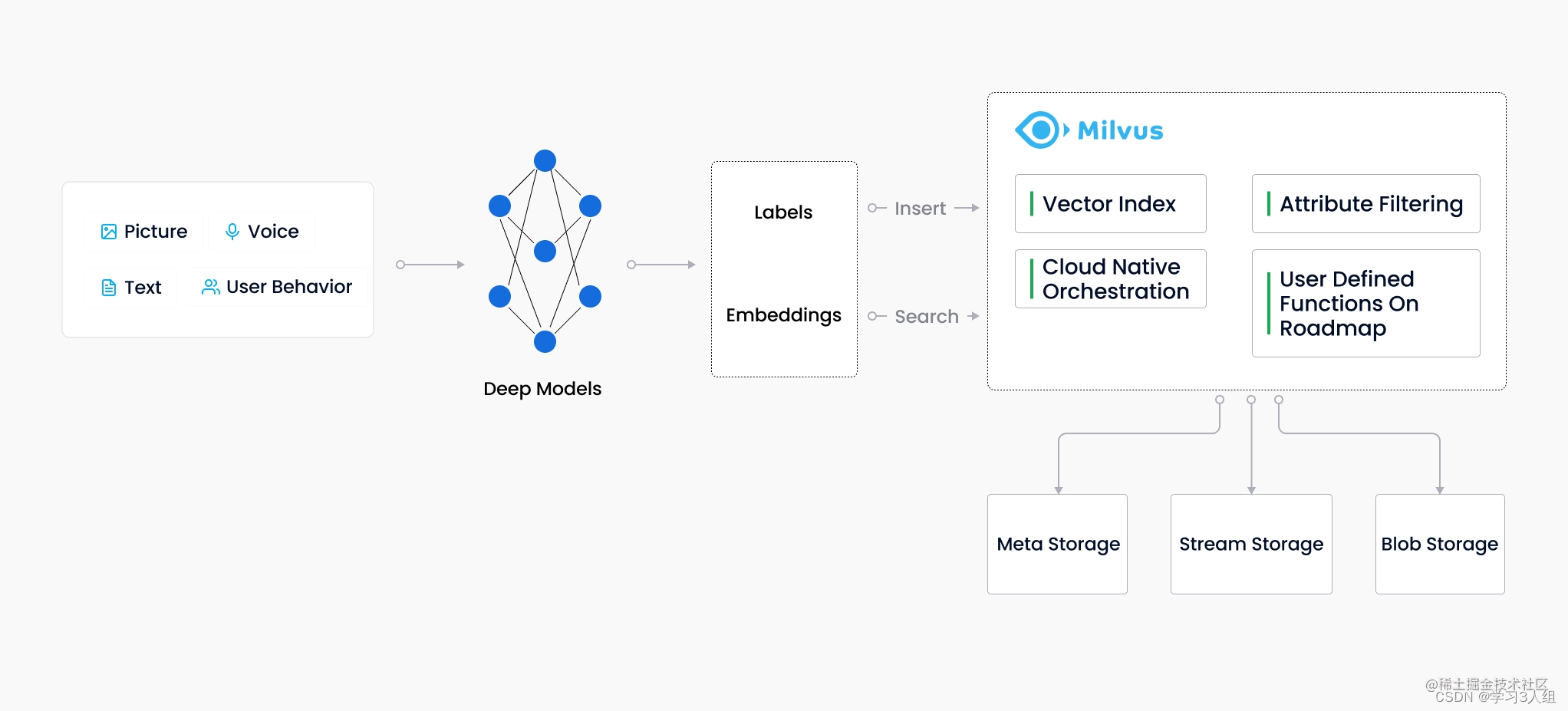
随着互联网不断发展,电子邮件、论文、物联网传感数据、社交媒体照片、蛋白质分子结构等非结构化数据已经变得越来越普遍。如果想要使用计算机来处理这些数据,需要使用 embedding 技术将这些数据转化为向量。随后,Milvus 会存储这些向量,并为其建立索引。Milvus 能够根据两个向量之间的距离来分析他们的相关性。如果两个向量十分相似,这说明向量所代表的源数据也十分相似。
Milvus 向量数据库专为向量查询与检索设计,能够为万亿级向量数据建立索引。
与现有的主要用作处理结构化数据的关系型数据库不同,Milvus 在底层设计上就是为了处理由各种非结构化数据转换而来的 Embedding 向量而生。网址:yii666.com
为什么选择使用 Milvus
高性能:性能高超,可对海量数据集进行向量相似度检索。
高可用、高可靠:Milvus 支持在云上扩展,其容灾能力能够保证服务高可用。
混合查询:Milvus 支持在向量相似度检索过程中进行标量字段过滤,实现混合查询。
开发者友好:支持多语言、多工具的 Milvus 生态系统。
Milvus基本概念
非结构化数据
非结构化数据指的是数据结构不规则,没有统一的预定义数据模型,不方便用数据库二维逻辑表来表现的数据。
非结构化数据包括图片、视频、音频、自然语言等,占所有数据总量的 80%。
非结构化数据的处理可以通过各种人工智能(AI)或机器学习(ML)模型转化为向量数据后进行处理。
特征向量
向量又称为 embedding vector,是指由 embedding 技术从离散变量(如图片、视频、音频、自然语言等各种非结构化数据)转变而来的连续向量。
在数学表示上,向量是一个由浮点数或者二值型数据组成的 n 维数组。
通过现代的向量转化技术,比如各种人工智能(AI)或者机器学习(ML)模型,可以将非结构化数据抽象为 n 维特征向量空间的向量。这样就可以采用最近邻算法(ANN)计算非结构化数据之间的相似度。
向量相似度检索
相似度检索是指将目标对象与数据库中数据进行比对,并召回最相似的结果。同理,向量相似度检索返回的是最相似的向量数据。
近似最近邻搜索(ANN)算法能够计算向量之间的距离,从而提升向量相似度检索的速度。如果两条向量十分相似,这就意味着他们所代表的源数据也十分相似。
Collection
包含一组 entity,可以等价于关系型数据库系统(RDBMS)中的表。
Entity
包含一组 field。field 与实际对象相对应。field 可以是代表对象属性的结构化数据,也可以是代表对象特征的向量。primary key 是用于指代一个 entity 的唯一值。
注意: 你可以自定义 primary key,否则 Milvus 将会自动生成 primary key。请注意,目前 Milvus 不支持 primary key 去重,因此有可能在一个 collection 内出现 primary key 相同的 entity。
Field
Entity 的组成部分。Field 可以是结构化数据,例如数字和字符串,也可以是向量。
注意:网址:yii666.com<
Milvus 2.0 现已支持标量字段过滤。并且,Milvus 2.0在一个集合中只支持一个主键字段。
Milvus与关系型数据库的对应关系如下:
| Milvus向量数据库 | 关系型数据库 |
|---|---|
| Collection | 表 |
| Entity | 行 |
| Field | 表字段 |
Partition
分区是集合(Collection)的一个分区。Milvus 支持将收集数据划分为物理存储上的多个部分。这个过程称为分区,每个分区可以包含多个段。
Segment
Milvus 在数据插入时,通过合并数据自动创建的数据文件。一个 collection 可以包含多个 segment。一个 segment 可以包含多个 entity。在搜索中,Milvus 会搜索每个 segment,并返回合并后的结果。
Sharding
Shard 是指将数据写入操作分散到不同节点上,使 Milvus 能充分利用集群的并行计算能力进行写入。默认情况下,单个 Collection 包含 2 个分片(Shard)。目前 Milvus 采用基于主键哈希的分片方式,未来将支持随机分片、自定义分片等更加灵活的分片方式。
注意: 分区的意义在于通过划定分区减少数据读取,而分片的意义在于多台机器上并行写入操作。文章来源地址https://www.yii666.com/blog/393941.html
索引
索引基于原始数据构建,可以提高对 collection 数据搜索的速度。Milvus 支持多种索引类型。为提高查询性能,你可以为每个向量字段指定一种索引类型。目前,一个向量字段仅支持一种索引类型。切换索引类型时,Milvus 自动删除之前的索引。文章地址https://www.yii666.com/blog/393941.html
相似性搜索引擎的工作原理是将输入的对象与数据库中的对象进行比较,找出与输入最相似的对象。索引是有效组织数据的过程,极大地加速了对大型数据集的查询,在相似性搜索的实现中起着重要作用。对一个大规模向量数据集创建索引后,查询可以被路由到最有可能包含与输入查询相似的向量的集群或数据子集。在实践中,这意味着要牺牲一定程度的准确性来加快对真正的大规模向量数据集的查询。
PChannel
PChannel 表示物理信道。每个 PChannel 对应一个日志存储主题。默认情况下,将分配一组 256 个 PChannels 来存储记录 Milvus 集群启动时数据插入、删除和更新的日志。文章来源地址:https://www.yii666.com/blog/393941.html
VChannel
VChannel 表示逻辑通道。每个集合将分配一组 VChannels,用于记录数据的插入、删除和更新。VChannels 在逻辑上是分开的,但在物理上共享资源。
Milvus 系统架构
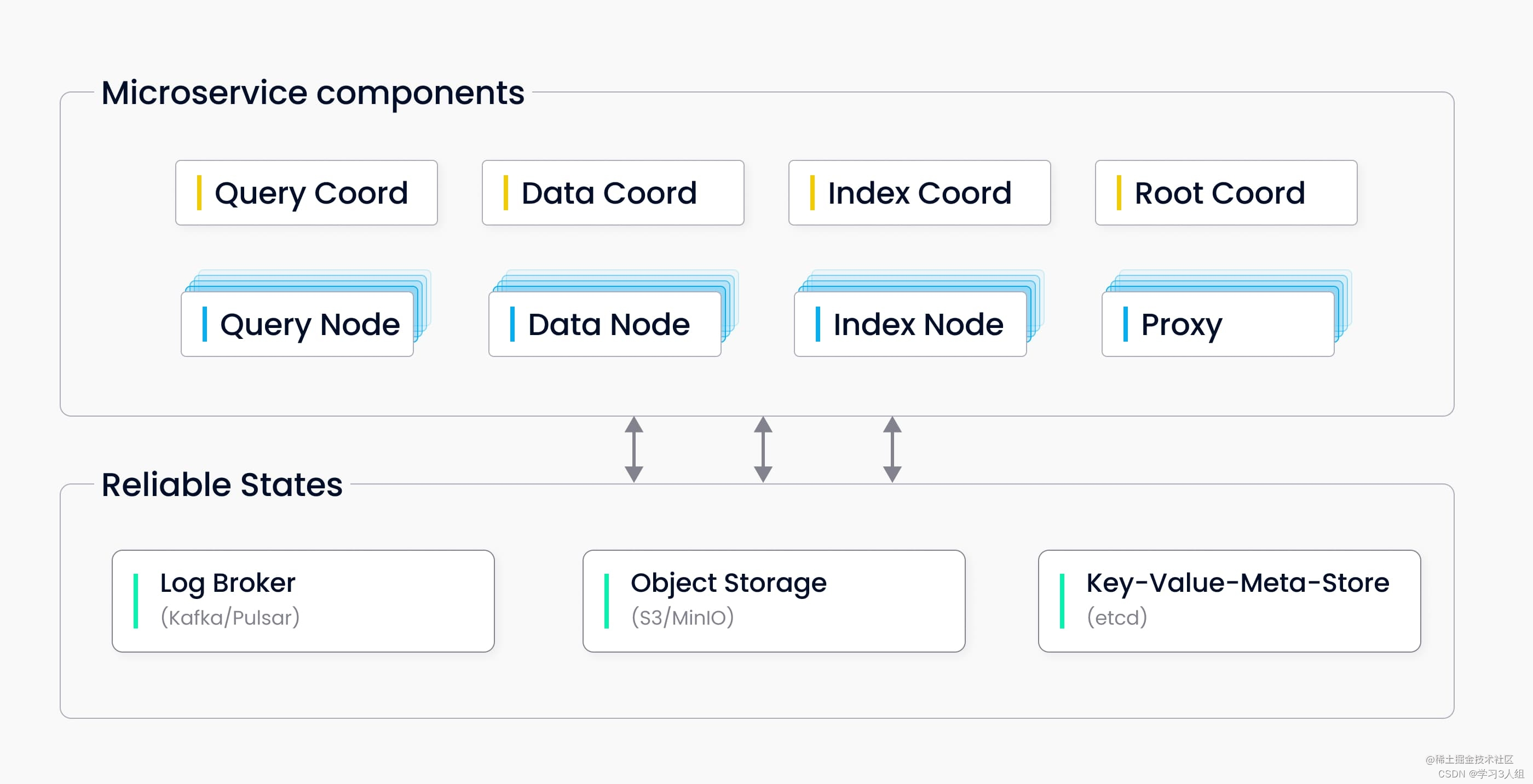
Milvus 2.0 是一款云原生向量数据库,采用存储与计算分离的架构设计,所有组件均为无状态组件,极大地增强了系统弹性和灵活性。
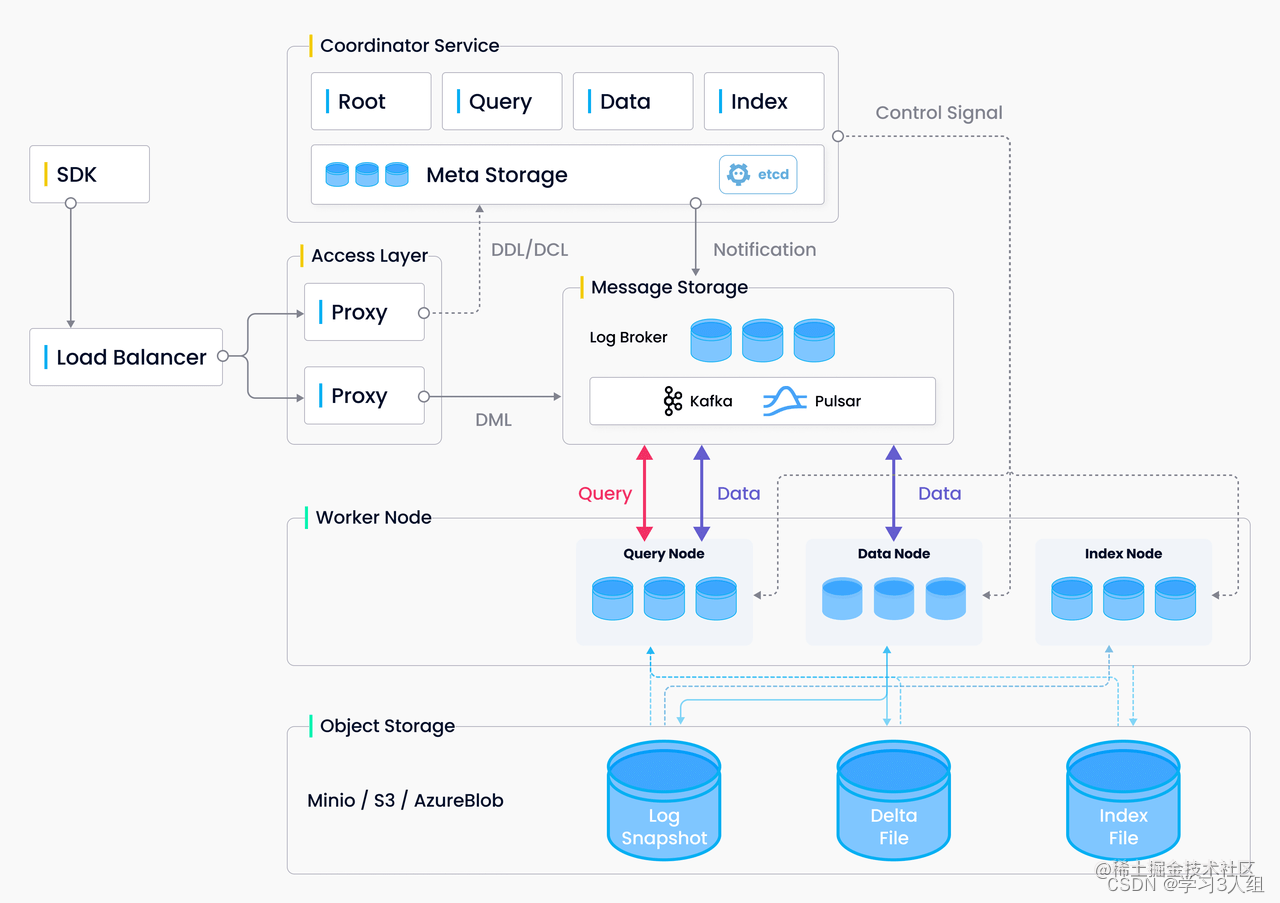
整个系统分为四个层次:
接入层(Access Layer):系统的门面,由一组无状态 proxy 组成。对外提供用户连接的 endpoint,负责验证客户端请求并合并返回结果。
协调服务(Coordinator Service):系统的大脑,负责分配任务给执行节点。协调服务共有四种角色,分别为 root coord、data coord、query coord 和 index coord。
执行节点(Worker Node):系统的四肢,负责完成协调服务下发的指令和 proxy 发起的数据操作语言(DML)命令。执行节点分为三种角色,分别为 data node、query node 和 index node。
存储服务 (Storage): 系统的骨骼,负责 Milvus 数据的持久化,分为元数据存储(meta store)、消息存储(log broker)和对象存储(object storage)三个部分。
各个层次相互独立,独立扩展和容灾。
接入层
接入层由一组无状态 proxy 组成,是整个系统的门面,对外提供用户连接的 endpoint。接入层负责验证客户端请求并减少返回结果。
Proxy 本身是无状态的,一般通过负载均衡组件(Nginx、Kubernetes Ingress、NodePort、LVS)对外提供统一的访问地址并提供服务。
由于 Milvus 采用大规模并行处理(MPP)架构,proxy 会先对执行节点返回的中间结果进行全局聚合和后处理后,再返回至客户端。
协调服务
协调服务是系统的大脑,负责向执行节点分配任务。它承担的任务包括集群拓扑节点管理、负载均衡、时间戳生成、数据声明和数据管理等。
协调服务共有四种角色:
Root coordinator(root coord):负责处理数据定义语言(DDL)和数据控制语言(DCL)请求。比如,创建或删除 collection、partition、index 等,同时负责维护中心授时服务 TSO 和时间窗口的推进。
Query coordinator (query coord):负责管理 query node 的拓扑结构和负载均衡以及从增长的 segment 移交切换到密封的 segment。
Data coordinator (data coord):负责管理 data node 的拓扑结构,维护数据的元信息以及触发 flush、compact 等后台数据操作。
Index coordinator (index coord):负责管理 index node 的拓扑结构,构建索引和维护索引元信息。
执行节点
执行节点是系统的四肢,负责完成协调服务下发的指令和 proxy 发起的数据操作语言(DML)命令。
由于采取了存储计算分离,执行节点是无状态的,可以配合 Kubernetes 快速实现扩缩容和故障恢复。
执行节点分为三种角色:
Query node: Query node 通过订阅消息存储(log broker)获取增量日志数据并转化为 growing segment,基于对象存储加载历史数据,提供标量+向量的混合查询和搜索功能。
Data node: Data node 通过订阅消息存储获取增量日志数据,处理更改请求,并将日志数据打包存储在对象存储上实现日志快照持久化。
Index node: Index node 负责执行索引构建任务。Index node不需要常驻于内存,可以通过 serverless 的模式实现。
存储服务
存储服务是系统的骨骼,负责 Milvus 数据的持久化,分为元数据存储(meta store)、消息存储(log broker)和对象存储(object storage)三个部分。
元数据存储
负责存储元信息的快照,比如:集合 schema 信息、节点状态信息、消息消费的 checkpoint 等。元信息存储需要极高的可用性、强一致和事务支持,因此,etcd 是这个场景下的不二选择。除此之外,etcd 还承担了服务注册和健康检查的职责。
对象存储
负责存储日志的快照文件、标量/向量索引文件以及查询的中间处理结果。Milvus 采用 MinIO 作为对象存储,另外也支持部署于 AWS S3 和Azure Blob 这两大最广泛使用的低成本存储。但是,由于对象存储访问延迟较高,且需要按照查询计费,因此 Milvus 未来计划支持基于内存或 SSD 的缓存池,通过冷热分离的方式提升性能以降低成本。
消息存储
消息存储是一套支持回放的发布订阅系统,用于持久化流式写入的数据,以及可靠的异步执行查询、事件通知和结果返回。执行节点宕机恢复时,通过回放消息存储保证增量数据的完整性。
目前,分布式版Milvus依赖 Pulsar 作为消息存储,单机版Milvus依赖 RocksDB 作为消息存储。消息存储也可以替换为 Kafka、Pravega 等流式存储。
整个 Milvus 围绕日志为核心来设计,遵循日志即数据的准则,因此在 2.0 版本中没有维护物理上的表,而是通过日志持久化和日志快照来保证数据的可靠性。
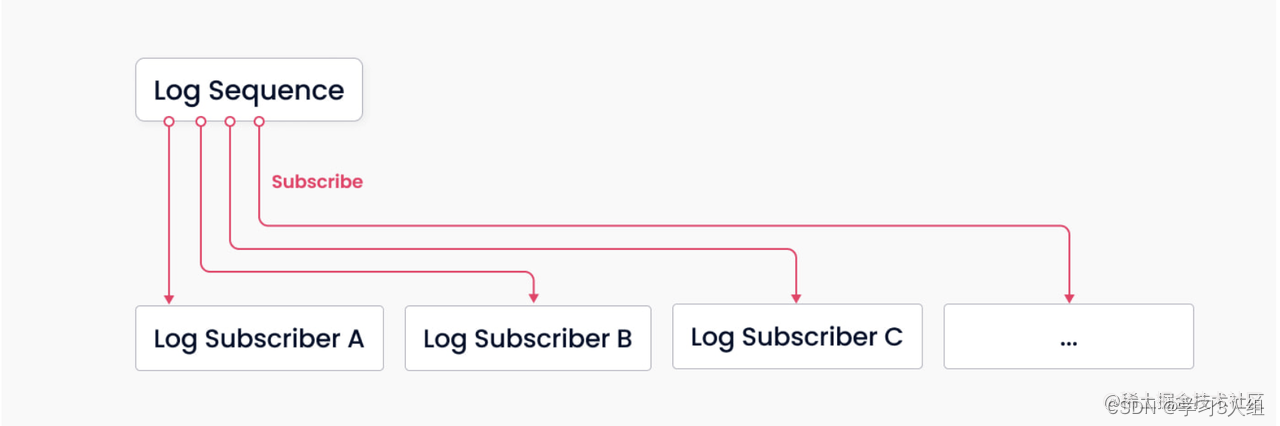
日志系统作为系统的主干,承担了数据持久化和解耦的作用。通过日志的发布订阅机制,Milvus 将系统的读、写组件解耦。一个极致简化的模型如上图所示,整个系统主要由两个角色构成,分别是消息存储(log broker)(负责维护”日志序列“)与“日志订阅者”。其中的“日志序列”记录了所有改变库表状态的操作,“日志订阅者”通过订阅日志序列更新本地数据,以只读副本的方式提供服务。 发布订阅机制还为系统在变更数据捕获(CDC)和全面的分布式部署方面的可扩展性提供了空间。
Milvus 主要的组件
Milvus 支持两种部署模式,单机模式(standalone)和分布式模式(cluster)。两种模式具备完全相同的能力,用户可以根据数据规模、访问量等因素选择适合自己的模式。Standalone 模式部署的 Milvus 暂时不支持在线升级为 cluster 模式。
单机版 Milvus
单机版 Milvus 包括三个组件:
Milvus 负责提供系统的核心功能。
etcd 是元数据引擎,用于管理 Milvus 内部组件的元数据访问和存储,例如:proxy、index node 等。
MinIO 是存储引擎,负责维护 Milvus 的数据持久化。
分布式版 Milvus
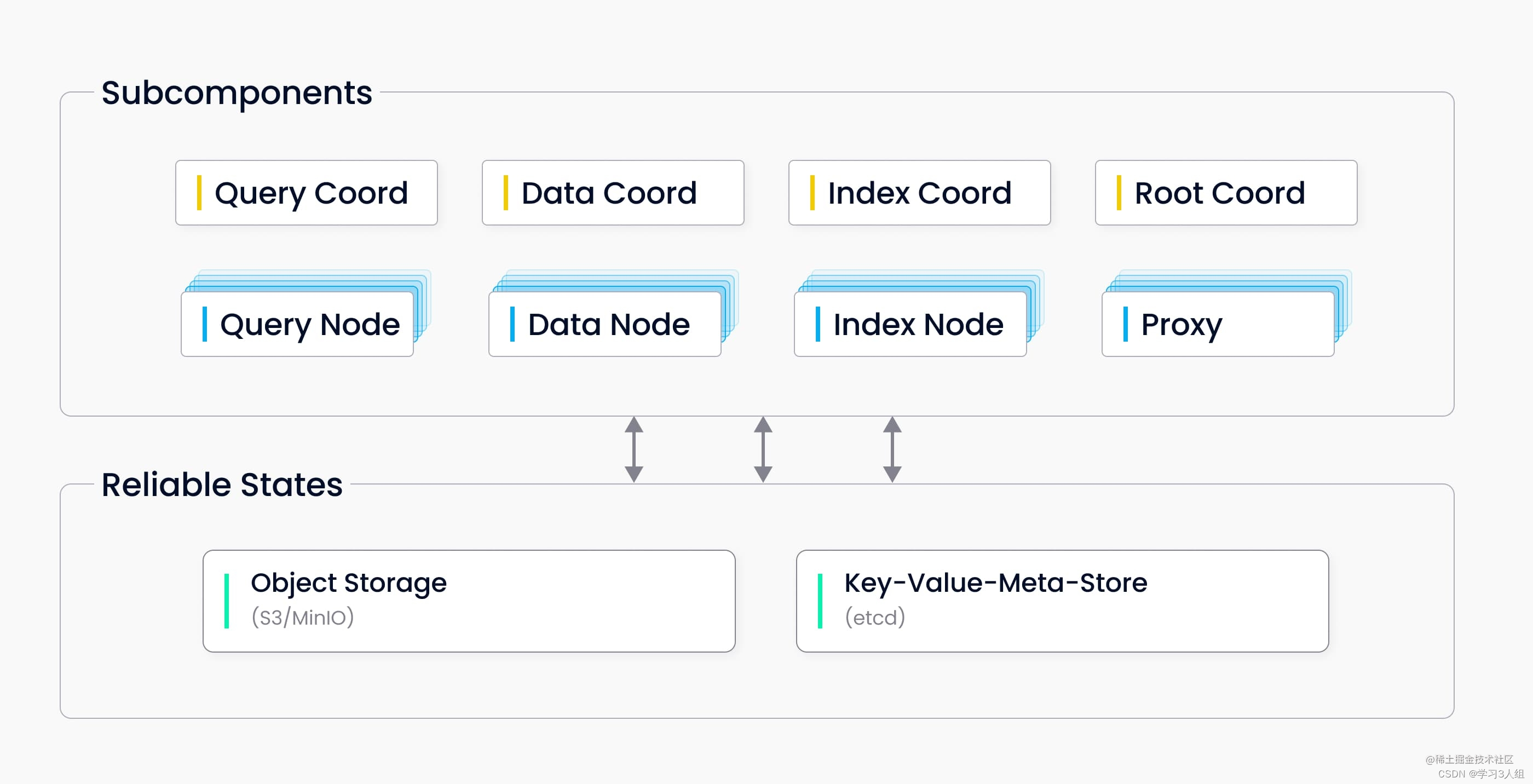
分布式版 Milvus 由八个微服务组件和三个第三方依赖组成,每个微服务组件可使用 Kubernetes 独立部署。
微服务组件
Root coord
Proxy
Query coord
Query node
Index coord
Index node
Data coord
Data node
第三方依赖
etcd 负责存储集群中各组件的元数据信息。
MinIO 负责处理集群中大型文件的数据持久化,如索引文件和全二进制日志文件。
Pulsar 负责管理近期更改操作的日志,输出流式日志及提供日志订阅服务。
Milvus 应用场景
你可以使用 Milvus 搭建符合自己场景需求的向量相似度检索系统。Milvus 的使用场景如下所示:
图片检索系统:以图搜图,从海量数据库中即时返回与上传图片最相似的图片。
视频检索系统:将视频关键帧转化为向量并插入 Milvus,便可检索相似视频,或进行实时视频推荐。
音频检索系统:快速检索海量演讲、音乐、音效等音频数据,并返回相似音频。
分子式检索系统:超高速检索相似化学分子结构、超结构、子结构。
推荐系统:根据用户行为及需求推荐相关信息或商品。
智能问答机器人:交互式智能问答机器人可自动为用户答疑解惑。
DNA 序列分类系统:通过对比相似 DNA 序列,仅需几毫秒便可精确对基因进行分类。
文本搜索引擎:帮助用户从文本数据库中通过关键词搜索所需信息。
注解:
【稀疏向量】【稠密向量】
机器学习中会经常用到向量,包括对特征的存储,优化的计算等等,都离不开向量。但是具体实现时,经常会采用两种方式存储向量,一种是使用数组的数据结构对向量建模,这种结构通常存储普通的向量,也称为稠密向量。一种是使用map的数据结构对向量建模,这种结构存储的向量大多数元素等于零,这种向量称为稀疏向量。
之所以使用两种不同的存储结构,是因为机器学习中的特征很多时候是高维空间中的元素,具有成千上万的分量,而这些分量是通过离散化得到的,所谓离散化,就是将原来取值为实数(比如某个特征为价格,取值为475.2)的特征,根据取值范围(例如范围在350800之间)分为若干个区间(例如按照每间隔10为一个区间,即分成了350360,360~370 ,790800),原来的一维特征也相应离散为若干维。如果价格在470480的区间中,则相应维度的特征取值为1,其他维度的特征取值为0。因此,如果使用稀疏向量存储,不仅节省空间,而且在后续的各种向量操作和优化的计算中会提高效率。