写在前面
大家好,我是刘聪NLP。
阿里在很早前就开源了Qwen-7B模型,但不知道为什么又下架了。就在昨天阿里又开源了Qwen-14B模型(原来的7B模型也放出来了),同时还放出了Qwen的技术报告内容。今天特此来给大家分享一下。
PS:现在国内的开源大模型也开始陆陆续续的放出了技术报告,都给我卷起来!!!
Report: https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf
GitHub: https://github.com/QwenLM/Qwen技术报告中介绍了整个Qwen系列的模型,有Base模型、RM模型、Chat模型、Code模型、Math模型、多模态模型。由于Code模型和Math模型暂时没有开源,多模态Qwen-VL模型本身有自己的论文,本次分享对三种模型就不做介绍了,感兴趣的同学自行查阅。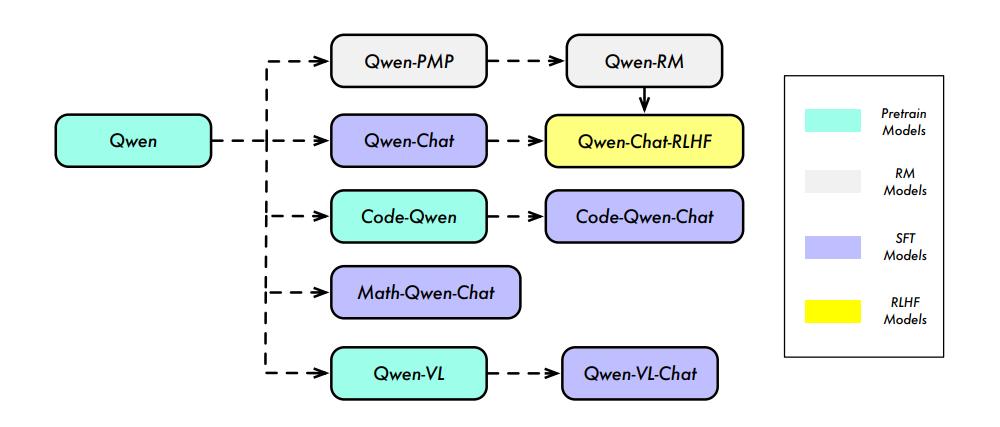
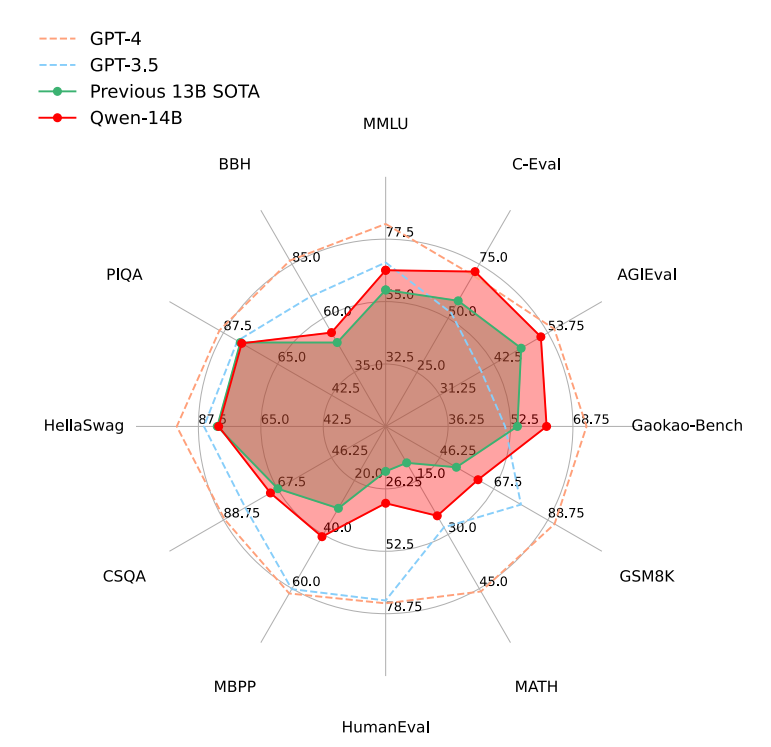
先说结论,Qwen-14B模型效果从12个数据集(涉及语言理解、知识、推理等多个领域)上进行均优于现有同等级的13B,但仍落后于GPT-3.5和GPT-4。
预训练
数据
预训练数据共3TB,主要涉及公共网络文档、百科全书、书籍、代码等,数据涉及多语言,但以中文和英文为主。为了保证数据质量,制定了一套全面的预处理程序。
Web数据需要从HTML中提取文本内容,并采用语言识别工具确定语种;
通过重复数据删除技术增加数据的多样性,包括规范化后的精确匹配重复数据删除方法和使用MinHash和LSH算法的模糊重复数据删除方法;
结合规则和机器学习的方法过滤低质量数据,即通过多个模型对内容进行评分,包括语言模型、文本质量评分模型以及用于识别潜在冒犯性模型;
从各种来源数据中手动采样并进行审查,以确保其质量;
有选择地对来自某些来源的数据进行采样,以确保模型在各种高质量内容上进行训练。
Tokenizer
词表大小影响者模型的训练效率和下游任务效果,Qwen采用开源快速BPE分词器-tiktoken,以cl100k为基础词库,增加了常用的中文字词以及其他语言的词汇,并把数字字符串拆成单个数字,最终词表大小为152K。
从不同语言上对比不同模型的压缩率,如下图所示,Qwen在绝大多少语言上都优于LLaMA-7B、Baichuan-7B、ChatGLM-6B、InternLM-7B模型。
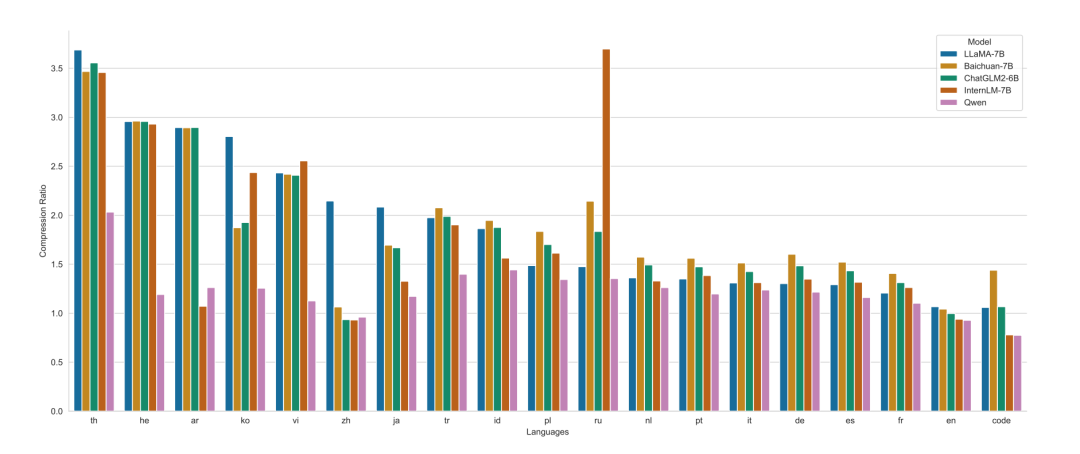
PS:不知道为啥没有对比Baichuan2模型。
模型
模型采用Transformer框架,主要做了以下修改:
Embedding and output projection:对于embedding层和lm_head层不进行权重共享,是两个单独的权重。
Positional embedding:采用RoPE为位置编码,并选择使用FP32精确度的逆频率矩阵。
Bias:在QKV注意力层中添加了偏差,以增强模型的外推能力。
Pre-Norm & RMSNorm:采用预归一化提高训练稳定性,并将传统归一化方法替换为RMSNorm。
Activation function:采用SwiGLU激活函数,不同于传统FFN的2个矩阵,SwiGLU有三个矩阵,因此缩小了隐藏层维度,由原来的4倍变成8/3倍。
外推能力扩展
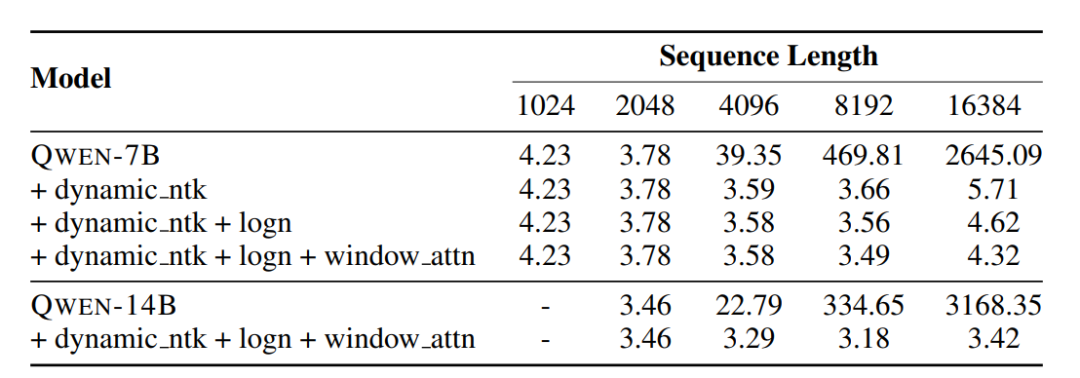
Transformer模型的注意力机制在上下文长度上有很大的限制,模型会随着上下文长度的增加,计算成本和内存会成倍增加。Qwen模型利用了简单地非训练计算,在推理过程中扩展上下文长度。
动态NTK感知插值,即对序列长度的增加动态缩放位置信息。
LogN-Scaling,根据上下文长度与训练长度的比率,对Q和V的点积进行重新缩放,确保注意力值的熵随着上下文长度的增长而保持稳定。
Window attention,将注意力限制在一个上下文窗口内,防止模型关注到太远的内容。并在不同层采用不同的窗口大小,较低的层使用较短的窗口,而较高的层使用较长的窗口。
训练
遵循自回归语言建模的标准方法,通过前面Token的内容预测下一个Token;
模型预训练时最大长度为2048,为了构建批次数据,对文本内容进行随机打乱及合并,再讲其截断到指定长度。
注意力模块采用Flash Attention技术,提高训练速度;
优化器采用AdamW,超参数β1、β2和ϵ为别为0.9、0.95和10−8;
采用余弦学习率计划,学习率会衰减到峰值的10%;
采用BFloat16进行混合精度训练。
预训练效果
QWEN模型再同等级参数下表现优异,即使是更大的型号如LLaMA2-70B,在3个任务中也被QWEN-14B超越。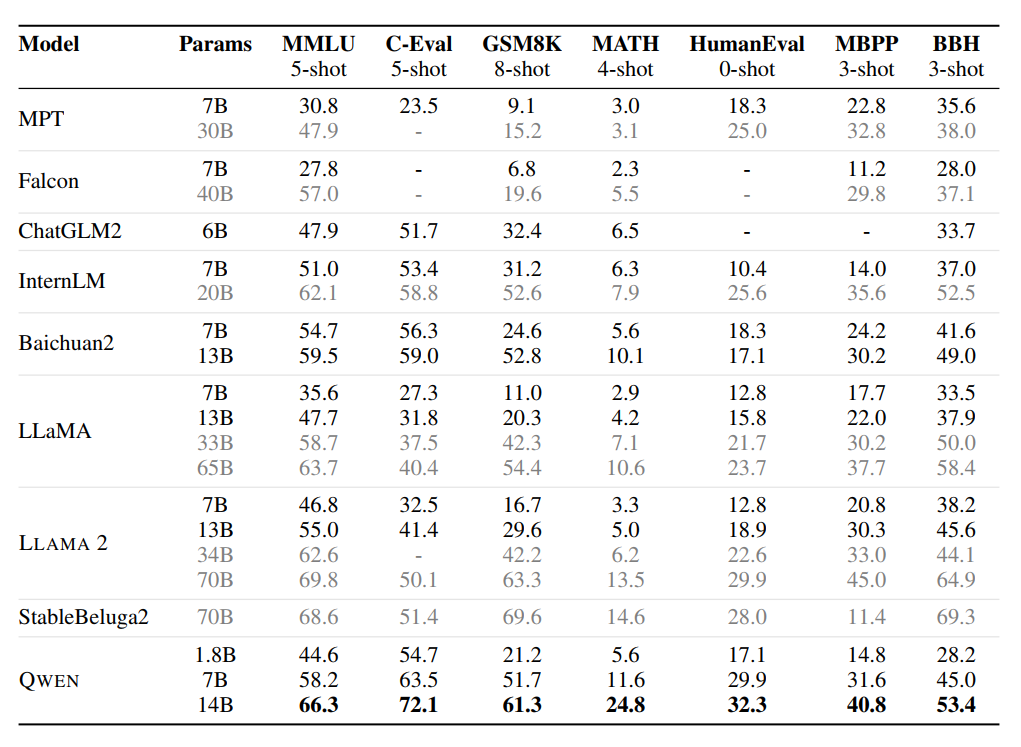
对齐
有监督微调SFT
为了提高有监督微调数据集的能力,对多种风格的对话进行了标注,来关注不同任务的自然语言生成,进一步提高模型的有用性。并且大小训练方法也会影响模型行了,Qwen采用ChatML样式的格式来进行模型训练。ChatML格式可以时模型有效区分各类信息,包括系统质量、用户输入、模型输出等,可以增强模型对复杂会话的处理分析能力。
优化器采用AdamW,超参数β1、β2和ϵ为别为0.9、0.95和1e−8;
模型最大输入长度2048;
训练批次大小为128;
模型共训练4000步,在前1430步中,学习率逐渐增加,达到2e−6的峰值。
为了防止过拟合,权重衰减的值设置为0.1,dropout设置为0.1,梯度裁剪的限制为1.0。
RM模型
在奖励模型的构建上,先采用大量数据进行偏好模型预训练(preference model pretraining,PMP),在经过高质量偏好数据进行奖励模型精调。高质量偏好数据通过6600详细标签的分类系统平衡采样获取,为保证数据的多样性和复杂性。
奖励模型时由同等大小Qwen模型+池化层得来,用特殊的句子结束标记映射值作为模型奖励值。
模型在训练过程中,学习率恒为3e−6,批次大小为64,最大长度为2048,训练一个epoch。

强化学习PPO
PPO阶段共包含四个模型:policy模型、value模型、reference模型、reward模型。训练过程中,先对policy模型训练50步预热,这样保证了value模型能够有效地适应不同的奖励模型。在PPO过程中,对每个query会同时采样两个response,KL散度系数设为0.04,并根据平均值对奖励进行归一化处理。
policy模型和value模型的学习率分别为1e−6和5e−6。为了增强训练的稳定性,裁剪值0.15。在进行推理时,生成策略的top-p值设置为0.9。
对齐结果
Qwen的效果优于相同规模的其他开源模型,如LLaMA2、ChatGLM2、InternLM、Baichuan2。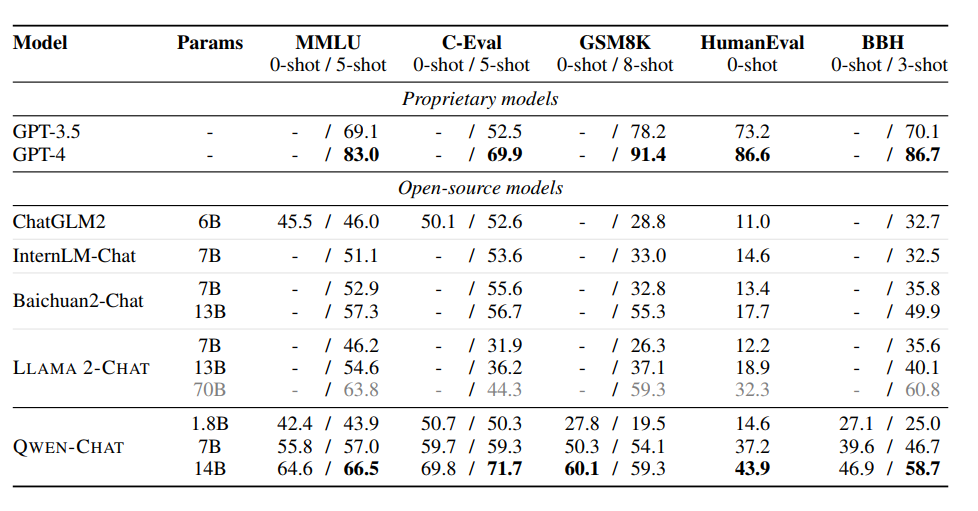
并且构造一个包含广泛主题的测试数据集,用于人工评测,比较了Qwen-7B-Chat(SFT)、Qwen-14B-Chat(SFT)、Qwen-14B-Chat(RLHF)、GPT4在对话上与GPT3.5的差异。可以看出RLHF模型明显优于SFT模型,说明RLHF可以生成更受人类喜爱的回答。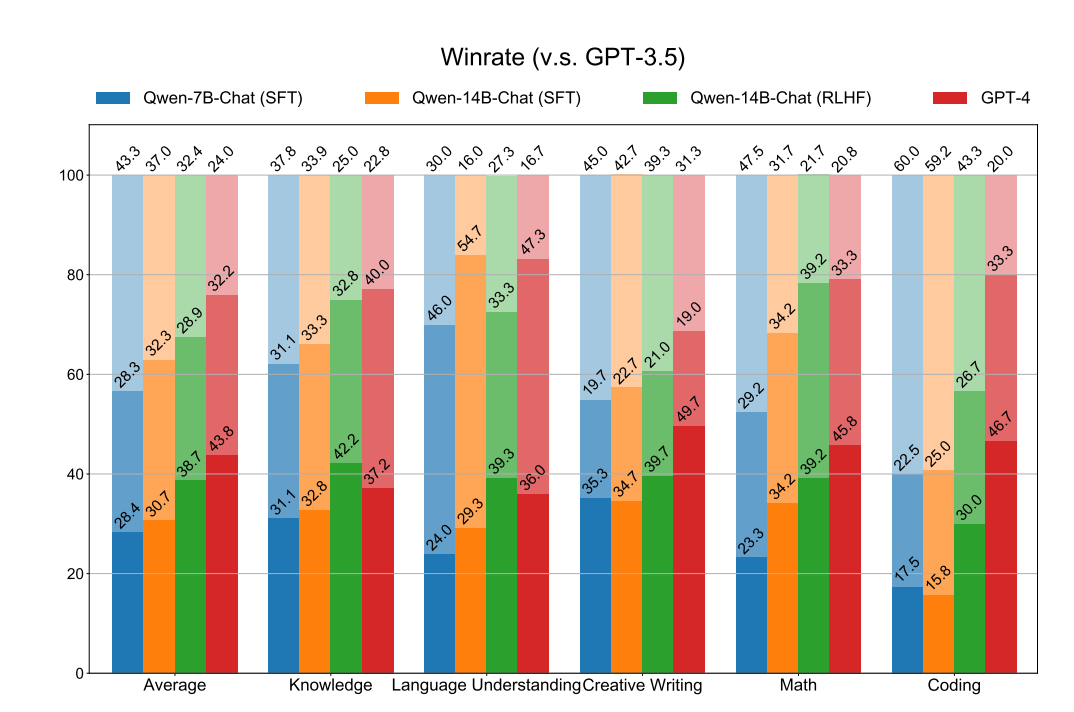
工具使用
Qwen模型具有工具使用能力:
可以通过ReAct提示进行使用未见的工具;
使用Python解释器增强数学推理、数据分析等能力;
作为代理,与人类交互过程中,可以访问HuggingFace中大量多模态模型集合。
PS:高质量数据2000条-React格式数据。
如何用 ReAct Prompting 技术命令千问使用工具
https://github.com/QwenLM/Qwen/blob/main/examples/react_prompt.md总结
大模型现在已经不仅仅是卷开源了,也开始卷技术报告了~
请多多关注知乎「刘聪NLP」,有问题的朋友也欢迎加我微信「logCong」私聊,交个朋友吧,一起学习,一起进步。我们的口号是“生命不止,学习不停”。
PS:新书已出《ChatGPT原理与实战》,欢迎购买~~。
往期推荐: