七十年前,麻省理工教授罗伯特·法诺 (Robert Fano) 在他的信息论课上给学生们提供了一道选择题:
(1) 参加传统的期末考试
(2) 解决一个难题
这个难题就是找到一种最有效的编码方法,用二进制数字来表示字母、数字和其他符号。
这看起来是一道灵活的智力题,其实这样的方法还可以用来压缩信息,方便保存和通过计算机网络传输。
当然,法诺教授隐藏了一个事实,他自己,甚至包括大名鼎鼎的信息论创始人香农都在这个问题上苦苦挣扎。
25岁的研究生霍夫曼不喜欢考试,他决定解决这个难题。
“被骗”的霍夫曼走上了一条不归路。
1
霍夫曼开始研究这个问题,考虑一条由字母、数字和标点符号组成的消息,最简单的编码方式是:为每个字符分配一个唯一的、长度相同的二进制数,例如:
A -> 01000001

B -> 01000010
C -> 01000010
这种方法非常容易解析,但是效率非常低下,因为有些字符使用频率高,有些使用频率低。
一种更好的办法是莫尔斯电码,频繁出现的字母 E 仅由一个点表示,而不太常见的 J 需要更长且更费力的点-划-划-划来表达。

虽然莫尔斯编码有长有短,但是效率依然低下,更烦人的是,发送信息时,每个字符之间还需要增加额外的停顿,否则就无法区分类似这样的两个消息:
划 点-划-点 点-点 划 点 (“trite”)
划 点-划-点 点-点-划 点 (“true”)
实际上,法诺教授已经部分解决了这个问题:使用无前缀码。
例如,如果字母S在特定消息中出现频率非常高,那么可以给他分配一个极短的代码01。
重点是,消息中其他字母都不会以01开头进行编码,010,011,0101都是被禁止的。
由于每个字母的前缀都完全不同,编码过的消息可以从左到右读取,没有任何歧义。
例如:
S -> 01
A -> 000
M -> 001
L -> 1
那么 0100000111 可以被没有歧义地翻译为SMALL。
那么如何找到一种算法,既能把最短的编码分配给最常用的字符,把最长的代码保留给很少用的字符,又能确保每个字符的前缀不同呢?
法诺教授提出了一个近似的方法,把消息中的字符按照出现频率,从上往下构建一个二叉树,然后分配编码。
具体的算法这里就不再赘述了,感兴趣的同学可以查看相关资料。
由于法诺教授的方法只能得到近似值,一定存在更好的压缩策略,所以他向学生们提出了挑战。
2
霍夫曼认认真真地研究了几个月,开发了多种方法,但没有一种被证明是有效的。
霍夫曼绝望了:被教授给骗了,还是去准备期末考试吧!
就在他把自己的笔记扔进垃圾桶的时候,一道闪电在脑海划过,解决方案出现了。
“这绝对是我一生中最独特的时刻!”
霍夫曼的想法非常简单和优雅,具体来说是按照字符出现的频率,从下往上构建二叉树。
举个例子就明白了。
假设有SCHOOLROOM这个消息,先计算出每个字符出现的频率。
O:4次
S/C/H/L/R/M :1次
霍夫曼先取出现频率最低的两个字符,比如R和M吧,构成一颗二叉树,其中父节点的频率是两个叶子节点的和,也就是2。
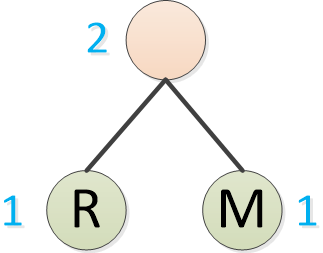
现在,频率最高的还是O,出现4次,R/M的父节点的频率是2, 其他字符依然是1。
霍夫曼继续找频率最低的,组成二叉树,比如H,L
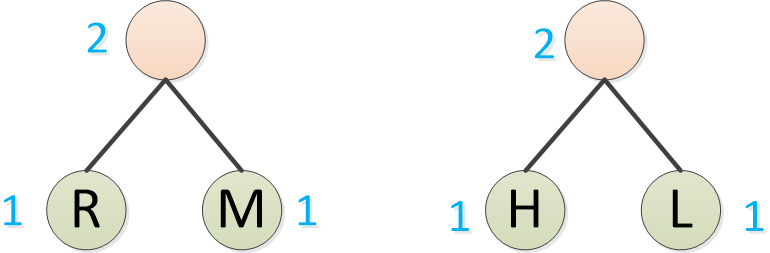
继续找频率最低的,组成二叉树,如S,C
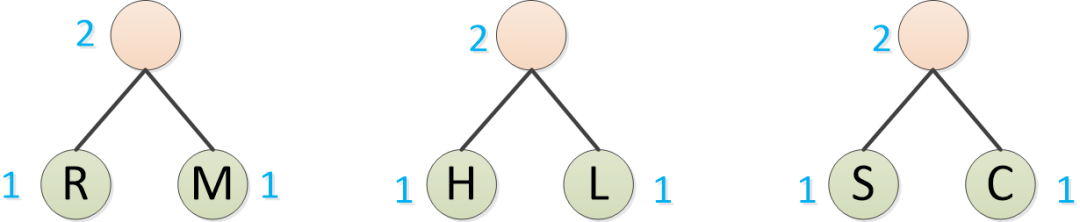
现在的出现频率表是这样的:
O:4次
R/M : 2次
H/L : 2次
S/C : 2次
霍夫曼依然取频率最低的,如H/L ,和S/C,组成二叉树
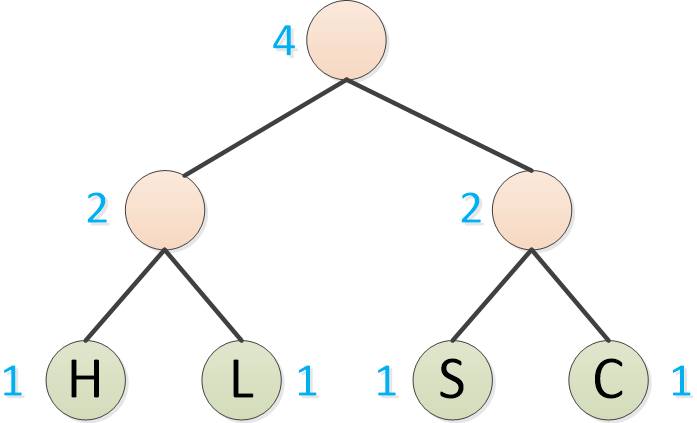
频率表变成了这样:
O:4次
R/M : 2次
H/L/S/C : 4次
再取两个频率最低的,形成二叉树,注意,频率低的成为左子树,频率高的成为右子树
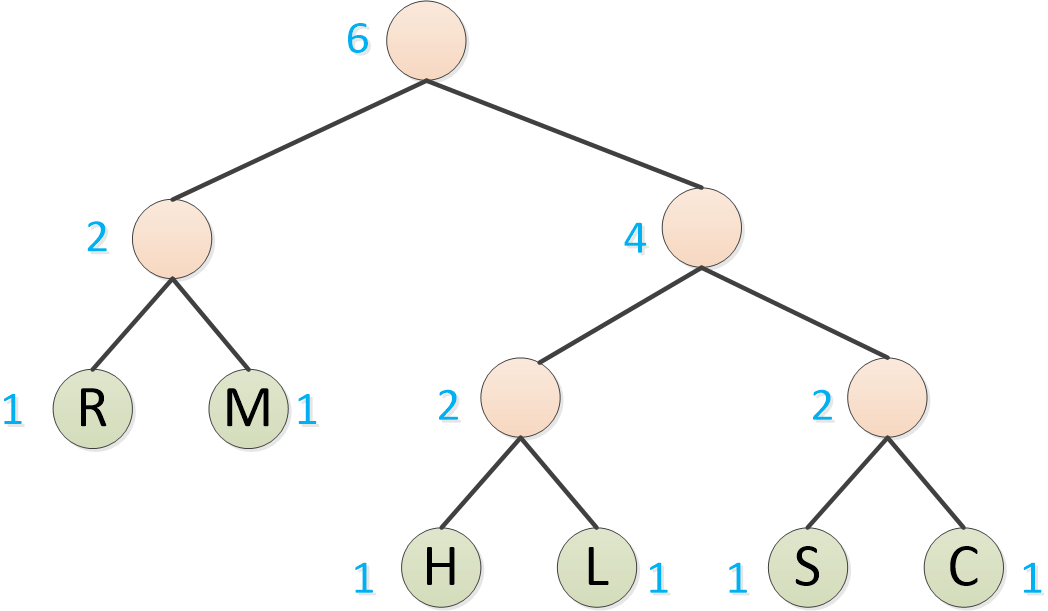
最后,把剩下的O也形成二叉树。
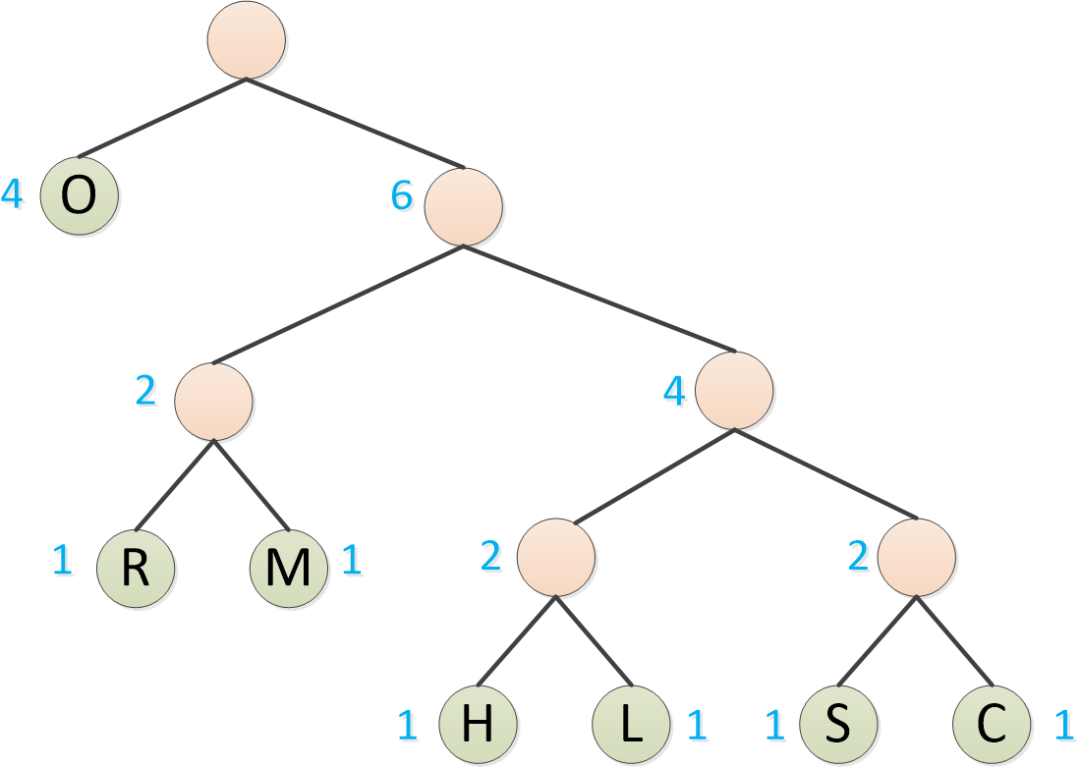
然后,对于左子树的分支,标记0,右子树的分支标记1
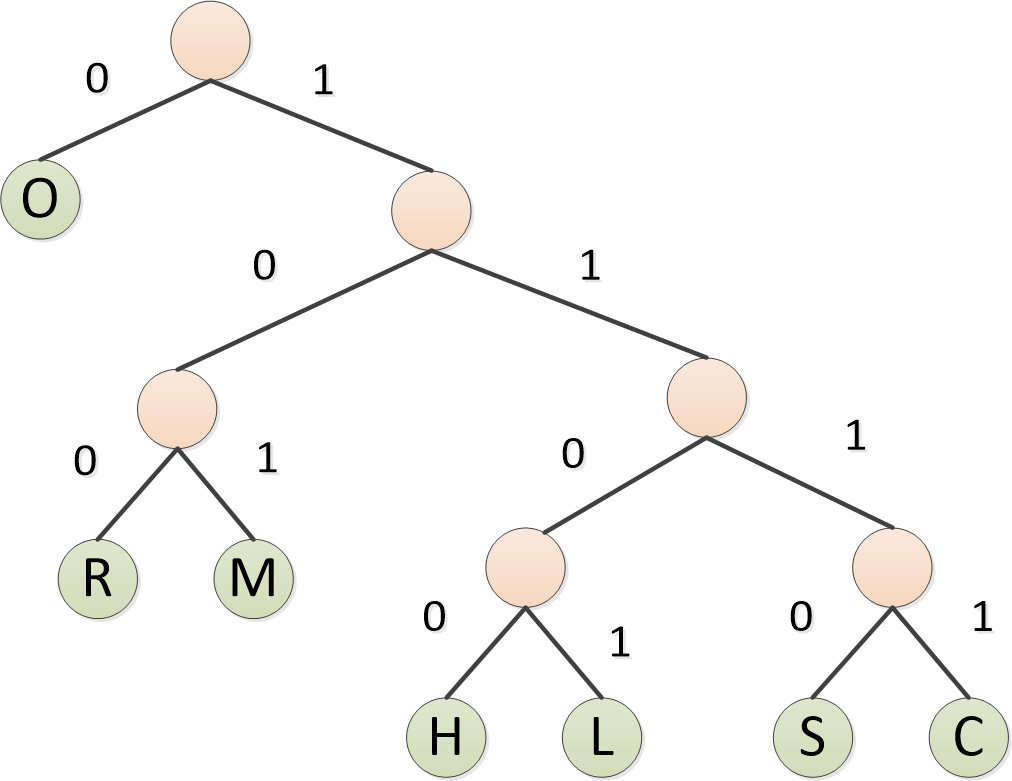
最终,形成了每个字符的编码
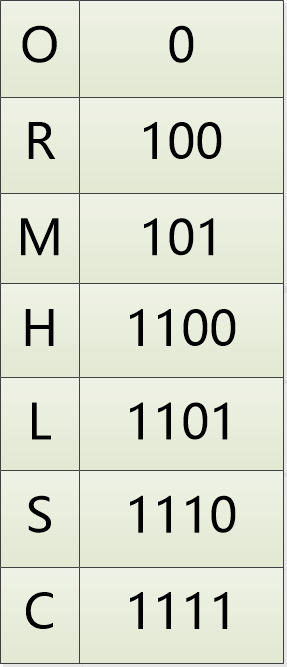
对于SCHOOLROOM来说,编码就是:11101111110000110110000101。
(注:由于选择同频率的节点时,可能次序不同,二叉树形状不同,霍夫曼编码并不唯一。)
霍夫曼的算法被称为“最佳编码”,实现了两个目标:
(1) 任何一个字符编码,都不是其他字符编码的前缀。
(2) 信息编码的总长度最小。
霍夫曼超越了他的老师的算法,后来他说:
“如果我知道教授法诺和信息论的创始人香农曾在这个问题上苦苦挣扎,我可能永远不会尝试解决这个问题,更不用说在 25 岁时解决这个问题了。”

就连伟大的香农也没有想到的算法,被一个学生无意间发现,不能不说是个奇迹。
霍夫曼的算法被广泛应用在数据压缩,文件压缩,图形编码等领域,是IT行业的一个非常基础的算法。
3
故事讲完了,聊几点儿感想:
(1)这个算法在70年前已经发明了,美国在计算机领域,无论是理论还是实践都领先太多。一个领域在刚开创时,遍地黄金,等到发展成熟,只能在边边角角里折腾了。
(2)霍夫曼的算法又简单又优美,就在刚才,家里5年级的小学生看了下这篇文章,我给她出个题,她很快就能把二叉树画出来,得到最终的编码。
但是,就像哥伦布发现美洲一样,一般人确实想不到,更不用说要用数学来表示和证明了。
(3)霍夫曼没有为自己的发明申请专利,算法能否申请专利还有很大争论,不过其他人利用霍夫曼算法开发的软件赚了几百万。霍夫曼的主要报酬是免除了信息论的期末考试。
《计算机编程的艺术》作者高德纳说:在计算机科学和数据通信领域,霍夫曼编码是人们一直使用的基本思想之一。
这可能就是最高的奖赏吧!
全文完,喜欢的话就在右下角点个赞和在看吧!