文章目录

1. Abstract
SAM正在成为许多高级任务的基础步骤,如图像分割、图像字幕和图像编辑。然而,其巨大的计算成本使其无法在行业场景中得到更广泛的应用。计算主要来自高分辨率输入的Transformer架构。

研究者为这项基本任务提出了一种性能相当的加速替代方法。通过将任务重新表述为片段生成和提示,我们发现具有实例分割分支的常规CNN检测器也可以很好地完成该任务。具体而言,我们将该任务转换为研究充分的实例分割任务,并仅使用SAM作者发布的SA-1B数据集的1/50直接训练现有的实例分割方法。使用我们的方法,我们在50倍的运行时速度下实现了与SAM方法相当的性能。我们给出了足够的实验结果来证明它的有效性。


2. 背景介绍
SAM被视为一个里程碑式的愿景基础模型。它可以在各种可能的用户交互提示的引导下分割图像中的任何对象。SAM利用了在广泛的SA-1B数据集上训练的Transformer模型,这使其能够熟练地处理各种场景和对象。SAM为一项激动人心的新任务打开了大门,该任务被称为Segment Anything。这项任务,由于其可推广性和潜力,具有成为未来广泛愿景任务基石的所有条件。
然而,尽管SAM和后续模型在处理细分市场任何任务方面取得了这些进步和有希望的结果,但其实际应用仍然具有挑战性。突出的问题是与SAM架构的主要部分Transformer(ViT)模型相关的大量计算资源需求。与卷积技术相比,ViT因其繁重的计算资源需求而脱颖而出,这给其实际部署带来了障碍,尤其是在实时应用中。因此,这种限制阻碍了SA任务的进展和潜力。
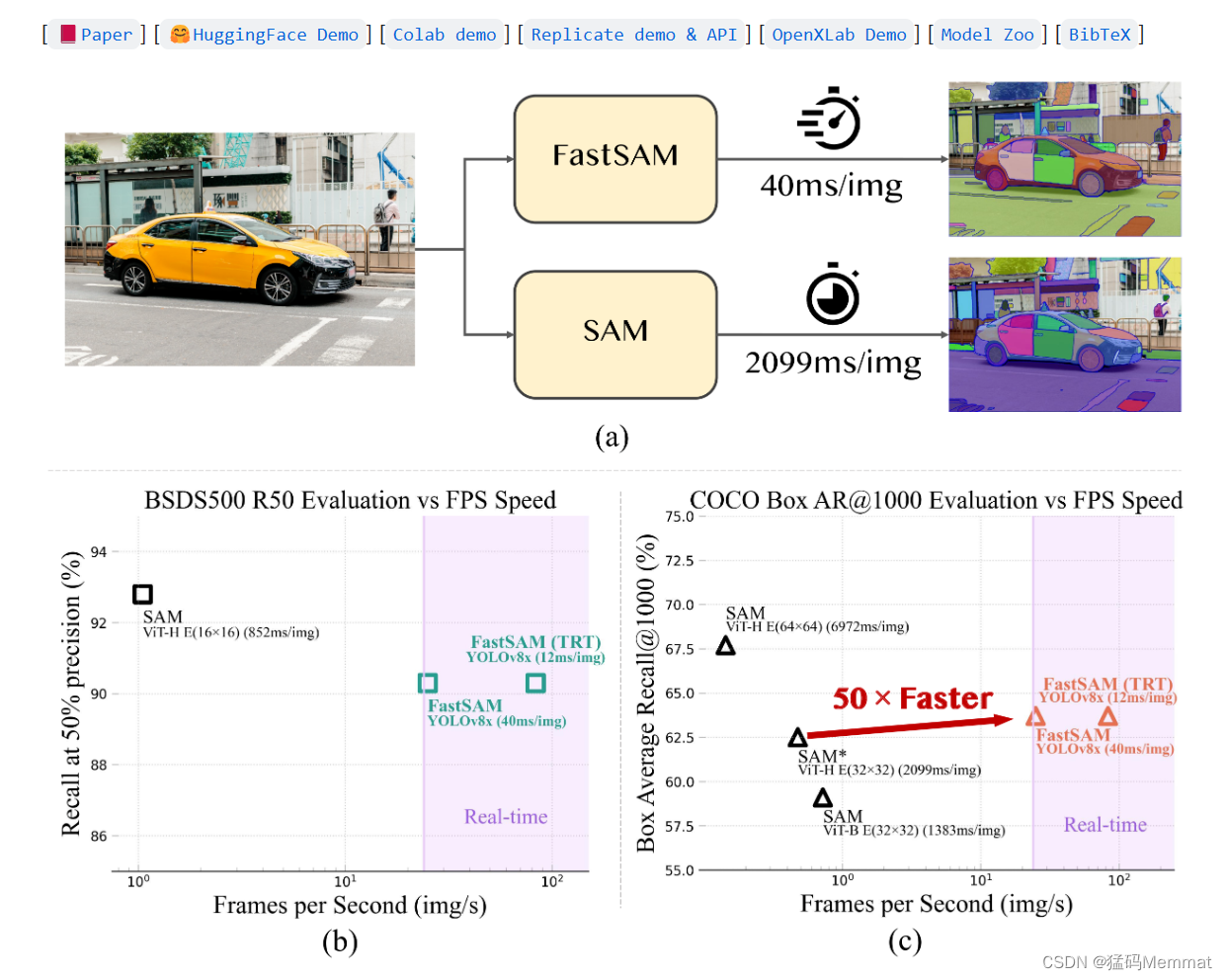



针对工业上对SAM实时分割的需求,本文设计了一个SA任务的实时解决方案FastSAM。我们将SA任务解耦为两个连续的阶段,即全实例分割(all-instance segmentation)和提示引导选择(prompt-guided selection)。第一阶段是基于卷积神经网络(CNN)检测器的实现。它生成图像中所有实例的分割掩码。然后在第二阶段,输出与提示符相对应的感兴趣区域。通过利用cnn的计算效率,我们证明了在不影响性能质量的情况下,任何模型的实时分段都是可以实现的。我们希望所提出的方法将促进分割任何东西的基本任务的工业应用。
我们提出的FastSAM基于YOLOv8-seg [16], YOLOv8-seg是一种配备实例分割分支的目标检测器,它利用了YOLACT[4]方法。我们还采用了SAM发布的广泛的SA-1B数据集。通过仅在SA-1B数据集的2%(1/50)上直接训练该CNN检测器,它实现了与SAM相当的性能,但大大减少了计算和资源需求,从而实现了实时应用。我们还将其应用于多个下游分割任务,以展示其泛化性能。在MS COCO上的目标提议任务[13]上,我们在AR1000下实现了63.7,比在32× 32点提示输入下的SAM高1.2分,但在单个NVIDIA RTX 3090上运行速度快50倍。
实时分段模型对工业应用很有价值。它可以应用于许多场景。所提出的方法不仅为大量的视觉任务提供了一种新的、实用的解决方案,而且速度非常快,比crre快几十倍或几百倍。它还为一般视觉任务的大型模型体系结构提供了新的视图。我们认为,对于特定的任务,特定的模型仍然可以获得更好的效率和准确性权衡。然后,在模型压缩的意义上,我们的方法证明了一条路径的可行性,该路径可以通过在结构之前引入人工先验来显着减少计算量。我们的贡献可以概括如下:
- 介绍了一种新颖的、基于cnn的实时SA任务解决方案,该解决方案在保持竞争性性能的同时显著降低了计算需求。
- 这项工作提出了将CNN检测器应用于SA任务的第一个研究,为轻量级CNN模型在复杂视觉任务中的潜力提供了见解。
- 在多个基准上对所提出的方法和SAM进行比较评估,可以深入了解该方法在SA领域中的优缺点。
2.0.1 TensorRT
TensorRT介绍: https://blog.csdn.net/weixin_42111770/article/details/114336102
pytorch模型(.pth)转tensorrt模型(.engine)几种方式:https://blog.csdn.net/qq_39056987/article/details/124588857
2.0.2 Zero-Shot
ZSLearning希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能。其中零次(Zero-shot)是指对于要分类的类别对象,一次也不学习。
Zero-shot一种定义:利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集;期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。
Zero-shot(零次学习)简介: https://blog.csdn.net/gary101818/article/details/129108491
机器学习中通常需要大量的训练数据来训练模型,以便它能够准确地识别和分类新的输入。然而,在现实世界中,获取大规模标记数据集可能是昂贵和耗时的。因此,零样本学习、一次样本学习和少样本学习等技术应运而生,它们旨在解决这个问题。
零样本学习(Zero-Shot Learning)是一种能够在没有任何样本的情况下学习新类别的方法。通常情况下,模型只能识别它在训练集中见过的类别。但通过零样本学习,模型能够利用一些辅助信息来进行推理,并推广到从未见过的类别上。这些辅助信息可以是关于类别的语义描述、属性或其他先验知识。
一次样本学习(One-Shot Learning)是一种只需要一个样本就能学习新类别的方法。这种方法试图通过学习样本之间的相似性来进行分类。例如,当我们只有一张狮子的照片时,一次样本学习可以帮助我们将新的狮子图像正确分类。
少样本学习(Few-Shot Learning)是介于零样本学习和一次样本学习之间的方法。它允许模型在有限数量的示例下学习新的类别。相比于零样本学习,少样本学习提供了更多的训练数据,但仍然相对较少。这使得模型能够从少量示例中学习新的类别,并在面对新的输入时进行准确分类。
Zero-Shot, One-Shot, and Few-Shot Learning概念介绍: https://blog.csdn.net/weixin_42010722/article/details/131182669
3. 框架详情 (Methodology)
3.1 Overview
下图给出了所提出的FastSAM方法的概述。该方法由两个阶段组成,即所有实例分割(all-instance segmentation, ais)和提示引导选择(prompt-guided selection, pgs)。前一阶段是基础,第二阶段本质上是面向任务的后处理。与端到端变换器不同,整体方法引入了许多与视觉分割任务相匹配的人类先验,如卷积的局部连接和感受野相关的对象分配策略。这使得它能够针对视觉分割任务进行定制,并且可以在较小数量的参数上更快地收敛。
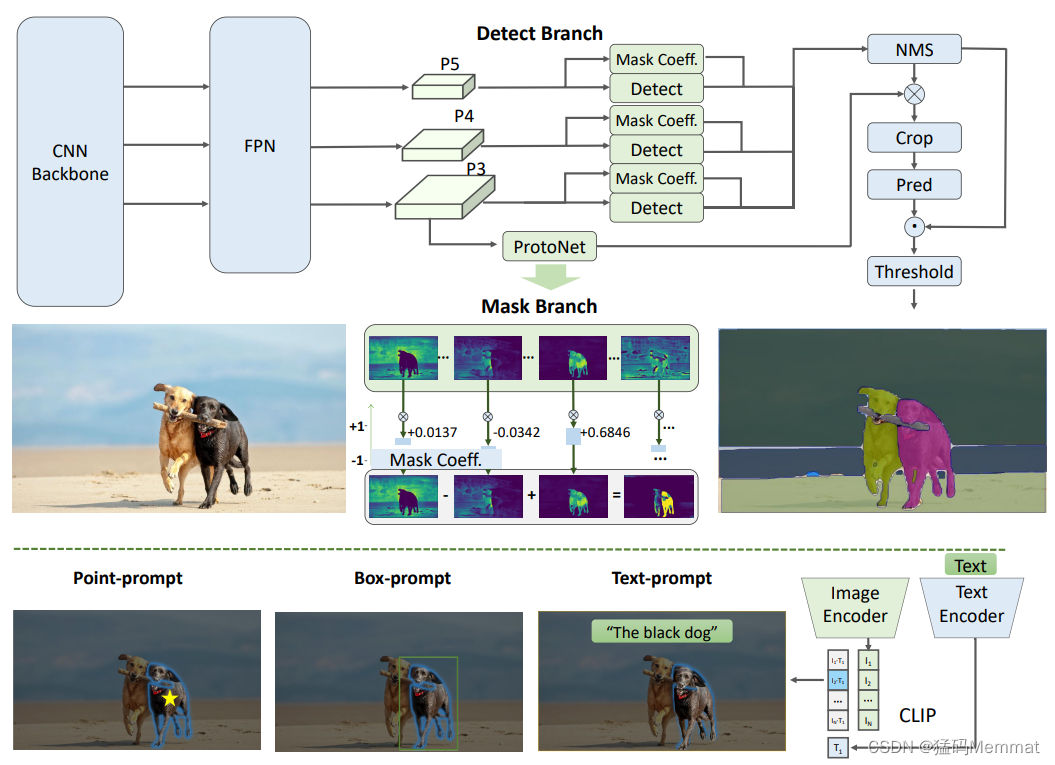
检测分支输出类别和边界框,而分割分支输出k个原型(在FastSAM中默认为32)以及k个掩码系数。分割和检测任务是并行计算的。分割分支输入高分辨率特征图,保留空间细节,还包含语义信息。该映射通过卷积层进行处理,放大,然后通过另外两个卷积层输出掩码。掩码系数,类似于探测头的分类分支,范围在-1和1之间。实例分割结果是通过将掩模系数与原型相乘,然后将其相加而获得的。
from fastsam import FastSAM, FastSAMPrompt
model = FastSAM('./weights/FastSAM.pt')
IMAGE_PATH = './images/dogs.jpg'
DEVICE = 'cpu'
everything_results = model(IMAGE_PATH, device=DEVICE, retina_masks=True, imgsz=1024, conf=0.4, iou=0.9,)
prompt_process = FastSAMPrompt(IMAGE_PATH, everything_results, device=DEVICE)
# everything prompt
ann = prompt_process.everything_prompt()
# bbox default shape [0,0,0,0] -> [x1,y1,x2,y2]
ann = prompt_process.box_prompt(bbox=[[200, 200, 300, 300]])
# text prompt
ann = prompt_process.text_prompt(text='a photo of a dog')
# point prompt
# points default [[0,0]] [[x1,y1],[x2,y2]]
# point_label default [0] [1,0] 0:background, 1:foreground
ann = prompt_process.point_prompt(points=[[620, 360]], pointlabel=[1])
prompt_process.plot(annotations=ann,output_path='./output/dog.jpg',)
3.2 All-instance Segmentation

3.3 Prompt-guided Selection
在使用YOLOv8成功分割图像中的所有对象或区域之后,分割任何对象任务的第二阶段是使用各种提示来识别感兴趣的特定对象。它主要涉及点提示、框提示和文本提示的使用。
Point prompt 包括将选定的点与从第一阶段获得的各种遮罩进行匹配。目标是确定点所在的遮罩。与SAM类似,我们在方法中使用前地面/背景点作为提示。在前景点位于多个遮罩中的情况下,可以利用背景点来过滤出与手头任务无关的遮罩。通过使用一组前景/背景点,我们能够在感兴趣的区域内选择多个遮罩。这些遮罩将合并为一个遮罩,以完全标记感兴趣的对象。此外,我们还利用形态学运算来提高掩模合并的性能。
Box prompt 长方体提示涉及在选定长方体和与第一阶段中的各种遮罩相对应的边界框之间执行并集交集(IoU)匹配。其目的是用所选框识别具有最高IoU分数的掩码,从而选择感兴趣的对象。
Text prompt 在文本提示的情况下,使用CLIP模型提取文本的相应文本嵌入。然后确定相应的图像嵌入,并使用相似性度量将其与每个掩模的内在特征相匹配。然后选择与文本提示的图像嵌入具有最高相似性得分的掩码。
通过仔细实施这些提示引导选择技术,FastSAM可以从分割图像中可靠地选择感兴趣的特定对象。上述方法提供了一种实时完成任何分割任务的有效方法,从而大大提高了YOLOv8模型在复杂图像分割任务中的实用性。一种更有效的即时引导选择技术留给了未来的探索。
3.3.1 CLIP
clip.py
import hashlib
import os
import urllib
import warnings
from typing import Any, Union, List
from pkg_resources import packaging
import torch
from PIL import Image
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize
from tqdm import tqdm
from .model import build_model
from .simple_tokenizer import SimpleTokenizer as _Tokenizer
try:
from torchvision.transforms import InterpolationMode
BICUBIC = InterpolationMode.BICUBIC
except ImportError:
BICUBIC = Image.BICUBIC
if packaging.version.parse(torch.__version__) < packaging.version.parse("1.7.1"):
warnings.warn("PyTorch version 1.7.1 or higher is recommended")
__all__ = ["available_models", "load", "tokenize"]
_tokenizer = _Tokenizer()
_MODELS = {
"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
"RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
"RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
"RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt",
"RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt",
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
"ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt",
"ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt",
"ViT-L/14@336px": "https://openaipublic.azureedge.net/clip/models/3035c92b350959924f9f00213499208652fc7ea050643e8b385c2dac08641f02/ViT-L-14-336px.pt",
}
def _download(url: str, root: str):
os.makedirs(root, exist_ok=True)
filename = os.path.basename(url)
expected_sha256 = url.split("/")[-2]
download_target = os.path.join(root, filename)
if os.path.exists(download_target) and not os.path.isfile(download_target):
raise RuntimeError(f"{
download_target} exists and is not a regular file")
if os.path.isfile(download_target):
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() == expected_sha256:
return download_target
else:
warnings.warn(f"{
download_target} exists, but the SHA256 checksum does not match; re-downloading the file")
with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:
with tqdm(total=int(source.info().get("Content-Length")), ncols=80, unit='iB', unit_scale=True, unit_divisor=1024) as loop:
while True:
buffer = source.read(8192)
if not buffer:
break
output.write(buffer)
loop.update(len(buffer))
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() != expected_sha256:
raise RuntimeError("Model has been downloaded but the SHA256 checksum does not not match")
return download_target
def _convert_image_to_rgb(image):
return image.convert("RGB")
def _transform(n_px):
return Compose([
Resize(n_px, interpolation=BICUBIC),
CenterCrop(n_px),
_convert_image_to_rgb,
ToTensor(),
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
])
def available_models() -> List[str]:
"""Returns the names of available CLIP models"""
return list(_MODELS.keys())
def load(name: str, device: Union[str, torch.device] = "cuda" if torch.cuda.is_available() else "cpu", jit: bool = False, download_root: str = None):
"""Load a CLIP model
Parameters
----------
name : str
A model name listed by `clip.available_models()`, or the path to a model checkpoint containing the state_dict
device : Union[str, torch.device]
The device to put the loaded model
jit : bool
Whether to load the optimized JIT model or more hackable non-JIT model (default).
download_root: str
path to download the model files; by default, it uses "~/.cache/clip"
Returns
-------
model : torch.nn.Module
The CLIP model
preprocess : Callable[[PIL.Image], torch.Tensor]
A torchvision transform that converts a PIL image into a tensor that the returned model can take as its input
"""
if name in _MODELS:
model_path = _download(_MODELS[name], download_root or os.path.expanduser("~/.cache/clip"))
elif os.path.isfile(name):
model_path = name
else:
raise RuntimeError(f"Model {
name} not found; available models = {
available_models()}")
with open(model_path, 'rb') as opened_file:
try:
# loading JIT archive
model = torch.jit.load(opened_file, map_location=device if jit else "cpu").eval()
state_dict = None
except RuntimeError:
# loading saved state dict
if jit:
warnings.warn(f"File {
model_path} is not a JIT archive. Loading as a state dict instead")
jit = False
state_dict = torch.load(opened_file, map_location="cpu")
if not jit:
model = build_model(state_dict or model.state_dict()).to(device)
if str(device) == "cpu":
model.float()
return model, _transform(model.visual.input_resolution)
# patch the device names
device_holder = torch.jit.trace(lambda: torch.ones([]).to(torch.device(device)), example_inputs=[])
device_node = [n for n in device_holder.graph.findAllNodes(