若该文为原创文章,转载请注明原文出处。
感谢恩培大佬对项目进行了完整的实现,并将代码进行开源,供大家交流学习。
恩培大佬开源地址,有兴趣的可以去复现一下。GitHub - enpeizhao/CVprojects: computer vision projects | 计算机视觉相关好玩的AI项目(Python、C++)
一、介绍
从恩培大佬的git上看到的小项目《火影结印识别》,发现大佬开源的代码是需要GPU的,本人电脑没有GPU,环境安装好了,没复现成功,所以取巧使用yolov5的方式实现一样的功能。
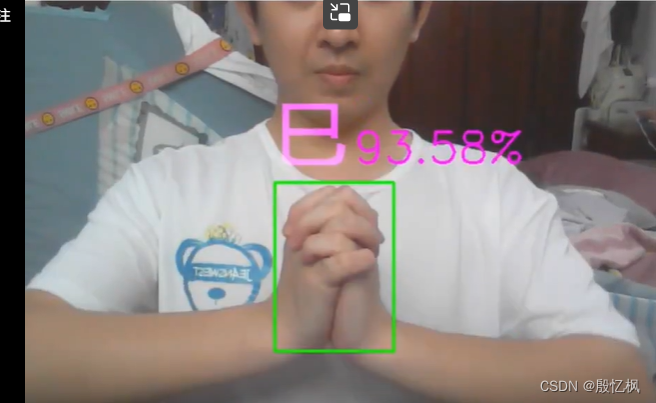
yolov5安装及训练前面有提及,不熟悉yolov5训练可以看前面文章。
二、训练集
准备素材,训练的手势共有七种,每种采集30张图片,并使用lableImg标注所有图片。

label标签

三、训练
训练使用的是AutoDL云端训练,样本不多,训练大概20-30分钟,用的是3090显卡。
这有有个注意的,直接使用AutoDL提供的镜像训练出来的pt文件一直识别检测不到,所以又换回yolov5-5版本,训练出来正常。

效果还行,想要复现就得自己训练。
四、代码
1、生成字幕需要的中文PNG图片
PNG图片是为了把识别到的字显示出来,使用OPENCV不好显示中心,所以提前准备好png直接在视频内叠加PNG图片。
'''
生成字幕需要的中文PNG图片
'''
from PIL import Image,ImageDraw,ImageFont
def generate(name='你好',color_label='green'):
filename = './png_label/'+name+'.png'
# 背景
bg = Image.new("RGBA",(400,100),(0,0,0,0))
# 添加文字
d = ImageDraw.Draw(bg)
font = ImageFont.truetype('./fonts/MSYH.ttc',80,encoding="utf-8")
if color_label == 'green':
color = (0,255,0,255)
else:
color = (255,0,0,255)
d.text((0,0),name,font=font,fill=color)
# 保存
bg.save(filename)
print('ok: '+ name)
generate('火遁豪火球之术','red')运行后,会生成PNG图片。

2、完整代码
import ctypes
import cv2
import numpy as np
import time
# 多进程
from multiprocessing import Process, Value
import threading
import torch
import sys
from playsound import playsound
class Ai_tello:
def __init__(self):
# ************************************ 绘制 相关 *********************************
self.png_dict = {}
# 获取
self.getPngList()
# 加载 yolov5模型
self.model = torch.hub.load('./yolov5', 'custom', './weights/pose.pt',source='local')
# 置信度阈值
self.model.conf = 0.5
print('self.model.conf = 0.5')
self.take_off_time = None
# 结印动作顺序
self.yolo_action_seq = ['ani_1', 'ani_2','ani_3', 'ani_4', 'ani_5', 'ani_6', 'ani_7']
# 状态机,1表示当前动作已做完(击中)
self.yolo_action_status = [0, 0, 0, 0, 0, 0, 0]
def getPngList(self):
'''
读取PNG图片,追加进png_dict
'''
palm_action = {'ani_1': '巳', 'ani_2': '未', 'ani_3': '申',
'ani_4': '亥', 'ani_5': '午', 'ani_6': '寅', 'ani_7':'火遁豪火球之术'}
for name in palm_action.values():
filename = './png_label/'+name+'.png'
png_img = self.readPngFile(filename, 0.9)
self.png_dict[name] = png_img
print('PNG文字标签加载完毕')
def playVoice(self, fileName,mode):
"""
播放音乐
"""
playsound(fileName)
def backPlay(self,fileName):
"""
后台播放
"""
t = threading.Thread(target=self.playVoice, args=(fileName,'voice'))
t.start()
def readPngFile(self, fileName, scale=0.5):
'''
读取PNG图片
'''
# 解决中文路径问题
png_img = cv2.imdecode(np.fromfile(fileName, dtype=np.uint8), -1)
# 转为BGR,变成3通道
png_img = cv2.cvtColor(png_img, cv2.COLOR_RGB2BGR)
png_img = cv2.resize(png_img, (0, 0), fx=scale, fy=scale)
return png_img
def addOverylay(self, frame, overlay, l, t):
'''
添加标签png覆盖
'''
# 解决l、t超界
l = max(l, 0)
t = max(t, 0)
# 覆盖显示
overlay_h, overlay_w = overlay.shape[:2]
# 覆盖范围
overlay_l, overlay_t = l, t
overlay_r, overlay_b = (l + overlay_w), (overlay_t+overlay_h)
# 遮罩
overlay_copy = cv2.addWeighted(
frame[overlay_t:overlay_b, overlay_l:overlay_r], 1, overlay, 20, 0)
frame[overlay_t:overlay_b, overlay_l:overlay_r] = overlay_copy
def cameraProcess(self):
'''
视频流处理:动作识别、绘制等
'''
print('cameraProcess');
cap = cv2.VideoCapture(0)
# 动作
palm_action = {'ani_1':'巳','ani_2':'未','ani_3':'申','ani_4':'亥','ani_5':'午','ani_6':'寅','ani_7':'火遁豪火球之术'}
triger_time = time.time()
while True:
# 读取视频帧
ret,frame = cap.read()
if frame is None:
continue;
frame = cv2.flip(frame, 1)
# 转为RGB
img_cvt = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
if self.take_off_time != None:
if time.time() - triger_time >= 2:
label_zh = palm_action['ani_7']
overlay = self.png_dict[label_zh]
self.addOverylay(frame,overlay,l,200)
else:
# 目标检测推理
results = self.model(img_cvt)
results_arr = results.pandas().xyxy[0].to_numpy()
# 解析目标检测结果
for item in results_arr:
# 标签ID
ret_label_id = item[-2]
# 标签名称
ret_label_text = item[-1]
# 置信度
ret_conf = item[-3]
# ani_1,ani_2....ani_6
# 结印动作,且置信度要求高一些
if 'ani_' in ret_label_text and ret_conf >= 0.7:
l,t,r,b = item[:4].astype('int')
# 绘制
cv2.rectangle(frame,(l,t),(r,b),(0,255,20),2)
# 绘制动作中文png
label_zh = palm_action[ret_label_text]
print(ret_label_text)
# 拿到对应中文文字的数组图片
overlay = self.png_dict[label_zh]
# 覆盖绘制
self.addOverylay(frame,overlay,l,t-100)
cv2.putText(frame,'{}%'.format(round(ret_conf*100,2)),(l+80,t-20),cv2.FONT_ITALIC,1.5,(255,0,255),2)
# 状态机列表中第一个0的索引
first_0_index = next(i for i,x in enumerate(self.yolo_action_status) if x == 0 )
# 对应动作名 ['ani_1', 'ani_2','ani_3', 'ani_4', 'ani_5', 'ani_6']
check_action_name = self.yolo_action_seq[first_0_index]
# 动作匹配
if ret_label_text == check_action_name:
# 赋值1
self.yolo_action_status[first_0_index] = 1
# 检查是否完毕
if self.yolo_action_status == [1,1,1,1,1,1,1]:
self.take_off_time = time.time()
print('动作全部匹配完')
self.backPlay('火遁豪火球.mp3')
# 计时
triger_time = time.time()
else:
print('击中一个动作,当前列表为'+str(self.yolo_action_status))
else:
print('未击中动作,当前列表为'+str(self.yolo_action_status))
cv2.imshow('demo', frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
if __name__ == '__main__':
# 实例化
ai_tello = Ai_tello()
ai_tello.cameraProcess()
代码有几个需要注意的:
一、加载 yolov5模型
加载 yolov5模型时,有可能出错,遇到的问题是版本不同,使用的是yolov5-5版本训练的,加载的文件不是,出错。
二、识别流程
识别采用的状态机方式,即事先定义一下数组【0,0,0,0,0,0,0】共7个元素,
当检测到对应动作时就置1,当数组全部为1时,就播放声音。
五、效果演示
如有侵权,或需要完整代码,请及时联系博主。