写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:[email protected]。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
打造未来智能应用的基石:腾讯混元大模型
本文关键字:腾讯云、大模型、AIGC、API调用、使用体验
文章目录
一、背景介绍
1. 什么是大模型
说起大模型,可能感觉是一个新词,但是相信你对最近一段时间以来层出不穷的各种AIGC【AI-Generated Content】工具一定并不陌生,包括各种聊天交互问答平台,文生图,图生图,以及各种嵌入形式的智能产品,如:AI辅助编程、AI写作软件等等。

这些软件的背后,无一例外都是由大模型在支持,只是对特定场景的优化程度不同,概况来说,它是一个大规模的语言模型或深度学习语言模型,有了这个模型我们可以基于它封装出各种各样的产品。
- 通常描述:大模型基于深度学习的神经网络技术,通过在大量的文本数据上进行训练而生成的模型。这种模型通常具有数十亿甚至数千亿的参数,可以理解和生成人类语言,用于各种自然语言处理和理解任务,包括但不限于文本分类、情感分析、机器翻译和问答系统。通过持续学习和微调,大模型可以理解和产生越来越高质量的文本,满足各种复杂的语言处理需求。
我们只需要知道,这个模型可以根据我们的输入来给出我们需要的输出,对于客户端界面我们可以根据应用场景封装出各式各样的产品。

2. AIGC扮演的角色
如果我们把大模型想象成一个超级智能的写作助手,它已经通过阅读和学习了大量的文本资料,从而学会了自然语言以及各种专业知识。于是我们可以问它各种问题,或让它帮我们写文案,编代码,或是作为一个辅助学习的有力帮手。此前,也引发了很多AI工具对各行业替代程度的讨论,以及AI所生成内容带来的一些问题,这里我们也稍微展开说明一下,让大家在使用以及了解的过程当中有一个更加全面的认识。

- 内容创作:内容创作是AIGC工具主要的应用形式,在理解了自然语言的基础上,我们还可以打造出可以交互式连续对话产品,不需要死板的输入各种指令,而是可以不断的修改和优化产出的内容。这些内容不限于各种文案,还可以是编程代码,知识问答,甚至直接输出图片、音频、影像。
- 主要影响:积极的一面自然是可以提高效率,对于重复性的工作可以瞬间以高标准快速完成,但有时生成的内容难免带一点AI味儿。同时,如果大量AI创作的内容涌入互联网也并不是一件好事,也使得虚假信息更难甄别。所以目前来看,我们在使用AIGC工具时还需要进行最后的人为干预,在封装产品时也要合理拒答安全诱导类问题,这也是一直以来致力解决的问题。
二、腾讯混元大模型
1. 产品介绍
腾讯混元大模型(Tencent Hunyuan)是由腾讯研发的大语言模型,具备强大的中文创作能力,复杂语境下的逻辑推理能力,以及可靠的任务执行能力。

目前,我们可以通过微信小程序来直接体验腾讯混元大模型,对于开发者,也开放了API接口的申请。
2. 核心优势

- 多轮对话:目前API调用最多支持30轮连续对话,可以对更多的场景提供很好的支持
- 内容创作:一键生成文章框架或内容,拓宽创作者思路并提供案例内容参考
- 逻辑推理:可以处理较为复杂的问题,如根据需求编写程序等
- 知识增强:持续终身训练为答案的时效性做出进一步的保障
- 多模态:继续拓宽输出内容形式,未来可期

3. 应用场景
目前腾讯混元大模型已经和多种产品进行了深度结合,包括文档编写、会议记录与总结、智能广告、营销文案等等。

可以访问产品首页查看演示视频:https://cloud.tencent.com/product/hunyuan
三、小程序抢先体验
小编有幸可以参加小程序的体验尝鲜,其实自己从2022年7月开始就开始用AIGC工具,接触了很多平台和软件,虽然大部分功能都不错,但是毕竟还是不太符合国人的习惯。这次在小程序中使用也是第一次,于是各方面都鼓捣了一下:
1. 主要界面

整体的操作界面以聊天交互式为主,可以直接输入文本或使用语音输入。
2. 指令集
值得一提的是这里显式的给出了指令集,也就相当于是给AI先安排一个角色,让它能够帮助我们更好的解决某些特定的问题,点击指令集后显示如下:
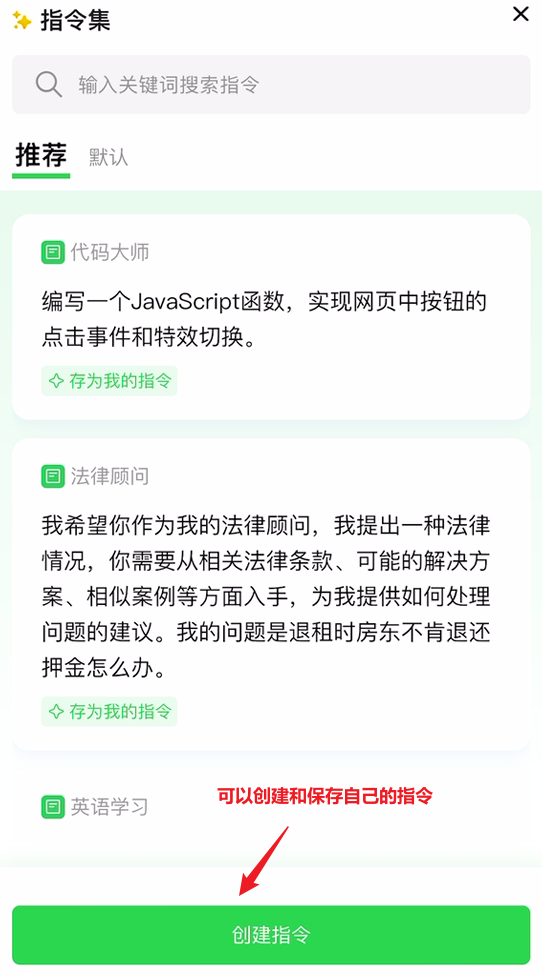
如果我们希望稍微修改指令中的描述,可以点击存为我的指令,然后我们可以编辑指令的内容、标题以及分类:

使用指令后,对应的指令内容会出现在输入框,在发送前可以最后修改,执行效果如下:


3. 灵感发现
灵感发现是另外一个特色功能,内置了很多各个场景的功能:

灵感发现与指令集还是有所区别的,相当于是一个比较完整的功能,点击之后是一个特定的功能,并且会给出一些选项,然后我们再以对话的方式继续表达我们的需求:
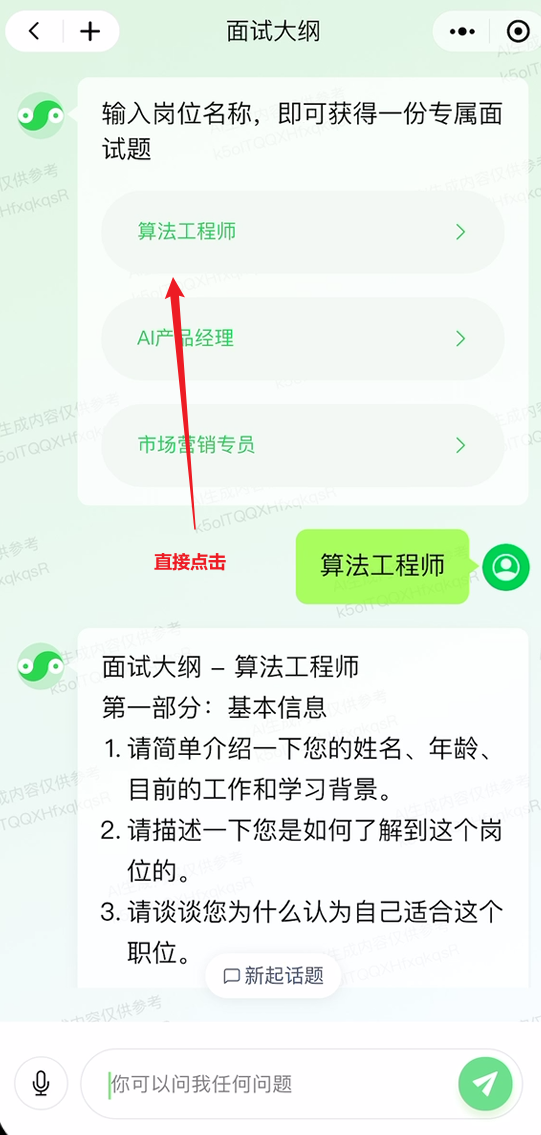
在使用的过程中,同样有可能会碰到答案内容过长,一次无法完全回答的情况,但是此时我们只需要点击继续,会将回答内容继续延长,而不会出现一条答案被分割成两条的情况,可以说是优化的十分用心了。
四、API开发调用
1. 接入指引
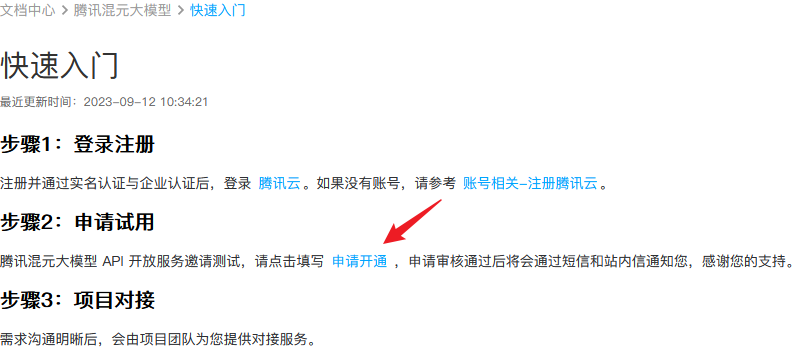
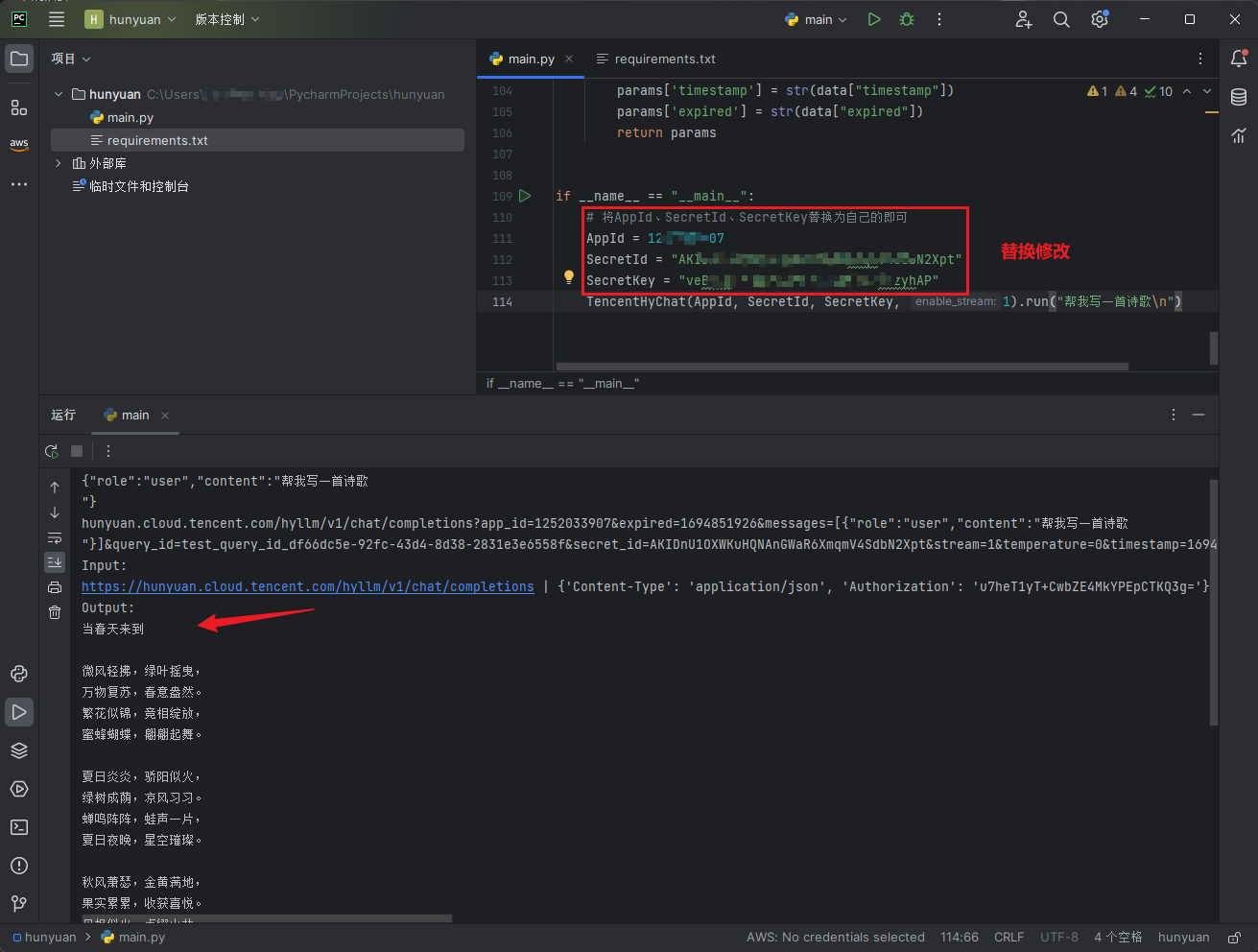
点击文档中的链接,先准备好需要的APPID和SecretId、SecretKey。
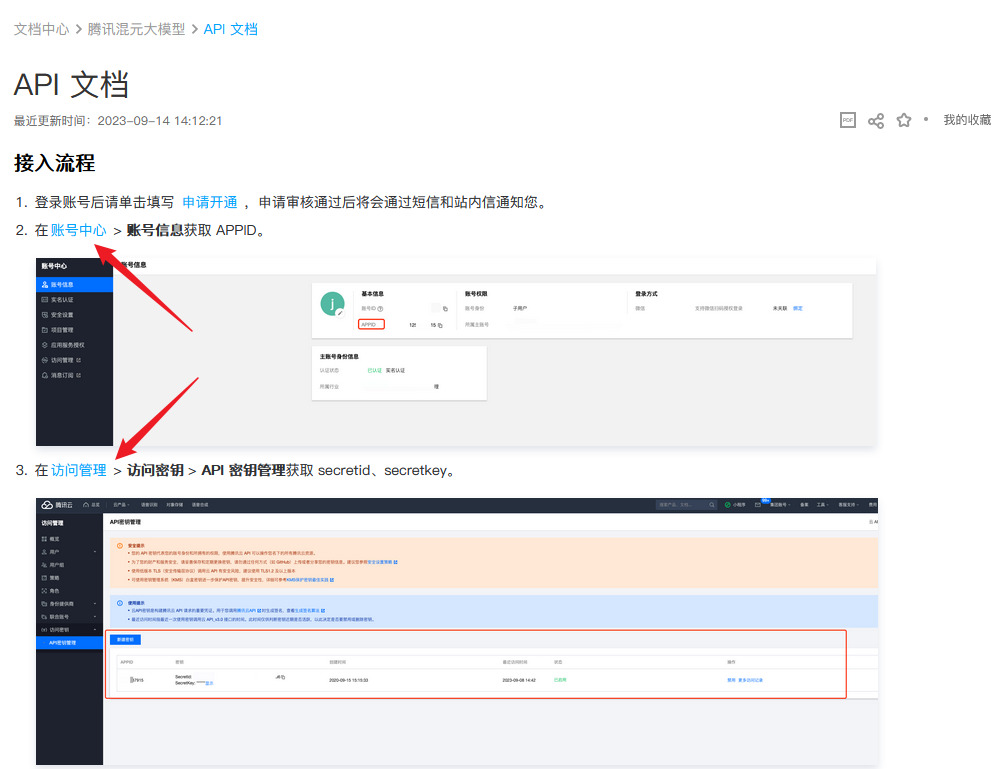
- 案例运行
首先我们在本地新建一个Anaconda环境【可以更好的区分管理依赖】或者直接新建一个Python项目,版本需要在3.x,新建一个py文件完整粘贴官方代码,同时创建一个requirements.txt放在同级目录:
brotlipy==0.7.0
sseclient-py==1.7.2
requests~=2.31.0
这里需要特别注意,sseclient-py一定要使用1.7.2版本,然后我们进入到项目路径,执行以下命令即可完成依赖的安装:
pip install -r requirements.txt
如果还缺少其它依赖可以根据提示进行安装,版本没有特别的要求。接下来只需要修改结尾main方法中的AppId、SecretId、SecretKey即可直接运行,前提是API已经正常开通:
2. 交互对话
官方案例实现之后,我们稍微做”亿点点“的修改,让它能够支持连续对话,我们可以现在输出控制台和它进行交互,并且借鉴这个思路,很容易封装成可以支持Web服务请求的封装接口,这样我们可以将其接入一些比较美观的前端界面,一个智能助手马上就可以诞生了。
- 完整代码:
# -*- coding: utf-8 -*-
# 运行环境python3
# 如果使用出错请注意sse版本是否正确, pip3 install sseclient-py==1.7.2
import time
import urllib
import uuid
import json
import requests
import sseclient
import hmac
import hashlib
import base64
_SIGN_HOST = "hunyuan.cloud.tencent.com"
_SIGN_PATH = "hyllm/v1/chat/completions"
_URL = 'https://hunyuan.cloud.tencent.com/hyllm/v1/chat/completions'
class TencentHyChat:
def __init__(self, appid, secretid, secretkey, enable_stream):
self.appid = appid
self.secretid = secretid
self.secretkey = secretkey
self.enable_stream = enable_stream
self.dialog_rounds = []
def __gen_signature(self, param):
sort_dict = sorted(param.keys())
sign_str = _SIGN_HOST + "/" + _SIGN_PATH + "?"
for key in sort_dict:
sign_str = sign_str + key + "=" + str(param[key]) + '&'
sign_str = sign_str[:-1]
hmacstr = hmac.new(self.secretkey.encode('utf-8'),
sign_str.encode('utf-8'), hashlib.sha1).digest()
s = base64.b64encode(hmacstr)
s = s.decode('utf-8')
return s
def __gen_sign_params(self, data):
params = dict()
params['app_id'] = data["app_id"]
params['secret_id'] = data['secret_id']
params['query_id'] = data['query_id']
# float类型签名使用%g方式,浮点数字(根据值的大小采用%e或%f)
params['temperature'] = '%g' % data['temperature']
params['top_p'] = '%g' % data['top_p']
params['stream'] = data["stream"]
messagestr = ""
# 数组按照json结构拼接字符串
for message in data["messages"]:
content = message["content"]
messagestr += '{"role":"' + message["role"] + '","content":"' + content + '"},'
messagestr = messagestr.strip(",")
params['messages'] = r"[{}]".format(messagestr)
params['timestamp'] = str(data["timestamp"])
params['expired'] = str(data["expired"])
return params
def __get_params(self, dialog_rounds):
timestamp = int(time.time()) + 10000
json_data = {
"app_id": self.appid,
"secret_id": self.secretid,
"query_id": "test_query_id_" + str(uuid.uuid4()),
"messages": dialog_rounds,
"temperature": 0.0,
"top_p": 0.8,
"stream": self.enable_stream,
"timestamp": timestamp,
"expired": timestamp + 24 * 60 * 60
}
return json_data
def run_chat(self):
while True:
user_input = input("You: ")
self.dialog_rounds.append({
"role": "user", "content": user_input})
if len(self.dialog_rounds) > 30:
self.dialog_rounds.pop(0) # 如果对话历史超过 30 轮,删除最早的对话
request = self.__get_params(self.dialog_rounds)
signature = self.__gen_signature(self.__gen_sign_params(request))
headers = {
"Content-Type": "application/json",
"Authorization": str(signature)
}
URL = _URL
resp = requests.post(URL, headers=headers, json=request, stream=True)
if self.enable_stream == 1:
client = sseclient.SSEClient(resp)
resp = ""
for event in client.events():
if event.data != '':
data_js = json.loads(event.data)
try:
if data_js['choices'][0]['finish_reason'] == 'stop':
break
assistant_content = data_js['choices'][0]['delta']['content']
resp += assistant_content
except Exception as e:
print(e)
print(data_js)
print(f"Assistant: {
resp}")
self.dialog_rounds.append({
"role": "assistant", "content": resp})
else:
response_data = resp.json()
assistant_content = response_data['choices'][0]['delta']['content']
print(f"Assistant: {
assistant_content}")
self.dialog_rounds.append({
"role": "assistant", "content": assistant_content})
if __name__ == "__main__":
# 将AppId、SecretId、SecretKey替换为自己的即可
AppId = xxx
SecretId = "xxx"
SecretKey = "xxx"
TencentHyChat(AppId, SecretId, SecretKey, 1).run_chat()
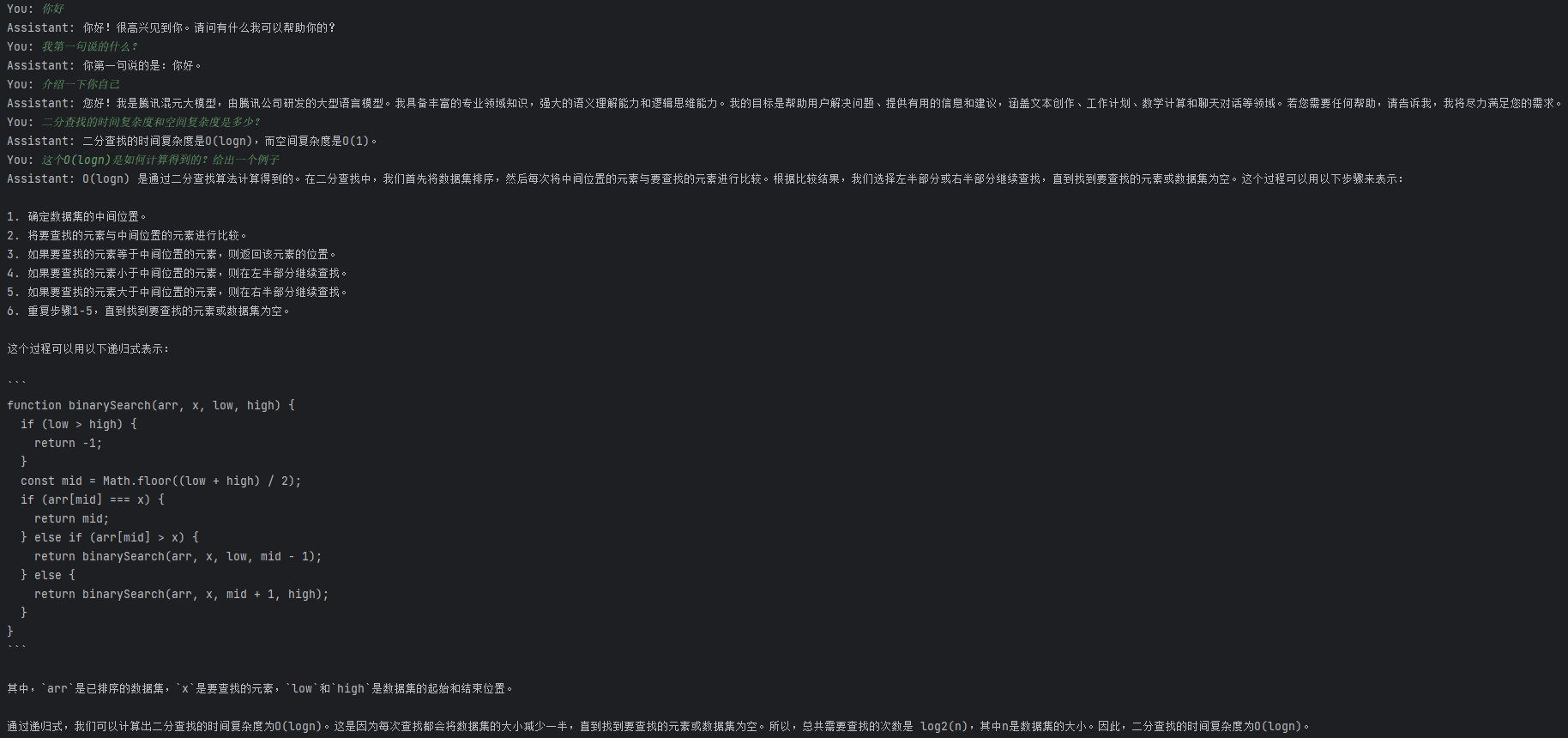
重新封装了代码,去掉了不需要的输出,于是我们得到了交互式的体验:
五、结语
整体体验下来,不得不感叹腾讯混元大模型与各应用结合的速度,同时和多个场景能够很好的结合,很符合国人的需求,并且有简单易用的小程序独立应用,而且这才只是刚刚起步。对于开发者来说,也可以快速而方便的接入,瞬间就可以将自己的产品智能化,相信混元大模型可以成为打造未来智能应用的基石!
- 插播一条重要消息:首批通过备案!腾讯混元大模型将陆续对公众开放

在腾讯全球数字生态大会上,腾讯混元大模型正式亮相,并通过腾讯云对外开放,客户可以直接通过API调用,也可以将腾讯混元大模型作为基底模型,在公有云上进行精调,为不同产业场景构建专属应用。