Datawhale干货
作者:王大鹏,Datawhale成员
大家好,我是大鹏,周末看到朋友转发的⼀篇文章:《那些年,为了进阿里背过的面试题》。
本文作者公众号
感叹失败的原因可能有很多,而做成的道路只有⼀条,那就是不断积累。纯手工的8291字的SQL面试题总结分享给初学者,俗称八股文,期待对新手有所帮助。
(Datawhale公众号后台回复:SQL面试题 可获取完整PDF资料)
窗口函数题
窗口函数其实就是根据当前数据, 计算其在所在的组中的统计数据。
窗口函数和group by得区别就是,groupby的聚合对每一个组只有一个结果,但是窗口函数可以对每一条数据都有一个结果。
商品类别数据集
一. 从数据集中得到每个类别收入第一的商品和收入第二的商品。
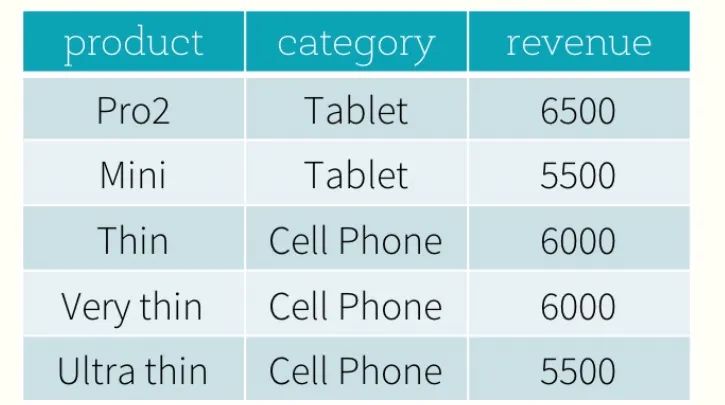
思路:计算每一个类别的按照收入排序的序号,然后取每个类别中的前两个数据。
总结答案:
SELECT
product,
category,
revenue
FROM (
SELECT
product,
category,
revenue,
dense_rank() OVER w as 'rank'
FROM productRevenue
WINDOW w as (PARTITION BY category ORDER BY revenue DESC)
) tmp
WHERE
'rank' <= 2;按照类别进行分组,且每个类别中的数据按照收入进行排序,并为排序过的数据增加编号:
SELECT product,
category,
revenue,
dense_rank() OVER w as 'rank'
FROM productRevenue
WINDOW w as (PARTITION BY category ORDER BY revenue DESC);根据编号,取得每个类别中的前两个数据作为最终结果;
二. 统计每个商品和此品类最贵商品之间的差值
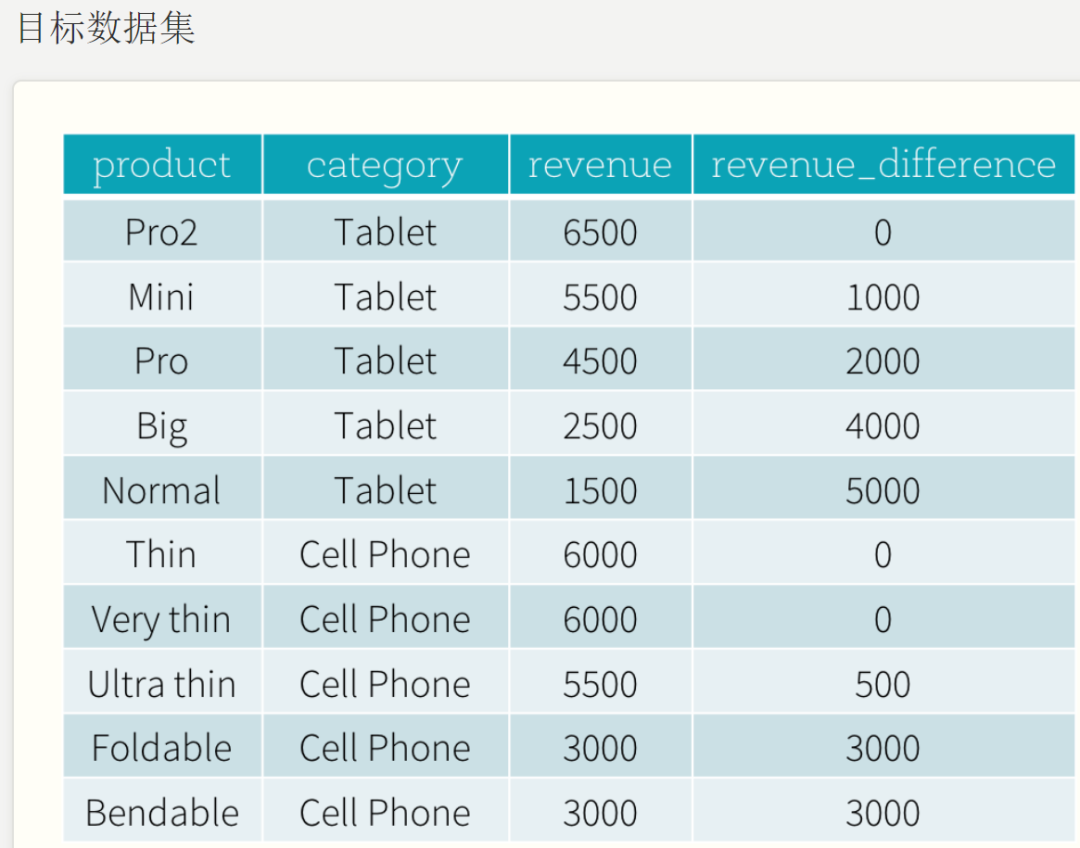
总结答案:
SELECT
product,
category,
revenue,
MAX(revenue) OVER w - revenue as revenue_difference
FROM productRevenue
WINDOW w as (PARTITION BY category ORDER BY revenue DESC);首先创建窗口,按照类别进行分组,并对价格倒叙排列;
应用窗口,求出每个组内的价格最大值,对其减去商品的价格,起别名。
用户表(时长,用户id)
查询某一天中时长最高的60% 用户的平均时长
总结答案:
with aa as(
select
*,
row_number() over(
order by
时长 desc
) as rank_duration
from
表
where
package_name = 'com.miHoYo.cloudgames.ys'
and date = 20210818
)
select
avg(时长)
from
aa
where
rank_duration <= (
select
max(rank_duration)
from
aa
) * 0.6;这是排名问题,排名问题可以考虑用窗口函数去解决。
将问题拆分为:
1) 找出时长前60%的用户;
2) 剔除访问次数前20%的用户
首先找某天的数据,按时长降序从高到低进行排名,注意要用row_number,相相等的话也会往后算数:
select
*,
row_number() over(
order by duration desc
) as rank_duration
from
表
where
package_name = 'com.miHoYo.cloudgames.ys'
and date = 20210818;排完名后,要找出前60%的用户:
**用户排名值<=最大的排名值 * 60%**,就是前60%的用户数据。
最大的排名值通过max(排名)来得到。
把排名结果表作为临时表,但是要注意的是,临时表只能用其中的字段,但是不能当作表来用。所以需要用with as语句将排名作为临时表。
用户签到表
有一张用户签到表【t_user_attendence】,标记每天用户是否签到(说明:该表包含所有用户所有工作日的出勤记录) ,包含三个字段:日期【fdate】,用户 id【fuser_id】,用户当天是否签到【fis_sign_in:0 否 1 是】
计算截至当前每个用户已经连续签到的天数
计算最近一次未签到的日期,再用当前日期减去那个日期
select
fuser_id,
datediff(CURDATE(), fdate_max) as fcon,
secutive_days
from
(
select
fuser_id,
max(fdate) as fdate_max
from
t_user_attendence
where
fis_sign_in = 0
group by
fuser_id
) t1;请计算每个用户历史以来最大的连续签到天数
思路1:把相同数值进行分组再自然连续排序,两个排序相减得到差值 t,若数值连续,则差值 t 相等。
先按人分组按天进行自然连续排序,再只取签到部分,按人分组进行自然连续排序,相差得到差值 diff1;再按照差值 diff1 分组计数,得到每人连续签到的天数,求最大值即可。
SELECT
fuser_id,
max(ct) as max_ct
FROM
(
SELECT
fuser_id,
diff1,
count(diff1) as ct
FROM
(
SELECT
*,
row_number() over (
PARTITION by fuser_id
ORDER BY
fdate
) as or2,
or1 - row_number() over (
PARTITION by fuser_id
ORDER BY
fdate
) as diff1
FROM
(
SELECT
fdate,
fuser_id,
fis_sign_in,
row_number() over (
partition by fuser_id
order by
fdate
) as or1
from
t_user_attendence
order by
fuser_id,
fdate
) t
where
fis_sign_in = 1
) t2
GROUP BY
fuser_id,
diff1
) t3
GROUP BY
fuser_id;思路2:把相同数值进行分组再自然连续排序,两个排序相减得到差值 t,若数值连续,则差值 t 相等。
SELECT
log_id, log_date
max(ct) as max_ct
FROM
(
SELECT
log_id,
diff1,
count(diff1) as ct
log_date
FROM
(
SELECT
*,
row_number() over (
PARTITION by log_id
ORDER BY
log_date
) as or2,
or1 - row_number() over (
PARTITION by log_id
ORDER BY
log_date
) as diff1
FROM
(
SELECT
log_id,
log_date,
row_number() over (
partition by log_id
order by
log_date
) as or1
from
log_info
order by
log_id,
log_date
) t
) t2
GROUP BY
log_id,
diff1,
log_date
) t3
GROUP BY
fuser_id, log_date;用户行为信息表
给你一个表,表中有两列数据:date和user_id,计算次日留存用户数
基础版本
**答案--**产出结果:第一列为时间,第二列为次日留存用户数;(简单实现)
SELECT b_time_load, COUNT(DISTINCT case when diff=1 then id else null end)as liucun_num
FROM
(
SELECT *, TIMESTAMPDIFF(DAY,a_time_load, b_time_load) as diff
FROM
(
SELECT a.id, a.time_load as a_time_load,b.time_load as b_time_load
FROM user_move as a
LEFT JOIN user_move as b
on a.id = b.id
)as c
)as d
GROUP BY b_time_load;实现思路:
次日留存用户数:在今日登录,明天也有登录的用户数。也就是时间间隔 = 1。
当一个表如果涉及到时间间隔,就需要用到自联结,也就是将相同的表进行联结。
第一步:因为要算时间间隔,因此需要先对表进行自联结:
select a.用户id,a.登陆时间,b.登陆时间
from 用户行为信息表 as a
left join 用户行为信息表 as b
on a.用户id = b.用户id
where a.应用名称= '相机';
// 根据条件看是否要加最后一句where。
第二步:计算两个日期的差值--
select *,timestampdiff(day,a.登陆时间,b.登陆时间) as 时间间隔
from c;
第三步:用case选出时间间隔为1的数据:
count(distinct case when 时间间隔=1 then 用户id else null end) as 次日留存数优化点
考虑表的日期分区
考虑对用户的去重,比如一天内登录多次的情况
考虑count distinct的效率,在前面就对diff = 1当作条件过滤,而不选择加在case when里做处理;
同上,求次日留存率
留存率 = 新增用户****中登录用户数 / 新增用户数,所以次日留存率 = 次日留存用户数 / 当日用户活跃数;
当日活跃用户数是 count(distinct 用户 id),用次日留存用户数 / 当日用户活跃数就是次日留存率:
SELECT b_time_load, COUNT(DISTINCT case when diff=1 then id else null end) as liucun_num, COUNT(DISTINCT case when diff=1 then id else null end)/ count(distinct id) as liucun_rate
FROM
(
SELECT *, TIMESTAMPDIFF(DAY,a_time_load, b_time_load) as diff
FROM
(
SELECT a.id, a.time_load as a_time_load,b.time_load as b_time_load
FROM user_move as a
LEFT JOIN user_move as b
on a.id = b.id
)as c
)as d
GROUP BY b_time_load每天的活跃用户数
select 登陆时间,count(distinct 用户id) as 活跃用户数
from 用户行为信息表
where 应用名称 ='相机'
group by 登陆时间;三日的留存数,三日留存率, 七日的留存数, 七日留存率
将diff后的数字改为3/7即可。
SELECT b_time_load, COUNT(DISTINCT case when diff=3 then id else null end) as liucun_num, COUNT(DISTINCT case when diff=3 then id else null end)/ count(distinct id) as liucun_rate
FROM
(
SELECT *, TIMESTAMPDIFF(DAY,a_time_load, b_time_load) as diff
FROM
(
SELECT a.id, a.time_load as a_time_load,b.time_load as b_time_load
FROM user_move as a
LEFT JOIN user_move as b
on a.id = b.id
)as c
)as d
GROUP BY b_time_load给定两张表订单表和用户表:查询2019年Q1季度,不同性别,不同年龄的成交用户数,成交量及成交金额
根据性别、年龄进行分组,利用多表连接及聚合函数求出成交用户数,成交量及成交金额。
select b.性别,b.age,
count(distinct a.用户id) as 用户数,
count(订单id),
sum(a.订单金额)
from 订单表 as a
inner join 用户表 as b
on a.用户id = b.用户id
where a.时间 between '2019-01-01' and '2019-03-31'
group by b.性别,b.age;给定两张表:订单表和用户表,2019年1-4月产生订单的用户,以及在次月的留存用户数
select a.用户id,
COUNT(case when TIMESTAMPDIFF(month,a.时间, b.时间)=1 then a.用户id else null end) as liucun_num
from 订单表 as a join 订单表 as b
on a.用户id = b.用户id
where a.时间 between '2019-01-01' and '2019-04-30'
group by a.用户id给定一个表,表里两个字段:user_id, date_key,找出来今日登录(2021-05-16)且一周内没有登录的用户id:
第一步,先把date_key字段类型处理成日期形式;
第二步,查找最近一周的用户登录;
第三步,查找今日登录的用户id,不在最近一周登录的id里的
select distinct user_id, date_format(date_key, '%Y-%m-%d') as login_date
from 用户行为信息表
where date_format(date_key, '%Y-%m-%d') ='2021-05-16'
and user_id not in
(select distinct user_id
from 用户行为信息表
WHERE DATEDIFF('2021-05-16',date_key)<=7 and DATEDIFF('2021-05-16',date_key)>0 )
order by user_id;员工表
有3个表dept(部门表),emp(员工表),salgrade(薪水等级表):
dept(DEPTNO,DNAME,LOC)代表(部门编号,部门名称,位置)
emp(EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO)代表(员工编号,员工姓名,工作岗位,上级经理编号, 入职日期)
salgrade(GRADE,LOSAL,HISAL)代表(薪水级别,最低薪水,最高薪水)
取得每个部门最高薪水的人员名称
答案
select e.deptno, e.ename, t.maxsal, e.sal
from (
select e.deptno, max(e.sal) as maxsal
from emp e
group by e.deptno
) t
join emp e
on t.deptno = e.deptno
where t.maxsal = e.sal
order by e.deptno;第一步:求出每个部门的最高薪水:
select e.deptno, max(e.sal) as maxsal
from emp e
group by e.deptno;
+--------+---------+
| deptno | maxsal |
+--------+---------+
| 10 | 5000.00 |
| 20 | 3000.00 |
| 30 | 2850.00 |
+--------+---------+第二步:将以上查询结果当成一个临时表
select e.deptno, e.ename, t.maxsal, e.sal
from t
join emp e
on t.deptno = e.deptno
where t.maxsal = e.sal
order by e.deptno;
+--------+-------+---------+---------+
| deptno | ename | maxsal | sal |
+--------+-------+---------+---------+
| 10 | KING | 5000.00 | 5000.00 |
| 20 | SCOTT | 3000.00 | 3000.00 |
| 20 | FORD | 3000.00 | 3000.00 |
| 30 | BLAKE | 2850.00 | 2850.00 |
+--------+-------+---------+---------+
最后把t换下。哪些人的薪水在部门平均薪水之上
答案
select t.detpno, e.ename
from (select e.deptno, avg(e.sal) as avgsal
from emp e
group by e.deptno) t
join emp e
on e.deptno = t.deptno
where e.sal > t.avgsal;第一步:求出每个部门的平均薪水
select e.deptno, avg(e.sal) as avgsal
from emp e
group by e.deptno;
+--------+-------------+
| deptno | avgsal |
+--------+-------------+
| 10 | 2916.666667 |
| 20 | 2175.000000 |
| 30 | 1566.666667 |
+--------+-------------+第二步:需要保证员工在这个部门里,将以上查询结果当成临时表t(deptno, avgsal)
select t.detpno, e.ename
from t
join emp e
on e.deptno = t.deptno
where e.sal > t.avgsal;第三步:把临时表t进行替换
select t.detpno, e.ename
from (select e.deptno, avg(e.sal) as avgsal
from emp e
group by e.deptno) t
join emp e
on e.deptno = t.deptno
where e.sal > t.avgsal;
+--------+-------+
| deptno | ename |
+--------+-------+
| 30 | ALLEN |
| 20 | JONES |
| 30 | BLAKE |
| 20 | SCOTT |
| 10 | KING |
| 20 | FORD |
+--------+-------+取得部门中(所有人的)平均薪水等级
取得部门中所有人的平均薪水的等级
答案
select t.deptno, t.avgsal, s.grade
from (select e.deptno, avg(e.sal) as avgsal
from emp e
group by e.deptno) t
join salgrade s
on t.avgsal between s.losal and s.hisal;第一步:求出每个部门的平均薪水
select e.deptno, avg(e.sal) as avgsal
from emp e
group by e.deptno;
+--------+-------------+
| deptno | avgsal |
+--------+-------------+
| 10 | 2916.666667 |
| 20 | 2175.000000 |
| 30 | 1566.666667 |
+--------+-------------+第二步:将以上表作为临时表t,根据平均薪水在等级表中进行比对
select t.deptno, t.avgsal, s.grade
from t
join salgrade s
on t.avgsal between s.losal and s.hisal;第三步:把临时表t替换为子查询
select t.deptno, t.avgsal, s.grade
from (select e.deptno, avg(e.sal) as avgsal
from emp e
group by e.deptno) t
join salgrade s
on t.avgsal between s.losal and s.hisal;
+--------+-------------+-------+
| deptno | avgsal | grade |
+--------+-------------+-------+
| 30 | 1566.666667 | 3 |
| 10 | 2916.666667 | 4 |
| 20 | 2175.000000 | 4 |
+--------+-------------+-------+取得部门中所有人的平均的薪水等级
答案
select t.deptno, avg(t.grade) as avgGrade
from (
select e.deptno, e.ename, s.grade
from emp e
join salgrade s
on e.sal between s.losal and s.hisal
order by e.deptno
)
group by t.deptno;第一步:求出每个人的薪水等级
select xxx
from emp e
join salgrade s
on e.sal between s.losal and s.hisal
order by e.deptno;
+--------+--------+-------+
| deptno | ename | grade |
+--------+--------+-------+
| 10 | CLARK | 4 |
| 10 | MILLER | 2 |
| 10 | KING | 5 |
+--------+--------+-------+
xxx为:e.deptno, e.ename, s.grade
(求得是部门等级值得平均值)第二步:求出每组薪水的平均值
select t.deptno, avg(t.grade) as avgGrade
from t
group by t.deptno;
+--------+----------+
| deptno | avgGrade |
+--------+----------+
| 10 | 3.6667 |
| 20 | 2.8000 |
| 30 | 2.5000 |
+--------+----------+不用组函数,取得最高薪水(给出两种解决方案)
方案一:
select sal
from emp
order by sal desc limit 1;方案二:两个表进行比较
select sal from emp
where sal not in(
select distinct a.sal
from emp a
join emp b
on a.sal < b.sal);取得平均薪水最高的部门的部门编号
答案
select e.deptno, avg(e.sal) as avgsal
from emp e
group by e.deptno
having avgsal = (select max(t.avgsal) as maxAvgSal from
(
select e.deptno, avg(e.sal) as avgsal
from emp e
group by e.deptno
)
);第一步:求出部门平均薪水
select e.deptno, avg(e.sal) as avgsal
from emp e
group by e.deptno;
+--------+-------------+
| deptno | avgsal |
+--------+-------------+
| 10 | 2916.666667 |
| 20 | 2175.000000 |
| 30 | 1566.666667 |
+--------+-------------+第二步:将以上查询结果当作临时表t
select max(t.avgsal) as maxAvgSal from t;
+-------------+
| maxAvgSal |
+-------------+
| 2916.666667 |
+-------------+第三步:最大的平均值有了,用其做过滤
select e.deptno, avg(e.sal) as avgsal
from emp e
group by e.deptno
having avgsal = (select max(t.avgsal) as maxAvgSal from t);
+--------+-------------+
| deptno | avgsal |
+--------+-------------+
| 10 | 2916.666667 |
+--------+-------------+取得平均薪水最高的部门的部门名称
部门名称在dept表
select e.deptno, d.dname, avg(e.sal) as avgsal
from emp e
join dept d
on e.deptno = d.deptno
group by e.deptno, d.dname
having avgsal = (select max(t.avgsal) as maxAvgSal from t);求平均薪水的等级最低的部门的部门名称
答案
select
t.deptno,t.dname,s.grade
from
(select
e.deptno,d.dname,avg(e.sal) as avgsal
from
emp e
join
dept d
on
e.deptno = d.deptno
group by
e.deptno,d.dname)t
join
salgrade s
on
t.avgsal between s.losal and s.hisal
where
s.grade = (select min(t.grade) as minGrade from (select
t.deptno,t.dname,s.grade
from
(select
e.deptno,d.dname,avg(e.sal) as avgsal
from
emp e
join
dept d
on
e.deptno = d.deptno
group by
e.deptno,d.dname)t
join
salgrade s
on
t.avgsal between s.losal and s.hisal)t);第一步:求出部门的平均薪水
select
e.deptno,d.dname,avg(e.sal) as avgsal
from
emp e
join
dept d
on
e.deptno = d.deptno
group by
e.deptno,d.dname;
+--------+------------+-------------+
| deptno | dname | avgsal |
+--------+------------+-------------+
| 10 | ACCOUNTING | 2916.666667 |
| 20 | RESEARCH | 2175.000000 |
| 30 | SALES | 1566.666667 |
+--------+------------+-------------+第二步:将以上查询结果当作临时表t,与salgrade表进行表连接
select
t.deptno,t.dname,s.grade
from
(select
e.deptno,d.dname,avg(e.sal) as avgsal
from
emp e
join
dept d
on
e.deptno = d.deptno
group by
e.deptno,d.dname)t
join
salgrade s
on
t.avgsal between s.losal and s.hisal;
+--------+------------+-------+
| deptno | dname | grade |
+--------+------------+-------+
| 30 | SALES | 3 |
| 10 | ACCOUNTING | 4 |
| 20 | RESEARCH | 4 |
+--------+------------+-------+排序求是不对的,得先求出最低等级。
第三步:将以上查询结果当成一张临时表t
select min(t.grade) as minGrade from (select
t.deptno,t.dname,s.grade
from
(select
e.deptno,d.dname,avg(e.sal) as avgsal
from
emp e
join
dept d
on
e.deptno = d.deptno
group by
e.deptno,d.dname)t
join
salgrade s
on
t.avgsal between s.losal and s.hisal)t;
+----------+
| minGrade |
+----------+
| 3 |
+----------+第四步:最终
select
t.deptno,t.dname,s.grade
from
(select
e.deptno,d.dname,avg(e.sal) as avgsal
from
emp e
join
dept d
on
e.deptno = d.deptno
group by
e.deptno,d.dname)t
join
salgrade s
on
t.avgsal between s.losal and s.hisal
where
s.grade = (select min(t.grade) as minGrade from (select
t.deptno,t.dname,s.grade
from
(select
e.deptno,d.dname,avg(e.sal) as avgsal
from
emp e
join
dept d
on
e.deptno = d.deptno
group by
e.deptno,d.dname)t
join
salgrade s
on
t.avgsal between s.losal and s.hisal)t);
+--------+-------+-------+
| deptno | dname | grade |
+--------+-------+-------+
| 30 | SALES | 3 |
+--------+-------+-------+取得比普通员工(员工代码没有在mgr上出现的)的最高薪水还要高的经理人姓名
答案
select ename from emp
where sal > (
select max(sal) as maxsal
from emp
where empno not in(
select distinct mgr from emp
where mgr is not null
)
);第一步:找出普通员工(员工代码没有出现在mgr上的)
先找出mgr有哪些人
select distinct mgr from emp;
+------+
| mgr |
+------+
| 7902 |
| 7698 |
| 7839 |
| 7566 |
| NULL |
| 7788 |
| 7782 |
+------+第二步:求出普通员工得最高薪水
select max(sal) as maxsal from emp where empno not in(select distinct mgr from emp where mgr is not null);
+---------+
| maxsal |
+---------+
| 1600.00 |
+---------+not in不会自动忽略空值,in会自动忽略空值。一旦没有忽略空值,None就会参与数学运算,结果就变为了None。not in是and, in参数关系是or。
第三步:比普通员工最高薪水还要高的
select ename from emp where sal > (
select max(sal) as maxsal from emp where empno not in(
select distinct mgr from emp where mgr is not null
)
);
+-------+
| ename |
+-------+
| JONES |
| BLAKE |
| CLARK |
| SCOTT |
| KING |
| FORD |
+-------+取得薪水最高的前五名员工
select * from emp order by sal desc limit 0,5;取得薪水最高的第六到第十名员工
select * from emp order by sal desc limit 5,5;取得最后入职的5名员工
select * from emp order by hiredate desc limit 5;取得每个薪水等级有多少员工
答案
select
t.grade,count(t.ename) as totalEmp
from
(select
e.ename,s.grade
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal) t
group by
t.grade;第一步:查询出每个员工的薪水等级
select
e.ename,s.grade
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal
order by
s.grade;
+--------+-------+
| ename | grade |
+--------+-------+
| JAMES | 1 |
| SMITH | 1 |
| ADAMS | 1 |
| MILLER | 2 |
| WARD | 2 |
| MARTIN | 2 |
| ALLEN | 3 |
| TURNER | 3 |
| BLAKE | 4 |
| FORD | 4 |
| CLARK | 4 |
| SCOTT | 4 |
| JONES | 4 |
| KING | 5 |
+--------+-------+第二步:将以上查询结果当成临时表t(ename,grade)
select
t.grade,count(t.ename) as totalEmp
from
(select
e.ename,s.grade
from
emp e
join
salgrade s
on
e.sal between s.losal and s.hisal) t
group by
t.grade;
+-------+----------+
| grade | totalEmp |
+-------+----------+
| 1 | 3 |
| 2 | 3 |
| 3 | 2 |
| 4 | 5 |
| 5 | 1 |
+-------+----------+列出所有员工及领导的名字
select
e.ename, b.ename as leadername
from
emp e
left join
emp b
on
e.mgr = b.empno;--(不用left连接的话,最高级的员工不会显示。用了left后,最高级的员工会显示,其---- leader为null。外连接查询的条数永远>=内连接)
列出受雇日期早于其直接上级的所有员工编号、姓名、部门名称
思路一:第一步将****emp a看成员工表,将emp b 看成领导表,员工表的mgr字段应该等于领导表的主键字段
select
e.empno,
e.ename
from
emp e
join
emp b
on
e.mgr = b.empno
where
e.hiredate < b.hiredate;
+-------+-------+
| empno | ename |
+-------+-------+
| 7369 | SMITH |
| 7499 | ALLEN |
| 7521 | WARD |
| 7566 | JONES |
| 7698 | BLAKE |
| 7782 | CLARK |
| 7876 | ADAMS |
+-------+-------+第二步:显示上面员工的部门名称,将****emp a员工表和dept d进行关联
select
d.dname,
e.empno,
e.ename
from
emp e
join
emp b
on
e.mgr = b.empno
join
dept d
on
e.deptno = d.deptno
where
e.hiredate < b.hiredate;
+------------+-------+-------+
| dname | empno | ename |
+------------+-------+-------+
| ACCOUNTING | 7782 | CLARK |
| RESEARCH | 7369 | SMITH |
| RESEARCH | 7566 | JONES |
| RESEARCH | 7876 | ADAMS |
| SALES | 7499 | ALLEN |
| SALES | 7521 | WARD |
| SALES | 7698 | BLAKE |
+------------+-------+-------+列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门
select
d.dname,(部门名称)
e.*(该部门的员工信息)
from
emp e
right join
dept d
on
e.deptno = d.deptno;
(需要让所有的部门显示出来,因此需要用右外连接)
内连接和外连接分别省略了inner和outer关键字列出至少有5个员工的所有部门
第一步:先求出每个部门有多少员工,将****emp a和部门表 dept d表进行关联,条件是e.deptno=d.deptno
第二步:然后通过分组e.deptno,过来count(e.ename) >= 5
select
e.deptno,count(e.ename) as totalEmp
from
emp e
group by
e.deptno
having
totalEmp >= 5;
+--------+----------+
| deptno | totalEmp |
+--------+----------+
| 20 | 5 |
| 30 | 6 |
+--------+----------+
2 rows in set这里比较关键:第一点 使用了group by 字段,select 后面的字段只能是group by后面的字段e.deptno和聚合函数对应的字段count(e.ename) as totalEmp
第二点:现在要对聚合函数的结果进行过滤,totalEmp字段不是数据库中的字段,不能使用where进行限制,只能使用having。
(子查询)列出薪水比“SMITH”多的所有员工信息
第一步:首先求出是,smith的工资
第二步:然后求出工资高于simith的
select * from emp where sal > (select sal from emp where ename = 'SMITH');列出所有"CLERK"(办事员)的姓名及其部门名称,部门人数
答案
select t1.deptno, t1.dname, t1.ename, t2.totalEmp
from (
select d.deptno, d.dname, e.ename
from emp e
join dept d
on e.deptno = d.deptno
where e.job = 'CLERK'
)t1
join (
select e.deptno, count(e.ename) as totalEmp
from emp e
group by e.deptno
)t2
on t1.deptno = t2.deptno;1、第一步在emp a表中查询出那些人的job岗位是办事员
2、将emp a表和dept d表相关联就可以得到职位是办事员的emp对应的部门名称
3、查询出每个部门对应的员工总数
4、将第三步的查询结果作为一个临时表t与第二步的查询结果进行关联,关联条件是t.deptno = d.deptno
第一步先找出这一帮人
select d.deptno, d.dname, e.ename
from emp e
join dept d
on e.deptno = d.deptno
where e.job = 'CLERK';第二步求出每个部门的员工数量
select e.deptno, count(e.ename) as totalEmp
from emp e
group by e.deptno;
最后汇总,把t1表换成第一个sql,t2换成第二个sql:
select t1.deptno, t1.dname, t1.ename, t2.totalEmp
from t1
join t2
on t1.deptno = t2.deptno;(子查询)列出最低薪水大于1500的各种工作及从事此工作的全部雇员人数
第一步:先求出每个工作岗位的最低薪水,把>1500的留下
select e.job, min(e.sal) as minsal
from emp e
group by e.job
having minsal > 1500;第二步:添加count聚合函数,来查看人数
select e.job, min(e.sal) as minsal, count(e.ename)as totalEmp
from emp e
group by e.job
having minsal > 1500(子查询)列出在部门“SALES”<销售部>工作的员工的姓名,假定不知道销售部门的部门编号
答案
select ename from emp
where deptno = (
select deptno from dept where dname = 'SALES'
);第一步:先求出部门的部门编号;
select deptno from dept where dname = 'SALES';
+--------+
| deptno |
+--------+
| 30 |
+--------+第二步:再从部门select部门中的员工姓名;
select ename from emp where deptno = (select deptno from dept where dname = 'SALES');
+--------+
| ename |
+--------+
| ALLEN |
| WARD |
| MARTIN |
| BLAKE |
| TURNER |
| JAMES |(经典)列出薪金高于公司平均薪金的所有员工,所在部门、上级领导、雇员的工资等级
答案
select e.ename,d.dname, b.ename as leadername, s.grade
from emp e
join dept d
on e.deptno = d.deptnp
left join emp b
on e.mgr = b.empno --员工的领导编号 等于 领导的员工编号
join salgrade s
on e.sal between s.losal and s.hisal
where e.sal >(select avg(sal) as avgsal from emp);第一步:求出薪金高于公司平均薪金的所有员工
第二步:把第一步的结果当成临时表t 将临时表t和部门表 dept d 和工资等级表salary s进行关联,求出员工所在的部门,雇员的工资等级等
关联的条件是t.deptno = d.deptno t.salary betweent s.lower and high;
第三步:求出第一步条件下的所有的上级领导,因为有的员工没有上级领导需要使用left join 左连接
第一步:求出公司的平均薪水
select avg(sal) as avgsal from emp;
+-------------+
| avgsal |
+-------------+
| 2073.214286 |
+-------------+
第二步:列出薪水高于平均薪水的所有员工
select e.ename
from emp e
where e.sal >(select avg(sal) as avgsal from emp);
第三步:列出所有员工的所在部门(需要join on)
select e.ename,d.dname
from emp e
join dept d
on e.deptno = d.deptnp
where e.sal >(select avg(sal) as avgsal from emp);
第四步:列出所有员工的上级领导(需要join on)
select e.ename,d.dname, b.ename as leadername
from emp e
join dept d
on e.deptno = d.deptnp
join emp b
on e.mgr = b.emp --员工的领导编号 等于 领导的员工编号
where e.sal >(select avg(sal) as avgsal from emp);
第五步:要求列出所有员工,在第二个join,员工表是emp e表,否则会只显示有领导的员工
select e.ename,d.dname, b.ename as leadername
from emp e
join dept d
on e.deptno = d.deptnp
left join emp b
on e.mgr = b.empno --员工的领导编号 等于 领导的员工编号
where e.sal >(select avg(sal) as avgsal from emp);
第六步:雇员的工资等级
select e.ename,d.dname, b.ename as leadername, s.grade
from emp e
join dept d
on e.deptno = d.deptnp
left join emp b
on e.mgr = b.empno --员工的领导编号 等于 领导的员工编号
join salgrade s
on e.sal between s.losal and s.hisal
where e.sal >(select avg(sal) as avgsal from emp);列出与“SCOTT”从事相同工作的所有员工及部门名称
step1:查询出SCOTT的工作岗位
select job from emp where ename = 'SCOTT';
+---------+
| job |
+---------+
| ANALYST |
+---------+step2:部门名称(需要join部门表)
select
d.dname,
e.*
from
emp e
join
dept d
on
e.deptno = d.deptno
where
e.job = (select job from emp where ename = 'SCOTT');列出薪金中等于第30号部门中员工的薪金的其它员工的姓名和薪金
答案
select ename, sal from emp
where sal in
(select distinct sal
from emp
where deptno = 30)
and
deptno <> 30;第一步:先知道第30号部门中员工的薪金有哪几种值
select distinct sal
from emp
where deptno = 30;第二步:显示姓名和薪水
select ename, sal from emp
where sal in
(
select distinct sal from emp where deptno = 30
);第三步:需要满足"其他员工"的条件
select ename, sal from emp
where sal in
(
select distinct sal from emp where deptno = 30
)
and
deptno <> 30;列出薪金高于在第30号部门中工作的所有员工的薪金的员工姓名和薪金、部门名称
第一步:找出部门30中的最高薪水
select max(sal) as maxsal
from emp
where deptno = 30;第二步:要输出的是员工姓名,因需要把emp表作为主表
select d.dname, e.ename, e.sal
from emp e
join dept d
on e.deptno = d.deptno
where e.sal > (select max(sal) as maxsal
from emp;(关键)列出在每个部门工作的员工数量、平均工资和平均服务期限
答案
select d.deptno, count(e.ename),
ifnull(avg(e.sal),0) as avgsal,
avg(ifnull((to_days(now())-to_days(hiredate))/365,0)) as serverTime
from emp e
right join dept d
on e.deptno = d.deptno
group by d.deptno;第一步:求出每个部门对应的所有员工,这里使用了右连接,保证显示所有的部门,但是有的部门不存在员工,但是也必须把所有的部门显示出来
-- 将员工表emp e和部门表dept d进行表连接,将员工表和部门表信息全部展示
select e.*, d.*
from emp e
right join dept d
on e.deptno = d.deptno;第二步:在第一步的基础上求出所有员工的数量,这里因为有的部门员工是null,所有不能使用count(*),count(*)统计包含null,应该使用count(e.ename)
-- 列出每个部门工作的员工数量
select d.deptno, count(e.ename)
from emp e
right join dept d
on e.deptno = d.deptno
group by d.deptno;第三步:求出员工的平均工资,因为有的部门员工不存在,所以对应的工作也是null,这里需要null值做处理
处理:
IFNULL(expr1, expr2),如果expr1不是Null,IFNULL()返回expr1,否则返回expr2。
-- 列出每个部门工作的员工数量
select d.deptno, count(e.ename),
ifnull(avg(e.sal),0) as avgsal
from emp e
right join dept d
on e.deptno = d.deptno
group by d.deptno;第四步:求出每个员工的平均服务期限:平均服务期限,每个人从入职到今天,一共服务了多少年。相加除以部门人数。
处理:
IFNULL(expr1, expr2),如果expr1不是Null,IFNULL()返回expr1,否则返回expr2。
-- to_days(日期类型) -> 天数
-- 获取数据库的系统当前时间的函数
select to_days(now());
-- 算出员工工作多少天
select ename, (to_days(now())-to_days(hiredate))/365 as serveryear
from emp;
--算出员工工作多少年
select avg((to_days(now())-to_days(hiredate))/365)as serveryear from emp
最终:
select d.deptno, count(e.ename),
ifnull(avg(e.sal),0) as avgsal,
avg(ifnull((to_days(now())-to_days(hiredate))/365,0)) as serverTime
from emp e
right join dept d
on e.deptno = d.deptno
group by d.deptno
注意:
count(*) 计算行的数目,包含 NULL
count(column) 特定的列的非空值的行数,不包含 NULL 值。列出所有员工姓名、部门名称和工资
-- 注意是所有员工
select d.dname,e.ename,e.sal
from emp e
right join dept d
on e.deptno = d.deptno列出所有部门的详细信息和人数
统计人数的时候不能使用count(*),而要使用count(e.ename)字段的值,同时
select
d.deptno,d.dname,d.loc,count(e.ename) as totalEmp
from
emp e
right join
dept d
on
e.deptno = d.deptno
group by
d.deptno,d.dname,d.loc;
+--------+------------+----------+----------+
| deptno | dname | loc | totalEmp |
+--------+------------+----------+----------+
| 10 | ACCOUNTING | NEW YORK | 3 |
| 20 | RESEARCH | DALLAS | 5 |
| 30 | SALES | CHICAGO | 6 |
| 40 | OPERATIONS | BOSTON | 0 |列出各种工作的最低工资及从事此工作的雇员姓名
第一步:求出各种工作的最低工资
select
e.job,min(e.sal) as minsal
from
emp e
group by
e.job;
+-----------+---------+
| job | minsal |
+-----------+---------+
| ANALYST | 3000.00 |
| CLERK | 800.00 |
| MANAGER | 2450.00 |
| PRESIDENT | 5000.00 |
| SALESMAN | 1250.00 |
+-----------+---------+第二步将以上查询结果当成临时表t(job,minsal)
select
e.ename
from
emp e
join
(select
e.job,min(e.sal) as minsal
from
emp e
group by
e.job) t
on
e.job = t.job
where
e.sal = t.minsal;
+--------+
| ename |
+--------+
| SMITH |
| WARD |
| MARTIN |
| CLARK |
| SCOTT |
| KING |
| FORD |列出各个部门Manager的最低薪金
各个部门,需要进行分组;
select e.deptno, min(e.sal) as minsal
from emp e
where e.job = 'Manager'
group by e.deptno;列出所有员工的年薪,按年薪从低到高进行排序
薪水为年薪+补助,给补助加上空值处理函数。
select ename, (sal + ifnull(comm, 0))*12 as yearsal from emp
order by yearsal asc;求出员工领导的薪水超过3000的员工名和领导名
先求出员工所对应的领导,最后再把员工领导的薪水超过3000的选出。
员工表连接领导表,员工的领导编号等于领导的员工编号
select e.ename, b.ename as leadername
from emp e
join emp b
on e.mgr = b.empno
where b.sal > 3000;求部门名称中带's'字符的部门员工的工资合计、部门人数
先求出部门中带s的有哪些部门;
select d.dname, sum(e.sal) as sumsal, count(e.ename) as totalEmp
from emp e
join dept d
on e.deptno = d.deptno
where d.dname like '%s%'
group by d.dname;给任职日期超过30年的员工加薪10%
修改需要用到update语句,
create table emp_bak1 as select * from emp;
update emp_bak1 set sal = sal * 1.1
where (to_days(now())-to_days(hiredate))/365 >30;学生表
有3个表S(学生表),C(课程表),SC(学生选课表):
S(SNO,SNAME)代表(学号,姓名)
C(CNO,CNAME,CTEACHER)代表(课号,课名,教师)
SC(SNO,CNO,SCGRADE)代表(学号,课号,成绩)
找出没选过“黎明”老师的所有学生姓名。
第一种做法:子查询
黎明老师的授课的编号 -->先找出选过黎明老师的学生编号 --> 在学生表中找出
一、找出黎明老师的授课的编号
select cno from c where cteacher = '黎明';
二、再找出选过黎明老师的学生编号
select sno from sc where cno in (select cno from c where cteacher = '黎明');
三、集合
select * from s where sno not in(select sno from sc where cno = (select cno from c where cteacher = '黎明'));第二种做法--表连接做法:
第一步:找到黎明老师所上课对应的课程对应的课程编号
select cno from c where cteacher = '黎明';
第二步:求出那些学生选修了黎明老师的课程
select sno from sc join(
select cno from c where cteacher = '黎明'
)t on sc.cno = t.cno;
第三步:求出那些学生没有选择黎明老师的课
select sno,sname from s where sno not in(select sno from sc join( select cno from c where cteacher = '黎明') t
on sc.cno = t.cno);列出2门以上(含2门)不及格学生姓名及平均成绩
思路一 :在sc表中首先按照学生编号进行分组,得到哪些学生的有两门以上的成绩低于60分
第一步:先查询学生不及格的门数
select
sc.sno ,count(*) as studentNum
from
sc
where
scgrade < 60
group by
sc.sno
having
studentNum >= 2;
(现在只得到了学生编号,需要在s表中找到学生姓名)
第二步:查询出该学生对应的编号
select
a.sno , a.sname
from
s as a
join
(
select
sc.sno ,count(*) as studentNum
from
sc
where
scgrade < 60
group by
sc.sno
having
studentNum >= 2
) as b
on
a.sno = b.sno;
+-----+----------+
| sno | sname |
+-----+----------+
| 1 | zhangsan |
+-----+----------+
1 row in se第三步得到该学生的平均成绩,把上面的表当成临时表m
select
m.sno,m.sname,avg(d.scgrade)
from
sc as d
join
(
select
a.sno , a.sname
from
s as a
join
(
select
sc.sno ,count(*) as studentNum
from
sc
where
scgrade < 60
group by
sc.sno
having
studentNum >= 2
) as b
on
a.sno = b.sno
) as m
on
m.sno = d.sno
group by
d.sno ;简单写法:
select t1.snmae, t2.avgscgrade
from t1
join t2
on t1.sno=t2.sno;既学过1号课程又学过2号课所有学生的姓名
select s.sname from
sc
join
s
on
sc.sno = s.sno
where
cno = 1 and sc.sno in(select sno from sc where cno = 2);(姓名不在sc表中,因此需要用到join)
不能写成下面的形式会存在错误
select sno from sc where cno=1 and cno =2;
分段用户数
给你两个表,表A为:uid, age;表B:uid、package_name、dtm。表B有100亿条,需求:每10岁为一年龄段,要每个年龄段的活跃用户数、使用应用数、使用应用的总次数
select
count(distinct B.uid) as 活跃用户数,
count(distincct B.package_name) as 使用应用数,
count(B.dtm) as 使用应用的总次数
from B
join (
select A.uid,
case when age <= 10 and age > 10 then '0-10'
when age <= 20 and age > 10 then '10-20'
when age > 20 and age <= 30 then '20-30'
when age > 30 and age <= 40 then '30-40'
else '40+' END as age_stage
From A) as C
on C.uid = B.uid
group by age_stage;时间戳考察
把时间得int数据转化为时间戳
20210902转化为2021-09-02
from_unixtime(unix_timestamp(cast(20210902 as string),'yyyyMMdd'),'yyyy-MM-dd')算时间差
where DATEDIFF('2021-05-16',date_key)<=7 and DATEDIFF('2021-05-16',date_key)>0公众号后台回复:SQL面试题 获取完整PDF资料

原创不易,点赞三连↓