随机访问与顺序访问
顺序访问
void BM_ordered(benchmark::State &bm) {
for(auto _: bm) {
#pragma omp parallel for
for(size_t i = 0; i<n; i++) {
benchmark::DoNotOptimize(a[a[i]]);
}
benchmark::DoNotOptimize(a[a[i]]);
}
}
BENCHMARK(BM_ordered);
随机访问
void BM_random(benchmark::State &bm) {
for(auto _ : bm) {
#pragma omp parallel for
for( size_t i = 0; i < n; i++) {
size_t r = randomize(i) % n;
benchmark::DoNotOptimize(a[a[i]]);
}
benchmark::DoNotOptimize(a[a[i]]);
}
}
结果:
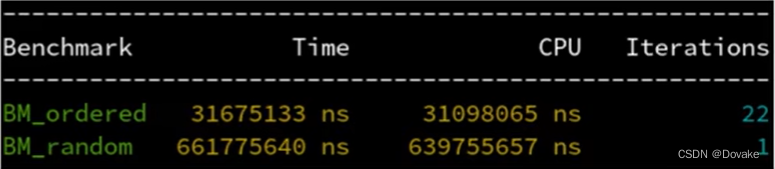
- 随机访问的效率比顺序访问低的多
- 随机访问只会访问到其中一个float,而这导致附近的64字节都被读取到缓存了,但是只用到了其中4字节,之后又没有用到剩下的60字节,导致浪费了94%的带宽
- 虽然说连续、顺序访问是最理想的,然而在使用哈希表等数据结构中,不可避免的会通过哈希函数得到随机的地址来访问,且Value类型可能小于64字节,浪费带宽。
解决 按最大的分块(4096字节)随机访问
- 解决方案,把分块的大小调的更大一些,比如4KB那么大,即64个缓存行,而不是一个
- 这样一次随机访问之后会伴随64次顺序访问,能被CPU检测到,从而启动缓存行预取,避免了等待数据抵达前空转浪费时间。
void BM_random_64B(benchmark::State &bm) {
for(auto _ : bm) {
#pragma omp parallel for
for( size_t i = 0; i < n/16; i++) {
size_t r = randomize(i) % (n/16);
for (size_t j = 0; j < 16; j++) {
benchmark::DoNotOptimize(a[a[i]]);
}
}
benchmark::DoNotOptimize(a[a[i]]);
}
}
void BM_random_4KB(benchmark::State &bm) {
for(auto _ : bm) {
#pragma omp parallel for
for( size_t i = 0; i < n/1024; i++) {
size_t r = randomize(i) % (n/1024);
for (size_t j = 0; j < 1024; j++) {
xxx
}
}`
}
}
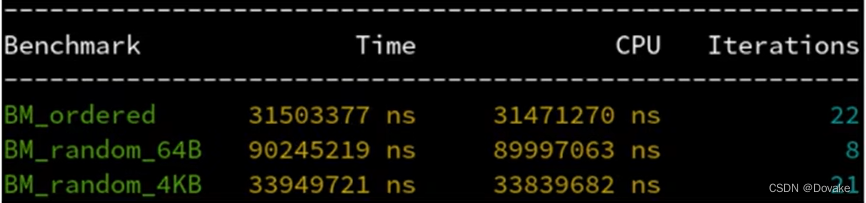
页对齐的重要性
- 为什么是4KB? 因为操作系统管理内存是用分页,程序的内存是一页一页贴在地址空间中的,有些地方可能不可访问呢,或者还没有分配,则把这个页设为不可用状态,访问他就会出错,进入内核模式。
- 因此硬件处于安全,预取不能跨越页边界,否则可能出发不必要的page fault。所以我们选用页的大小,因为本来就不能跨页顺序预取,所以被我们切掉也无所谓
- 我们可以用 mm_alloc 申请起始地址对齐到页边界的一段内存,真正做到每个块内部不出现跨页现象。
为什么写入比读取慢?
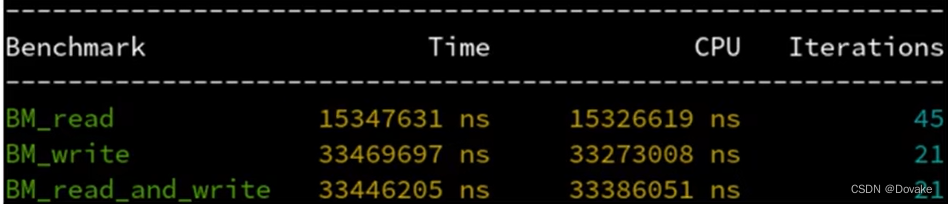
- 写入花的时间似乎是读取的2倍
- 写入的同事读取,和单写入的时间是一样的
- 似乎写入一个数组的同时也会读取这个数组,造成两倍带宽?
写入的粒度太小造成不必要的读取
- 缓存和内存通信的最小单位是缓存行: 64字节。
- 当CPU试图写入4字节时,因为剩下的60字节没有改变,缓存不知道CPU接下来会不会用到那60字节,因此他只好从内存读取完整的64字节,修改其中的4字节为CPU给的数据,之后再择机协会。
- 这就导致了虽然没有用到读取数据,但实际上缓存还是从内存读取了,从而浪费2倍带宽。