1 简介
Headless Service是一种特殊的服务类型,它不会分配虚拟 IP,而是直接暴露所有 Pod 的 IP 和 DNS 记录。这客户端可以直接访问 Pod IP 地址,并使用这些 IP 地址进行负载均衡。
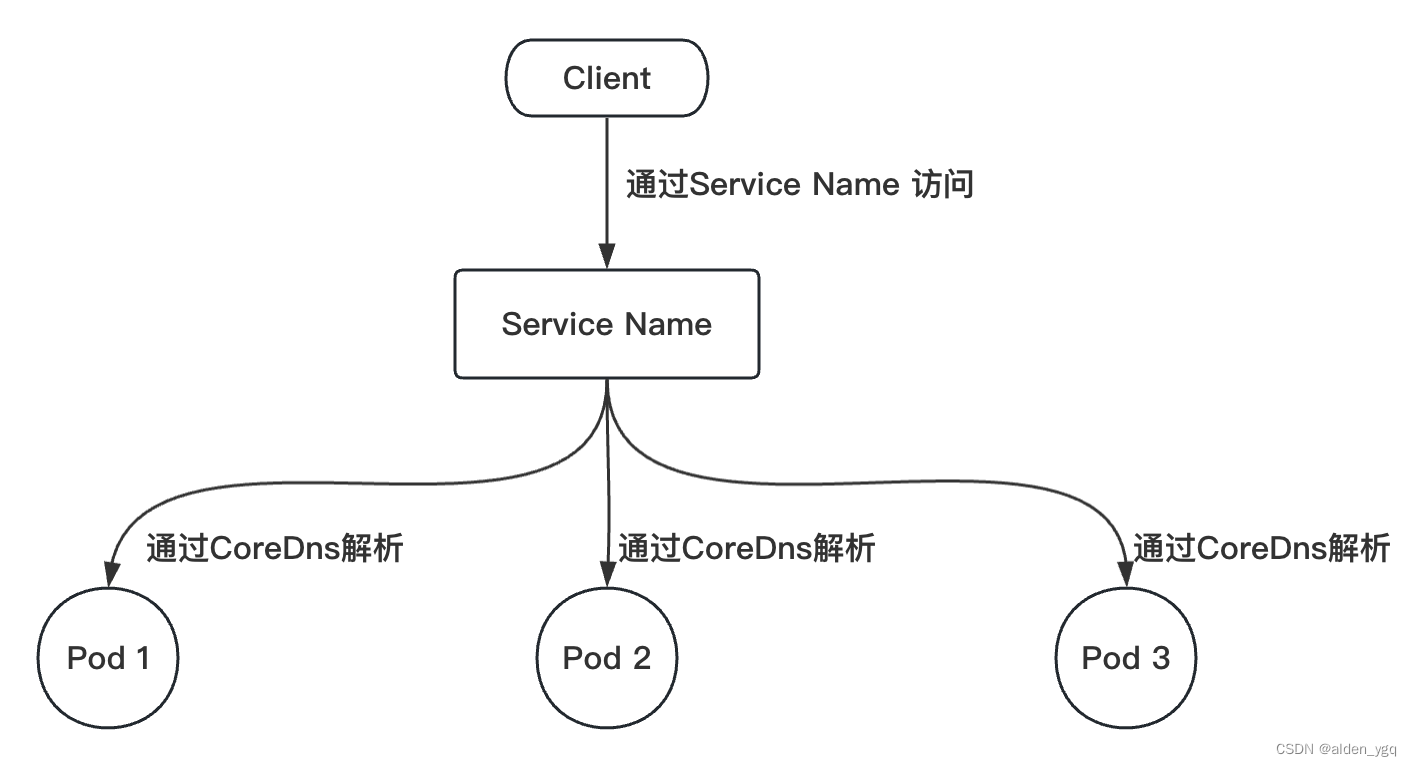
Headless Services是一种特殊的service,其spec:clusterIP表示为None,这样在实际运行时就不会被分配ClusterIP。也被称为无头服务。
案例:
创建一个 Headless Service 如下:
apiVersion: v1
kind: Service
metadata:
name: statefulset-service
spec:
clusterIP: None
selector:
app: statefulset-app
ports:
- name: http
port: 80
这样就创建了一个名为 statefulset-service 的 Headless Service,并且选择了标签为 app: statefulset-app 的所有 Pod 作为其后端。
当查询该 Service 的 DNS 记录时,就会得到如下结果:
$ nslookup statefulset-service.default.svc.cluster.local
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: statefulset-service.default.svc.cluster.local
Address: 10.244.0.5
Name: statefulset-service.default.svc.cluster.local
Address: 10.244.0.6
Name: statefulset-service.default.svc.cluster.local
Address: 10.244.0.7
可以看到,返回了三个 IP 地址,分别对应于三个 Pod 的 IP 地址。
如果想要访问其中一个 Pod,比如 pod-1,可以使用 pod-1.statefulset-service.default.svc.cluster.local 这样的域名来访问。
2 Headless 工作原理
当创建一个名为 statefulset-service 的 Headless 服务时,Kubernetes 将为每个 Pod 创建一个 DNS 记录。这个 DNS 实体的名称采用形式:“{podname}.{headless-name}.{namespace}.svc.cluster.local”。
- {podname}是 Pod 名称
- {headless-name}是 Headless 服务名称
- {namespace}是命名空间名称
当查询"pod-1.statefulset-service.default.svc.cluster.local"时,将以 DNS 方式返回一个 A 记录,其中包含所有匹配的 Pod IP 地址。这意味着可以通过 Pod IP 地址直接访问 Headless 服务,并使用 CoreDNS 返回 A 记录中的 IP 地址进行负载均衡(当然可以使用配置的 LoadBalancer,而不是 Kubernetes 提供的负载均衡)。

3 Headless 优缺点
3.1 优点
- 高度动态和可扩展:由于没有虚拟 VIP,Headless 服务对 Pod 的数量没有限制,具有高度动态和可扩展的特性。
- 直接访问 Pod IP 地址:与 ClusterIP 相比,在 Headless 服务中没有默认负载均衡器,因此可以直接访问 Pod 的实际 IP 地址。
- API 选择器的支持:在 Headless 服务中,支持 API 选择器。这使得我们可以根据标签选择特定的 Pod。
3.2 缺点
- 没有默认负载均衡器:由于没有默认负载均衡器,所以我们需要手动进行负载均衡。
4 Headless 与 ClusterIP 区别
ClusterIP 是 Kubernetes 默认的服务类型。它为 Pod 组提供了一个虚拟 IP,并通过代理模式进行负载均衡。当在编写 Service 配置文件时,通常会指定 ClusterIP 类型。这样就可以使用 Virtual IP 在 Kubernetes 中跨节点访问 Pod 组。
另一方面,Headless 服务类型并不分配虚拟 IP,而是直接暴露所有 Pod 的 DNS 记录。没有默认负载均衡器,可直接访问 Pod IP 地址。因此,当需要与集群内真实的 Pod IP 地址进行直接交互时,Headless 服务就派上用场了。
5 headless svc和 普通svc 区别
普通 svc
可以看作是有头svc, 表示svc本身也有一个地址(cluster ip), dns查询时只会返回Service的地址, 具体client访问的是哪个Real Server,是由iptables来决定的。
headless svc
headless 无头, 无头表示这个svc的负载均衡是没有clusterip的, dns查询会如实的返回2个真实的endpoint。
6 Headless 使用场景
Headless 服务类型通常适用于需要直接访问 Pod IP 地址的分布式应用程序,尤其是以下几种场景:
- 数据库集群:数据库集群需要高可用性和可扩展性,并且要求能够在任何时候访问每个节点。Headless 服务可以为每个节点分配一个唯一的 DNS 实体名称,从而支持直接访问 Pod IP 地址,实现负载均衡和故障转移。
- 消息队列:消息队列需要高吞吐量和低延迟,以支持实时数据处理和流式计算。Headless 服务可以为每个节点分配一个唯一的 DNS 实体名称,从而支持与节点的直接交互和负载均衡,实现数据传输的高效性。
- 分布式缓存:分布式缓存需要支持多个节点之间的数据同步和复制,并且要求能够在任何时候访问每个节点。Headless 服务可以为每个节点分配一个唯一的 DNS 实体名称,从而支持直接访问 Pod IP 地址,实现数据的高可用性和可靠性。
- 超高性能应用程序:超高性能应用程序需要支持动态扩展和负载均衡,并且要求能够在任何时候被每个节点,同时对延迟敏感。Headless 服务可以为每个节点分配一个唯一的 DNS 实体名称,从而支持直接访问 Pod IP 地址,实现高可用性和可靠性。在这些情况下,每个节点都有自己的身份和状态,需要使用持久化存储进行数据共享。
在调用某个节点时,单个服务和端点并不太重要,而是要保证在数据共享期间追踪正确的节点。这种情况下,使用 Headless 服务就非常有用了。
7 为什么要用headless service+statefulSet部署有状态应用?
headless service一般和statefulSet结合使用,其关联关系是:
- headless service会为关联的Pod分配一个域<service name>.$<namespace name>.svc.cluster.local
- StatefulSet会为关联的Pod保持一个不变的Pod Name,statefulset中Pod的hostname格式为$(StatefulSet name)-$(pod序号)
- StatefulSet会为关联的Pod分配一个dnsName,域名标准是:$<Pod Name>.$<service name>.$<namespace name>.svc.cluster.local。
Headless Service首先是Service,一般的Service能被内部和外部访问。之所以叫Headless Service是因为只对内提供访问,需要提供稳定的访问能力,否则就没什么作用了。比如说拥有固定的Pod名称和存储,所以一般会结合StatefulSet一起使用,用来部署有状态的应用。
8 Headless 对 Kube-proxy 的影响
Headless 服务对 Kube-proxy 的影响主要体现在其负载均衡的实现方式上。在 Kubernetes 中,Kube-proxy 负责为 Service 提供负载均衡功能,以便客户端能够直接连接到任意一个 Pod。对于 ClusterIP 类型的 Service,Kube-proxy 会创建一个虚拟 IP 地址,并将请求发送到该地址所绑定的一个或多个 Pod 上。
而对于 Headless Service,Kube-proxy 创建的是一组 DNS 记录,用于解析到每个 Pod 的 IP 地址。这样,客户端就可以通过 DNS 解析来得到 Pod 的 IP 地址,并与它直接建立连接,完全绕过了 Kube-proxy 组件。
对于 Kube-proxy + IPVS 方式(即使用 IPVS 实现 Kube-proxy 的负载均衡),Headless 服务同样不会受到 IPVS 的影响,因为它们都是通过直接访问 Pod IP 地址来实现负载均衡的。在这种情况下,IPVS 只会提供网络层转发的功能,并没有更深层次的介入。
因此,当使用 Headless 服务时,需要手动进行负载均衡。
9 CoreDNS 如何与 Headless 协作的
CoreDNS 是 Kubernetes 中的默认 DNS 服务器,它管理着整个集群的服务发现。CoreDNS 是一种单独的容器,可以在每个节点上运行。当 CoreDNS 启动时,它会检索 kube-apiserver 中的整个服务定义,并将其转换为 DNS 记录。
当创建一个 Headless 服务时,CoreDNS 将为每个 Pod 创建一个 DNS 记录,该记录直接指向 Pod 的实际 IP 地址。这将有助于在 Headless 服务类型中对 Pod 进行直接访问。
使用Headless service的流量均衡负载的能力是由 CoreDNS 的 RR 轮询算法来实现的。
10 Headless 和 Endpoint 之间的关系
Headless 服务类型下所有 Pod 将作为独立的 Endpoint 发布到 Kubernetes API 服务器中。这使得其他适用于 ClusterIP 服务类型的 Kubernetes 组件可以对其进行发现和路由。
在 Headless 服务中,可以使用 Endpoints 对象来访问所有 Pod IP 地址。这是一个由 Kubernetes 自动生成的对象,其中包含了相应 Service 的全部 Endpoint 信息。
在 Endpoint 对象方面,它的主要作用是管理具体的 Pod IP 地址,并与 Headless 服务保持同步。当 Pod 发生故障或需要进行扩容时,Endpoint 对象会及时更新,并确保 Headless 服务始终具有最新的 Pod IP 地址。这样可以确保开发者能够始终访问到可用的 Pod,并保证应用程序的稳定性和可靠性。
11 Selector 是如何影响 Headless 和 CoreDNS?
使用了 CoreDNS 的集群默认会配置自动服务发现,它能够根据 Service 和 Endpoint 对象自动生成 DNS 解析记录。对于普通的 Service 对象,CoreDNS 会将其 ClusterIP 映射到一个域名下,这个域名为 {service-name}.{namespace}.svc.cluster.local。而对于 Headless Service,由于没有 Selector 对象,CoreDNS 将不会生成对应的 A 记录,只会生成 SRV 记录。
具体来说,在使用了 CoreDNS 的 Kubernetes 集群中,对于 Headless Service,CoreDNS 会在域名 .{service-name}.{namespace}.svc.cluster.local 下生成一个 SRV 记录,这个记录包含了每个 Pod 的 IP 地址和端口号。客户端可以通过查询这个 SRV 记录来获取所有 Pod 的地址和端口号,并进行连接。换句话说,使用了 CoreDNS 的 Kubernetes 集群,Headless Service 可以正常工作,并且提供了更加灵活的负载均衡方式,客户端可以通过查询 SRV 记录,灵活选择需要连接的 Pod。
需要注意的是,在使用了 CoreDNS + Headless Service 的场景中,如果想要实现服务发现和负载均衡功能,客户端必须支持 SRV 记录类型。因此,在开发应用时,需要确保客户端能够正确地解析并使用 SRV 记录。
12 使用 Headless 的风险
- 直接暴露所有 Pod 的 DNS 记录可能导致安全漏洞。恶意用户可能会利用 Headless 服务类型攻击系统。
- 由于没有默认负载均衡器,因此需要手动进行负载均衡。这可能导致一些人员工作量过大,管理变得复杂。
- 使用 Headless 服务可能会增加 DNS 服务器的工作量。在具有大量 Pod 和 Headless 服务的较大集群中,DNS 服务器可能会成为瓶颈。