目录
一、实验介绍
在本系列先前的代码中,借助深度学习框架的帮助,已经完成了前馈神经网络的大部分功能。本文将基于鸢尾花数据集构建一个数据迭代器,以便在每次迭代时从全部数据集中获取指定数量的数据。(借助深度学习框架中的Dataset类和DataLoader类来实现此功能)
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
ChatGPT:
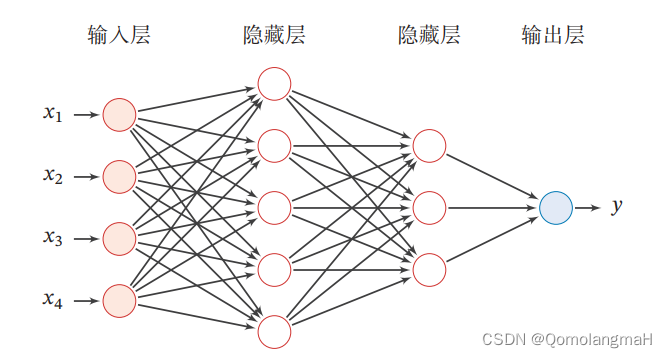
前馈神经网络(Feedforward Neural Network)是一种常见的人工神经网络模型,也被称为多层感知器(Multilayer Perceptron,MLP)。它是一种基于前向传播的模型,主要用于解决分类和回归问题。
前馈神经网络由多个层组成,包括输入层、隐藏层和输出层。它的名称"前馈"源于信号在网络中只能向前流动,即从输入层经过隐藏层最终到达输出层,没有反馈连接。
以下是前馈神经网络的一般工作原理:
输入层:接收原始数据或特征向量作为网络的输入,每个输入被表示为网络的一个神经元。每个神经元将输入加权并通过激活函数进行转换,产生一个输出信号。
隐藏层:前馈神经网络可以包含一个或多个隐藏层,每个隐藏层由多个神经元组成。隐藏层的神经元接收来自上一层的输入,并将加权和经过激活函数转换后的信号传递给下一层。
输出层:最后一个隐藏层的输出被传递到输出层,输出层通常由一个或多个神经元组成。输出层的神经元根据要解决的问题类型(分类或回归)使用适当的激活函数(如Sigmoid、Softmax等)将最终结果输出。
前向传播:信号从输入层通过隐藏层传递到输出层的过程称为前向传播。在前向传播过程中,每个神经元将前一层的输出乘以相应的权重,并将结果传递给下一层。这样的计算通过网络中的每一层逐层进行,直到产生最终的输出。
损失函数和训练:前馈神经网络的训练过程通常涉及定义一个损失函数,用于衡量模型预测输出与真实标签之间的差异。常见的损失函数包括均方误差(Mean Squared Error)和交叉熵(Cross-Entropy)。通过使用反向传播算法(Backpropagation)和优化算法(如梯度下降),网络根据损失函数的梯度进行参数调整,以最小化损失函数的值。
前馈神经网络的优点包括能够处理复杂的非线性关系,适用于各种问题类型,并且能够通过训练来自动学习特征表示。然而,它也存在一些挑战,如容易过拟合、对大规模数据和高维数据的处理较困难等。为了应对这些挑战,一些改进的网络结构和训练技术被提出,如卷积神经网络(Convolutional Neural Networks)和循环神经网络(Recurrent Neural Networks)等。
本系列为实验内容,对理论知识不进行详细阐释
(咳咳,其实是没时间整理,待有缘之时,回来填坑)
0. 导入必要的工具包
import torch
from sklearn.datasets import load_iris
from torch.utils.data import Dataset, DataLoader
Dataset和DataLoader类用于处理数据集和数据加载
1. 直接加载鸢尾花数据集
加载鸢尾花数据进行归一化并可选地进行洗牌操作,以便于后续的深度学习任务。
import torch
from sklearn.datasets import load_iris
def load_data(shuffle=True):
x = torch.tensor(load_iris().data)
y = torch.tensor(load_iris().target)
# 数据归一化
x_min = torch.min(x, dim=0).values
x_max = torch.max(x, dim=0).values
x = (x - x_min) / (x_max - x_min)
if shuffle:
idx = torch.randperm(x.shape[0])
x = x[idx]
y = y[idx]
return x, ya. 加载数据集
-
调用
load_iris().data函数加载数据,并使用torch.tensor将数据转换为PyTorch张量,将结果赋值给变量x。 -
调用
load_iris().target函数加载目标变量,并使用torch.tensor将数据转换为PyTorch张量,将结果赋值给变量y。
b. 数据归一化
-
计算矩阵
x每列的最小值。-
torch.min函数的dim参数设置为0表示按列计算最小值,.values属性获取最小值的张量。
-
-
计算矩阵
x每列的最大值。-
torch.max函数的dim参数设置为0表示按列计算最大值,.values属性获取最大值的张量。
-
-
x = (x-x_min)/(x_max-x_min):对矩阵x进行归一化处理,将每个元素减去最小值,然后除以最大值与最小值之差。这样可以将数据缩放到0和1之间。
c. 洗牌操作
-
if shuffle::如果shuffle参数为True,执行以下代码块。-
idx = torch.randperm(x.shape[0]):生成一个随机排列的索引,范围从0到x的行数减1。torch.randperm函数返回一个随机排列的整数序列。 -
x = x[idx]:根据生成的随机索引对矩阵x进行行重排,打乱数据的顺序。 -
y = y[idx]:根据生成的随机索引对向量y进行行重排,保持目标变量与输入数据的对应关系。
-
-
return x, y:返回处理后的输入特征矩阵x和目标变量向量y。
d. 打印数据
x, y = load_data()
print("Input features (x):")
print(x)
print("Target variables (y):")
print(y)

2. 定义类封装数据
创建一个用于处理鸢尾花数据集的自定义数据集(继承自Dataset类),该自定义数据集类可以用于创建鸢尾花数据集的训练集、验证集或测试集对象,并提供给__getitem__和__len__方法,以便能够使用DataLoader类进行数据加载和批处理操作。
class IrisDataset(Dataset):
def __init__(self, mode='train', num_train=120, num_dev=15):
super(IrisDataset,self).__init__()
x, y = load_data(shuffle=True)
if mode == 'train':
self.x, self.y = x[:num_train], y[:num_train]
elif mode == 'dev':
self.x, self.y = x[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
else:
self.x, self.y = x[num_train + num_dev:], y[num_train + num_dev:]
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
def __len__(self):
return len(self.x)-
class IrisDataset(Dataset)::定义了一个名为IrisDataset的类,该类继承自Dataset类,表示一个自定义的数据集。
a. __init__(构造函数:用于初始化数据集对象)
-
该函数接受三个参数:
-
mode表示数据集模式(默认为'train') -
num_train表示训练样本的数量(默认为120) -
num_dev表示验证样本的数量(默认为15)。
-
-
super(IrisDataset, self).__init__():调用父类Dataset的构造函数,确保正确地初始化基类。 -
x, y = load_data(shuffle=True):调用之前定义的load_data函数加载数据集。 -
如果数据集模式为'train':
-
将前
num_train个训练样本赋值给类的成员变量self.x和self.y,表示训练数据集。
-
-
如果数据集模式为'dev':
-
将从第
num_train个样本开始的num_dev个样本赋值给类的成员变量self.x和self.y,表示验证数据集。
-
-
如果数据集模式不是'train'也不是'dev':
-
将从第
num_train + num_dev个样本开始的剩余样本赋值给类的成员变量self.x和self.y,表示测试数据集。
-
b. __getitem__(获取指定索引处的样本)
-
return self.x[idx], self.y[idx]:根据索引idx返回对应位置的输入特征和目标变量。
c. __len__(获取数据集的长度)
-
return len(self.x):返回数据集的长度,即样本数量。
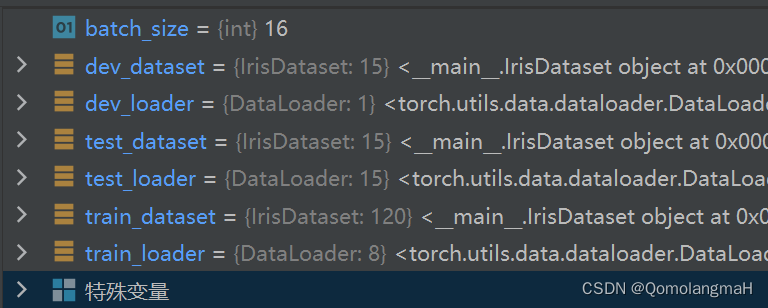
3. 构建数据集(批量加载训练、验证、测试集)
batch_size = 16
# 分别构建训练集、验证集和测试集
train_dataset = IrisDataset(mode='train')
dev_dataset = IrisDataset(mode='dev')
test_dataset = IrisDataset(mode='test')
train_loader = DataLoader(train_dataset, batch_size=batch_size,shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=True)- 使用自定义的数据封装类加载鸢尾花数据集的训练集、验证集和测试集,并使用
DataLoader进行批量加载。train_dataset是要加载的数据集对象,batch_size是批量大小,表示每个批次的样本数量,shuffle=True表示在每个迭代周期中对数据进行随机洗牌。- 将验证集数据集加载到
dev_loader中,未指定shuffle参数,默认为False,不进行洗牌。 - 将测试集数据集加载到
test_loader中,将batch_size设置为1,表示每个批次只包含一个样本,同时指定shuffle=True,在每个迭代周期中对数据进行随机洗牌。
4. 代码整合
# 导入必要的工具包
import torch
from sklearn.datasets import load_iris
from torch.utils.data import Dataset, DataLoader
# 此函数用于加载鸢尾花数据集
def load_data(shuffle=True):
x = torch.tensor(load_iris().data)
y = torch.tensor(load_iris().target)
# 数据归一化
x_min = torch.min(x, dim=0).values
x_max = torch.max(x, dim=0).values
x = (x - x_min) / (x_max - x_min)
if shuffle:
idx = torch.randperm(x.shape[0])
x = x[idx]
y = y[idx]
return x, y
# 构建自己的数据集,继承自Dataset类
class IrisDataset(Dataset):
def __init__(self, mode='train', num_train=120, num_dev=15):
super(IrisDataset, self).__init__()
x, y = load_data(shuffle=True)
if mode == 'train':
self.x, self.y = x[:num_train], y[:num_train]
elif mode == 'dev':
self.x, self.y = x[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
else:
self.x, self.y = x[num_train + num_dev:], y[num_train + num_dev:]
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
def __len__(self):
return len(self.x)
batch_size = 16
# 分别构建训练集、验证集和测试集
train_dataset = IrisDataset(mode='train')
dev_dataset = IrisDataset(mode='dev')
test_dataset = IrisDataset(mode='test')
train_loader = DataLoader(train_dataset, batch_size=batch_size,shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=True)