RV64
比起 RV32,其实扩展不多。
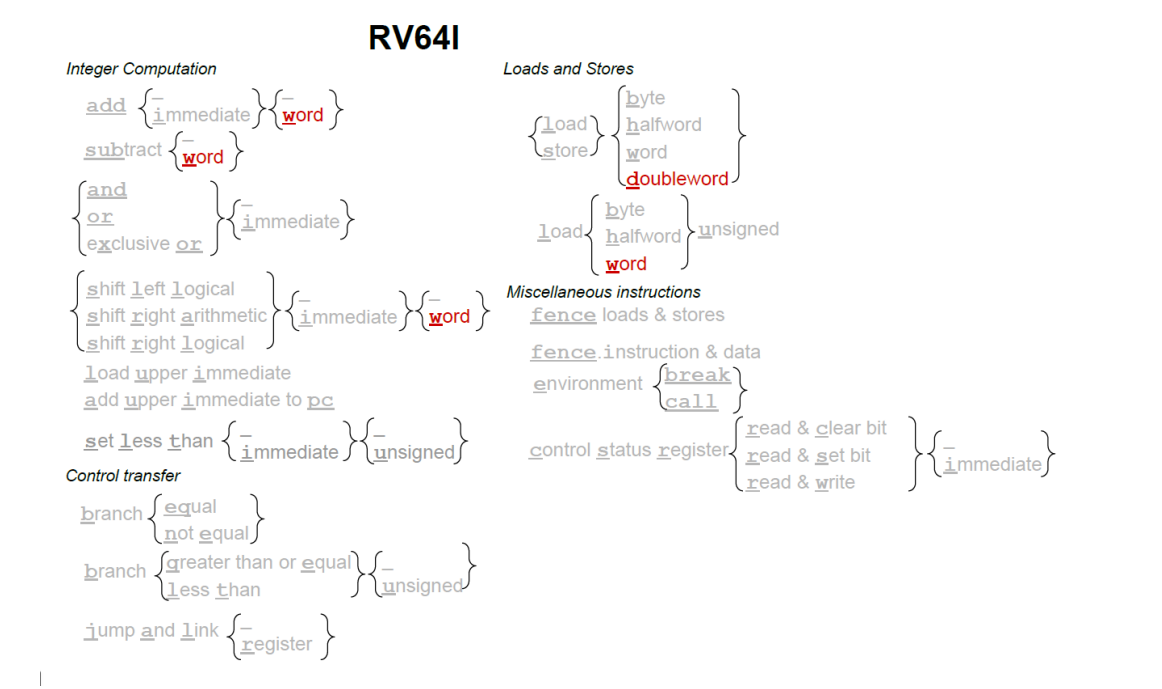
主要是添加了一系列字,双字为单位的操作。
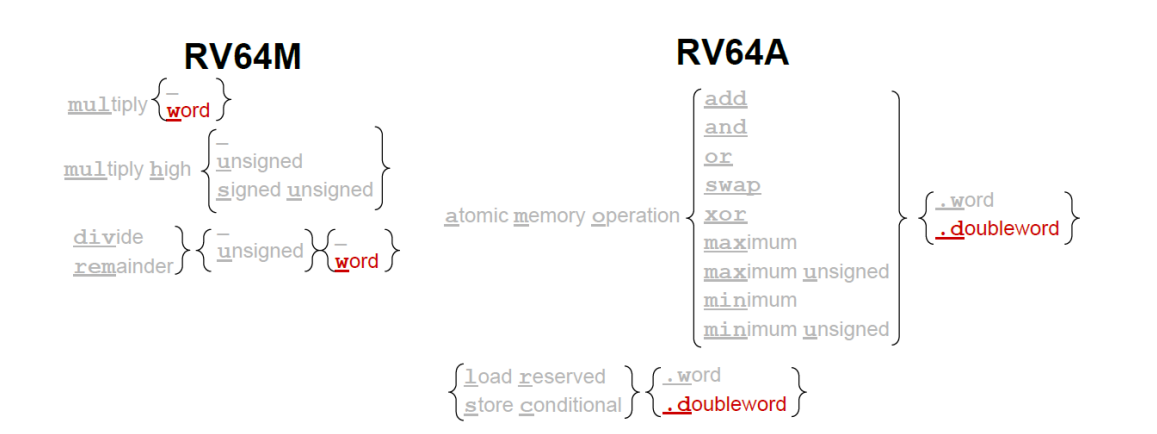
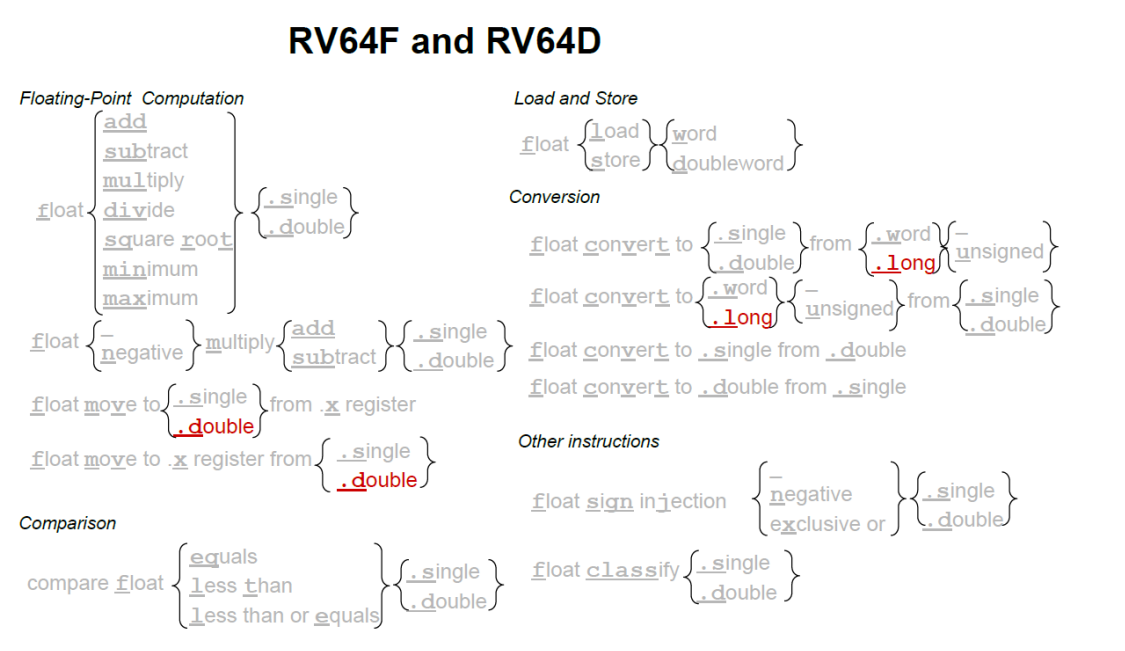
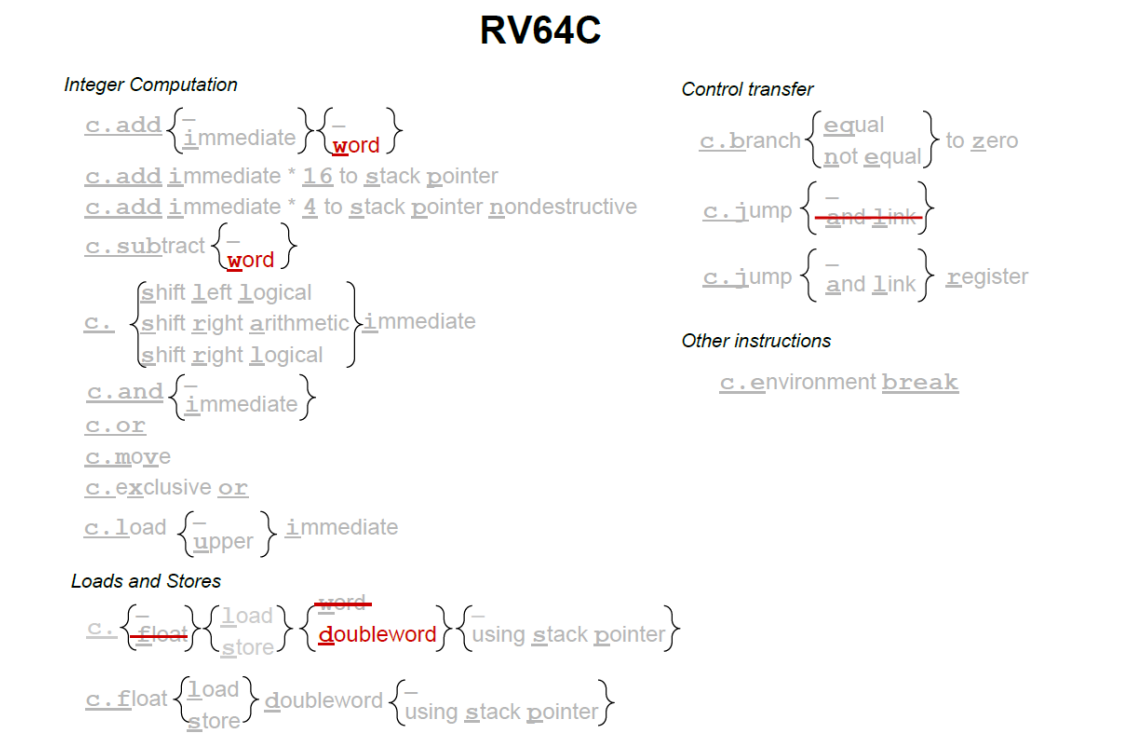
各个 ISA 32 64比较
x86:变量都存在寄存器里,不像 32 存在内存里,因此指令数少很多,但是因此添加了很多新操作码来操作更多的寄存器,因此指令长度变长了(添加前缀来区分),代码体积大很多。
arm:有一系列和 arm32 类似的问题,:分支指令使用的条件码,指令中源和目 标寄存器字段并不固定,条件移动指令,复杂寻址模式,不一致的性能计数器,以及只支持 32 位长度的指令。
mips:需要用 nop 填充分支延迟槽。
比较起来 RV64 程序大小还是算作最小的。因此缓存缺失率比较低,或者可以在差不多缺页率的情况下使用更小的缓存空间。
RV32/64 特权架构
前面都是通用的用户模式介绍。这一章我们引入两个新的模式:机器模式,监管者模式。
多模式的引入支持一些网络数据包处理,多任务处理,虚拟化硬件等。
指令列表
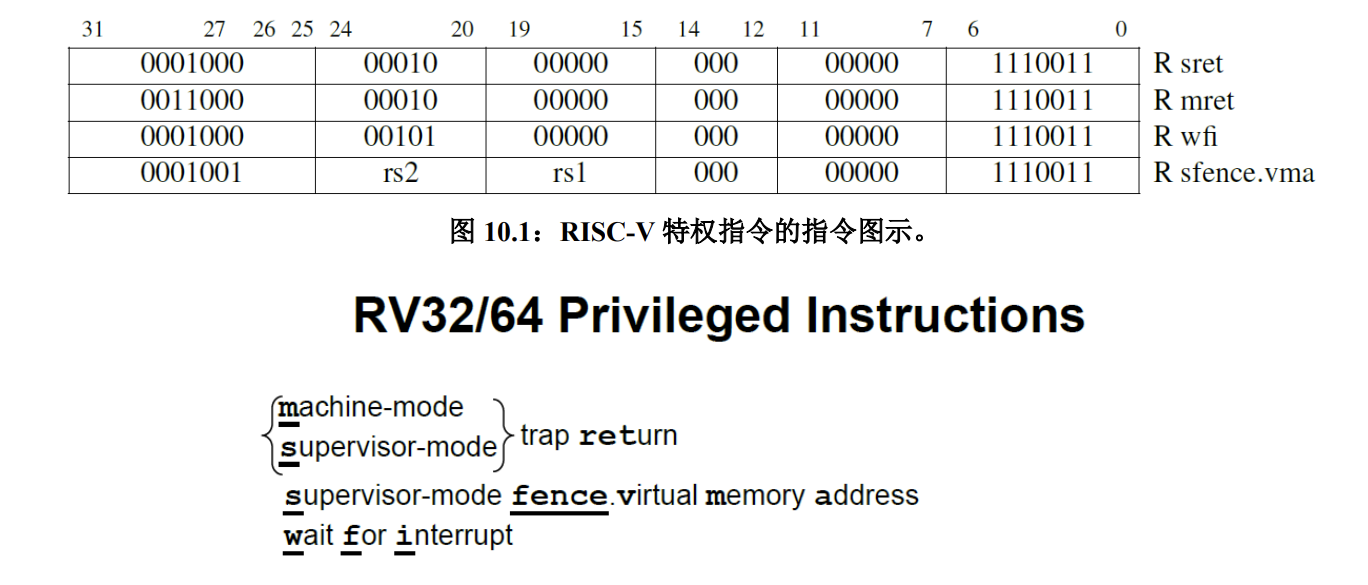
指令数量不多,通过一系列 CSR 寄存器进行管理。
机器模式
支持对硬件的所有访问,因此机器模式 M 模式是所有 RV 实现都必须包含的。
机器模式最重要的功能是拦截,处理异常的能力。RV 中异常主要分为两种:指令执行期间的同步异常(主要包括一些错误,比如访存地址不存在),和中断异常。
同步异常包括:
-
访问错误异常,当物理内存的地址不支持访问类型时发生(例如尝试写入 ROM)。
-
断点异常,在执行 ebreak 指令,或者地址或数据与调试触发器匹配时发生。
-
环境调用异常,在执行 ecall 指令时发生。
-
非法指令异常,在译码阶段发现无效操作码时发生。
-
非对齐地址异常,在有效地址不能被访问大小整除时发生,例如地址为 0x12 的 amoadd.w。
虽然前面说了, store load 是可以支持非对齐的访问的。但是可能有一些实现者选择放弃非对齐硬件设计,而且原子操作必须是对齐的。没有这种硬件实现,遇到非对齐的访问时就需要异常进行处理,牺牲一些时间,不过对于上层程序员来说最终实现结果还是一样的。
中断主要分为:软件中断,定时器中断,外部中断。
异常处理
主要由8个异常寄存器来处理。
- mtvec(Machine Trap Vector)它保存发生异常时处理器需要跳转到的地址。
- mepc(Machine Exception PC)它指向发生异常的指令。
- mcause(Machine Exception Cause)它指示发生异常的种类。
- mie(Machine Interrupt Enable)它指出处理器目前能处理和必须忽略的中断。
- mip(Machine Interrupt Pending)它列出目前正准备处理的中断。
- mtval(Machine Trap Value)它保存了陷入(trap)的附加信息:地址例外中出错的地址、发生非法指令例外的指令本身,对于其他异常,它的值为 0。
- mscratch(Machine Scratch)它暂时存放一个字大小的数据。
- mstatus(Machine Status)它保存全局中断使能,以及许多其他的状态。
- wfi(Wait For Interrupt)低功耗延时。
mstatus 被置1的时候才产生中断。mie 中存储了具体是哪个中断的标志位。比如如果 mstatus.MIE = 1,mie[7] = 1,且 mip[7] = 1,则可以处理机器的时钟中断。
异常处理流程如下:
- pc 值存入 mepc,pc 值被设置为 mtvec(mepc 是引发异常的指令,或中断的返回处)。
- 设置 mcause 标识异常原因,以及 mtval 标识异常附加信息。
- mstatus.MIE = 0 来禁止中断处理,之前的 MIE 值存入 MPIE。
- 发生异常之前的权限模式保留在 mstatus 的 MPP 域中,再把权限模式更改为 M。
- 整数寄存器中的值存入 mscratch 临时保存(软件会让 mscratch 包含指向附加临时内存空 间的指针,处理程序用该指针来保存其主体中将会用到的整数寄存器。)。
- 执行完成异常后基本是以上的逆操作。中断程序恢复其保存在内存中的寄存器,mscratch 与整数寄存器再次交换;mret 指令将 mepc 恢复到 pc,MPIE 恢复到 MIE,MPP 恢复权限模式信息。

上图是一个定时器中断时钟自增(+1000时钟周期)代码示例。MIE mtvec 默认设置好了。
用户模式
机器模式可以操作所有硬件,是必须实现的模式。但是这种模式对用户来说不安全。
用户模式则封装那些我们不希望用户修改的系统信息,并且为不受信任的进程提供隔离保护。
mstatus.MPP 设置为 U 模式即为用户模式。当用户模式下想要使用机器模式指令(如 mret)或者访问机器模式寄存器时就会发生非法指令异常,控制权移交给 M 模式处理异常。
MU 两种模式能读,写,执行的内存空间是不同的。实现了 MU 模式的处理器会有一个 PMP 功能,其中有如下几段:地址寄存器,A 域(标识此 PMP 是否开启),L 域(锁定此 PMP 和对应的地址寄存器),XWR(与地址寄存器相对应的配置寄存器,标识执行,读,写权限)。

监管者模式
委托
PMP 有很多缺点,比如他只支持固定连续空间的内存权限管理,容易造成存储碎片化;且无法对辅存分页。
RISC-V 采用基于分页的虚拟内存解决以上问题。这也是 S 监管者模式的核心。这种模式旨在支持一些现代操作系统(如 Unix)。
S 模式优先级介于 M 模式和 U 模式之间,不能直接操作 PMP,机器模式下的一些 CSR,指令。
默认情况下所有异常都会被交给 M 模式处理,但是一些现代操作系统可能更期望把部分系统异常交给 S 模式处理。一种解决办法是 M 模式重新把这些异常导向给 S 模式处理,不过这样比较浪费资源。RV 的解决办法是异常委托机制,可以把部分中断或异常导向给 S 模式而不给 M 模式处理。
mideleg(Machine Interrupt Delegation,机器中断委托)CSR 控制将哪些中断委托给 S 模式。mideleg 和 mip mie 一样,每几位对应一个中断,比如 mideleg[5] 是 S 模式的时钟中断,置位后时钟中断就优先交给 S 模式处理。
sip sie 是 mip mie 的子集,但是只有 mideleg 中委托对应位给 S 模式的中断才能交给他们处理。
medeleg 是委托异常。
中断异常处理
整体流程和 M 模式差不多,不过用了一套自己的 CSR & 寄存器。
- pc 值存入 sepc,pc 值被设置为 stvec(sepc 是引发异常的指令,或中断的返回处)。
- 设置 scause 标识异常原因,以及 stval 标识异常附加信息。
- sstatus.SIE = 0 来禁止中断处理,之前的 SIE 值存入 SPIE。
- 发生异常之前的权限模式保留在 sstatus 的 SPP 域中,再把权限模式更改为 S。
基于页面的虚拟内存
S 模式采用一种传统的虚拟内存技术,把内存划分为固定大小的页来进行地址转换和内存保护。load 和 store 访问的虚拟逻辑地址需要被转化为内存中真正的物理地址,这一操作通过 页表 来实现。
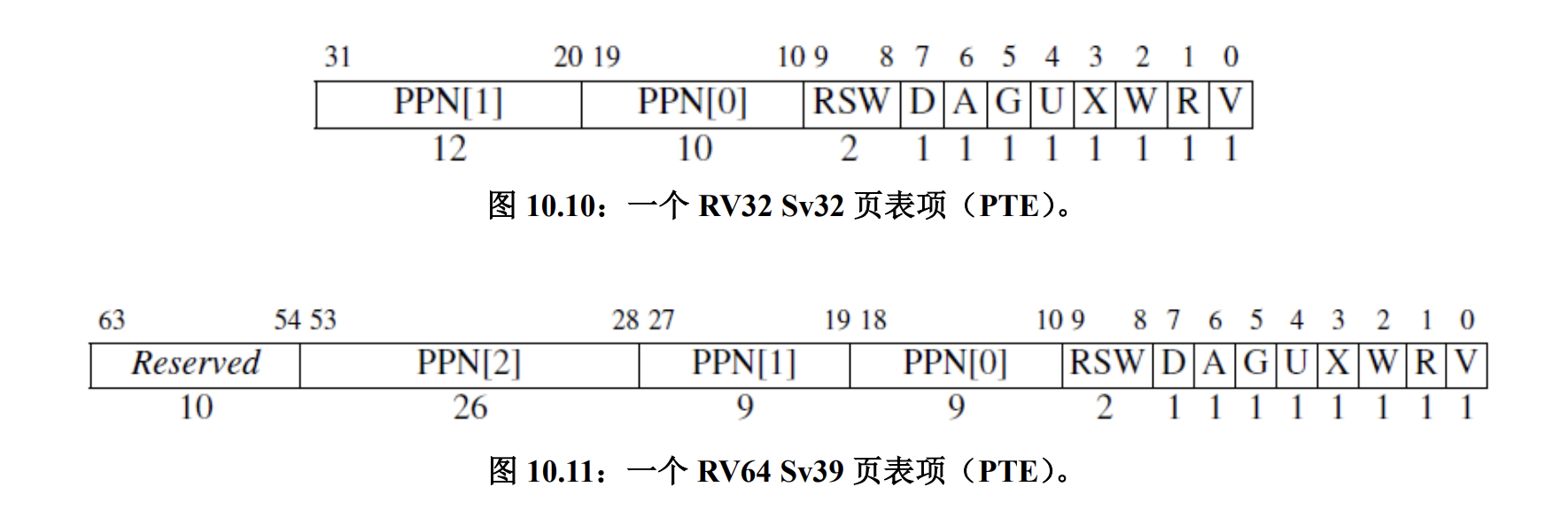
RISC-V 的分页方案以 SvX 的模式命名,X 是每个虚拟地址的长度(单位 bit)。比如 Sv32 Sv39. 比如,RV32 的 Sv32 支持 4GiB 虚拟空间,划分为 2^10 4MiB 巨页,每个巨页分为 2^10 个 4KiB 基页。因此 Sv32 是 2^10 基数的二级树结构。
上图中包含页表项的详细展开。
- V:是否启用此页表项,如果=0那么访问这个页表项进行虚拟空间和物理地址的转化会造成页错误。
- RWX:读写执行。如果都是0,说明这个结点是树路径结点而不是叶子结点。
- U:=1 表示用户模式可以访问这个页表项,S 模式不行;=0相反。
- G:这个映射是否对所有虚拟空间都有效。通常用于 OS 的页面。
- A:自从上次 A 位被清除后,该映射是否被访问过。
- D:自从上次 D 位被清除后,该映射是否被弄脏(如被写过)。
- RSW:留给 OS 使用。
- PPN:部分物理地址的映射(如果当前页表项是叶子结点),或者下一个页表的位置。
RV64 比较常用的虚拟内存映射方式是 Sv39,3层 2^9 的树。PPN 长度页扩展了,支持更长的物理地址。
satp(Supervisor Address Translation and Protection,监管者地址转换和保护)用于控制分页系统。模式表示是否开启分页以及分页级别;ASID 是减少上下文切换开销的可选内容;PPD 是物理地址的根页表(基址?)。

查找映射流程:
- VPN 虚拟地址。
- 其页号和 satp 页表基址找到对应页表页。
- 找到其中物理地址值。
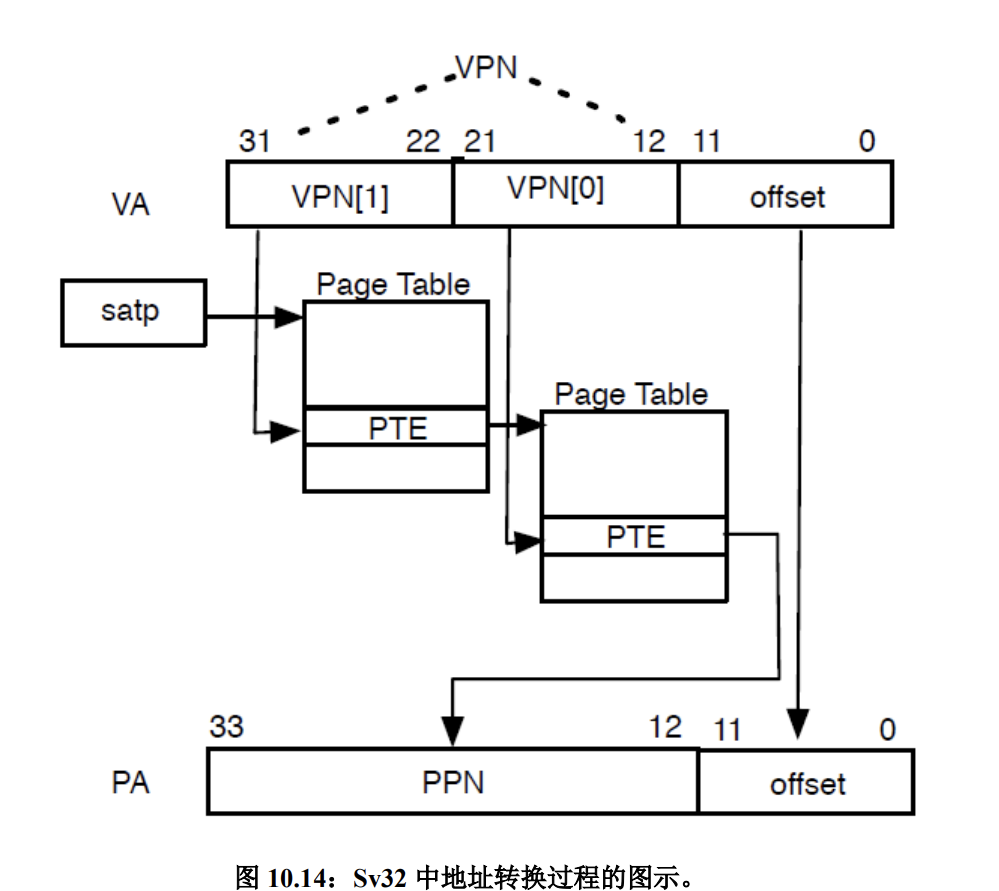
不过每次物理地址都用页表去查找转换效率还是比较低的,因此一般使用 TLB 来缓存部分地址映射。S 模式通过 sfence.vma 指令通知处理器有新缓存地址更新了,处理器根据一些算法更新 TLB。
RV 未来的可选扩展
- B 扩展:位操作
主要是一些对位的操作,比如计算前导后置0,插入 提取 测试位等。
- E 扩展:嵌入式
为了减少对低端核心的开销,削减了16个寄存器。
- H 扩展:特权态
Hypervisor,加入了管理程序模式和二级地址翻译,一般用于管理多个 OS.
- J 扩展:动态翻译
比如 java 和 js 的动态检查和垃圾回收。
- L 扩展:十进制小数
支持一些十进制小数表示运算。
- N 扩展:用户态中断
用户态中断不触发外界环境响应,直接进入用户态处理程序。
- P 扩展:单指令多数据
主要用于小资源并行运算,不过如果计算资源足够还是建议用 V 扩展解决。
- Q 扩展:四精度浮点
前提要求:已经实现了 RV64IFD。