Spring源码学习笔记—基础
前言
如果你是一个初学者。刚开始阅读Spring源码,一定会感觉特别困难。因为其中涉及太多新东西。但这正说明,Spring源码是一个宝库。
第一章 bean的元数据
一、回顾bean的注入方式
1、xml
<bean id="user" class="com.ydlclass.User" scope="prototype" autowire="byType" init-method="init" depends-on="a,b" >
<property name="name" value="jerry"/>
<property name="age" value="18"/>
</bean>
2、注解
@Controller
public class UserController {
}
@Service
@DependsOn(value = {
"xxx", "yyyy"})
public class UserService {
}
@Repository
public class UserDao {
}
@Compoment
@DependsOn(value = {
"xxx", "yyyy"})
public class RedisTemplate {
}
3、配置类
@Configuration
public class UserConfiguration {
@Bean("user")
public User user(){
User user = new User();
user.setName("lily");
user.setAge(20);
return user;
}
}
4、@Import注解
public class MySelector implements ImportSelector {
@Override
public String[] selectImports(AnnotationMetadata importingClassMetadata) {
return new String[]{
"com.ydlclass.UserService","com.ydlclass.UserDao"};
}
}
@Configuration
@Import(MySelector.class)
public class UserConfiguration {
}
二、BeanDefiniiton详解
Spring在构造bean时,不可能像我们主动构造那样,随心所欲的new,赋值、以及完成方法调用。他需要将千差万别的class概括成为一种【统一的描述性】语言,Spring提供了一个接口BeanDefintion为我们统一了这种描述bean的元数据。
bean的元数据通常是我们使用xml或者注解进行配置的数据,我们的Spring容器启动之间第一步就是加载配置数据,这些元数据会被加载到内存以一个个beanDefinition的形式保存在一个map中。
一个BeanDefiniiton大概保存了以下信息:
- 定义了id、别名与Bean的对应关系(BeanDefinitionHolder)
- 具体的工厂方法(Class类型),包括工厂方法的返回类型,工厂方法的Method对象
- 构造函数、构造函数形参类型
- Bean的class对象
- 作用范围、是否懒加载等等
以下是BeanDefiniiton的类的结构图,这里没有用类图,我觉得这里用这样的图好看一些:
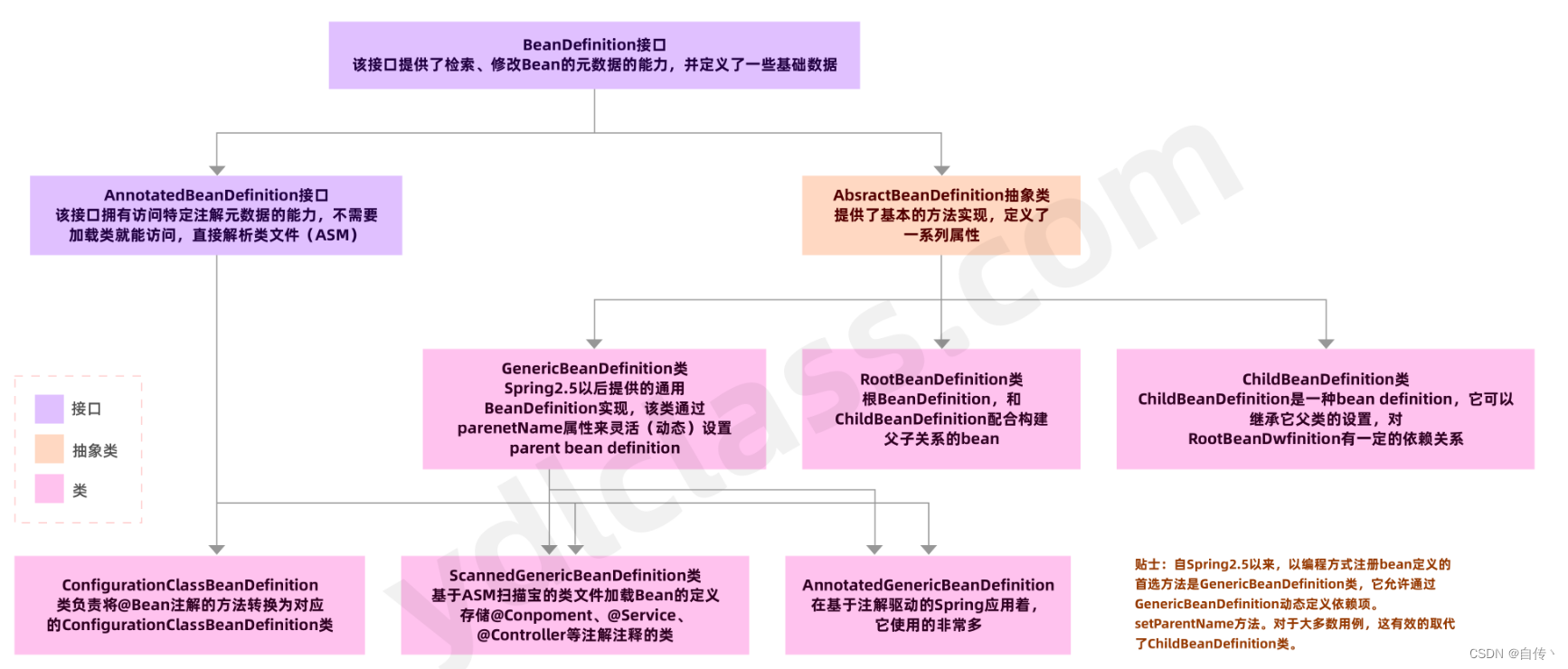
beanDefinition来源不同可能会有不同实现,目前我们最常用的实现就是GenericBeanDefinition这个实现类。
小知识:Generic(一般的,通用的),几乎所有以这个单词打头的实现,都是Spring的通用实现。
接口:接口是用来做顶层设计、依赖管理的。接口间的依赖决定了业务之间的耦合,接口是能力的抽象
抽象类:实现接口层的核心、共享的方法。模板方法设计模式涉及抽象类的运用,而Spring中即有所体现
1、认识BeanDefinition
BeanDefinition接口定义了大量的常量和方法:
public interface BeanDefinition extends AttributeAccessor, BeanMetadataElement {
// 常量标志一个bean的作用范围
String SCOPE_SINGLETON = ConfigurableBeanFactory.SCOPE_SINGLETON;
String SCOPE_PROTOTYPE = ConfigurableBeanFactory.SCOPE_PROTOTYPE;
// 设置父BeanDefinition,可以只对有父子关系的bean
void setParentName(@Nullable String parentName);
String getParentName();
// bean的类的全限定名
void setBeanClassName(@Nullable String beanClassName);
String getBeanClassName();
void setScope(@Nullable String scope);
String getScope();
void setLazyInit(boolean lazyInit);
boolean isLazyInit();
// 设置依赖性,被依赖的bean会优先创建
void setDependsOn(@Nullable String... dependsOn);
String[] getDependsOn();
// 是否允许自动装配
void setAutowireCandidate(boolean autowireCandidate);
boolean isAutowireCandidate();
// 设置是否主要bean
void setPrimary(boolean primary);
boolean isPrimary();
// 工厂bean和工厂方法
void setFactoryBeanName(@Nullable String factoryBeanName);
String getFactoryBeanName();
void setFactoryMethodName(@Nullable String factoryMethodName);
String getFactoryMethodName();
ConstructorArgumentValues getConstructorArgumentValues();
default boolean hasConstructorArgumentValues() {
return !getConstructorArgumentValues().isEmpty();
}
// 使用setter注入时的key-value对,都保存在这里
MutablePropertyValues getPropertyValues();
default boolean hasPropertyValues() {
return !getPropertyValues().isEmpty();
}
// @since 5.1初始化方法和销毁方法
void setInitMethodName(@Nullable String initMethodName);
String getInitMethodName();
void setDestroyMethodName(@Nullable String destroyMethodName);
String getDestroyMethodName();
// 为bean设置角色
void setRole(int role);
int getRole();
// bean的描述
void setDescription(@Nullable String description);
String getDescription();
// 返回此bean定义的可解析类型,基于bean类或其他特定元数据。
// 这通常在运行时合并bean定义上完全解决但不一定是在配置时定义实例上。
ResolvableType getResolvableType();
boolean isSingleton();
boolean isPrototype();
boolean isAbstract();
}
2、AbstractBeanDefinition
该类对通用核心方法完成了实现(这也是抽象类的作用),同时对一些成员变量提供了默认值:
public abstract class AbstractBeanDefinition extends BeanMetadataAttributeAccessor
implements BeanDefinition, Cloneable {
// 定义一些常量
public static final String SCOPE_DEFAULT = "";
public static final int AUTOWIRE_NO = AutowireCapableBeanFactory.AUTOWIRE_NO;
public static final int AUTOWIRE_BY_NAME = AutowireCapableBeanFactory.AUTOWIRE_BY_NAME;
public static final int AUTOWIRE_BY_TYPE = AutowireCapableBeanFactory.AUTOWIRE_BY_TYPE;
// ...还有很多
// 初始化默认值
private volatile Object beanClass;
private String scope = SCOPE_DEFAULT
private boolean autowireCandidate = true;
private boolean primary = false;
// ...还有很多
// 构造器
protected AbstractBeanDefinition() {
this(null, null);
}
// 指定构造器参数和属性参数
protected AbstractBeanDefinition(@Nullable ConstructorArgumentValues cargs, @Nullable MutablePropertyValues pvs) {
this.constructorArgumentValues = cargs;
this.propertyValues = pvs;
}
// 使用深拷贝创建一个新的
protected AbstractBeanDefinition(BeanDefinition original) {
}
// 复制一个bean的定义到当前bean,通常父子bean合并时可用
public void overrideFrom(BeanDefinition other) {
}
// ...此处省略其他的方法实现
}
3、GenericBeanDefinition
该类实现比较简单,提供了设置父子关系和构建实例的方法,该类及其子类是目前版本使用最多的BeanDefinition:
public class GenericBeanDefinition extends AbstractBeanDefinition {
@Nullable
private String parentName;
public GenericBeanDefinition() {
super();
}
// 通过深拷贝创建一个bean
public GenericBeanDefinition(BeanDefinition original) {
super(original);
}
@Override
public void setParentName(@Nullable String parentName) {
this.parentName = parentName;
}
@Override
@Nullable
public String getParentName() {
return this.parentName;
}
@Override
public AbstractBeanDefinition cloneBeanDefinition() {
return new GenericBeanDefinition(this);
}
}
此时,我们可以编写如下的测试用例:
@Test
public void testGenericBeanDefinition(){
GenericBeanDefinition beanDefinition = new GenericBeanDefinition();
beanDefinition.setBeanClassName("com.ziang.User");
// 此处类似setter注入的描述
MutablePropertyValues propertyValues = new MutablePropertyValues();
propertyValues.addPropertyValue("name","lily");
propertyValues.addPropertyValue("age",12);
beanDefinition.setPropertyValues(propertyValues);
}
注:这个测试用例及其简单,但是他却可以使用字符串的形式描述一切的类。
我们再测试一种具有继承关系的bean:
public class Dog {
private String color;
private Integer age;
}
public class TeddyDog extends Dog{
private String name;
}
xml可以如下定义:
<bean id="dog" class="com.ydlclass.Dog">
<property name="color" value="white"/>
<property name="age" value="3"/>
</bean>
<bean id="teddyDog" class="com.ydlclass.TeddyDog" parent="dog">
<property name="name" value="小红"/>
</bean>
如果是手动定义如下:
@Test
public void testRootBeanDefinition() throws ClassNotFoundException, NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException {
RootBeanDefinition dog = new RootBeanDefinition();
dog.setBeanClassName("com.ydlclass.Dog");
BeanMetadataAttribute color = new BeanMetadataAttribute("color","white");
BeanMetadataAttribute age = new BeanMetadataAttribute("age","3");
dog.addMetadataAttribute(color);
dog.addMetadataAttribute(age);
// 子Definition的创建需要依赖父Definition
ChildBeanDefinition teddy = new ChildBeanDefinition("dog");
teddy.setBeanClassName("com.ydlclass.TeddyDog");
BeanMetadataAttribute name = new BeanMetadataAttribute("name","doudou");
teddy.addMetadataAttribute(name);
}
GenericBeanDefinition在很多场景可以替换以上的内容,但是由于历史等原因,RootBeanDefinition依旧存在而且很重要,后期的归一处理还是要将不同的BeanDefinition转换或合并成一个RootBeanDefinition:
- RootBeanDefinition与AbstractBeanDefinition是互补关系,RootBeanDefinition在AbstractBeanDefinition的基础上定义了更多属性。
- RootBeanDefinition不能有父BeanDefinition,可以和ChildBeanDefinition配合使用构建父子关系(bean是可以继承的)。
- 目前最常用的BeanDefinition是GenericBeanDefinition及其子类的实现,GenericBeanDefinition很强大,也可以很轻松的独立的构建父子关系。
- 有时为了统一调用,不同的BeanDefinition可以合并、拷贝等。
// 转换的 GenericBeanDefinition definition = new GenericBeanDefinition(teddy); // 合并的 definition.overrideFrom(dog);
三、BeanDefinition注册器
有了统一标准的元数据之后,我们就可以统一管理,这就需要一个容器去存储,当然我们可以使用map这样的集合类,当然spring差不多也是这样做的,他为我们提供了一个接口BeanDefinitionRegistry。只要实现了这个接口,就会拥有注册beanDefinition的能力。
BeanDefinitionRegistry接口如下:
public interface BeanDefinitionRegistry extends AliasRegistry {
// 注册一个BeanDefinition
void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException;
void removeBeanDefinition(String beanName) throws NoSuchBeanDefinitionException;
BeanDefinition getBeanDefinition(String beanName) throws NoSuchBeanDefinitionException;
boolean containsBeanDefinition(String beanName);
String[] getBeanDefinitionNames();
int getBeanDefinitionCount();
boolean isBeanNameInUse(String beanName);
}
一个bean可以有一个id,和多个名字或别名,AliasRegistry为我们提供了注册别名的能力:
public interface AliasRegistry {
void registerAlias(String name, String alias);
void removeAlias(String alias);
boolean isAlias(String name);
String[] getAliases(String name);
}
spring给我们提供了一个超级简单的实现SimpleBeanDefinitionRegistry,如下:
public class SimpleBeanDefinitionRegistry extends SimpleAliasRegistry implements BeanDefinitionRegistry {
// 维持一个map用来保存beanDefinition,就这么简单
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(64);
// 对beanDefinition的增删查改
@Override
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "'beanName' must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
this.beanDefinitionMap.put(beanName, beanDefinition);
}
@Override
public void removeBeanDefinition(String beanName) throws NoSuchBeanDefinitionException {
if (this.beanDefinitionMap.remove(beanName) == null) {
throw new NoSuchBeanDefinitionException(beanName);
}
}
@Override
public BeanDefinition getBeanDefinition(String beanName) throws NoSuchBeanDefinitionException {
BeanDefinition bd = this.beanDefinitionMap.get(beanName);
if (bd == null) {
throw new NoSuchBeanDefinitionException(beanName);
}
return bd;
}
@Override
public boolean containsBeanDefinition(String beanName) {
return this.beanDefinitionMap.containsKey(beanName);
}
@Override
public String[] getBeanDefinitionNames() {
return StringUtils.toStringArray(this.beanDefinitionMap.keySet());
}
@Override
public int getBeanDefinitionCount() {
return this.beanDefinitionMap.size();
}
@Override
public boolean isBeanNameInUse(String beanName) {
return isAlias(beanName) || containsBeanDefinition(beanName);
}
}
这里我们编写测试用例:
@Test
public void testRegistryByJava(){
// 定义一个注册器,用来注册和管理BeanDefinition
BeanDefinitionRegistry registry = new SimpleBeanDefinitionRegistry();
// 代码方式创建
GenericBeanDefinition beanDefinition = new GenericBeanDefinition();
beanDefinition.setBeanClassName("com.ydlclass.User");
MutablePropertyValues propertyValues = new MutablePropertyValues();
propertyValues.addPropertyValue("name","lily");
propertyValues.addPropertyValue("age",12);
beanDefinition.setPropertyValues(propertyValues);
// 进行注册
registry.registerBeanDefinition("user",beanDefinition);
logger.info("The beanClassName is {}.",beanDefinition.getBeanClassName());
}
四、加载BeanDefinition
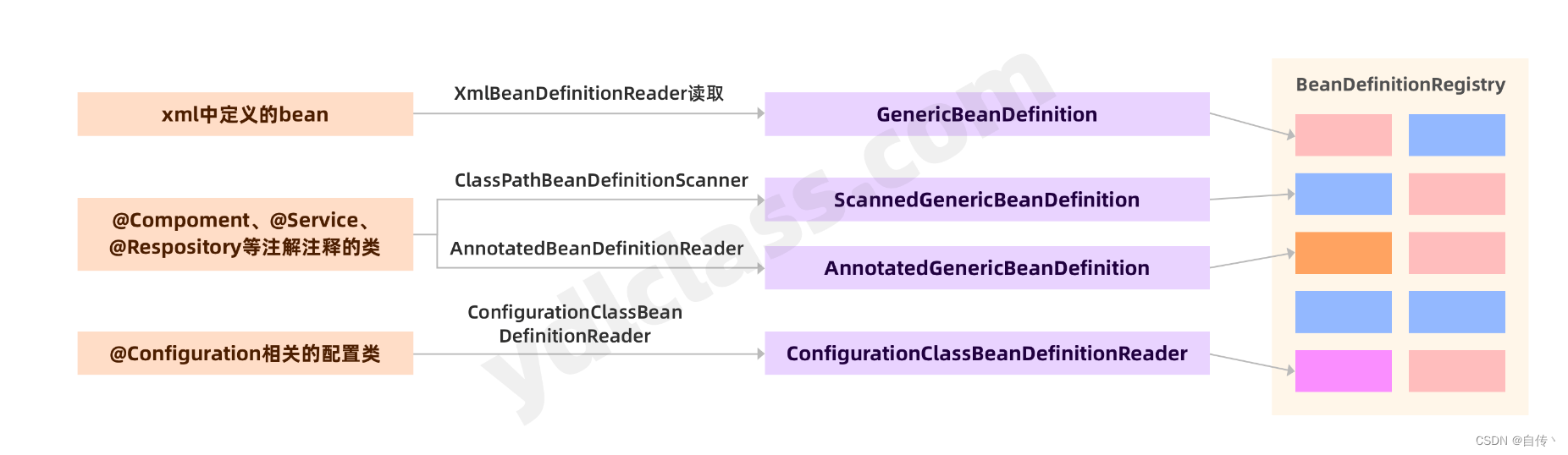
当然我们不可能为每一个类手动编写与之对应的BeanDefinition,元数据还是要从xml或注解或配置类中获取,spring也为我们提供了对应的工具。
1、读取xml配置文件
该类通过解析xml完成BeanDefinition的读取,并且将它解析的BeanDefinition注册到一个注册器中:
@Test
public void testRegistryByXml(){
// 定义一个注册器,用来注册和管理BeanDefinition
BeanDefinitionRegistry registry = new SimpleBeanDefinitionRegistry();
// 通过xml文件加载
XmlBeanDefinitionReader xmlReader = new XmlBeanDefinitionReader(registry);
xmlReader.loadBeanDefinitions("classpath:spring.xml");
logger.info(Arrays.toString(registry.getBeanDefinitionNames()));
}
原理后边介绍。
2、加载带注解的bean
@Test
public void testRegistryByAnnotation() {
// 定义一个注册器,用来注册和管理BeanDefinition
BeanDefinitionRegistry registry = new SimpleBeanDefinitionRegistry();
// 通过配置文件加载
AnnotatedBeanDefinitionReader annoReader = new AnnotatedBeanDefinitionReader(registry);
annoReader.register(User.class);
logger.info(Arrays.toString(registry.getBeanDefinitionNames()));
}
3、读取配置类
ConfigurationClassBeanDefinitionReader可以读取配置类,只是这个类不让我们使用,该类提供了如下方法:
private void loadBeanDefinitionsForConfigurationClass
private void registerBeanDefinitionForImportedConfigurationClass
private void loadBeanDefinitionsForBeanMethod(BeanMethod beanMethod)
他会将读取的元数据封装成为:ConfigurationClassBeanDefinition。
4、类路径扫描
@Test
public void testRegistryByScanner() {
// 定义一个注册器,用来注册和管理BeanDefinition
BeanDefinitionRegistry registry = new SimpleBeanDefinitionRegistry();
// 通过扫描包的方式
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(registry);
scanner.scan("com.ydlclass");
logger.info(Arrays.toString(registry.getBeanDefinitionNames()));
}
5、包扫描的过程
无论是扫包还是其他方式,我们我们解析一个类无非有几种方式:
- 加载一个类到内存,获取Class对象,通过反射获取元数据
- 直接操纵字节码文件(.class),读取字节码内的元数据
毫无疑问spring选择了第二种,
原因:第二种性能要优于第一种。第一种会将扫描的类全部加载到堆内存,无疑会浪费空间,增加gc次数,第二种可以根据元数据按需加载
我们以包扫描的doScan方法为例(ClassPathBeanDefinitionScanner类):
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
// BeanDefinitionHolder持有 BeanDefinition实例和名字以及别名
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
// 这里是具体的扫描过程,找出全部符合过滤器要求的BeanDefinition
// 返回的BeanDefinition的实际类型为ScannedGenericBeanDefinition
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 根据不同的bean类型做统一处理,如附默认值等
// 因为有些数据我们并没有配置,需要这里做默认处理
for (BeanDefinition candidate : candidates) {
// 如果存在,则解析@Scope注解,为候选bean设置代理的方式ScopedProxyMode,XML属性也能配置:scope-resolver、scoped-proxy,可以指定代理方式jdk或者cglib
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 首先从注解中获取bean的名字,如果没有
// 使用beanName生成器beanNameGenerator来生成beanName
// 在注解中的bean的默认名称和xml中是不一致的
// 注解中如果没有指定名字本质是通过ClassUtil 的 getShortName 方法获取的
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 将进一步设置应用于给定的BeanDefinition,使用AbstractBeanDefinition的一些默认属性值
//设置autowireCandidate属性,即XML的autowire-candidate属性,IoC学习的时候就见过该属性,默认为true,表示该bean支持成为自动注入候选bean
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 如果bean定义是AnnotatedBeanDefinition类型,ScannedGenericBeanDefinition同样属于AnnotatedBeanDefinition类型
if (candidate instanceof AnnotatedBeanDefinition) {
// 4 处理类上的其他通用注解:@Lazy, @Primary, @DependsOn, @Role, @Description
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 检查给定的 beanName,确定相应的bean 定义是否需要注册或与现有bean定义兼容
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
// 根据proxyMode属性的值,判断是否需要创建scope代理,一般都是不需要的
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
我们可以紧接着看看其中很重要的一个方法:
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
// Spring5的新特性,直接从"META-INF/spring.components"组件索引文件中加载符合条件的bean,避免了包扫描,用于提升启动速度
// Spring5升级的其中一个重点就提升了注解驱动的启动性能,"META-INF/spring.components"这个文件类似于一个“组件索引”文件,我们将需要加载的组件(beean定义)预先的以键值对的样式配置到该文件中,当项目中存在"META-INF/spring.components"文件并且文件中配置了属性时,Spring不会进行包扫描,而是直接读取"META-INF/spring.components"中组件的定义并直接加载,从而达到提升性能的目的。
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
我们可以添加如下的依赖,自动生成部分索引:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-indexer</artifactId>
<version>6.0.3</version>
</dependency>
编译后的文件如下:
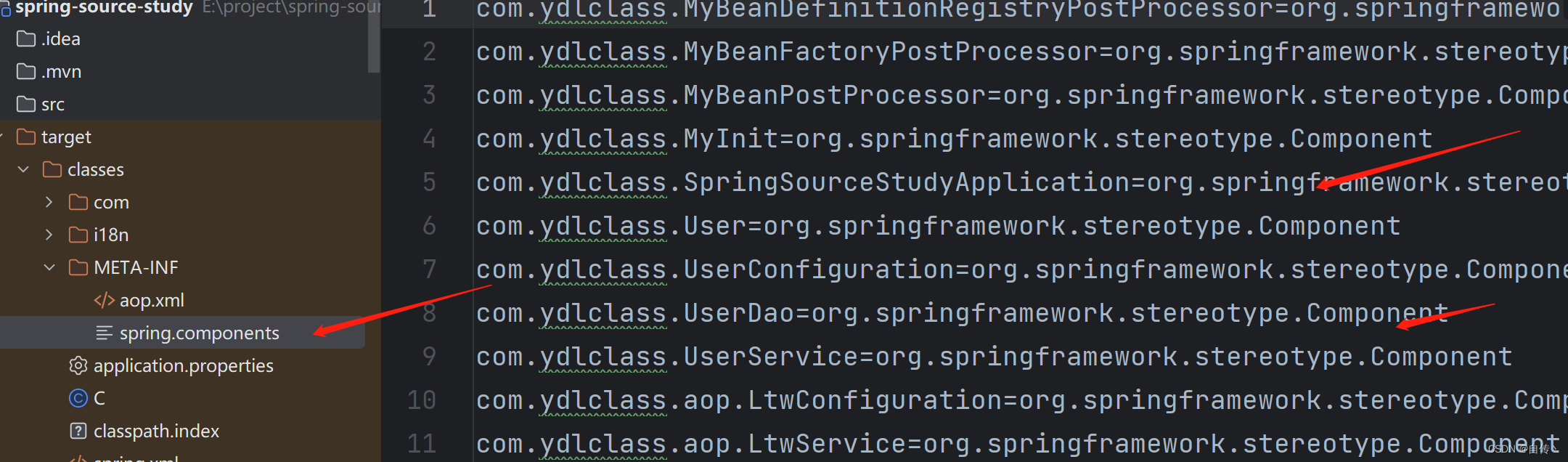
当然我们更加关注的是scanCandidateComponents方法:
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// 生成完整的资源解析路径
// com.ydlclass -> classpath*:com/ydlclass/**/*.class
// 关于资源解析的内容会在后边的课程单独讲
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 加载所有路径下的资源,我们看到前缀是"classpath*",因此项目依赖的jar包中的相同路径下资源都会被加载进来
// Spring会将每一个定义的字节码文件加载成为一个Resource资源(包括内部类都是一个Resource资源)
// 此处是以资源(流)的方式加载(普通文件),而不是将一个类使用类加载器加载到jvm中。
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
// 遍历所有的资源文件
for (Resource resource : resources) {
String filename = resource.getFilename();
// 此处忽略CGLIB生成的代理类文件,这个应该不陌生
if (filename != null && filename.contains(ClassUtils.CGLIB_CLASS_SEPARATOR)) {
continue;
}
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
try {
// getMetadataReader方法会生成一个元数据读取器
// 我们的例子中是SimpleMetadataReader
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 检查读取到的类是否可以作为候选组件,即是否符合TypeFilter类型过滤器的要求
// 使用IncludeFilter。就算目标类上没有@Component注解,它也会被扫描成为一个Bean
// 使用ExcludeFilter,就算目标类上面有@Component注解也不会成为Bean
if (isCandidateComponent(metadataReader)) {
// 构建一个ScannedGenericBeanDefinition
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
}
}
}
}
return candidates;
}
上边的源码中我们看到读取类文件的真实的实例是simpleMetadataReader,spring选用了【read+visitor】的方式来读取字节码,read负责暴露接口,visitor负责真正的读取工作:
final class SimpleMetadataReader implements MetadataReader {
SimpleMetadataReader(Resource resource, @Nullable ClassLoader classLoader) throws IOException {
SimpleAnnotationMetadataReadingVisitor visitor = new SimpleAnnotationMetadataReadingVisitor(classLoader);
// 这里是核心,一个reader需要结合一个visitor
getClassReader(resource).accept(visitor, PARSING_OPTIONS);
this.resource = resource;
// 元数据都是visitor的能力,典型的访问者设计模式
this.annotationMetadata = visitor.getMetadata();
}
// 通过资源获取一个ClassReader
private static ClassReader getClassReader(Resource resource) throws IOException {
try (InputStream is = resource.getInputStream()) {
try {
return new ClassReader(is);
}
}
}
// 提供了通用能力
@Override
public ClassMetadata getClassMetadata() {
return this.annotationMetadata;
}
@Override
public AnnotationMetadata getAnnotationMetadata() {
return this.annotationMetadata;
}
}
SimpleAnnotationMetadataReadingVisitor类使用了大量asm的内容,由此可见spring在读取元数据的时候,是直接读取class文件的内容,而非加载后通过反射获取,我们列举其中的个别属性和方法,大致能窥探一二:
final class SimpleAnnotationMetadataReadingVisitor extends ClassVisitor {
// 访问一个内部类的方法
@Override
public void visitInnerClass(String name, @Nullable String outerName, String innerName, int access) {
// ...省略
}
// 访问注解的方法
@Override
@Nullable
public AnnotationVisitor visitAnnotation(String descriptor, boolean visible) {
// ...省略
}
// 访问方法的方法
@Override
@Nullable
public MethodVisitor visitMethod(
// ...省略
}
// ...省略
}
这其中还是用了一些类如下:
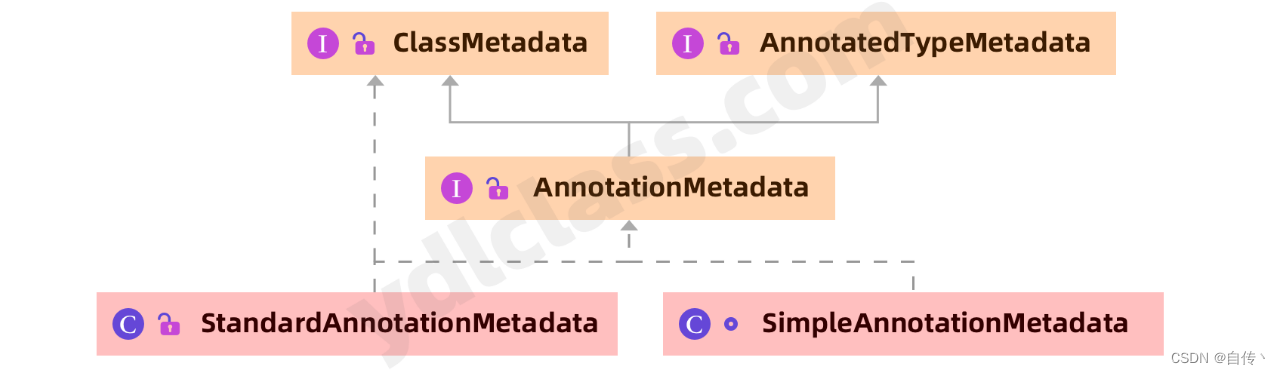
这些类都是对注解和类的元数据进行了封装,提供更简单的访问方式,很简单。
我们写一个简单的小例子,来看看:
@Test
public void testAsm() throws IOException {
Resource resource = new ClassPathResource("com/ydlclass/User.class");
ClassReader classReader = new ClassReader(resource.getInputStream());
logger.info(classReader.getClassName());
// 缺少visitor的reader能力优先,我们只做几个简单的实现
// visitor实现相对复杂,我们没有必要去学习
// classReader.accept(xxxVisitor);
// 返回的对应的常量池的偏移量+1
// 0-3 cafebaba 4-7 主次版本号 8-9 第一个是10+1
// 二进制可以使用bined插件查看
logger.info("The first item is {}.",classReader.getItem(1));
logger.info("The first item is {}.",classReader.getItem(2));
// 00 3A 这是字节码文件看到的,
// 常量池的计数是 1-57 0表示不引用任何一个常量池项目
logger.info("The first item is {}.",classReader.getItemCount());
// 通过javap -v .\User.class class文件访问标志
// flags: (0x0021) ACC_PUBLIC, ACC_SUPER 十进制就是33
// ACC_SUPER 0x00 20 是否允许使用invokespecial字节码指令的新语义.
// ACC_PUBLIC 0x00 01 是否为Public类型
logger.info("classReader.getAccess() is {}",classReader.getAccess());
}
不同的register方式形成了不同的BeanDefinition子类:
第二章 基础工具
一、内省 api
1、什么是内省?
内省(IntroSpector)是Java 语言针对Bean类属性、事件的一种缺省处理方法,Spring的源码中也会经常出现相关的api,所以我们有必要了解一下。
JavaBean是一种特殊的类,主要用于传递数据信息,这种类中的方法主要用于访问私有的字段,且方法名符合某种命名规则。说起来与反射有些相似,事实上,内省机制也是通过反射来实现的。
相对于内省,反射则更加强大,他能在运行状态把Java类中的各种成分映射成相应的Java类,可以动态的获取所有的属性以及动态调用任意一个方法,强调的是运行状态。
内省和反射的常用api如下:
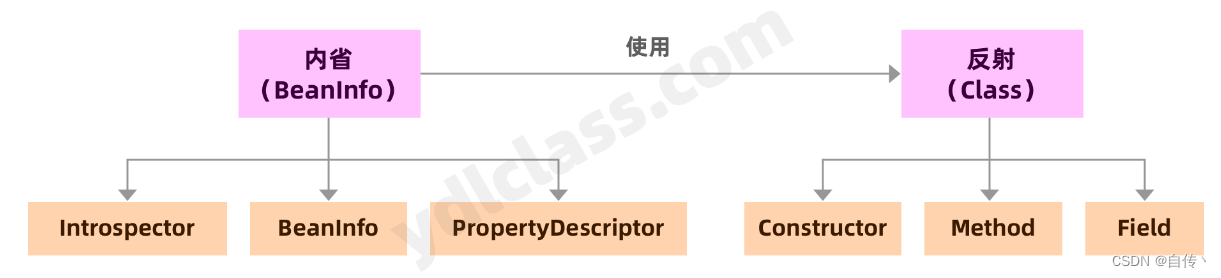 在Java内省中,用到的基本上就是上述几个类。
在Java内省中,用到的基本上就是上述几个类。
内省api的一般的做法是通过类 Introspector 的 getBeanInfo方法来获取某个对象的 BeanInfo 信息,然后通过 BeanInfo 来获取属性的描述器(PropertyDescriptor),通过这个属性描述器就可以获取某个属性对应的 取值/赋值 方法,然后我们就可以通过反射机制来调用这些方法,这就是内省机制。
import java.beans.BeanInfo;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
import java.lang.reflect.Method;
@Test
public void testIntrospect1() throws IntrospectionException {
BeanInfo beanInfo = Introspector.getBeanInfo(User.class, Object.class);
PropertyDescriptor[] propertyDescriptors = beanInfo.getPropertyDescriptors();
for (PropertyDescriptor propertyDescriptor : propertyDescriptors) {
logger.info("{}",propertyDescriptor.getPropertyType());
logger.info("{}",propertyDescriptor.getReadMethod());
logger.info("{}",propertyDescriptor.getWriteMethod());
}
}
// 2.操纵bean的指定属性:age
@Test
public void testIntrospect2() throws Exception {
User user = new User();
PropertyDescriptor pd = new PropertyDescriptor("age", User.class);
// 得到属性的写方法,为属性赋值
Method method = pd.getWriteMethod();
method.invoke(user, 24);
// 获取属性的值
method = pd.getReadMethod();
System.out.println(method.invoke(user, null));
}
大名鼎鼎的BeanUtils可以更加简单优雅的操作bean:
@Test
public void testBeanUtil() throws Exception {
User user = new User();
// 赋值
BeanUtils.setProperty(user,"name","tom");
BeanUtils.setProperty(user,"age",10);
logger.info("user->{}",user);
// 获取值
logger.info("the user's name is ->{}.",BeanUtils.getProperty(user,"name"));
}
二、更强的反射工具
在spring中,我们除了能看到内省相关的api,看到的更多的可能是反射api了,当然针对原生api的复杂性,spring同样进行了封装,让其使用起来更简单。
spring给我们提供了强大的反射工具BeanWrapper,下边的例子展示了该类如何配合BeanDefinition对其进行了实例化:
1、bean的创建
@Test
public void testCreate() throws ClassNotFoundException, NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException {
// 1、通过任意形式捕获beanDefinition
GenericBeanDefinition beanDefinition = new GenericBeanDefinition();
beanDefinition.setBeanClassName("com.ydlclass.User");
MutablePropertyValues propertyValues = new MutablePropertyValues();
propertyValues.addPropertyValue("name","lily");
propertyValues.addPropertyValue("age",12);
beanDefinition.setPropertyValues(propertyValues);
// 2、通过权限定名称获得Class
Class<?> aClass = Class.forName(beanDefinition.getBeanClassName());
// 3、使用BeanWrapper包裹实例,使其更方便使用反射方法
BeanWrapper beanWrapper = new BeanWrapperImpl(aClass);
beanWrapper.setPropertyValues(beanDefinition.getPropertyValues());
Object bean = beanWrapper.getWrappedInstance();
logger.info("The bean is [{}]",bean);
}
我们可以看到BeanWrapperImpl仅仅需要一个Class就能十分友好的结合beanDefinition进行构建和赋值,而不需要通过复杂的反射获取构造器进行实例化,获取字段对象进行赋值,当然这仅仅是api封装的功劳,原理还是那些东西。
2、批量构造
我们可以使用如下的方法进行批量构造:
@Test
public void testBatchCreate() throws ClassNotFoundException, NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException {
// 1、通过任意形式捕获beanDefinition
BeanDefinitionRegistry registry = new SimpleBeanDefinitionRegistry();
XmlBeanDefinitionReader xmlReader = new XmlBeanDefinitionReader(registry);
xmlReader.loadBeanDefinitions("classpath:spring.xml");
// 2、通过反射实例化
String[] definitionNames = registry.getBeanDefinitionNames();
for (String definitionName : definitionNames) {
BeanDefinition beanDefinition = registry.getBeanDefinition(definitionName);
String beanClassName = beanDefinition.getBeanClassName();
Class<?> aClass = Class.forName(beanClassName);
Constructor<?> constructor = aClass.getConstructor();
Object bean = constructor.newInstance();
// 3、使用BeanWrapper包裹实例,使其更方便使用反射方法
BeanWrapper beanWrapper = new BeanWrapperImpl(bean);
beanWrapper.setPropertyValues(beanDefinition.getPropertyValues());
bean = beanWrapper.getWrappedInstance();
System.out.println(bean);
}
}
貌似事与愿违,此时抛出一个异常,是说无法将一个TypedStringValue类型的数据转化为一个Integer,没有合适的转化器:
org.springframework.beans.TypeMismatchException: Failed to convert property value of type 'org.springframework.beans.factory.config.TypedStringValue' to required type 'java.lang.Integer' for property 'age';
这个问题,我们先按下不表,后边再解释,接着我们看几个常用的类:
3、ResolvableType
该类可以封装Java类型,提供对超类类型、接口和泛型参数的访问,以及最终解析为类的能力,这是非常常见的一个类,他能及其方便的简化对反射api的调用,该类在spring中的使用率非常高。
ResolvableType可以从字段、方法参数、方法返回类型或类中获得。这个类上的大多数方法本身都会返回一个ResolvableType,以便于链式调用。
官方的案例如下:
private HashMap<Integer, List<String>> myMap;
public void example() {
ResolvableType t = ResolvableType.forField(getClass().getDeclaredField("myMap"));
t.getSuperType(); // AbstractMap<Integer, List<String>>
t.asMap(); // Map<Integer, List<String>>
t.getGeneric(0).resolve(); // Integer // 获取泛型
t.getGeneric(1).resolve(); // List
t.getGeneric(1); // List<String>
//第二个泛型,里面的泛型,即List<String>里面的String
t.resolveGeneric(1, 0); // String
}
我们也可以写测试用例测试一下,光看不练是记不牢的:
@Test
public void testTypeResolvableType() throws NoSuchFieldException {
ResolvableType type = ResolvableType.forField(DefaultSingletonBeanRegistry.class.getDeclaredField("singletonObjects"));
// 获取类型
logger.info(type.getType().getTypeName());
// 获取泛型
logger.info(Arrays.toString(type.getGenerics()));
logger.info(Arrays.toString(type.getInterfaces()));
logger.info(Arrays.toString(type.resolveGenerics()));
// 获取来源
Class<?> resolve = type.resolve();
logger.info(type.getRawClass().getName());
}
Resolvable:可解析的,可分解的。spring中经常出现这个单词。如ResolvableAttribute,ResolvableType,registerResolvableDependency,后期遇到我们再学习。
三、类型转化
我们从xml中搜集到的所有数据都是【字符串】,但是实际的类中的成员变量可能是数字,数组,集合,或者是复杂的引用数据类型,所以spring给我们提供了强大的转换服务(conversionService接口)。
1、转换服务
ConversionService接口很简单,可以根据源类型和目标类型进行判断是否可以转换,并执行转换:
public interface ConversionService {
boolean canConvert(@Nullable Class<?> sourceType, Class<?> targetType);
boolean canConvert(@Nullable TypeDescriptor sourceType, TypeDescriptor targetType);
@Nullable
<T> T convert(@Nullable Object source, Class<T> targetType);
// 将给定的{@code source}转换为指定的{@code targetType}。
Object convert(@Nullable Object source, @Nullable TypeDescriptor sourceType, TypeDescriptor targetType);
}
我们不妨看看DefaultConversionService的源码,更多核心的功能是在器父类中实现的,在构造实例时,他会默认传入大量可用转化器:
public class DefaultConversionService extends GenericConversionService {
@Nullable
private static volatile DefaultConversionService sharedInstance;
public DefaultConversionService() {
// 添加大量的默认的转换器
addDefaultConverters(this);
}
// 类似单例的获取方式
public static ConversionService getSharedInstance() {
DefaultConversionService cs = sharedInstance;
if (cs == null) {
synchronized (DefaultConversionService.class) {
cs = sharedInstance;
if (cs == null) {
cs = new DefaultConversionService();
sharedInstance = cs;
}
}
}
return cs;
}
// 添加适合大多数环境的转换器
public static void addDefaultConverters(ConverterRegistry converterRegistry) {
addScalarConverters(converterRegistry);
addCollectionConverters(converterRegistry);
converterRegistry.addConverter(new ByteBufferConverter((ConversionService) converterRegistry));
converterRegistry.addConverter(new StringToTimeZoneConverter());
converterRegistry.addConverter(new ZoneIdToTimeZoneConverter());
converterRegistry.addConverter(new ZonedDateTimeToCalendarConverter());
//...还有好多
}
// 增加通用的转换器,例如集合、数组、对象等
public static void addCollectionConverters(ConverterRegistry converterRegistry) {
ConversionService conversionService = (ConversionService) converterRegistry;
converterRegistry.addConverter(new ArrayToCollectionConverter(conversionService));
converterRegistry.addConverter(new CollectionToArrayConverter(conversionService));
converterRegistry.addConverter(new StringToCollectionConverter(conversionService));
converterRegistry.addConverter(new CollectionToObjectConverter(conversionService));
converterRegistry.addConverter(new ObjectToCollectionConverter(conversionService));
//...还有好多
}
// 新增标量的转化器,主要是字符串数字类型
private static void addScalarConverters(ConverterRegistry converterRegistry) {
converterRegistry.addConverterFactory(new NumberToNumberConverterFactory());
converterRegistry.addConverterFactory(new StringToNumberConverterFactory());
converterRegistry.addConverter(Number.class, String.class, new ObjectToStringConverter());
converterRegistry.addConverter(new StringToPropertiesConverter());
converterRegistry.addConverter(new PropertiesToStringConverter());
converterRegistry.addConverter(new StringToUUIDConverter());
//...还有好多
}
}
2、独立编写转化器
在上一个例子中,我们的异常说是TypedStringValue到Integer无法转化,TypedStringValue是Spring对String的一个包装,具体的值是存在TypedStringValue中的,我们的DefaultConversionService没有默认的转换器,当然实际Spring在转换的时候会做出处理,我们也可以自己写TypedStringValueToInteger和TypedStringValueToString的转换器:
@Test
public void testBatchCreateByBeanWrapper() throws ClassNotFoundException, NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException {
// 1.通过任意形式捕获beanDefinition
BeanDefinitionRegistry registry = new SimpleBeanDefinitionRegistry();
XmlBeanDefinitionReader xmlReader = new XmlBeanDefinitionReader(registry);
xmlReader.loadBeanDefinitions("classpath:spring.xml");
// 2.通过反射实例化
for (String definitionName : registry.getBeanDefinitionNames()) {
BeanDefinition beanDefinition = registry.getBeanDefinition(definitionName);
String beanClassName = beanDefinition.getBeanClassName();
Constructor<?> constructor = Class.forName(beanClassName).getConstructor();
Object bean = constructor.newInstance();
// 3.注册类型转换器:由于xml配置中的字符串会被转化为TypedStringValue类型,
// 而TypedStringValue无法自由转化为其他类型(如Integer、String),所以需要自行定义转化器并注册入转化服务
DefaultConversionService conversionService = new DefaultConversionService();
conversionService.addConverter(new Converter<TypedStringValue, Integer>() {
@Override
public Integer convert(@NonNull TypedStringValue source) {
return Integer.valueOf(Objects.requireNonNull(source.getValue()));
}
});
conversionService.addConverter(new Converter<TypedStringValue, String>() {
@Override
public String convert(@NonNull TypedStringValue source) {
return source.getValue();
}
});
// 4.使用BeanWrapper包裹实例,使其更方便使用反射方法
BeanWrapper beanWrapper = new BeanWrapperImpl(bean);
beanWrapper.setConversionService(conversionService);
beanWrapper.setPropertyValues(beanDefinition.getPropertyValues());
bean = beanWrapper.getWrappedInstance();
logger.info(bean.toString());
}
}
3、转化器源码
所有注册的convertor都会存储在Converters中,该类结构相对比较复杂:
private static class Converters {
// 存取通用的转换器,并不限定转换类型,一般用于兜底
private final Set<GenericConverter> globalConverters = new CopyOnWriteArraySet<>();
// 指定了类型对,对应的转换器们的映射关系。
// ConvertiblePair:表示一对,包含sourceType和targetType
// ConvertersForPair:这一对对应的转换器们(因为能处理一对类型转换可能存在多个转换器),内部使用一个双端队列Deque来存储,保证顺序
private final Map<ConvertiblePair, ConvertersForPair> converters = new ConcurrentHashMap<>(256);
public void add(GenericConverter converter) {
// 获得他的类型对儿
Set<ConvertiblePair> convertibleTypes = converter.getConvertibleTypes();
if (convertibleTypes == null) {
// 如果没有限定转换类型,添加到globalConverters
this.globalConverters.add(converter);
}
else {
// 如果已经存在转换类型,我们写的都在这里
for (ConvertiblePair convertiblePair : convertibleTypes) {
// 找到与之匹配的加进去,这里是个链表
getMatchableConverters(convertiblePair).add(converter);
}
}
}
@Nullable
public GenericConverter find(TypeDescriptor sourceType, TypeDescriptor targetType) {
// 搜索完整的类型层次结构,父类--->
// 比如想要搜索【虎猫 -> 老虎】,但如过虎猫有父类(猫)
// 我们还需检索【猫 -> 老虎】
List<Class<?>> sourceCandidates = getClassHierarchy(sourceType.getType());
List<Class<?>> targetCandidates = getClassHierarchy(targetType.getType());
for (Class<?> sourceCandidate : sourceCandidates) {
for (Class<?> targetCandidate : targetCandidates) {
// 所有的类型都要匹配
ConvertiblePair convertiblePair = new ConvertiblePair(sourceCandidate, targetCandidate);
// 找到一个就返回
GenericConverter converter = getRegisteredConverter(sourceType, targetType, convertiblePair);
if (converter != null) {
return converter;
}
}
}
return null;
}
@Nullable
private GenericConverter getRegisteredConverter(TypeDescriptor sourceType,
TypeDescriptor targetType, ConvertiblePair convertiblePair) {
// 根据convertiblePair获取ConvertersForPair
ConvertersForPair convertersForPair = this.converters.get(convertiblePair);
if (convertersForPair != null) {
GenericConverter converter = convertersForPair.getConverter(sourceType, targetType);
if (converter != null) {
return converter;
}
}
// 检查是否能匹配兜底的全局转换器
for (GenericConverter globalConverter : this.globalConverters) {
if (((ConditionalConverter) globalConverter).matches(sourceType, targetType)) {
return globalConverter;
}
}
return null;
}
}
ConvertiblePair:表示一对,包含sourceType和targetType
final class ConvertiblePair {
private final Class<?> sourceType;
private final Class<?> targetType;
}
ConvertersForPair:这一对对应的转换器们(因为能处理一对类型转换可能存在多个转换器),内部使用一个双端队列Deque来存储,保证顺序。它的结构如下:

private static class ConvertersForPair {
// 内部维护的队列
private final Deque<GenericConverter> converters = new ConcurrentLinkedDeque<>();
public void add(GenericConverter converter) {
this.converters.addFirst(converter);
}
@Nullable
public GenericConverter getConverter(TypeDescriptor sourceType, TypeDescriptor targetType) {
for (GenericConverter converter : this.converters) {
// 此处表明,如果我们有特殊的需求,还可以实现ConditionalGenericConverter,实现特殊的匹配规则,连边中的converter可以有不同的匹配规则,
// 当然通常情况下会返回第一个
if (!(converter instanceof ConditionalGenericConverter genericConverter) ||
genericConverter.matches(sourceType, targetType)) {
return converter;
}
}
return null;
}
}
4、PropertyEditor
你还有可能看到有些地方的文章将类型转换器使用的是PropertyEditor,这个类是定义在java.beans中的接口,功能和本章内容相似,是spring3.0之前使用的转换器,我们就不用看了:
BeanWapper中使用如下方法添加:beanWrapper.registerCustomEditor(xxxxPropertyEditor);
有兴趣的可以自行学习。
四、资源获取
Spring的【Resource】接口位于【org.springframework.core.io】 包,他抽象了对资源的访问的能力。 下面提供了【Resource】接口的概述, Spring本身广泛地使用了Resource接口,这个我们之前就接触过了。
public interface Resource extends InputStreamSource {
boolean exists();
boolean isReadable();
boolean isOpen();
boolean isFile();
URL getURL() throws IOException;
URI getURI() throws IOException;
File getFile() throws IOException;
ReadableByteChannel readableChannel() throws IOException;
long contentLength() throws IOException;
long lastModified() throws IOException;
Resource createRelative(String relativePath) throws IOException;
String getFilename();
String getDescription();
}
1、内置的 Resource的实现
Spring包含了几个内置的 Resource 实现,如下所示:
- UrlResource:UrlResource包装了java.net.URL,可以用来访问任何需要通过URL访问的对象,例如文件、HTTPS目标、FTP目标等。 所有URL都用一个标准化的字符串表示,这样就可以使用适当的标准化前缀来表示不同类型的URL。 这包括用于访问文件系统路径的’ file: ‘,用于通过https协议访问资源的’ https: ‘,用于通过ftp访问资源的’ ftp: '等。
- ClassPathResource:该类表示应该从【类路径】中获取的资源。 它使用线程上下文类装入器、给定的类装入器或给定的类装入资源。
- FileSystemResource:这是面向java.io的Resource实现,可以简单的实现对系统文件的操作。
- InputStreamResource:给定的InputStream的Resource实现。 只有当没有特定的资源实现适用时,才应该使用它。
- ByteArrayResource:这是一个给定字节数组的资源实现。
我们编写以下三个测试有用例来简单学习感知一下:
@Test
public void testUrl() throws IOException {
Resource resource = new UrlResource("https://dldir1.qq.com/qqfile/qq/PCQQ9.7.0/QQ9.7.0.28921.exe");
FileOutputStream fos = new FileOutputStream("\\" + resource.getFilename());
// 该工具包需要引入commons-io
IOUtils.copy(resource.getInputStream(), fos);
}
@Test
public void testFileSystem() throws IOException {
Resource resource = new FileSystemResource("\\spring\\spring.xml");
byte[] buffer = new byte[1024 * 100];
int offset = IOUtils.read(resource.getInputStream(), buffer);
logger.info(new String(buffer, 0, offset));
}
@Test
public void testClassPath() throws IOException {
Resource resource = new ClassPathResource("spring.xml");
byte[] buffer = new byte[1024 * 100];
int offset = IOUtils.read(resource.getInputStream(), buffer);
logger.info(new String(buffer, 0, offset));
}
2、xml解析
这里我们接着之前的源码继续深入,回顾我们之前的加载beanDefinition的过程:
- 加载.class文件资源,这里和类加载不是一个概念。
- 加载xml文件
首先我们看一个小知识点:
- 前缀[classpath:*] :只会到target下面的class路径中查找文件,通常匹配一个资源。
- 前缀[classpath*:] :不仅包含target下面的class路径,还包括jar文件中(target下面的class路径)进行查找,可以匹配多个资源,这种场景非常多,比如在实现了springboot自动装配相关的jar包中绝大多数都会有spring.factories文件。
spring给我们提供了springPathMatchingResourcePatternResolver类,该工具可以很灵活的帮助我们获取对应的Resource实例,他提供了getResource和getResources方法为我们使用:
public Resource getResource(String location) {
Assert.notNull(location, "Location must not be null");
// 留给我们的扩展的协议解析器,如自定义
for (ProtocolResolver protocolResolver : getProtocolResolvers()) {
Resource resource = protocolResolver.resolve(location, this);
if (resource != null) {
return resource;
}
}
if (location.startsWith("/")) {
return getResourceByPath(location);
}
// classpath:
else if (location.startsWith(CLASSPATH_URL_PREFIX)) {
return new ClassPathResource(location.substring(CLASSPATH_URL_PREFIX.length()), getClassLoader());
} else {
try {
// 尝试将位置解析为URL…
URL url = ResourceUtils.toURL(location);
// 检测是不是file: vfsfile:打头的
return (ResourceUtils.isFileURL(url) ? new FileUrlResource(url) : new UrlResource(url));
}
}
}
我们写一个测试用例如下:
@Test
public void testPathMatchingResourcePatternResolver() throws IOException {
PathMatchingResourcePatternResolver resourcePatternResolver = new PathMatchingResourcePatternResolver();
Resource httpResource = resourcePatternResolver.getResource("https://leetcode.cn/problems/permutation-sequence/");
// https://leetcode.cn/problems/permutation-sequence/
logger.info(httpResource.getURI().toString());
Resource classPathResource = resourcePatternResolver.getResource("classpath:spring.xml");
// file:/Users/ziang.zhang/dreamPointer/JavaSpace/JavaProjects/spring-framework-source/spring-framework-source/spring-ziang-demo/build/resources/test/spring.xml
logger.info(classPathResource.getURI().toString());
Resource fileResource = resourcePatternResolver.getResource("file:/Users/ziang.zhang/Downloads/chrome/dcf57c3fb1a448bba392e5b1f0cd302f.png");
// file:/Users/ziang.zhang/Downloads/chrome/dcf57c3fb1a448bba392e5b1f0cd302f.png
logger.info(fileResource.getURI().toString());
Resource[] resources = resourcePatternResolver.getResources("classpath*:META-INF/spring.factories");
for (Resource resource : resources) {
// jar:file:/Users/ziang.zhang/dreamPointer/JavaSpace/JavaProjects/spring-framework-source/spring-framework-source/spring-beans/build/libs/spring-beans-5.2.23.BUILD-SNAPSHOT.jar!/META-INF/spring.factories
logger.info(resource.getURI().toString());
}
}
当然我们也可以调用getResources方法获取类路径下的所有的同名文件:
我们可以写如下的测试用例:
public void testMoreFile() throws IOException {
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
Resource[] resources = resolver.getResources("classpath*:/META-INF/spring.factories");
for (Resource resource : resources) {
System.out.println(resource.getURI());
}
}
结果如下:

源码的部分,我们从以下方法看起:
xmlReader.loadBeanDefinitions("classpath:spring.xml");
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException {
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader instanceof ResourcePatternResolver) {
try {
// 此方法会返回一个以上可用的Resource实现,根据前缀特征
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
int count = loadBeanDefinitions(resources);
return count;
}
}
else {
// 只能加载单个资源的绝对URL。
Resource resource = resourceLoader.getResource(location);
int count = loadBeanDefinitions(resource);
if (actualResources != null) {
actualResources.add(resource);
}
if (logger.isTraceEnabled()) {
logger.trace("Loaded " + count + " bean definitions from location [" + location + "]");
}
return count;
}
}
回到我们的doLoadBeanDefinitions方法中:
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
Document doc = doLoadDocument(inputSource, resource);
int count = registerBeanDefinitions(doc, resource);
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + count + " bean definitions from " + resource);
}
return count;
}
}
继续进入核心方法loadDocument:
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
// ...其他省略
return builder.parse(inputSource);
}
此时,xml文件变成了Document对象,以下的内容无需再看,解析使用的不是dom4j而是jdk自带的org.w3c.dom相关的api。
以下是解析dom的部分:
我们回到doLoadBeanDefinitions中,再看一眼registerBeanDefinitions方法,该方法是将DOM注册为beanDefinition的地方
int count = registerBeanDefinitions(doc, resource);
一直进入核心方法,如下正是在解决各个一级标签,如import、bean、alias等:
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}
我们跟进到一个解析bean标签的方法,一直跟进可以找到如下代码:
@Nullable
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, @Nullable BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));
// 获取className
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
try {
// 创建bean的定义
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 解析属性标签scope、lazy-init等
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
// 解析<meta key="" value=""/>
parseMetaElements(ele, bd);
// <lookup-method></lookup-method>
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
// <replaced-method></replaced-method>
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
// 构造注入的元素
parseConstructorArgElements(ele, bd);
// setter注入的元素
parsePropertyElements(ele, bd);
// 解析qualifier
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}
catch (ClassNotFoundException ex) {
error("Bean class [" + className + "] not found", ele, ex);
}
catch (NoClassDefFoundError err) {
error("Class that bean class [" + className + "] depends on not found", ele, err);
}
catch (Throwable ex) {
error("Unexpected failure during bean definition parsing", ele, ex);
}
finally {
this.parseState.pop();
}
return null;
}
看到此处,如何加载xml文件我们已经了然于胸。
五、环境抽象
spring提供了Environment接口,是一个对环境的抽象,集成在容器中,它模拟了应用程序环境的两个关键方面,分别是profiles和properties。
一个profile是一个给定名字的,在【逻辑上分了组】的beanDifination配置,只有在给定的profile是激活的情况下才向容器注册。
properties 在几乎所有的应用程序中都扮演着重要的角色,他就是一大堆的key-value的集合,他可能源自各种来源:属性文件、JVM系统属性、系统环境变量、JNDI、servlet上下文参数、特定的【Properties】对象、“Map”对象等等。 与属性相关的Environment对象的作用是为用户提供一个方便的服务接口,用于配置属性源并从那里解析属性。
1、properties
Spring中的环境对象提供了对【属性】的搜索操作,我们看一下下边的例子:
@Test
public void testMoreEnvProperties() throws IOException {
ApplicationContext ctx = new GenericApplicationContext();
Environment env = ctx.getEnvironment();
boolean containsMyProperty = env.containsProperty("JAVA_HOME");
logger.info("Does my environment contain the 'JAVA_HOME' property? {}", containsMyProperty);
}
当然我们也可以debug,观察其中的env变量:
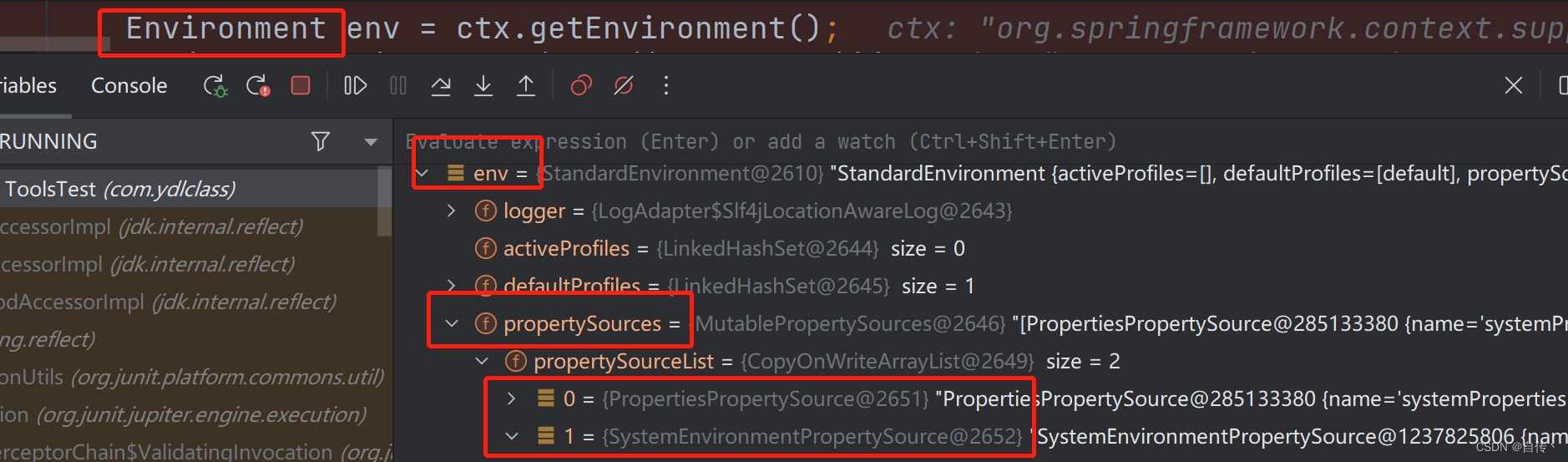 在前面的代码片段中,我们看到了查询在spring的env中是否存在【JAVA_HOME】属性。 为了回答这个问题,Environment对象对propertySources中的【PropertySource】执行搜索。
在前面的代码片段中,我们看到了查询在spring的env中是否存在【JAVA_HOME】属性。 为了回答这个问题,Environment对象对propertySources中的【PropertySource】执行搜索。
这里边又出现了PropertySource的概念,他是对任何【键值对源】的一个简单抽象, spring的StandardEnvironment配置了两个基础PropertySource对象:
(1)一个代表JVM系统属性的集合(“System.getProperties()”)
@Test
public void testSystemProperties() {
Properties properties = System.getProperties();
Set<Map.Entry<Object, Object>> entries = properties.entrySet();
for (Map.Entry<Object,Object> entry:entries){
System.out.println(entry);
}
}
 (2)一个代表系统环境变量的设置(System.getenv()”)
(2)一个代表系统环境变量的设置(System.getenv()”)
@Test
public void testSystemEnv() {
Map<String, String> env = System.getenv();
Set<Map.Entry<String, String>> entries = env.entrySet();
for (Map.Entry<String,String> entry:entries){
System.out.println(entry);
}
}
其值如下,部分截取:
 StandardEnvironment的源码如下,默认情况便确实会将这两个propertySource加入env:
StandardEnvironment的源码如下,默认情况便确实会将这两个propertySource加入env:
public class StandardEnvironment extends AbstractEnvironment {
/** System environment property source name: {@value}. */
public static final String SYSTEM_ENVIRONMENT_PROPERTY_SOURCE_NAME = "systemEnvironment";
/** JVM system properties property source name: {@value}. */
public static final String SYSTEM_PROPERTIES_PROPERTY_SOURCE_NAME = "systemProperties";
@Override
protected void customizePropertySources(MutablePropertySources propertySources) {
propertySources.addLast(
new PropertiesPropertySource(SYSTEM_PROPERTIES_PROPERTY_SOURCE_NAME, getSystemProperties()));
propertySources.addLast(
new SystemEnvironmentPropertySource(SYSTEM_ENVIRONMENT_PROPERTY_SOURCE_NAME, getSystemEnvironment()));
}
}
当然,整个机制都是可配置的。 我们可以将自定义的属性源集成到此搜索中。 为此,我们可以实例化自己的【PropertySource】,并将它添加到当前’ Environment ‘的’ propertyssources '集合中,如下:
public class MyPropertySource extends PropertySource<String> {
public MyPropertySource(String name) {
super(name);
}
@Override
public String getProperty(String name) {
// 这里可以是源自任何逻辑的键值对来源,
// 可以从properties文件中检索,也可以是数据库检索,等等
return "hello";
}
}
测试用例如下:
@Test
public void testStandardEnvironment() {
StandardEnvironment env = new StandardEnvironment();
MutablePropertySources sources = env.getPropertySources();
sources.addFirst(new MyPropertySource("my-source"));
}
【@PropertySource 】注解提供了一种方便的声明性机制,用于向Spring的【Environment】中添加【 PropertySource】。
给定一个名为app的propertis文件,输入内容,如【teacherName=itnanls】,编写如下配置类:
@Configuration
@PropertySource("classpath:app.properties")
public class EnvPropertiesConfig {
}
测试用例如下:
@Test
public void testEnvironment() {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(EnvPropertiesConfig.class);
logger.info(applicationContext.getEnvironment().getProperty("my.name"));
logger.info(applicationContext.getEnvironment().getProperty("my.age"));
}
2、Profiles
Profiles在核心容器中提供了一种机制,允许在不同环境中注册不同的Bean。 “环境”这个词对不同的用户有不同的含义,
- 在开发中使用内存中的数据源,还是在生产中从JNDI中查找的数据源。
- 为客户A和客户B部署注册定制的bean实现。
考虑一个实际应用程序中的第一个用例,它需要一个“数据源”。 在测试环境中,配置可能类似如下:
@Bean
public DataSource dataSource() {
return new EmbeddedDatabaseBuilder()
.setType(EmbeddedDatabaseType.HSQL)
.addScript("classpath:com/bank/config/sql/schema.sql")
.addScript("classpath:com/bank/config/sql/test-data.sql")
.build();
}
现在考虑如何将该应用程序部署到生产环境中,假设应用程序的数据源已注册到生产应用程序服务器的JNDI目录中。 我们的 ‘dataSource’ bean现在看起来如下所示:
@Bean
public DataSource dataSource() throws Exception {
Context ctx = new InitialContext();
return (DataSource) ctx.lookup("java:comp/env/jdbc/datasource");
}
重点:问题是如何根据当前环境在使用这两种数据源之间进行切换?
当然,我们可以使用 @Profile。
【@Profile】注解允许您指出,当一个或多个bean在哪一种Profile被激活时被注入。 使用前面的例子,我们可以将dataSource配置重写如下:
@Configuration
@Profile("development")
public class StandaloneDataConfig {
@Bean
public DataSource dataSource() {
return new EmbeddedDatabaseBuilder()
.setType(EmbeddedDatabaseType.HSQL)
.addScript("classpath:com/bank/config/sql/schema.sql")
.addScript("classpath:com/bank/config/sql/test-data.sql")
.build();
}
}
@Configuration
@Profile("production")
public class JndiDataConfig {
@Bean(destroyMethod="")
public DataSource dataSource() throws Exception {
Context ctx = new InitialContext();
return (DataSource) ctx.lookup("java:comp/env/jdbc/datasource");
}
}
@Profile也可以在方法级别声明,只包含一个配置类的一个特定bean(例如,对于一个特定bean的替代变体),如下面的示例所示:
@Configuration
public class AppConfig {
@Bean("dataSource")
@Profile("development")
public DataSource standaloneDataSource() {
return new EmbeddedDatabaseBuilder()
.setType(EmbeddedDatabaseType.HSQL)
.addScript("classpath:com/bank/config/sql/schema.sql")
.addScript("classpath:com/bank/config/sql/test-data.sql")
.build();
}
@Bean("dataSource")
@Profile("production")
public DataSource jndiDataSource() throws Exception {
Context ctx = new InitialContext();
return (DataSource) ctx.lookup("java:comp/env/jdbc/datasource");
}
}
3、激活一个配置
现在我们已经更新了配置,我们仍然需要指示Spring哪个配置文件是活动的。 如果我们现在启动我们的样例应用程序,我们会看到抛出一个NoSuchBeanDefinitionException,因为容器无法找到名为dataSource的Spring bean。
激活配置文件有几种方式,但最直接的方式是通过【ApplicationContext】可用的【Environment】API以编程方式执行。 下面的例子展示了如何做到这一点:
@Test
public void testProfile(){
// 创建容器
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
// 激活环境
context.getEnvironment().setActiveProfiles("development");
// 扫包
context.scan("com.ydlclass.datasource");
// 刷新
context.refresh();
// 使用
DataSource bean = context.getBean(DataSource.class);
logger.info("{}",bean);
}
此外,你还可以通过spring.profiles来声明性地激活环境【active】属性,它可以通过系统环境变量、JVM系统属性、servlet上下文参数在’ web.xml '中指定。
请注意,配置文件不是一个“非此即彼”的命题。 你可以一次激活多个配置文件。 通过编程方式,你可以向 ‘setActiveProfiles()’ 方法提供多个配置文件名,该方法接受 'String…'可变参数。 下面的示例激活多个配置文件:
加入启动参数:
-Dspring.profiles.active="profile1,profile2"
编程的方式:
ctx.getEnvironment().setActiveProfiles("profile1", "profile2");
spring-boot中会更加简单,我们这里就不赘述了:
spring.profiles.active=dev
六、发布订阅
1、简介
spring为我们提供了event multicaster,可以十分简单的实现发布订阅模式:
multicast(组播): 也叫多播, 多点广播或群播。 指把信息同时传递给一组目的地址。它使用策略是最高效的,因为消息在每条网络链路上只需传递一次,而且只有在链路分叉的时候,消息才会被复制。
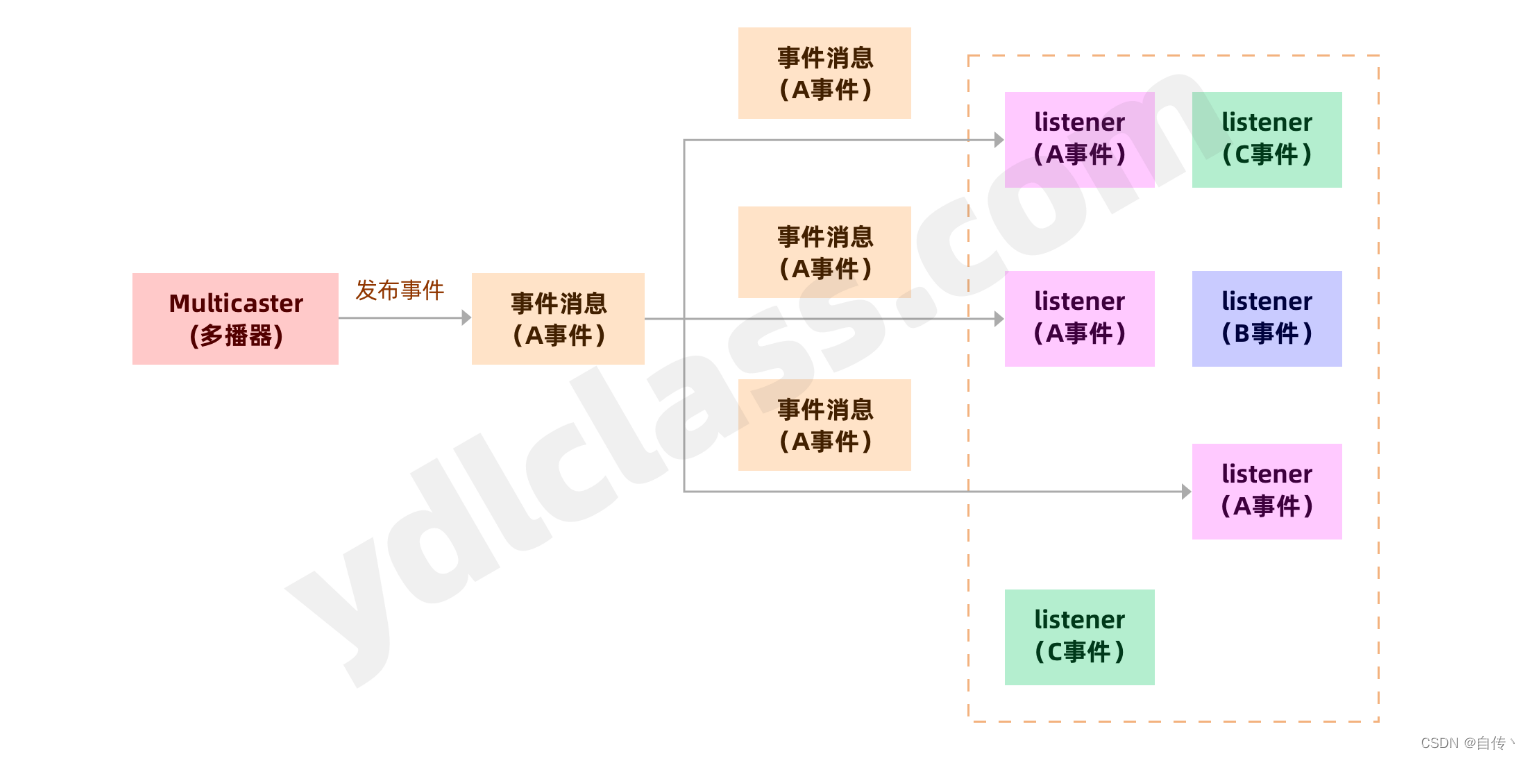
spring启动时也会默认注入一个如下的bean:simpleApplicationEventMulticaster,我们可以使用这个类轻松实现事件机制,这是典型的【观察者设计模式】:
@Test
public void testEventMulticaster() {
SimpleApplicationEventMulticaster caster = new SimpleApplicationEventMulticaster();
caster.addApplicationListener(new EmailListener());
caster.addApplicationListener(new EmailListener());
caster.addApplicationListener(new MessageListener());
caster.multicastEvent(new OrderEvent("FYI, check your order!"));
}
结果如下:

2、源码阅读
这其中有很多复杂的情况,比如listener是我们直接手动注册的实例呢,还是spring工厂中的bean呢,如果是bean是singleton还是prototype呢?
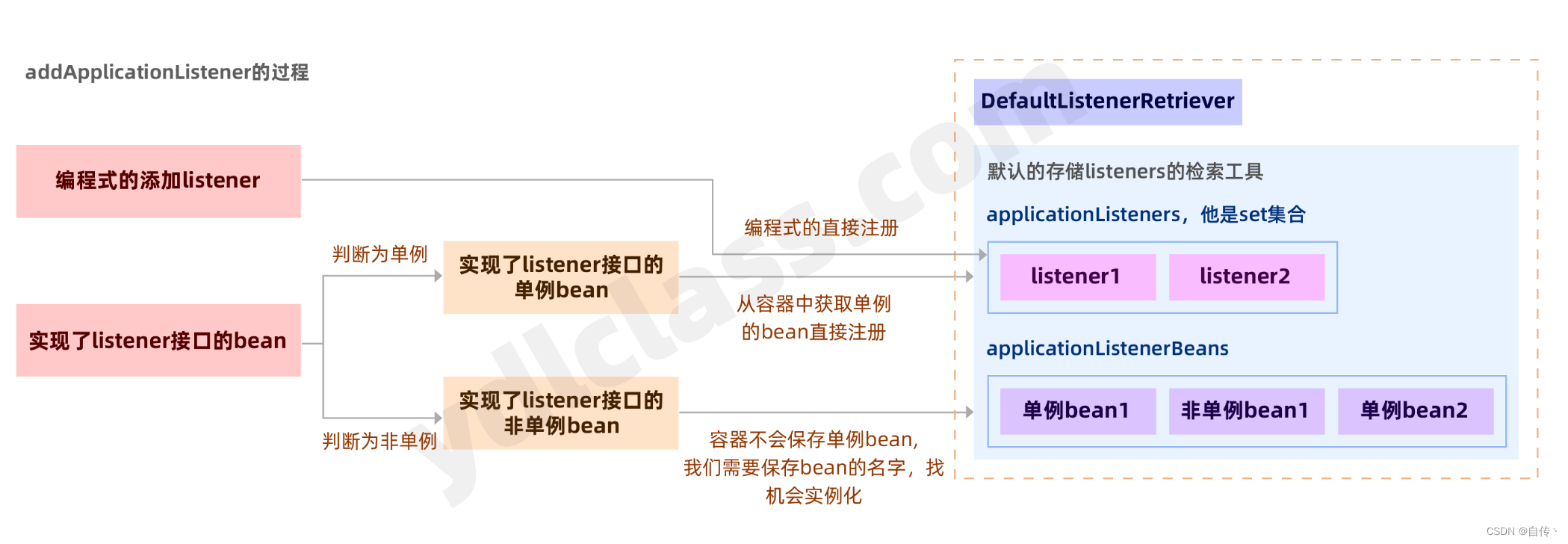
因为源码比较复杂,我们需要结合下图一起看:
图一:
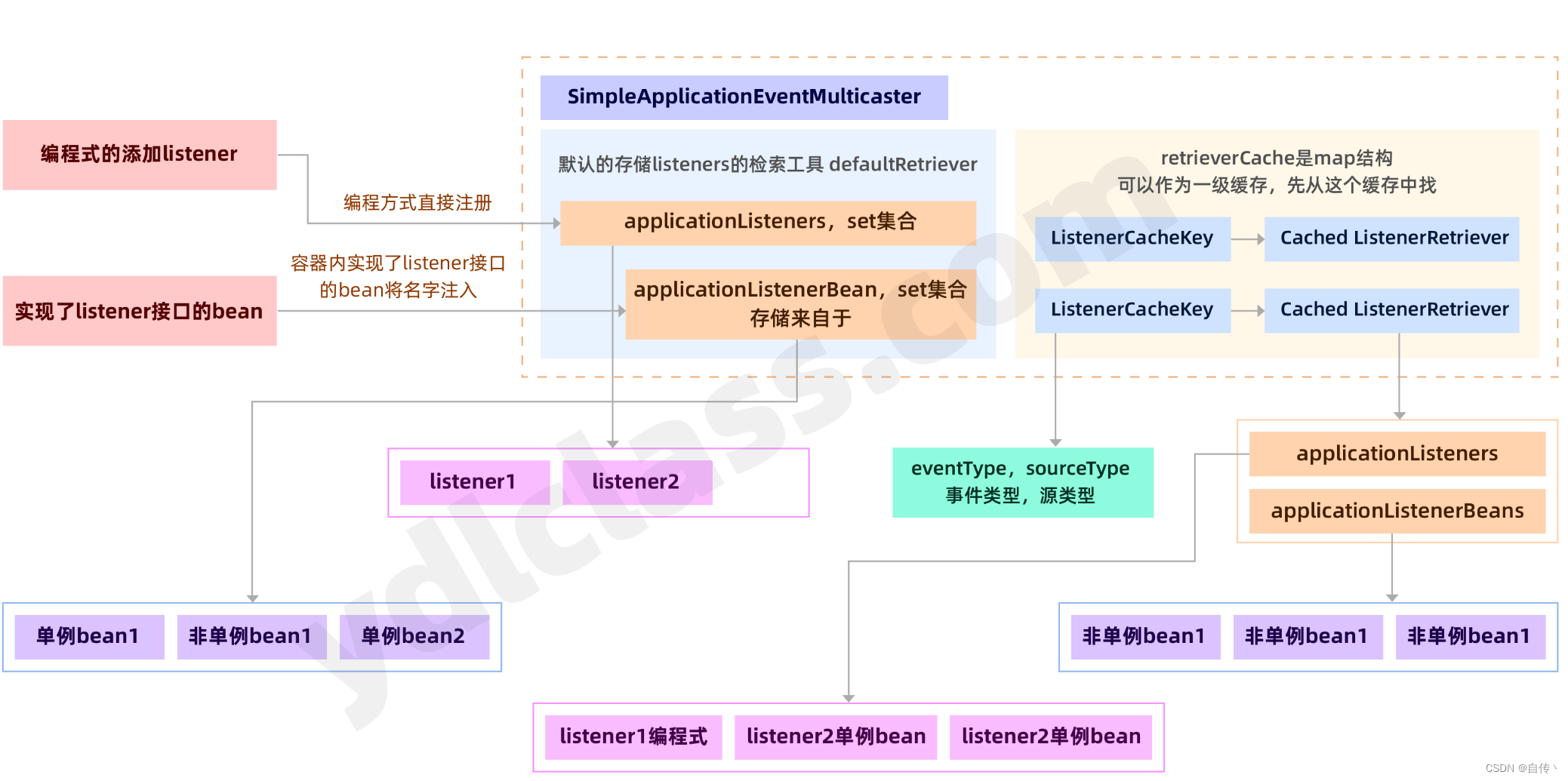
图二显示了当listener被调用执行后,如何进行了缓存:
SimpleApplicationEventMulticaster源码如下:
public class SimpleApplicationEventMulticaster extends AbstractApplicationEventMulticaster {
// 定义一个线程池,事件被触发时可由他来实现事件,默认为null
private Executor taskExecutor;
// 这个用来捕获listener执行过程中产生的异常
// 需要这用 赋值caster.setErrorHandler(new XxxErrorHandler())
private ErrorHandler errorHandler;
private volatile Log lazyLogger;
public SimpleApplicationEventMulticaster() {
}
public SimpleApplicationEventMulticaster(BeanFactory beanFactory) {
setBeanFactory(beanFactory);
}
public void setErrorHandler(@Nullable ErrorHandler errorHandler) {
this.errorHandler = errorHandler;
}
@Nullable
protected ErrorHandler getErrorHandler() {
return this.errorHandler;
}
//设置一个自定义执行器(线程池)来调用每个侦听器。
public void setTaskExecutor(@Nullable Executor taskExecutor) {
this.taskExecutor = taskExecutor;
}
@Nullable
protected Executor getTaskExecutor() {
return this.taskExecutor;
}
// 广播一个事件
@Override
public void multicastEvent(ApplicationEvent event) {
multicastEvent(event, resolveDefaultEventType(event));
}
// 广播一个事件的具体实现
@Override
public void multicastEvent(final ApplicationEvent event, @Nullable ResolvableType eventType) {
ResolvableType type = (eventType != null ? eventType : resolveDefaultEventType(event));
Executor executor = getTaskExecutor();
// 核心一:getApplicationListeners(event, type)稍后看
// 他的重点是如何设计的缓存
// 获取所有与event事件匹配的listener并调用核心方法onApplicationEvent
for (ApplicationListener<?> listener : getApplicationListeners(event, type)) {
// 如果你设置了线程池他会将任务丢给线程池
if (executor != null) {
// 核心二:调用Listener的方法invokeListener
executor.execute(() -> invokeListener(listener, event));
}
// 否则就以单线程的方式运行
else {
invokeListener(listener, event);
}
}
}
// 调用listener的方法
protected void invokeListener(ApplicationListener<?> listener, ApplicationEvent event) {
// ErrorHandler可以保存Listener在执行过程中产生的异常
// 其默认为null,我们可以独立设置
ErrorHandler errorHandler = getErrorHandler();
if (errorHandler != null) {
try {
doInvokeListener(listener, event);
}
catch (Throwable err) {
// 将执行listener时产生放入errorHandler
errorHandler.handleError(err);
}
}
else {
// 负责直接调用
doInvokeListener(listener, event);
}
}
@SuppressWarnings({
"rawtypes", "unchecked"})
private void doInvokeListener(ApplicationListener listener, ApplicationEvent event) {
try {
// 调用方法
listener.onApplicationEvent(event);
}
// 捕获类型转化异常
catch (ClassCastException ex) {
String msg = ex.getMessage();
if (msg == null || matchesClassCastMessage(msg, event.getClass()) ||
(event instanceof PayloadApplicationEvent && matchesClassCastMessage(msg, ((PayloadApplicationEvent) event).getPayload().getClass())) ) {
// 可能是lambda定义的侦听器,我们无法为其解析泛型事件类型
// 让我们抑制异常。
Log loggerToUse = this.lazyLogger;
if (loggerToUse == null) {
loggerToUse = LogFactory.getLog(getClass());
this.lazyLogger = loggerToUse;
}
if (loggerToUse.isTraceEnabled()) {
loggerToUse.trace("Non-matching event type for listener: " + listener, ex);
}
} else {
throw ex;
}
}
}
private boolean matchesClassCastMessage(String classCastMessage, Class<?> eventClass) {
// 在Java 8上,消息以类名“Java .lang”开始。字符串不能强制转换…
if (classCastMessage.startsWith(eventClass.getName())) {
return true;
}
// 在Java 11中,消息以“class…”开头,也就是class . tostring ()
if (classCastMessage.startsWith(eventClass.toString())) {
return true;
}
// 在Java 9上,用于包含模块名称的消息:" Java .base/ Java .lang. lang. xml "。字符串不能强制转换…”
int moduleSeparatorIndex = classCastMessage.indexOf('/');
if (moduleSeparatorIndex != -1 && classCastMessage.startsWith(eventClass.getName(), moduleSeparatorIndex + 1)) {
return true;
}
// 假设一个不相关的类转换失败……
return false;
}
}
其父类中有更多实现,包括getApplicationListeners(event, type):
public abstract class AbstractApplicationEventMulticaster
implements ApplicationEventMulticaster, BeanClassLoaderAware, BeanFactoryAware {
// 真正保存listener的地方,他保存了传入的listener实例和容器里的监听器bean的名字
// 其结构如图1
private final DefaultListenerRetriever defaultRetriever = new DefaultListenerRetriever();
// 这个集合是对已调用的event和listener的缓存
// ListenerCacheKey保存了一组event和source
// CachedListenerRetriever保存了已注册的、容器的单例bean、容器的非单例beanName
// 非单例的bean只能缓存name,实例会消亡
final Map<ListenerCacheKey, Cached Retriever> retrieverCache = new ConcurrentHashMap<>(64);
@Nullable
private ClassLoader beanClassLoader;
@Nullable
private ConfigurableBeanFactory beanFactory;
// 以编程的方式添加监听器
@Override
public void addApplicationListener(ApplicationListener<?> listener) {
// 这个过程可能存在线程安全的问题,比如一线线程
synchronized (this.defaultRetriever) {
// 因为你的Aop可能影响到该listener
// 我们需要将代理对象从defaultRetriever中删除,因为我们并不需要
Object singletonTarget = AopProxyUtils.getSingletonTarget(listener);
if (singletonTarget instanceof ApplicationListener) {
this.defaultRetriever.applicationListeners.remove(singletonTarget);
}
// 添加原生的监听器到defaultRetriever
this.defaultRetriever.applicationListeners.add(listener);
// 清理缓存
this.retrieverCache.clear();
}
}
// 直接以bean的方式将listenerBeanName添加到defaultRetriever
@Override
public void addApplicationListenerBean(String listenerBeanName) {
synchronized (this.defaultRetriever) {
this.defaultRetriever.applicationListenerBeans.add(listenerBeanName);
// 清理缓存
this.retrieverCache.clear();
}
}
// 获得所有的bean的实例
// 第一部分:编程式的bean的实例
// 第二部分:容器的bean,进行实例化
protected Collection<ApplicationListener<?>> getApplicationListeners() {
synchronized (this.defaultRetriever) {
return this.defaultRetriever.getApplicationListeners();
}
}
// ...省略掉大量雷同的crud(增删查改)代码
// 我们看一个比较有难度的方法,该方法根据事件获取满足条件的listeners
protected Collection<ApplicationListener<?>> getApplicationListeners(
ApplicationEvent event, ResolvableType eventType) {
// 获得事件源(那个类中发布的时间(如OrderService类发布是orderEvent))
// source就是OrderService,event就是orderEvent
Object source = event.getSource();
Class<?> sourceType = (source != null ? source.getClass() : null);
// 通过事件类型和源类型创建缓存key
// 第二次请求就避免了再次检索
ListenerCacheKey cacheKey = new ListenerCacheKey(eventType, sourceType);
// 定义新的Listener缓存器,他是作为retrieverCache的value
CachedListenerRetriever newRetriever = null;
// 核心:快速检查缓存中的内容
CachedListenerRetriever existingRetriever = this.retrieverCache.get(cacheKey);
if (existingRetriever == null) {
// 满足条件,则在existingRetriever缓存一个新的条目
// key->ListenerCacheKey(eventType和sourceType)
// value->CachedListenerRetriever(保存了与key匹配的listeners)
if (this.beanClassLoader == null ||(ClassUtils.isCacheSafe(event.getClass(), this.beanClassLoader) &&
(sourceType == null || ClassUtils.isCacheSafe(sourceType, this.beanClassLoader)))) {
// 创建一个新的缓存器,目前里边为空
newRetriever = new CachedListenerRetriever();
// 将这个key和检索器放入整体缓存map中
existingRetriever = this.retrieverCache.putIfAbsent(cacheKey, newRetriever);
// 添加失败,则将newRetriever置空
// 多线程下可能会添加失败,两个线程同时添加,只能有一个成功
if (existingRetriever != null) {
// 将new的缓存器置空,复用其他线程创建的
newRetriever = null;
}
}
}
// 如果缓存命中(缓存中存在这一对key-value)
if (existingRetriever != null) {
Collection<ApplicationListener<?>> result = existingRetriever.getApplicationListeners();
// 将缓存中的Listeners全部取出,返回
if (result != null) {
return result;
}
// 缓存命中没有拿到结果,此时result为null
// 这种一般出现在多线程情况,有一个线程已经创建了这个缓存器,但是还没有机会赋值
// 当前线程又拿到了这个缓存器,那我们就继续
}
// 该方法会为我们当前根据key过滤合适的listeners,并缓存器赋值
return retrieveApplicationListeners(eventType, sourceType, newRetriever);
}
// 该方法会给传入的newRetriever赋值,检索过程相对复杂
// 这个方法会过滤满足条件的Listeners,并将过滤后的内容放到缓存中
private Collection<ApplicationListener<?>> retrieveApplicationListeners(
ResolvableType eventType, @Nullable Class<?> sourceType, @Nullable CachedListenerRetriever retriever) {
// 保存所有过滤好的listeners
// 他包含编程式的实例和容器的bean
List<ApplicationListener<?>> allListeners = new ArrayList<>();
// 过滤后的监听器,将来做缓存用
Set<ApplicationListener<?>> filteredListeners = (retriever != null ? new LinkedHashSet<>() : null);
// 过滤后的监听器beanName,将来做缓存用
Set<String> filteredListenerBeans = (retriever != null ? new LinkedHashSet<>() : null);
Set<ApplicationListener<?>> listeners;
Set<String> listenerBeans;
// 每个线程拷贝独立的listeners和listenerBeans
synchronized (this.defaultRetriever) {
// 优先做一个拷贝
listeners = new LinkedHashSet<>(this.defaultRetriever.applicationListeners);
listenerBeans = new LinkedHashSet<>(this.defaultRetriever.applicationListenerBeans);
}
// 将所有的listener实例遍历,过滤满足条件的
for (ApplicationListener<?> listener : listeners) {
if (supportsEvent(listener, eventType, sourceType)) {
// 如果传递了缓存器,就将它存入filteredListeners
if (retriever != null) {
filteredListeners.add(listener);
}
allListeners.add(listener);
}
}
// bean要在这里获取初始化
if (!listenerBeans.isEmpty()) {
// 这里初始化
ConfigurableBeanFactory beanFactory = getBeanFactory();
for (String listenerBeanName : listenerBeans) {
try {
// 判断beanFactory是不是支持该事件
if (supportsEvent(beanFactory, listenerBeanName, eventType)) {
// 从bean工厂获取,实例化bean
ApplicationListener<?> listener =
beanFactory.getBean(listenerBeanName,ApplicationListener.class);
if (!allListeners.contains(listener) && supportsEvent(listener, eventType, sourceType)) {
if (retriever != null) {
// 如果是单例的就加入filteredListeners
if (beanFactory.isSingleton(listenerBeanName)) {
filteredListeners.add(listener);
}
// 如果不是单例bean,则加入filteredListenerBeans
// 原因是非单例bean使用结束可能会被gc,下次使用需要重新实例化
// 所以,我们并不缓存非单例的listenerbean
else {
filteredListenerBeans.add(listenerBeanName);
}
}
// 无论是不是单例,都将实例加入allListeners,
// 他将作为当前方法的返回值
allListeners.add(listener);
}
}
else {
// 删除不匹配的侦听器
// ApplicationListenerDetector,可能被额外的排除
// BeanDefinition元数据(例如工厂方法泛型)
Object listener = beanFactory.getSingleton(listenerBeanName);
if (retriever != null) {
filteredListeners.remove(listener);
}
allListeners.remove(listener);
}
}
catch (NoSuchBeanDefinitionException ex) {
}
}
}
// 给结果排序
AnnotationAwareOrderComparator.sort(allListeners);
// 实际进行缓存的地方
// 在这里我们缓存了applicationListeners(编程式的和单例的bean)
// 和applicationListenerBeans,主要是非单例bean的名字
// 下次从缓存获取的时候还是会再次实例化非单例的bean
if (retriever != null) {
// 如果啥也没有过滤则添加全部的Listeners和ListenerBeans到retriever
if (filteredListenerBeans.isEmpty()) {
retriever.applicationListeners = new LinkedHashSet<>(allListeners);
retriever.applicationListenerBeans = filteredListenerBeans;
}
else {
retriever.applicationListeners = filteredListeners;
retriever.applicationListenerBeans = filteredListenerBeans;
}
}
return allListeners;
}
}
value:CachedListenerRetriever的实现:
//listener缓存工具类,它封装了一组特定的目标侦听器,允许高效检索预先过滤的侦听器。每个事件类型和源类型缓存这个helper的实例。
private class CachedListenerRetriever {
// 保存了满足条件的applicationListeners
// 包含编程式的和容器内满足条件的单例bean
@Nullable
public volatile Set<ApplicationListener<?>> applicationListeners;
// 保存了满足条件的非单例的applicationListenerBeans
@Nullable
public volatile Set<String> applicationListenerBeans;
// 该方法是从特定缓存获取applicationListeners
// 这个方法会再次实例化非单例的bean
@Nullable
public Collection<ApplicationListener<?>> getApplicationListeners() {
Set<ApplicationListener<?>> applicationListeners = this.applicationListeners;
Set<String> applicationListenerBeans = this.applicationListenerBeans;
if (applicationListeners == null || applicationListenerBeans == null) {
// Not fully populated yet
return null;
}
// 创建一个临时的集合保存所有的监听器
List<ApplicationListener<?>> allListeners = new ArrayList<>(
applicationListeners.size() + applicationListenerBeans.size());
allListeners.addAll(applicationListeners);
// 这里实例化剩下的bean,容器内的非单例bean
// 这里不一样的地方是非单单例的bean,每次清除缓存都要重新实例化
if (!applicationListenerBeans.isEmpty()) {
BeanFactory beanFactory = getBeanFactory();
for (String listenerBeanName : applicationListenerBeans) {
try {
allListeners.add(beanFactory.getBean(listenerBeanName, ApplicationListener.class));
}
catch (NoSuchBeanDefinitionException ex) {
}
}
}
// 对他进行重排序
if (!applicationListenerBeans.isEmpty()) {
AnnotationAwareOrderComparator.sort(allListeners);
}
return allListeners;
}
}
默认的listener的存储器:
private class DefaultListenerRetriever {
public final Set<ApplicationListener<?>> applicationListeners = new LinkedHashSet<>();
public final Set<String> applicationListenerBeans = new LinkedHashSet<>();
public Collection<ApplicationListener<?>> getApplicationListeners() {
List<ApplicationListener<?>> allListeners = new ArrayList<>(
this.applicationListeners.size() + this.applicationListenerBeans.size());
allListeners.addAll(this.applicationListeners);
if (!this.applicationListenerBeans.isEmpty()) {
BeanFactory beanFactory = getBeanFactory();
for (String listenerBeanName : this.applicationListenerBeans) {
try {
ApplicationListener<?> listener =
beanFactory.getBean(listenerBeanName, ApplicationListener.class);
if (!allListeners.contains(listener)) {
allListeners.add(listener);
}
}
catch (NoSuchBeanDefinitionException ex) {
// 单例侦听器实例(没有支持bean定义)消失,可能在销毁阶段的中间
}
}
}
AnnotationAwareOrderComparator.sort(allListeners);
return allListeners;
}
}
你可以尝试在listener中添加如下代码:
System.out.println("thread --> " + Thread.currentThread().getName());
我们可以尝试修改之前的代码,当然我们也可以设定异常处理器:
@Test
public void testEventMulticaster(){
SimpleApplicationEventMulticaster caster = new SimpleApplicationEventMulticaster();
// 这是任务执行器,线程池
caster.setTaskExecutor(Executors.newFixedThreadPool(10));
// 设置异常处理器
caster.setErrorHandler(new ErrorHandler() {
@Override
public void handleError(Throwable t) {
// 做补偿处理,发送通知等等操作
System.out.println("有异常了,快来处理");
logger.error("此处发生了异常-->", t);
}
});
caster.addApplicationListener(new EmailListener());
caster.addApplicationListener(new EmailListener());
caster.addApplicationListener(new MessageListener());
caster.multicastEvent(new OrderEvent(this));
}
我们可以看到,现在listener的调用线程确实是从线程池中获取。
七、国际化
spring引入了MessageSource机制,可以帮我们简单的实现国际化( internationalization),简称i18n。
ResourceBundleMessageSource是一个简单的实现,我们可以建立如下的文件用以测试:
 文件内容超级简单,分别是:
文件内容超级简单,分别是:
- zh_CN的文件内容:hello=你好 {0}
- en_us的文件内容:hello=hello {0}
使用以下的测试用例就可以简单的获取对应Locale的内容:
@Test
public void testMessageSource() {
ResourceBundleMessageSource rbs = new ResourceBundleMessageSource();
rbs.setBasename("i18n/message");
rbs.setDefaultEncoding("UTF-8");
rbs.setDefaultLocale(Locale.CHINA);
String hello = rbs.getMessage("hello", new Object[]{
"tom"}, Locale.US);
System.out.println(hello);
}
关于方法中的几个参数的描述:
- string code:文件中的key
- Object[] args:待解析字符串的参数,value中可以存在带{}占位符的变量
- String defaultMessage:读取不到国际化信息时依据此默认值进行处理
- Locale locale:国际化定位,如 Locale.CHINA 代表中国
更多关于国际化的内容我们可以在后边再做介绍。