本文是根据 Datawhale 开源教程LeetCode 算法笔记(Leetcode-Notes)做的笔记 https://github.com/datawhalechina/leetcode-notes,主要记录学习过程中的一些重要的是知识点。
一. 数据结构与算法
1. 数据结构
数据结构的作用,就是为了提高计算机硬件的利用率。
对于数据结构,我们可以按照数据的 「逻辑结构」 和 「物理结构」 来进行分类。
1.1 逻辑结构
| 逻辑结构(Logical Structure):数据元素之间的相互关系。
1. 集合结构
- 唯一性:集合中元素唯一、没有重复的元素
- 无序性:元素之间没有关系,无序的
2. 线性结构
一对一
线性结构中的数据元素(除了第一个和最后一个元素),左侧和右侧分别只有一个数据与其相邻。、
线性结构类型包括:数组和链表,以及他们衍生出来的栈、队列、哈希表
3. 树形结构
一对多
最简单的树形结构是二叉树,树型结构类型还包括多叉树、字典树等
4. 图形结构
多对多
图形结构类型包括:无向图、有向图、连通图等。
2. 物理结构
| 物理结构(Physical Structure):数据的逻辑结构在计算机中的存储方式。
2.1 顺序存储
元素在内存中顺序存储,占用一个连续的内存空间,数据的逻辑关系通过数据的内存地址直接反映
优点:简单、易理解,节省内存
缺点:存储分配要事先进行;另外对于一些操作的时间效率较低(移动、删除元素等操作)
2.2 链式存储
随机存储,在内存中可以连续也可以不连续,哪里有用哪里
链式存储结构中,一般将每个数据元素占用的若干单元的组合称为一个链结点。每个链结点不仅要存放一个数据元素的数据信息,还要存放一个指出这个数据元素在逻辑关系的直接后继元素所在链结点的地址,该地址被称为指针。换句话说,数据元素之间的逻辑关系是通过指针来间接反映的。
优点:便于插入、删除等操作
缺点:占用内存大,不仅要存储数据,还要存储数据间的逻辑关系(指针)
2. 算法
「算法」 指的就是解决问题的方法
2.1 算法的特性
- 输入(可以没有输入)
- 输出(一个或多个输出,至少要有一个输出)
- 有穷性(可以在可接受的时间内完成)
- 确定性(每一条代码都要有明确的含义,不能有歧义)
- 可行性(每一步都能通过执行有限次数完成,并且可以转换为程序在计算机上运行并得到正确的结果)
2.2 一个好的算法追求的目标
- 正确性
- 可读性
- 健壮性
- 时间复杂度低(运行快)
- 空间复杂度低(占用内存少)
二. 时间复杂度常见误区及知识点整理
1. 什么是时间复杂度?
时间复杂度是一个函数,它定性描述该算法的运行时间。
在程序开发中,开发者用来估算自己的程序需要的运行时间
那么如何估算程序的运行时间呢?我们通常通过算法的操作单元数量来代表程序运行的消耗时间,这里默认CPU的每个单元运行消耗的时间都是相同的。
假设算法(程序)的问题规模是n,可以用f(n)来表示问题规模n需要的操作单元数量。随着数据规模 n 的增大,算法执行时间的增长率和f(n)的增长率相同,这称作为算法的渐近时间复杂度,简称时间复杂度,记为 O(f(n))。
接下来我们将这个函数进行解释,方便理解。O(f(n))的形式是不是类似于我们以前见到的 f(x) ,首先让我们想一想 f(x) 表示的含义:
| f(x): 自变量为 x ,因变量为 f(x) ,f(x)随着x的变化而变化
那么我们很容易可以得到 O(f(n)) 的解释:
| O(f(n)):自变量为问题规模 n 需要的操作单元数量 f(n) ,因变量为算法时间复杂度O(f(n)) ,O(f(n)) 随着 f(n) 的变化而变化
2. 不同数据规模的差异
如下图中可以看出不同算法的时间复杂度在不同数据输入规模下的差异。

时间复杂度,不同数据规模的差异
在决定使用哪些算法的时候,不是时间复杂越低的越好(因为简化后的时间复杂度忽略了常数项等等),要考虑数据规模,如果数据规模很小,用O(n^2)的算法甚至比O(n)的可能更好(在有常数项的时候)。
那为什么在计算时间复杂度的时候要忽略常数项系数呢?也就说 O(5n) 看成 O(n) 的时间复杂度,O(5n^2) 看成 O(n^2) 的时间复杂度,而且要默认O(n) 优于 O(n^2) 呢 ?
这里就又涉及到大O的定义,因为大O就是数据量级突破一个点且数据量级非常大的情况下所表现出的时间复杂度,这个数据量也就是常数项系数已经不起决定性作用的数据量。
所以我们说的时间复杂度都是省略常数项系数的,是因为一般情况下都是默认数据规模足够的大,基于这样的事实,给出的算法时间复杂的的一个排行如下所示:
O(1)常数阶 < O(logn)对数阶 < O(n)线性阶 < O(nlogn)线性对数阶 < O(n^2)平方阶 < O(n^3)立方阶 < O(2^n)指数阶
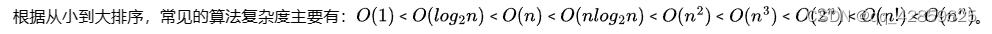
但是也要注意,如果这个常数非常大,例如10^7 ,10^9 ,那么常数就是不得不考虑的因素了。
3. O(logn)中的log是以什么为底?
平时说这个算法的时间复杂度是logn的,那么一定是log 以2为底n的对数么?
其实不然,也可以是以10为底n的对数,也可以是以20为底n的对数,但我们统一说 logn,也就是忽略底数的描述。
为什么可以这么做呢?
首先让我们回顾一个高中学过的换底公式:
根据上面的公式,我们可以得到 以10为底n的对数= 以2为底n的对数 / 以2为底10的对数 * ,也就是:
| 以2为底n的对数 = 以2为底10的对数 * 以10为底n的对数
其中第一项是常数,因此 以2为底n的对数的时间复杂度 = 以10为底n的对数的时间复杂度
4. 递归算法的时间复杂度
一些同学可能一看到递归就想到了O(log n),其实并不是这样,递归算法的时间复杂度本质上是要看: 递归的次数 * 每次递归中的操作次数
具体如何分析参考https://programmercarl.com/前序/通过一道面试题目,讲一讲递归算法的时间复杂度!.html。
拓展: 什么是空间复杂度呢?
是对一个算法在运行过程中占用内存空间大小的量度,记做S(n)=O(f(n))。关注空间复杂度有两个常见的相关问题
- 空间复杂度是考虑程序(可执行文件)的大小么?
空间复杂度是考虑程序运行时占用内存的大小,而不是可执行文件的大小。
- 空间复杂度是准确算出程序运行时所占用的内存么?
不要以为空间复杂度就已经精准的掌握了程序的内存使用大小,很多因素会影响程序真正内存使用大小,例如编译器的内存对齐,编程语言容器的底层实现等等这些都会影响到程序内存的开销。
所以空间复杂度是预先大体评估程序内存使用的大小。
三. 练习
2. 0709. 转换成小写字母
2.1 题目大意
描述:给定一个字符串 s s s。
要求:将该字符串中的大写字母转换成相同的小写字母,返回新的字符串。
说明:
- 1 ≤ s . l e n g t h ≤ 100 1 \le s.length \le 100 1≤s.length≤100。
- s s s 由 ASCII 字符集中的可打印字符组成。
示例:
- 示例 1:
输入:s = "Hello"
输出:"hello"
- 示例 2:
输入:s = "LOVELY"
输出:"lovely"
实现
def lower_string(s):
result = ""
for char in s:
if 'A' <= char <= 'Z':
result += chr(ord(char) + 32)
else:
result += char
return result
列出完整的ASCII码对照表:
| ASCII值 | 对应字符 | ASCII值 | 对应字符 | ASCII值 | 对应字符 |
|---|---|---|---|---|---|
| 0 | NUL(null) | 32 | (space) | 64 | @ |
| 1 | SOH (start of header) | 33 | ! | 65 | A |
| 2 | STX (start of text) | 34 | " | 66 | B |
| 3 | ETX (end of text) | 35 | # | 67 | C |
| 4 | EOT (end of transmission) | 36 | $ | 68 | D |
| 5 | ENQ (enquiry) | 37 | % | 69 | E |
| 6 | ACK (acknowledge) | 38 | & | 70 | F |
| 7 | BEL (bell) | 39 | ’ | 71 | G |
| 8 | BS (backspace) | 40 | ( | 72 | H |
| 9 | TAB (horizontal tab) | 41 | ) | 73 | I |
| 10 | LF (NL line feed, new line) | 42 | * | 74 | J |
| 11 | VT (vertical tab) | 43 | + | 75 | K |
| 12 | FF (NP form feed, new page) | 44 | , | 76 | L |
| 13 | CR (carriage return) | 45 | - | 77 | M |
| 14 | SO (shift out) | 46 | . | 78 | N |
| 15 | SI (shift in) | 47 | / | 79 | O |
| 16 | DLE (data link escape) | 48 | 0 | 80 | P |
| 17 | DC1 (device control 1) | 49 | 1 | 81 | Q |
| 18 | DC2 (device control 2) | 50 | 2 | 82 | R |
| 19 | DC3 (device control 3) | 51 | 3 | 83 | S |
| 20 | DC4 (device control 4) | 52 | 4 | 84 | T |
| 21 | NAK (negative acknowledge) | 53 | 5 | 85 | U |
| 22 | SYN (synchronous idle) | 54 | 6 | 86 | V |
| 23 | ETB (end of trans. block) | 55 | 7 | 87 | W |
| 24 | CAN (cancel) | 56 | 8 | 88 | X |
| 25 | EM (end of medium) | 57 | 9 | 89 | Y |
| 26 | SUB (substitute) | 58 | : | 90 | Z |
| 27 | ESC (escape) | 59 | ; | 91 | [ |
| 28 | FS (file separator) | 60 | < | 92 | \ |
| 29 | GS (group separator) | 61 | = | 93 | ] |
| 30 | RS (record separator) | 62 | > | 94 | ^ |
| 31 | US (unit separator) | 63 | ? | 95 | _ |
| ASCII值 | 对应字符 | ASCII值 | 对应字符 |
|---|---|---|---|
| 96 | ` | 112 | p |
| 97 | a | 113 | q |
| 98 | b | 114 | r |
| 99 | c | 115 | s |
| 100 | d | 116 | t |
| 101 | e | 117 | u |
| 102 | f | 118 | v |
| 103 | g | 119 | w |
| 104 | h | 120 | x |
| 105 | i | 121 | y |
| 106 | j | 122 | z |
| 107 | k | 123 | { |
| 108 | l | 124 | | |
| 109 | m | 125 | } |
| 110 | n | 126 | ~ |
| 111 | o | 127 | DEL |
我们发现,大写 A 和小写 a 之间,编码刚好差 32 。
总结
首先,我们学习了数据结构的分类,它们主要分为逻辑结构和物理结构。逻辑结构涵盖了集合结构、线性结构、树形结构和图形结构。这些结构帮助我们组织和理解数据。而物理结构则关注数据在计算机内部的存储方式,有顺序存储和链式存储。这些概念很基础但也很重要,因为它们决定了我们如何操作和访问数据。
其次,算法是解决问题的方法。一个好的算法应该具备一些特性,比如输入、输出、有穷性、确定性和可行性。同时,一个好的算法还应该追求正确性、可读性、健壮性、低时间复杂度和低空间复杂度。这些标准帮助我们评估算法的质量和效率。
在学习中,我还了解到了时间复杂度的重要性。时间复杂度描述了算法的运行时间随问题规模增长的趋势。虽然我们通常用大O符号来表示时间复杂度,但需要记住,它是在数据规模足够大时的一种估计。不同算法有不同的时间复杂度,如O(1)、O(logn)、O(n)等。选择合适的算法取决于数据规模,不一定是时间复杂度越低越好,而是要综合考虑。
最后,我还了解到了关于对数的一些有趣的事情。在时间复杂度中,我们常说O(logn),但底数可以是不同的,如2、10、20等。这是因为我们可以用对数换底公式来相互转换。所以,我们通常说“对数复杂度”,而不关心具体底数。
总的来说,学习数据结构和算法是编程世界中的基本功,它们帮助我们更好地理解问题、设计高效的解决方案。通过了解逻辑结构、物理结构、算法特性、时间复杂度和对数的相关知识,为后面的数据结构与算法打下了基础。希望我的学习感想和总结也能对你有所帮助!
参考资料:
【1】https://github.com/datawhalechina/leetcode-note
【2】代码随想录"算法性能分析"章节,学习地址https://programmercarl.com/前序/关于时间复杂度,你不知道的都在这里!.html
【3】https://algo.itcharge.cn/00.Introduction/01.Data-Structures-Algorithms/