今天Franpper在使用YOLOv8进行目标追踪时产生了一个报错:torch.cuda.OutOfMemoryError: CUDA out of memory
以往遇到CUDA out of memory基本都是在训练过程中由于Batch Size设置得过大导致显存不够引起的,今天却是在预测的过程中报了这个错误,按照以往的经验使用模型预测的时候占用的显存应该不会很大,按理说不会产生这个错误,所以Franpper感到很奇怪,然后尝试查了下问题并解决。
先介绍一下报错的情况与问题分析:
主要任务是使用YOLOv8对视频中的目标进行分割与追踪,接口调用如下:
from ultralytics import YOLO
weigth_path = r"weigth_path "
video_path = r"video_path "
model = YOLO(weigth_path)
results = model.track(source=video_path, save=True, stream=False, persist=True)执行结果如下,在追踪到195帧的时候显存爆了
video 1/1 (195/396) G:\work\test\7.mp4: 640x384, 71.0ms
Traceback (most recent call last):
File"F:pythonProject/ultralytics/ultralytics/trackers/utils/tracker_test.py", line 13, in <module>
results = model.track(frame_number=1, source=vedio_path, save=True, stream=False, persist=True)
File "F:pythonProject\ultralytics\ultralytics\engine\model.py", line 300, in track
return self.predict(source=source, stream=stream, **kwargs)
File "E:\Anaconda3\envs\physterm\lib\site-packages\torch\utils\_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "F:pythonProject\ultralytics\ultralytics\engine\model.py", line 269, in predict
return self.predictor.predict_cli(source=source) if is_cli else self.predictor(source=source, stream=stream)
File "F:pythonProject\ultralytics\ultralytics\engine\predictor.py", line 202, in __call__
return list(self.stream_inference(source, model, *args, **kwargs)) # merge list of Result into one
File "E:\Anaconda3\envs\physterm\lib\site-packages\torch\utils\_contextlib.py", line 56, in generator_context
response = gen.send(request)
File "F:pythonProject\ultralytics\ultralytics\engine\predictor.py", line 277, in stream_inference
s += self.write_results(i, self.results, (p, im, im0))
File "F:pythonProject\ultralytics\ultralytics\engine\predictor.py", line 182, in write_results
self.plotted_img = result.plot(**plot_args)
File "F:pythonProject\ultralytics\ultralytics\engine\results.py", line 250, in plot
annotator.masks(pred_masks.data, colors=[colors(x, True) for x in idx], im_gpu=im_gpu)
File "F:pythonProject\ultralytics\ultralytics\utils\plotting.py", line 156, in masks
masks_color = masks * (colors * alpha) # shape(n,h,w,3)
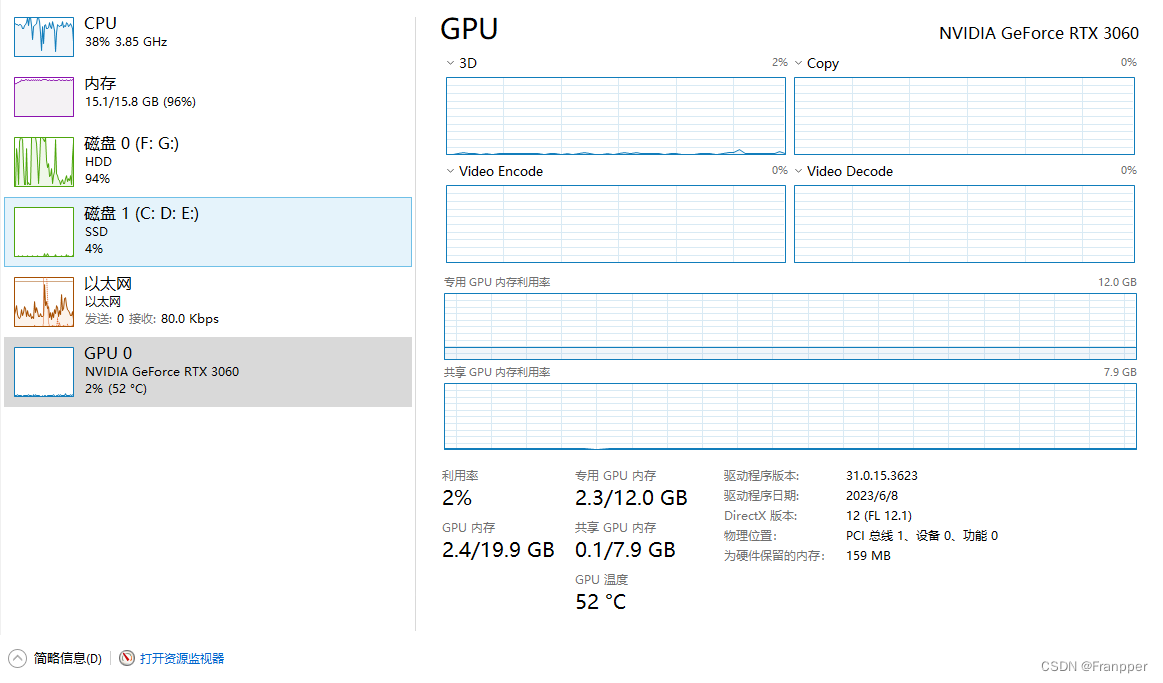
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 280.00 MiB (GPU 0; 12.00 GiB total capacity; 16.77 GiB already allocated; 0 bytes free; 17.51 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF显存的使用情况如下图所示
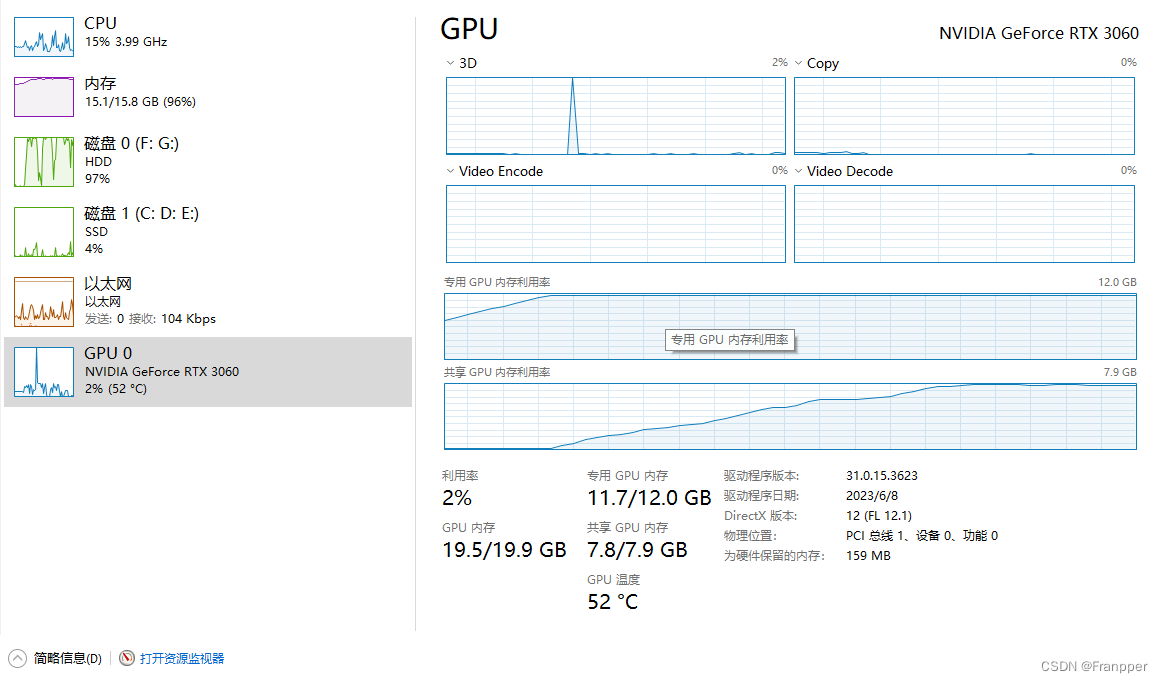
然后Franpper又做了几次测试:400帧的视频在12G显存的电脑会爆显存,但是在24G显存的电脑上可以检测完毕;600帧的视频在24G显存的电脑上会爆显存,但是可以在48G显存的电脑上执行完毕。随着视频帧数的增加,即使是48G显存的电脑在追踪任务中也会出现爆显存的结果。
根据随着检测视频帧数的增加显存占用也逐渐增加的现象,可以推断出在检测的过程中有一些数据不断保存在GPU中,导致显存占用持续上升。
然后Franpper就开始Debug,找啊找,在predict.py中定位到了问题,文件路径如下图,因为Franpper用的是分割,所以在segment文件夹的下面。

扫描二维码关注公众号,回复:
16838611 查看本文章

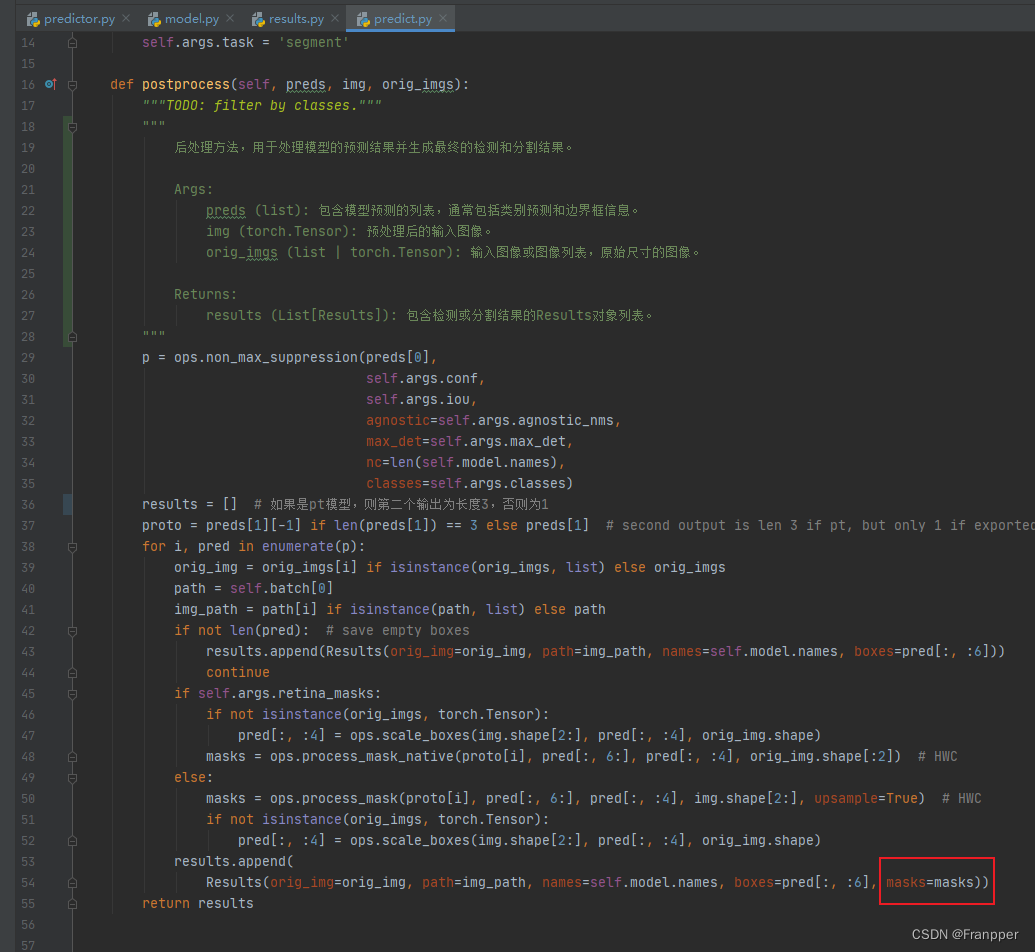
然后将这行代码
results.append(
Results(orig_img=orig_img, path=img_path, names=self.model.names,
boxes=pred[:, :6], masks=masks))改为:
results.append(
Results(orig_img=orig_img, path=img_path, names=self.model.names,
boxes=pred[:, :6], masks=masks.cpu()))如下图所示:

更改之后再执行就可以正常运行啦!
video 1/1 (396/396) G:\work\test.mp4: 640x384 , 72.0ms
Speed: 1.9ms preprocess, 51.9ms inference, 42.6ms postprocess per image at shape (1, 3, 640, 384)
Results saved to F:pythonProject\ultralytics\runs\segment\track66
396 labels saved to F:pythonProject\ultralytics\runs\segment\track66\labels
Process finished with exit code 0此时GPU的状态如下: