文章目录
1.下载安装
pip install bs4
2.导入
from bs4 import BeautifulSoup as bs
3.装载HTML文档
soup = bs(doc, 'lxml')
#doc是一个HTML文档字符串,可以自动补全 lxml是指定该文档的解析方式 python自带的解析器是parser
4.将文档数转换成字符串格式
soup.prettify()
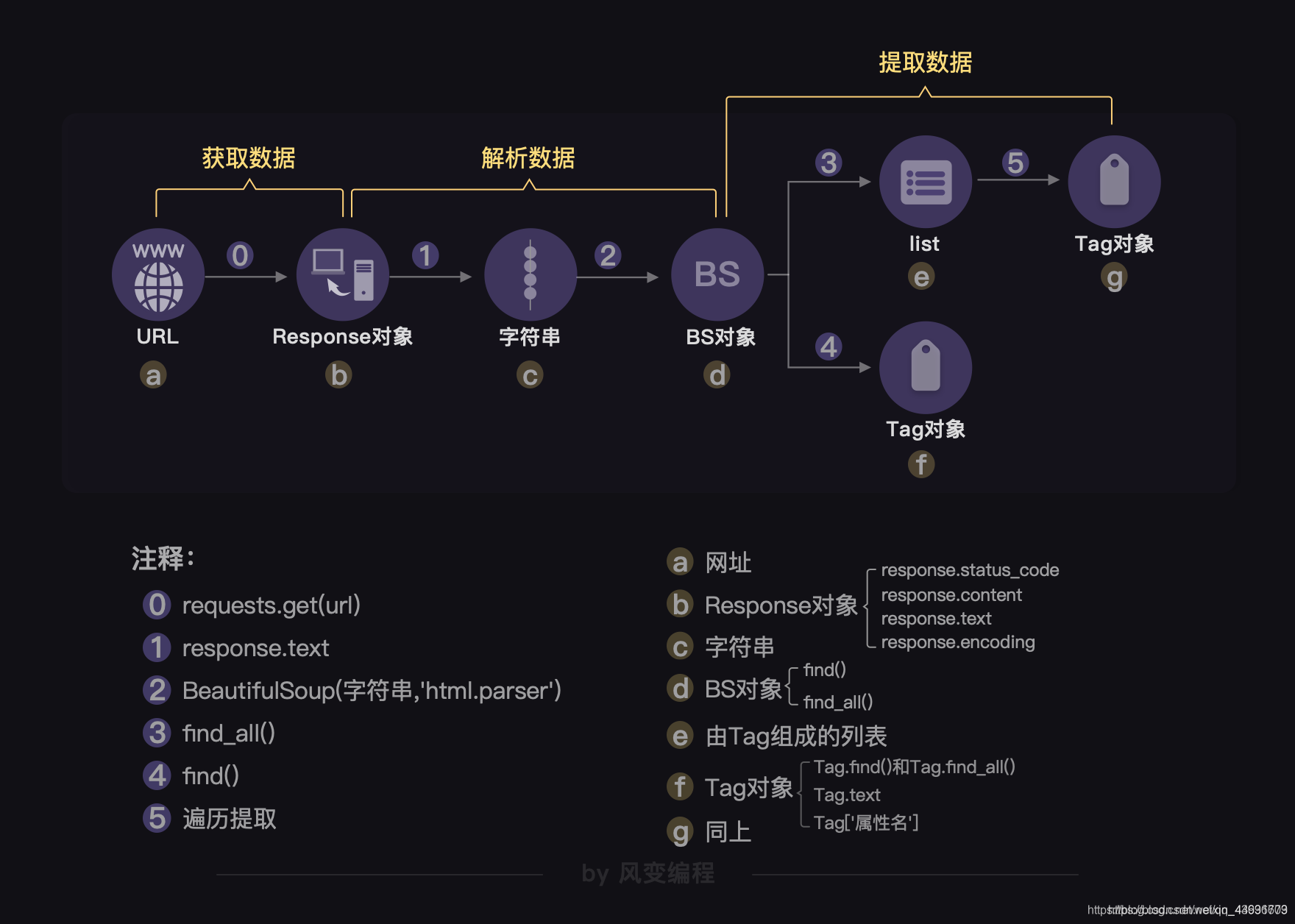
5.BeautifulSoup查找文档元素
(1)find() 查找一个元素节点,返回第一个满足要求的节点信息
(2)find_all()
find_all(self, name=None, attrs={
}, recursive=True, text=None, limit=None, **kwargs)
self表明它是一个类成员函数;name是要查找的标签元素名称;attrs表示元素的属性,一个字典;recursive是默认True,全范围查找该节点下面的子树;…
(3)返回的都是列表,每个元素都是一个bs4.element.Tag对象
(4)获取包含的文本值:tag.text
6.BeautifulSoup遍历文档树
tag.parent:获取tag节点的父节点
tag.children:获取tag节点的所有子节点,包括element,text等类型的子节点
tag.desendants:获取tag节点的所有子孙节点,包括element,text等类型的子节点
tag.next_sibling:tag临近的下一个兄弟节点
tag.previous_sibling:tag临近的前一个兄弟节点
7.BeautifulSoup使用css语法查找元素
(1)tag.select(css):tag是HTML文档中的一个元素节点
css一般结构:[tagName][attName][=value] 全是可选的,表示元素名称,元素属性,元素属性的值
(2)属性的语法:
[attName]选取带有指定属性的每个元素
[attName=value]选取带有指定属性和值的每个元素
[aattName^=value]:匹配属性值以value开头的每个元素
[attName$=value]:匹配属性值以value结尾的每个元素
[attName*=value]:匹配属性值包含value的每个元素
(3)遍历:
css有多个节点时,空格分开:
soup.select("div p"):查找div节点下所有子孙p节点的信息
soup.select("div > p"):查找div节点下所有直接子节点p的信息
soup.select("div ~ p"):查找div后面所有同级别兄弟节点p的信息
soup.select("div + p"):查找前一个节点后面所有同级别兄弟节点的信息
9.字符编码问题
import urllib.request
from bs4 import BeautifulSoup as bs
from bs4 import UnicodeDammit
data = urllib.request.urlopen(url)
data=data.read()
dammit = UnicodeDammit(data,['gbk','utf-8'])
data = dammit.unicode_markup
soup = bs(data,'lxml')
tags = soup.select("div[class='属性值'] span.....")
for tag in tags:
print(tag)
8.实例:爬取中国天气网数据兰州7天的

import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Mobile Safari/537.36'
}
allUrl="http://www.weather.com.cn/weather/101160101.shtml"
response = requests.get(url=allUrl,headers = headers)
response.encoding="utf-8"
html = response.text
soup = BeautifulSoup(html, "html.parser")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(date, weather, temp)
except Exception as err:
print(err)
》》》》》》有个问题,超出索引 我没找到错 大佬找到了帮忙说一下
list index out of range
25日(明天) 阴转多云 15℃/6℃
26日(后天) 晴 19℃/8℃
27日(周二) 多云 18℃/6℃
28日(周三) 多云转晴 19℃/7℃
29日(周四) 晴 21℃/7℃
30日(周五) 晴转多云 30℃/12℃
Process finished with exit code 0