BeautifulSoup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式
解析器
对网页进行析取时,若未规定解析器,此时使用的是python内部默认的解析器“html.parser”。
解析器是什么呢? BeautifulSoup做的工作就是对html标签进行解释和分类,不同的解析器对相同html标签会做出不同解释。
举个官方文档上的例子:
BeautifulSoup("<a></p>", "lxml")
# <html><body><a></a></body></html>
BeautifulSoup("<a></p>", "html5lib")
# <html><head></head><body><a><p></p></a></body></html>
BeautifulSoup("<a></p>", "html.parser")
# <a></a>
官方文档上多次提到推荐使用"lxml"和"html5lib"解析器,因为默认的"html.parser"自动补全标签的功能很差,经常会出问题。
| Parser | Typical usage | Advantages | Disadvantages |
| Python’s html.parser | BeautifulSoup(markup,"html.parser") |
|
|
| lxml’s HTML parser | BeautifulSoup(markup,"lxml") |
|
|
| lxml’s XML parser | BeautifulSoup(markup,"lxml-xml") BeautifulSoup(markup,"xml") |
|
|
| html5lib | BeautifulSoup(markup,"html5lib") |
|
|
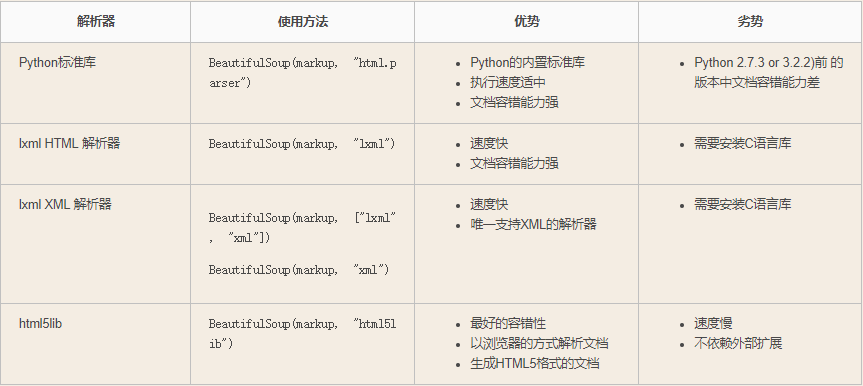
可以看出,“lxml”的解析速度非常快,对错误也有一定的容忍性。“html5lib”对错误的容忍度是最高的,而且一定能解析出合法的html5代码,但速度很慢。
我们在实际爬取网站的时候,原网页的编码方式不统一,其中有一句乱码,用“html.parser”和“lxml”都解析到乱码的那句,后面的所有标签都被忽略了。而“html5lib”能够完美解决这个问题。
安装及基本使用
安装:
#安装 Beautiful Soup pip install beautifulsoup4 #安装解析器 Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml .根据操作系统不同,可以选择下列方法来安装lxml: $ apt-get install Python-lxml $ easy_install lxml $ pip install lxml 另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib: $ apt-get install Python-html5lib $ easy_install html5lib $ pip install html5lib
简单使用:
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ #基本使用:容错处理,文档的容错能力指的是在html代码不完整的情况下,使用该模块可以识别该错误。使用BeautifulSoup解析上述代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出 from bs4 import BeautifulSoup soup=BeautifulSoup(html_doc,'lxml') #具有容错功能 res=soup.prettify() #处理好缩进,结构化显示 print(res)
各种api详解
- 1. name,标签名称
import requests
from bs4 import BeautifulSoup
ret = requests.get(url="https://www.autohome.com.cn/news/")
soup = BeautifulSoup(ret.text, 'lxml')
print(type(soup))
# <class 'bs4.BeautifulSoup'>
tag = soup.find('a')
name = tag.name # 获取
print("=" * 120)
print(tag)
# <a class="orangelink" href="//www.autohome.com.cn/beijing/cheshi/" target="_blank"><i class="topbar-icon topbar-icon16 topbar-icon16-building"></i>进入北京车市</a>
print(type(tag))
# <class 'bs4.element.Tag'>
print("=" * 120)
print(name) # a
tag.name = 'span' # 设置,将标签设置为span
print(soup) # a标签已经被修改成了span标签
# <html>....<span class="orangelink" href="//www.autohome.com.cn/beijing/cheshi/" target="_blank"><i class="topbar-icon topbar-icon16 topbar-icon16-building"></i>进入北京车市</span>....</html>
soup类型为BeautifulSoup,tag类型为bs4.element.tag,下面是tag的一些属性
- 2. attr,标签属性
tag = soup.find('a')
attrs = tag.attrs # 获取
print(tag)
# <a class="orangelink" href="//www.autohome.com.cn/beijing/cheshi/" target="_blank">
print(attrs)
# {'target': '_blank', 'href': '//www.autohome.com.cn/beijing/cheshi/', 'class': ['orangelink']}
tag.attrs = {'ik': 123} # 设置
tag.attrs['id'] = 'iiiii' # 添加
print(soup.find("a"))
# <a id="iiiii" ik="123">
- 2.5 contents 获取标签内所有内容
body = soup.find('body')
v = body.contents
- 3. children,所有子标签
# body = soup.find('body')
# v = body.children
- 4. descendants,所有子子孙孙标签
# body = soup.find('body')
# v = body.descendants
- 4.5 parent 父节点
body = soup.find('a')
v = body.parent
- 4.6 parents 获取所有祖先节点
body = soup.find('a')
v = body.parents
print(v)
# <generator object parents at 0x000001E1225C4E60>
是迭代器,要遍历输出
- 5. clear,将标签的所有子标签全部清空(保留标签名)
# tag = soup.find('body')
# tag.clear()
# print(soup)
- 6. decompose,递归的删除所有的标签
# body = soup.find('body')
# body.decompose()
# print(soup)
- 7. extract,递归的删除所有的标签,并获取删除的标签
# body = soup.find('body')
# v = body.extract()
# print(soup)
- 8. decode,转换为字符串(含当前标签);decode_contents(不含当前标签)
# body = soup.find('body')
# v = body.decode()
# v = body.decode_contents()
# print(v)
- 9. encode,转换为字节(含当前标签);encode_contents(不含当前标签)
# body = soup.find('body')
# v = body.encode()
# v = body.encode_contents()
# print(v)
- 10. find,获取匹配的第一个标签
# tag = soup.find('a')
# print(tag)
# tag = soup.find(name='a', attrs={'class': 'sister'}, recursive=True, text='Lacie')
# tag = soup.find(name='a', class_='sister', recursive=True, text='Lacie')
# print(tag)
- 11. find_all,获取匹配的所有标签
# tags = soup.find_all('a')
# print(tags)
# tags = soup.find_all('a',limit=1)
# print(tags)
# tags = soup.find_all(name='a', attrs={'class': 'sister'}, recursive=True, text='Lacie')
# # tags = soup.find(name='a', class_='sister', recursive=True, text='Lacie')
# print(tags)
# ####### 列表 #######
# v = soup.find_all(name=['a','div'])
# print(v)
# v = soup.find_all(class_=['sister0', 'sister'])
# print(v)
# v = soup.find_all(text=['Tillie'])
# print(v, type(v[0]))
# v = soup.find_all(id=['link1','link2'])
# print(v)
# v = soup.find_all(href=['link1','link2'])
# print(v)
# ####### 正则 #######
import re
# rep = re.compile('p')
# rep = re.compile('^p')
# v = soup.find_all(name=rep)
# print(v)
# rep = re.compile('sister.*')
# v = soup.find_all(class_=rep)
# print(v)
# rep = re.compile('http://www.oldboy.com/static/.*')
# v = soup.find_all(href=rep)
# print(v)
# ####### 方法筛选 #######
# def func(tag):
# return tag.has_attr('class') and tag.has_attr('id')
# v = soup.find_all(name=func)
# print(v)
# ## get,获取标签属性
# tag = soup.find('a')
# v = tag.get('id')
# print(v)
- 12. has_attr,检查标签是否具有该属性
# tag = soup.find('a')
# v = tag.has_attr('id')
# print(v)
- 13. get_text,获取标签内部文本内容
# tag = soup.find('a')
# v = tag.get_text('id')
# print(v)
- 14. index,检查标签在某标签中的索引位置
# tag = soup.find('body')
# v = tag.index(tag.find('div'))
# print(v)
# tag = soup.find('body')
# for i,v in enumerate(tag):
# print(i,v)
- 15. is_empty_element,是否是空标签(是否可以是空)或者自闭合标签,
判断是否是如下标签:'br' , 'hr', 'input', 'img', 'meta','spacer', 'link', 'frame', 'base'
# tag = soup.find('br')
# v = tag.is_empty_element
# print(v)
- 16. 兄弟节点,当前的关联标签
# soup.next # soup.next_element # soup.next_elements # soup.next_sibling # soup.next_siblings # # tag.previous # tag.previous_element # tag.previous_elements # tag.previous_sibling # tag.previous_siblings # # tag.parent # tag.parents
- 17. 查找某标签的关联标签
# tag.find_next(...) # tag.find_all_next(...) # tag.find_next_sibling(...) # tag.find_next_siblings(...) # tag.find_previous(...) # tag.find_all_previous(...) # tag.find_previous_sibling(...) # tag.find_previous_siblings(...) # tag.find_parent(...) # tag.find_parents(...) # 参数同find_all
- 18. select,select_one, CSS选择器
soup.select("title")
soup.select("p nth-of-type(3)")
soup.select("body a")
soup.select("html head title")
tag = soup.select("span,a")
soup.select("head > title")
soup.select("p > a")
soup.select("p > a:nth-of-type(2)")
soup.select("p > #link1")
soup.select("body > a")
soup.select("#link1 ~ .sister")
soup.select("#link1 + .sister")
soup.select(".sister")
soup.select("[class~=sister]")
soup.select("#link1")
soup.select("a#link2")
soup.select('a[href]')
soup.select('a[href="http://example.com/elsie"]')
soup.select('a[href^="http://example.com/"]')
soup.select('a[href$="tillie"]')
soup.select('a[href*=".com/el"]')
from bs4.element import Tag
def default_candidate_generator(tag):
for child in tag.descendants:
if not isinstance(child, Tag):
continue
if not child.has_attr('href'):
continue
yield child
tags = soup.find('body').select("a", _candidate_generator=default_candidate_generator)
print(type(tags), tags)
from bs4.element import Tag
def default_candidate_generator(tag):
for child in tag.descendants:
if not isinstance(child, Tag):
continue
if not child.has_attr('href'):
continue
yield child
tags = soup.find('body').select("a", _candidate_generator=default_candidate_generator, limit=1)
print(type(tags), tags)
- 19. 标签的内容(str)
# tag = soup.find('span')
# print(tag.string) # 获取
# tag.string = 'new content' # 设置
# print(soup)
# tag = soup.find('body')
# print(tag.string)
# tag.string = 'xxx'
# print(soup)
# tag = soup.find('body')
# v = tag.stripped_strings # 递归内部获取所有标签的文本
# print(v)
- 20.append在当前标签内部追加一个标签
# tag = soup.find('body')
# tag.append(soup.find('a'))
# print(soup)
#
# from bs4.element import Tag
# obj = Tag(name='i',attrs={'id': 'it'})
# obj.string = '我是一个新来的'
# tag = soup.find('body')
# tag.append(obj)
# print(soup)
- 21.insert在当前标签内部指定位置插入一个标签
# from bs4.element import Tag
# obj = Tag(name='i', attrs={'id': 'it'})
# obj.string = '我是一个新来的'
# tag = soup.find('body')
# tag.insert(2, obj)
# print(soup)
- 22. insert_after,insert_before 在当前标签后面或前面插入
# from bs4.element import Tag
# obj = Tag(name='i', attrs={'id': 'it'})
# obj.string = '我是一个新来的'
# tag = soup.find('body')
# # tag.insert_before(obj)
# tag.insert_after(obj)
# print(soup)
- 23. replace_with 在当前标签替换为指定标签
# from bs4.element import Tag
# obj = Tag(name='i', attrs={'id': 'it'})
# obj.string = '我是一个新来的'
# tag = soup.find('div')
# tag.replace_with(obj)
# print(soup)
- 24. 创建标签之间的关系
# tag = soup.find('div')
# a = soup.find('a')
# tag.setup(previous_sibling=a)
# print(tag.previous_sibling)
- 25. wrap,将指定标签把当前标签包裹起来
# from bs4.element import Tag
# obj1 = Tag(name='div', attrs={'id': 'it'})
# obj1.string = '我是一个新来的'
#
# tag = soup.find('a')
# v = tag.wrap(obj1)
# print(soup)
# tag = soup.find('a')
# v = tag.wrap(soup.find('p'))
# print(soup)
- 26. unwrap,去掉当前标签,将保留其包裹的标签
# tag = soup.find('a')
# v = tag.unwrap()
# print(soup)
111