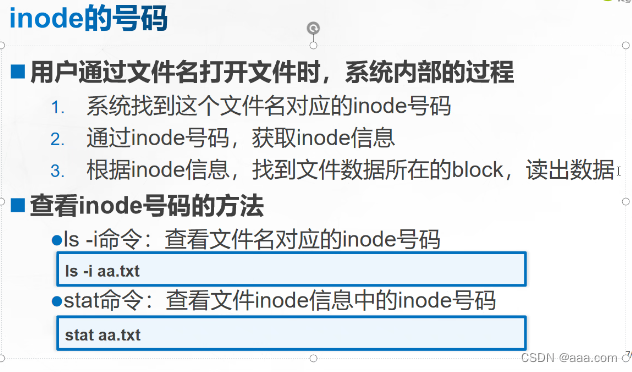
inode和block概述

核心:备份
文件数据包:存储的文件(图片,视频,文本)
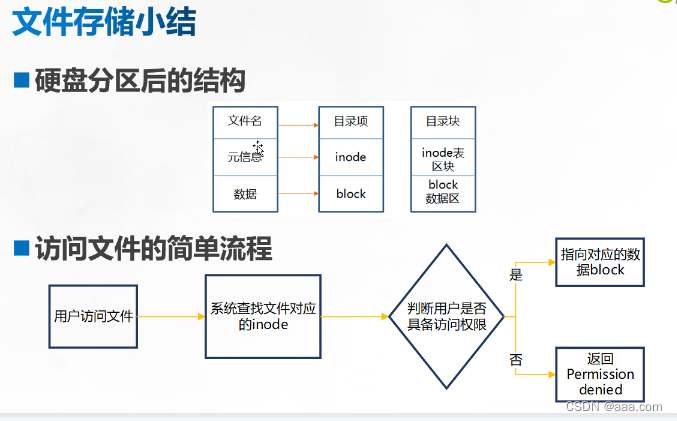
Linux存储的两种机制:inode号 block(最小为4K,不满4K也占一个)
1.文件会生成一个inode号
2.文件必然会占用存储空间 block(连续八个扇区组成一个block)
inode号:元信息(即windows 中文件的属性)
存储的元信息内容:文件的创建者,更改日期,文件的大小,文件的权限
跟随inode号标识,存储在硬盘上的。
一般inode号占用的空间为512K左右。128字节-256字节
inode号用完了(少见但不绝对),即使磁盘还有空间也无法创建数据(磁盘配额的原理)
一个文件必须占用一个inode号,至少占一个块。
文件必须有inode号。
Linux一切皆文件,目录也是文件。
Linux内部怎么来识别文件:通过inode号识别。
对于系统来说,文件名只是inode号的别称,方便用户使用,文件名和inode号一一对应。系统通过inode号识别文件。
文件的元信息中,不包括文件名称(只看inode号)
模拟:
zzr写内容的过程:
zzr--------inode号------到硬盘上打开这个文件------(检索文件的元信息,用户是否有权限访问文件,用户有没有写的权限。)------写入123------保存(检索元信息,用户能不能在当前目录写入,更改元信息,文件的inode号会发生变化。)
stat:
atime:访问这个文件就会改变这个时间
mtime:修改文件数据内容,就会更新 find 面试题
find /opt/ -mtime +10 -size +10G -type f -exec rm -rf {} \;
ctime:修改文件的权限或者属性,更改文件内容也可能会变(change time)
文件名和inode号剥离之后:
1.文件名包含特殊字符,可能无法正常删除,这时可以通过inode号,直接找到数据所在块,直接删除。
2.移动,重命名,不影响inode号
3.一旦打开文件之后,系统全部以inode号识别文件,文件名不再考虑。
4.vim编辑器修改文件内容之后,可能会生成一个新的inode 号
5.文件名不在元信息当中
find /opt/ -inum inode号码 -exec rm -rf {} \;
如果乱码文件无法删除,可以用inode号删除
文件恢复
xfs文件系统进行备份和恢复文件:
centos7默认使用xfs文件系统,
xfsdump的备份是有级别的, 0表示全量,1-9表示增量备份。
xfsdump的命令格式和选项:
-f指定备份文件的目录
-L指定目录标签
-l:指定备份级别
-M:指定设备标签
-s:备份单个文件,后面不能直接跟路径。
xfsdump -f 备份文件的存放位置 要备份的路径和设备。[指定标签]
xfsdump使用是有限制的:
1.只能恢复已挂载的文件系统设备。
2.只能备份xfs文件系统。
3.必须要有root权限。
4.数据恢复只能通过xfsrestore解析,进行恢复。
5.两个设备的UUID相同,不能进行备份。
数据要先备份,才能恢复
xfsdump:备份磁盘数据
xfsrestore:恢复数据
-f /opt/backup backup必须是个文件,不能是目录,而且必须是一个没有的文件,执行后会自动生成他
/dev/sdb1
[-L 指向/backup -M sdb1]
xfsdump -l 1 /opt/backup1 /dev/sdb1 [-L backup1 -M sdb1] 增量备份(最多到9),备份的文件的文件名不能重复。
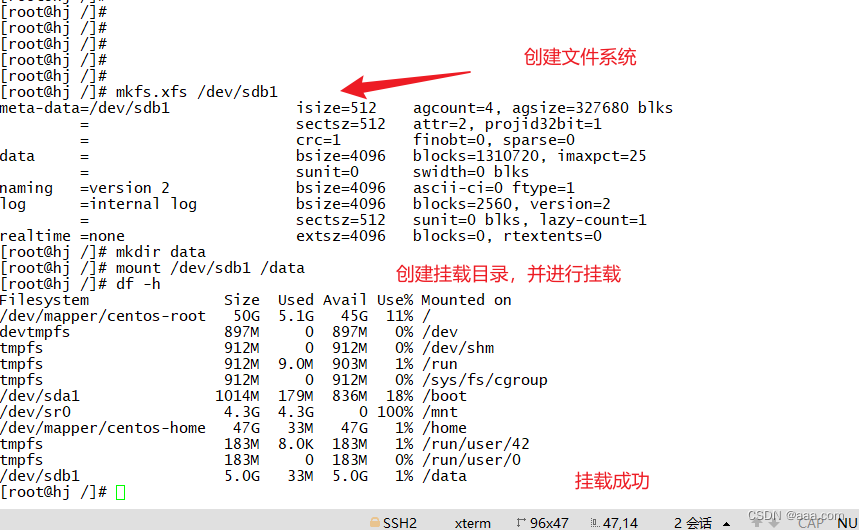
以下是实验过程


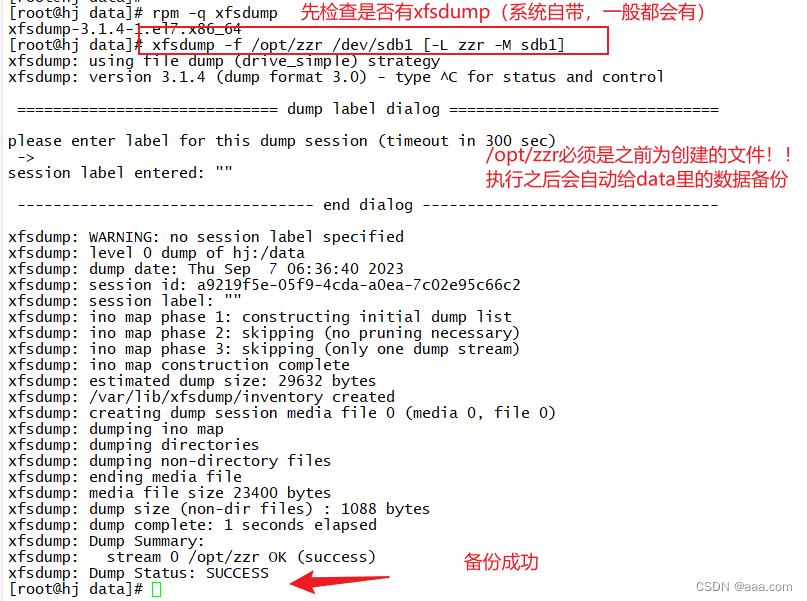

实验成功