1. 基本概念
整数在存储单元中都是以补码形式存储的,存储单元中的第 1 个二进制位代表符号。整型变量的值的范围包括负数到正数。 但是在实际应用中,有的数据的范围常常只有正值(如学号、年龄等),为了充分利用变量的值的范围,可以将变量定义为“无符号”类型。可以在类型符号前面加上修饰符 unsigned ,表示指定该变量是“无符号整数”类型。如果加上修饰符 signed,则是“有符号”类型。如果不加任何的修饰符,默认就是有符号数。例如 int 与 signed int 等价
有符号整型数据存储单元中最高位代表数值的符号,如果指定为无符号型,存储单元中全部二进制位都用作存放数值本身,而没有符号。无符号变量只能存放没有符号的整数,不能存放负数,如 -123 等。由于无符号整型变量不用符号位,所以可表示数值的范围是一般整型变量中的两倍。下面表格中展示了各种无符号整型的数值表示范围
| 无符号整型 | 可表示的范围 |
|---|---|
| unsigned char | 0~(28-1) |
| unsigned int | 0~(232-1) |
| unsigned short | 0~(216-1) |
| unsigned long | 0~(232-1) |
| unsigned long long | 0~(264-1) |
2. 引例
首先来看两段程序
程序 1
#include <stdio.h>
int main()
{
unsigned char a = 255;
char b = 255;
printf("%d %u\n",a,a);
printf("%d %u\n",b,b);
return 0;
}
程序 2
#include <stdio.h>
int main()
{
unsigned char a = -1;
char b = -1;
printf("%d %u\n",a,a);
printf("%d %u\n",b,b);
return 0;
}
这两段程序的运行结果是一样的,如下图所示:
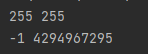
下面将会详细分析这两段程序
2. 分析过程
2.1 程序 1
我们观察程序 1 的定义部分:
unsigned char a = 255;
char b = 255;
这里定义了两个变量无符号字符 a 和有符号字符 b,并且同时赋予了初值 255,我们需要注意的是使用 unsigned char 的数据范围是0~255,而 char 的数据范围是 -128~127,255 对于 char 来说已经超出了他的范围,255 (这里其实我也不是很清楚,到底有没有符号位,如果有符号位那就是 9 位,但是最高位为 0 所以发生截断也只存储了8位下来,如果没有符号位那就正好是存储了 8 位)对应的补码为:1111 1111,下面我们来看看它在内存中的存储情况
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
|---|---|---|---|---|---|---|---|---|
| unsigned char | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 |
| char | 符号位 | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 |
这就是 255 存储在不同变量中的内存情况,可以看到实际存储的二进制是一样的
我们再来查看一下输出的部分
printf("%d %u\n",a,a);
printf("%d %u\n",b,b);
这两行是分别将变量 a、b 先以有符号整数的形式输出,然后再以无符号整数的形式输出
对于变量 a 来说,255 的存储是正常的,所以可以正常的输出两个 255,这从结果上来看也是如此
对于变量 b 来说,255 的存储是异常的,准确来说发生了溢出。在使用有符号整数的形式输出时等于 -1,而使用无符号整数的形式输出时等于 4294967295,那么为什么会输出这两个奇怪的数字呢?
根据 C 语言的规范,发生溢出时,对于有符号类型的溢出,结果是未定义的。因此,编译器的行为在这种情况下是不确定的。
首先来看有符号整数的形式输出时,255 存储在内存的二进制为:1111 1111,以符号整数的形式输出时最高位识别为符号位,也即是负数,后面的数值位采用的是补码形式表示,换为原码后就是表示的十进制的 1,连起来就是 -1
在使用 %u 格式化符号打印 b 时,它将被解释为一个很大的无符号整数,以 32 位系统为例,等于 4294967295,而 4294967295 实际上就是 232-1,而将 b 赋值为 254,就会输出 232-2,他们存在着一一对应的关系
2.2 程序 2
我们观察程序 2 的定义部分:
unsigned char a = -1;
char b = -1;
这里定义了两个变量无符号字符 a 和有符号字符 b,并且同时赋予了初值 -1,我们需要注意的是使用 unsigned char 的数据范围是0~255,而 char 的数据范围是 -128~127,-1 对于 unsigned char 来说已经超出了他的范围,-1 (最高位为符号位)对应的补码为:1111 1111,下面我们来看看它在内存中的存储情况
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
|---|---|---|---|---|---|---|---|---|
| unsigned char | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 |
| char | 符号位 | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 | 数值位 |
这就是 -1 存储在不同变量中的内存情况,可以看到实际存储的二进制是一样的
我们再来查看一下输出的部分
printf("%d %u\n",a,a);
printf("%d %u\n",b,b);
这两行是分别将变量 a、b 先以有符号整数的形式输出,然后再以无符号整数的形式输出
对于变量 a 来说,-1 的存储是不正常的,但是由于存储的二进制是 1111 1111 于是无论是使用 %d 还是 %u 输出它都被解释为无符号整数 255
对于变量 b 来说,-1 的存储是正常的,但是使用无符号整数的形式输出时却等于 4294967295,这实际上是发生了溢出。
使用无符号整数的形式打印有符号的负整数时,它被解释为一个很大的无符号整数,以 32 位系统为例,等于 4294967295,而 4294967295 实际上就是 232-1,如果给 b 赋值为 -2,那么打印出的值就是 232-2,他们存在着一一对应的关系
3. 总结
下面以有 char 的有无符号来做总结,可以 char 的有无符号可以表示的范围可以分为下面三个部分:

其中 signed char 可以表示范围为 ①+②,unsigned char ②+③
设
char a = x;
这里 x 为常数,我们来对 x 的范围和对应的输出进行讨论
| 数据类型 | x属于的范围 | 输出格式 | 输出结果 |
|---|---|---|---|
| signed char | ①② | %d | 正确 |
| signed char | ③ | %d | x-28 |
| signed char | ① | %u | 溢出,输出结果为232+x |
| signed char | ② | %u | 正确 |
| signed char | ③ | %u | 溢出,输出结果为232+(x-28) |
| unsigned char | ① | %d | x+28 |
| unsigned char | ②③ | %d | 正确 |
| unsigned char | ① | %u | x+28 |
| unsigned char | ②③ | %u | 正确 |
可以看到如果数据范围在 ② 中的时候,都可以正确的输出正确的值,但是在 ① 或者 ③ 时,就只有特定的数据类型配合特定的输出格式才可以得到正确的值了,在实际开发的时候应该根据数据的范围来选择合适的数据类型以及符号特性。char 只有 1 字节,其他的整型数据都是大同小异的只不过占有更多的字节,相信大家可以举一反三去探究其他的整型的符号特性