BP神经网络
BP神经网络是指误差逆传播算法训练的多层前馈网络。
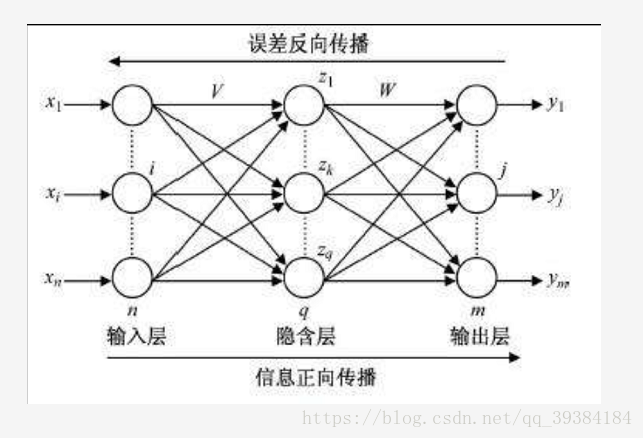
如下图为两层两层的BP神经网络(只有隐含层和输出层是参与计算和权值调整的节点层)。
注:本文中用到的Python及其模块安装教程参见
结构和原理
在“单细胞”的神经网络里,实际上只有一层,即最后的输出层。在上图中有两层,第一层每个节点的输入都是一样的,都是
x1,x2,x3……xn
。每个节点的超平面都可以用
g(v)=wv+b
来表示。但是,所有的节点最后输出的函数只有1或0两个状态,所以有激活函数为Logistic函数:
f(v)=11+e−(wTv+b)
f(v)=11+e−(wTv+b)
这个函数其实是
f(t)=11+e−t
和
t=wTv+b
这两个函数组合变量代换形成的。
t=wTv+b
在之前的人工神经网络中已经介绍过。
f(t)=11+e−t
的图形如下图所示。
- 图2:
f(t)=11+e−t
的图形
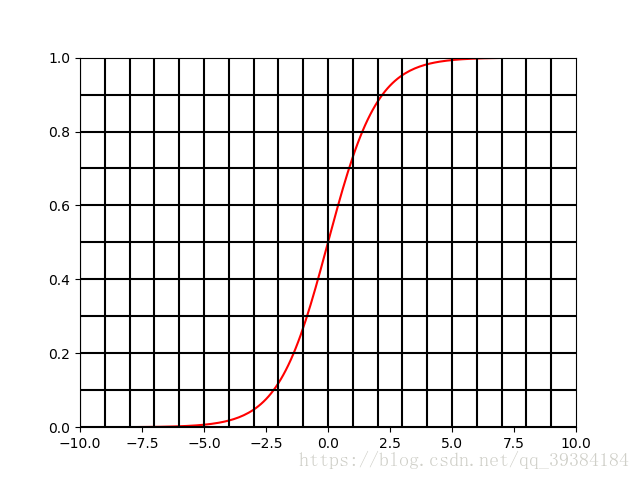
在t大于某个值时,函数值就是1,t小于某个值时,函数值就是0。
也可以写成以下的形式:
f(t)=11+e−mt
其中m是可以调整的参数,m越小曲线越平缓,m越大曲线越立陡,分类边界越明显。具体在每个应用中怎么取m的值要依情况而定,如果需要边界区分非常明显,那就把m的值设置地大一些。例如,m=10时,函数图形如下图。
- 图3:
f(t)=11+e−10t
的图形
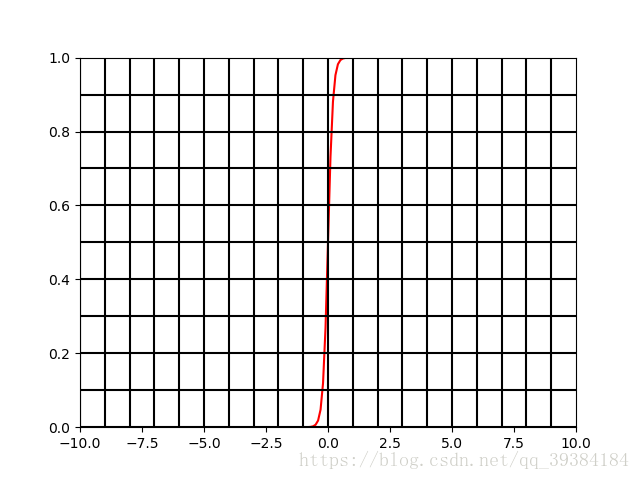
所以对于
f(v)=11+e−(wTv+b)
函数来说,函数会根据v的输入对应产生1和0两种函数值,而这里面待定的就是w这个矩阵,这就是在网络训练中需要决定的。而每个节点都有函数
f(v)=11+e−(wTv+b)
,而且每个节点之间都可能完全不一样。从上面的两层的BP神经网络的图可以看出,前面一层的输出结果作为后面一层节点的输入,最后一层的输出是n个不同的1或0,也就是说这个神经网络最多可以标识
2n
种不同的分类。
训练过程
这里希望找到一种方法可以让设置好的各个权值能够匹配尽可能多的训练样本的分类情况,和线性回归中希望残差尽量小的思路一致。使用最小二乘法,最小二乘法的思路是,如果把误差表示成样本做自变量的函数,然后用求极值的方法来推导就可以找出这个误差最小情况下的各个系数值了。
隐含层节点的输入为:
hi=wihxi+bh
。
隐含层节点的输出为:
ho=f(hi)
。
输出层节点的输入为:
yi=who+bo
。
输出层节点的输出为:
yo=f(yi)
。
注意,这里面的
xi,wih,who,ho,yo
都是向量。
误差函数为:
Ei=doi−yoi
整个网络误差函数为:
E=12∑ni=1Ei=12∑ni=1(doi−yoi)2
这个函数前面的系数
12
只是为了之后求导方便,不影响函数的性质。
对这个误差函数进行求导求偏微分。
输出层误差偏微分:
∂E∂who=∂Eyi∂yi∂who
其中
∂E∂yi=∂12∑ni=1(doi−yoi)212∑ni=1(doi−yoi)2yi
=−(doi−yoi)f‘(yi)=−δo
∂yi∂who=∂(whoho+bo)∂who=ho
那么
∂E∂who=∂Eyi∂yi∂who=−δoho
误差的梯度
δo=−(doi−yoi)f‘(yi)
隐含层误差偏微分:
∂E∂wih=∂E∂hi∂hi∂wih
其中
∂E∂hi=∂12∑ni=1(doi−yoi)2∂ho∂ho∂hi
=∂12∑ni=1(doi−f(yi))2∂ho∂ho∂hi
=∂12∑ni=1(doi−f(whoho+bo))2∂h0∂ho∂hi
=−(doi−yoi)f‘(yi)who∂ho∂hi
=−δowhof‘(hi)
=−δh
∂hi∂wih=∂(wihxi+bh)∂wih=xi
那么
∂E∂wih=−δhxi
误差的梯度
δh=(δowho)f‘(hi)
(三)权值更新。
隐含层更新:
wN+1ih=wNih+ηδhxi
输出层更新:
wN+1ho=wNho+ηδoho
过程解释
首先设置两套w作为两层网络各自的“超平面”的系数,然后输入一次完整的训练过程,就会有一个误差值出现。
接着就是一次一次地进行w的调整。调整的方法是,首先用最小二乘法的方式,找到一个误差和自变量的关系,然后求误差极值。
在最后的
wN+1ih=wNih+ηδhxi
和
wN+1ho=wNho+ηδoho
这两个公式里,用的是试探性的方法。
+ηδhxi
和
+ηδoho
是一种试探的“步长”,第一次分别设置了
wih
和
who
,如果有误差,就试着往误差小的一边“走一步”,这就是一次一次迭代的目的。最后找到一个误差满足要求的点,把这一点的
wih
和
who
都记录保存下来,网络就训练完毕了。这种步长试探的思路也叫梯度下降法。
想了解更多关于大数据和机器学习:大数据与机器学习专栏