C++线程库

文章目录
线程的创建
- 调用无参的构造函数
thread() noexcept;
#include<iostream>
#include<thread>
using namespace std;
int main()
{
thread t1;
return 0;
}
- thread提供无参构造,创建出来的线程对象没有关联任何的线程函数,即没有启动任何线程。而在Linux中创建线程须调用
pthread_create函数,并需要传参线程执行的函数和该函数需要的参数等参数,即程序运行时会启动线程。
- 调用带参的构造函数
template <class Fn, class... Args>
explicit thread (Fn&& fn, Args&&... args);
-
fn是可调用对象,可以是函数指针、lambda表达式、函数对象。
-
Args是线程调用对象所需要若干个参数。
-
注意该带参的构造函数用explicit关键字修饰,即该带参的构造函数不支持隐式类型转换。
#include<iostream>
#include<thread>
using namespace std;
void Add(int left, int right)
{
cout << left + right << endl;
}
int main()
{
int x = 10;
int y = 20;
thread t1(Add,x,y);
t1.join();
return 0;
}
- 把Add函数和整型x、y变量传参給t1线程,当程序运行起来,t1线程会调用Add函数,并把x,y作为参数按顺序传递給left,right。
- 线程禁用拷贝函数
-
禁用拷贝函数的作用在于禁止拷贝构造和拷贝赋值,防止多个线程对同一个线程对象进行复制操作,从而避免潜在的并发、数据不一致问题。其作用主要表现为以下:
-
防止不同线程共享相同的线程对象:如果允许线程对象被复制,那么不同的线程可能会共享相同的线程状态,导致无法确定线程的行为。这可能导致竞态条件和数据竞争等并发问题。、
-
强制显式管理线程对象的生命周期:禁用拷贝函数迫使程序员显式地管理线程对象的生命周期。这可以确保线程的创建、销毁和使用都是明确的,减少了出现资源泄漏或线程泄漏的可能性。
-
提高线程安全性:禁用拷贝函数有助于提高线程安全性,因为不同线程之间不会意外地共享线程对象的状态。这有助于减少并发编程中的错误和难以调试的问题。
-
- 允许使用移动构造函数来构造线程对象
thread (thread&& x) noexcept;
通过使用 std::move 将线程对象从一个地方移到另一个地方,可以避免拷贝线程对象,同时确保线程对象的生命周期正确管理。
#include<iostream>
#include<thread>
using namespace std;
void Add(int left, int right)
{
cout << left + right << endl;
}
int main()
{
int x = 10;
int y = 20;
thread t1=thread(Add,x,y);
t1.join();
return 0;
}
- 使用带参构造创建一个匿名的线程对象,然后通过移动赋值构造t1对象,匿名对象所管理的资源移动給t1对象管理,且延长了线程对象的生命周期。
#include<iostream>
#include<thread>
using namespace std;
void Add(int left, int right)
{
cout <<"left+right: " << left + right << endl;
}
class ADD
{
public:
int operator()()
{
int x = 20, y = 10;
return x + y;
}
};
int main()
{
int x = 10;
int y = 20;
thread t1(Add,x,y);//可调用对象为函数指针
thread t2([x, y] {
cout <<"x+y: " << x + y << endl; });//可调用对象为lambda表达式
ADD dd;
thread t3(dd);//可调用对象为函数对象
t1.join();
t2.join();
t3.join();
return 0;
}
- ADD类只含有一个仿函数operator(),说明该类可以像函数一样使用,在main函数中创建了一个ADD对象dd,把函数对象dd作为可调用对象传递給线程t3
thread提供的成员函数
thread中常用的成员函数如下:
| 成员函数 | 功能 |
|---|---|
| join | 对该线程进行等待,在等待的线程返回之前,调用join函数的线程将会被阻塞 |
| joinable | 判断该线程是否已经执行完毕,如果是则返回true,否则返回false |
| detach | 将该线程与创建线程进行分离,被分离后的线程不再需要创建线程调用join函数对其进行等待 |
| get_id | 获取该线程的id |
| swap | 将两个线程对象关联线程的状态进行交换 |
另外,joinable函数可以判断线程是否有效的,是以下任意情况则线程无效:
- 采用无参构造函数构造的线程对象。
- 线程对象的状态已经转移给其他线程对象。
- 线程已经调用join或者detach结束。
get_id
- 通过线程对象来调用thread的成员函数get_id来获取线程id。
- 如果是在线程对象所关联的线程函数中,可以通过调用this_thread命名空间的get_id函数来获取线程id。
void func()
{
cout <<"this_thread::get_id: " << this_thread::get_id() << endl;
}
int main()
{
thread t1(func);
cout << "t1 id: "<<t1.get_id() << endl;
t1.join();
return 0;
}
this_thread命名空间
为了能在线程函数中更好的调用线程的成员函数,库中将几个常用的成员函数包装在this_thread命名空间中。可以在线程所关联的线程函数中通过this_thread::xxx调用。
this_thread命名空间内的成员函数有:
| get_id | 获取该线程的id |
|---|---|
| yield | 让出当前线程的执行权,允许系统将执行时间片分配给其他可运行的线程 |
| sleep_until | 让当前线程休眠到一个具体时间点 |
| sleep_for | 让当前线程休眠一个时间段 |
说明一下:
yield函数作用包括:
- 放弃当前线程的执行权。
yield()函数会主动放弃当前线程的执行权,告诉操作系统该线程愿意将剩余时间片让给其他线程。这样做可以提高系统的多线程并发性能,避免某个线程长时间占用 CPU 资源而导致其他线程被延迟调度的问题。 - 控制线程的执行优先级。通过使用
yield()函数,您可以以某种方式控制线程的执行优先级。当一个线程通过yield()放弃执行权时,操作系统可以按照一定的调度算法重新选择下一个要运行的线程。 - yield函数只是一个对线程调度的建议,操作系统不一定会按照您的要求进行调度。具体的行为可能受到操作系统和硬件平台的影响。即并不能确保下一个获得执行权的线程一定是其他线程,也有可能是之前的同一个线程继续执行。
- 在某些情况下,
yield()可能会导致线程的性能下降,因为线程需要频繁放弃和重新获得执行权。 yield()函数通常用于无锁操作,当当前线程需要切换到另一个线程时,可以调用yield令当前线程放弃时间片,切换上下文,让步給另一个线程占用CPU。
yield让当前线程让步CPU时间片,让其他线程占用CPU,通常用于无锁操作。
总结一下:
- 线程是操作系统中的一个概念,线程对象可以关联一个线程,用来控制线程以及获取线程的状态。
- 如果创建线程对象时没有提供线程函数,那么该线程对象实际没有对应任何线程。
- 如果创建线程对象时提供了线程函数,那么就会启动一个线程来执行这个线程函数,该线程与主线程一起运行。
- thread类是防拷贝的,不允许拷贝构造和拷贝赋值,但是可以移动构造和移动赋值,可以将一个线程对象关联线程的状态转移给其他线程对象,并且转移期间不影响线程的执行。
线程的回收策略
启动一个线程后,该线程会占用一些资源,当这个线程退出时,需要将线程所占用的资源进行回收,否则会导致内存泄漏问题。因此thread库就为我们两种回收线程资源的策略。
join
主线程创建新线程后,需要调用
join函数回收新线程,主线程会阻塞在join函数处,直到新线程退出,主线程回收新线程资源成功。
- 因此主线程调用
join函数回收完新线程相关资源后,该新线程对象和刚被销毁的栈帧就没有关系了,因此对同一个线程只能join一次,否则程序会崩溃。
void func()
{
cout << "this_thread::get_id: " << this_thread::get_id() << endl;
}
int main()
{
thread t1(func);
cout << "t1 id: " << t1.get_id() << endl;
t1.join();
t1.join();
return 0;
}
- 但如果一个线程对象
join后,又调用移动赋值函数,将一个右值线程对象的关联线程的状态转移过来了,那么这个线程对象又可以调用一次join。
void func()
{
cout << "this_thread::get_id: " << this_thread::get_id() << endl;
}
int main()
{
thread t1(func);
cout << "t1 id: " << t1.get_id() << endl;
t1.join();
t1 = thread(func);
t1.join();
return 0;
}
- 当采用
join方法回收线程资源时,可能会出现在join之前因为抛异常或其他原因退出当前栈帧而导致join失败。
void func()
{
cout << "this_thread::get_id: " << this_thread::get_id() << endl;
}
int main()
{
thread t1(func);
cout << "t1 id: " << t1.get_id() << endl;
if (3 != 0)
{
return -1;//退出当前栈帧
}
t1.join();
return 0;
}
因此可以采用RAII的方式包装线程对象,利用对象的生命周期控制线程的资源释放,即当退出当前栈帧时自动调用join方法释放线程资源。
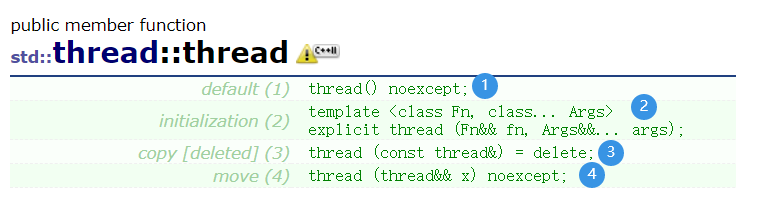
class mythread
{
public:
mythread(thread& t):_t(t)
{
cout << "thread id: " << _t.get_id() << endl;
}
~mythread()
{
cout << "thread id: " << _t.get_id() << " join success" << endl;
_t.join();
}
mythread(mythread const&) = delete;
mythread& operator=(const mythread&) = delete;
private:
thread& _t;
};
void func()
{
cout << "this_thread::get_id: " << this_thread::get_id() << endl;
}
int main()
{
thread t1(func);
mythread tt(t1);
return 0;
}
detach
主线程创建新线程后,也可以调用
detach函数将新线程与主线程进行分离,分离后新线程会在后台运行,其所有权和控制权将会交给C++运行库,此时C++运行库会保证当线程退出时,其相关资源能够被正确回收。
- 使用
detach的方式回收线程的资源,一般在线程对象创建好之后就立即调用detach函数。避免在调用detach之前因为某些原因退出当前栈帧导致线程分离失败,从而导致程序崩溃。
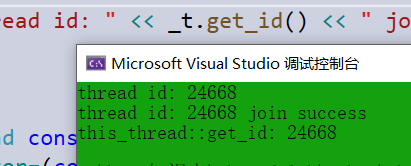
线程函数参数
线程函数的参数是以值拷贝的方式拷贝到线程栈空间中的,因此:即使线程参数为引用类型,在 线程中修改后也不能修改外部实参,因为其实际引用的是线程栈中的拷贝,而不是外部实参。
void ADD(int& num)
{
num = num + 1;
}
int main()
{
int num = 10;
thread t1(ADD,num);
t1.join();
cout << "after num: " << num << endl;//10 not 11
return 0;
}
如果要通过线程函数的形参改变外部的实参,可以参考以下三种方式:
- 当想要线程函数的形参引用的是外部传进来的实参时,借助std::ref函数保持对实参的引用特性。
void ADD(int& num)
{
num = num + 1;
}
int main()
{
int num = 10;
thread t1(ADD,ref(num));
t1.join();
cout << "after num: " << num << endl;//11
return 0;
}
- 传入实参的地址,线程函数可以通过该地址拿到实参从而进行修改,进而影响外部的实参。
void ADD(int* num)
{
*num = *num + 1;
}
int main()
{
int num = 10;
thread t1(ADD,&num);
t1.join();
cout << "after num: " << num << endl;//11
return 0;
}
- 借助lambda表达式,利用lambda表达式的捕捉列表捕捉外部实参的引用,在函数体内对该实参进行修改,进而影响外部的实参。
int main()
{
int num = 10;
thread t1([&num] {
num = num + 1; });
t1.join();
cout << "after num: " << num << endl;//11
return 0;
}
mutex的种类
在C++11中,Mutex总共包了四个互斥量的种类:
-
std::mutex
C++11提供的最基本的互斥量,该类的对象之间不能拷贝,也不能进行移动。mutex最常用的三个函数:函数名 函数功能 lock() 上锁:锁住互斥量,若该互斥量被其他线程所占有,阻塞等待该锁解锁 unlock() 解锁:释放对互斥量的所有权 try_lock() 尝试锁住互斥量,如果该互斥量已经被其他线程所占有,将直接返回 注意一下,当线程函数调用lock()时:
- 如果该互斥量当前没有被锁住,则调用线程将该互斥量锁住,直到调用 unlock之前, 该线程一直拥有该锁。
- 如果当前互斥量被其他线程锁住,则当前的调用线程被阻塞住。
- 如果当前互斥量被当前线程锁住,然后当前现在又通过lock()去申请该互斥量,会导致死锁问题。
注意一下,当线程函数调用try_lock()时:
- 如果当前互斥量没有被其他线程占有,则该线程锁住互斥量,直到该线程调用 unlock 释放互斥量
- 如果当前互斥量被其他线程锁住,则当前调用线程返回 false,而并不会被阻塞掉
- 如果当前互斥量被当前线程锁住,然后当前线程又通过try_lock去申请该互斥量,若申请互斥量失败会立刻返回,不会造成死锁问题。
死锁概念:死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所占用不会释放的资源而处于的一种永久等待状态。换言之,一个线程持有资源不释放,向申请不到的资源进行申请,而申请失败处于阻塞等待状态,那么持有的资源将无法释放或者让别的线程使用,该线程就处于死锁状态。
-
std::recursive_mutex
其允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权, 释放互斥量时需要调用与该锁层次深度相同次数的 unlock()。除此之外, std::recursive_mutex 的特性和 std::mutex 大致相同。
-
std::timed_mutex
比 std::mutex 多了两个成员函数,try_lock_for(),try_lock_until() 。
- try_lock_for()
接受一个时间范围,表示在这一段时间范围之内线程如果没有获得锁则被阻塞住(与 std::mutex 的 try_lock() 不同,try_lock 如果被调用时没有获得锁则直接返回 false),如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。 - try_lock_until()
接受一个时间点作为参数,在指定时间点未到来之前线程如果没有获得锁则被阻塞住, 如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
除此之外,timed_mutex也提供了
lock、try_lock和unlock成员函数,其的特性与mutex大致相同。 - try_lock_for()
-
std::recursive_timed_mutex
recursive_timed_mutex就是recursive_mutex和timed_mutex的结合,recursive_timed_mutex既支持在递归函数中进行加锁操作,也支持定时尝试申请锁。
加锁示例
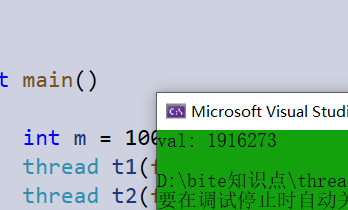
int gval = 0;
void func1(int val)
{
for (int i = 0; i < val; i++)
{
gval++;
}
}
int main()
{
int m = 1000000;
thread t1(func1,m);
thread t2(func1,2*m);
t1.join();
t2.join();
cout << "val: " << gval << endl;
return 0;
}
- 在这个示例中,全局变量gval线程t1和线程t2都能拿到,然后调用同一个函数func对gval进行加加操作。由于没有任何保护措施,会导致程序运行完并不是我们想要的样子。可能当线程t1对gval加加时,线程t2对gval也进行加加操作,那么两个线程对同一个数进行加加后拷贝回去,实际上只对gval加加了一次。
因此需要用互斥量保护临界区。
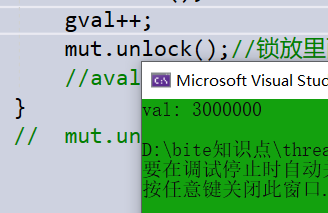
int gval = 0;
mutex mut;
void func1(int val)
{
for (int i = 0; i < val; i++)
{
mut.lock();
gval++;
mut.unlock();//锁放里面相比于锁放外面会多一个是加锁解锁的消耗二个是切换上下文的消耗
}
}
int main()
{
int m = 1000000;
thread t1(func1,m);
thread t2(func1,2*m);
t1.join();
t2.join();
cout << "val: " << gval << endl;
return 0;
}
- 当两个线程运行到
mut.lock()这一行时,两个线程会竞争互斥锁,竞争到的线程能够进入临界区执行相关代码,而竞争失败的线程就阻塞等待。当该互斥锁被持有的线程释放时,该竞争失败的线程才能被唤醒,有机会再次竞争到互斥锁。每次只能有一个线程进入临界区。 - 实际上将加锁解锁操作放在循环里面,相比于放在循环外面,所消耗的资源会更多。将加锁解锁放在循环里面,一是频繁的加锁解锁有消耗,二是抢不到锁的线程要阻塞休眠,切换上下文。这就会导致多个线程频繁的切换上下文,其二是切换上下文的消耗。
int gval = 0;
mutex mut;
void func1(int val)
{
mut.lock();
for (int i = 0; i < val; i++)
{
gval++;
}
mut.unlock();
}
int main()
{
int m = 1000000;
thread t1(func1,m);
thread t2(func1,2*m);
t1.join();
t2.join();
cout << "val: " << gval << endl;
return 0;
}
lock_guard
在使用互斥锁时,有可能存在加锁后,在解锁前因为线程对象的生命周期结束或其他原因导致退出当前栈帧,没有完成解锁。那么会导致其他线程在申请当前锁时阻塞住造成死锁问题,因此可以以RAII的方式包装互斥锁,需要用到锁的地方实例化一个lock_guard对象,调用构造函数成功上锁,出作用域前,lock_guard对象要被销毁,调用析构函数自动解锁,可以有效避免死锁问题。
lock_guard是C++11中的一个模板类,其定义如下:
template <class Mutex>
class lock_guard;
class Lock_guard
{
public:
Lock_guard(mutex& mut):_mut(mut)
{
_mut.lock();
}
~Lock_guard()
{
_mut.unlock();
}
Lock_guard(const Lock_guard&) = delete;
Lock_guard& operator=(const Lock_guard&) = delete;
private:
mutex& _mut;
};
int gval = 0;
mutex mut;
void func1(int val)
{
{
Lock_guard lg(mut);
for (int i = 0; i < val; i++)
{
gval++;
}
}
}
int main()
{
int m = 1000000;
thread t1(func1,m);
thread t2(func1,2*m);
t1.join();
t2.join();
cout << "val: " << gval << endl;
return 0;
}
- lock_guard需要包含一个锁成员变量,该成员变量需要是一个引用类型,在构造函数传参进来一个互斥量mut,用该互斥量来初始化锁成员变量,该成员变量就是lock_guard对象需要维护的互斥锁。
- 需要用到锁的地方实例化一个lock_guard对象,调用构造函数成功上锁。
- 出作用域前,lock_guard对象要被销毁,调用析构函数自动解锁。
- 可以定义一个匿名局部域来控制lock_guard的生命周期,在该局部内的代码都会被lock_guard所保护。
- 需要删除lock_guard的拷贝构造和拷贝赋值,因为lock_guard内的锁成员变量不支持拷贝。
- C++库中也有lock_guard,其用法与上面实现的大同小异
- lock_guard的缺陷:太单一,用户没有办法对该锁进行控制,因此C++11又提供了unique_lock。
unique_lock
- 与lock_gard类似,unique_lock类模板也是采用RAII的方式对锁进行了封装,并且也是以独占所 有权的方式管理mutex对象的上锁和解锁操作,即其对象之间不能发生拷贝。
- 在构造(或移动 (move)赋值)时,unique_lock 对象需要传递一个 Mutex 对象作为它的参数,新创建的 unique_lock 对象负责传入的 Mutex 对象的上锁和解锁操作。
- 使用以上类型互斥量实例化 unique_lock的对象时,自动调用构造函数上锁,unique_lock对象销毁时自动调用析构函数解锁,可以很方便的防止死锁问题。
与lock_guard不同的是,unique_lock更加的灵活,提供了更多的成员函数:
- 上锁/解锁操作:lock、try_lock、try_lock_for、try_lock_until和unlock。
- 修改操作:移动赋值、交换(swap:与另一个unique_lock对象互换所管理的互斥量所有权)、释放(release:返回它所管理的互斥量对象的指针,并释放所有权)。
- 获取属性:owns_lock(返回当前对象是否上了锁)、operator bool()(与owns_lock()的功能相同)、mutex(返回当前unique_lock所管理的互斥量的指针)。
unique_lock其用法和lock_guard相似
mutex mut;
void func()
{
unique_lock<mutex> ul(mut);//调用构造函数加锁
//......
ul.lock();
func1();
//......
ul.unclock();
}//调用析构函数解锁
原子性操作库(atomic)
多线程最主要的问题是共享数据带来的问题(即线程安全)。如果共享数据都是只读的,那么没问题,因为只读操作不会影响到数据,更不会涉及对数据的修改,所以所有线程都会获得同样的数据。但是,当一个或多个线程要修改共享数据时,就会产生很多潜在的麻烦。
int gval = 0;
void func1(int val)
{
for (int i = 0; i < val; i++)
{
gval++;
}
}
int main()
{
int m = 1000000;
thread t1(func1, m);
thread t2(func1, 2 * m);
t1.join();
t2.join();
cout << "val: " << gval << endl;
return 0;
}
- 上面的代码打印出来的结果会出现少于3000000的情况,其根本原因在于对gval的加加操作不是原子性的。
加加操作分为三步:
load:将共享变量gval从内存加载到寄存器中。update:更新寄存器里面的值,执行+1操作。store:将新值从寄存器写回共享变量n的内存地址。
0039310F mov eax,dword ptr [gval (03A03D0h)]
00393114 add eax,1
00393117 mov dword ptr [gval (03A03D0h)],eax
- 在程序运行完时,导致gval的值不是3000000的原因有很多。在单CPU的情况下,线程t1去到内存中拿到gval的数据,放到CPU的寄存器上,刚完成加加操作的第一步,这时候时间片的时间到了。需要将线程t1切换,OS切换t1的上下文。然后t2可能顺利的完成了加加操作,将加加后的值写回到内存中。这时候切回到线程t1,用之前在内存拿到的值继续完成剩下的加加操作。因此两个线程对同一个变量gval各自加加了一次,实际上gval只被加加了一次。
- C++98对于这里出现的线程安全问题,会对共享数据使用加锁保护。
虽然加锁可以解决,但是加锁有一个缺陷就是:只要一个线程在对sum++时,其他线程就会被阻塞,会影响程序运行的效率,而且锁如果控制不好,还容易造成死锁。
因此C++11中引入了原子操作。所谓原子操作:即不可被中断的一个或一系列操作,C++11引入 的原子操作类型,使得线程间数据的同步变得非常高效。以下为原子操作类型的名称及其对应的内置类型名称
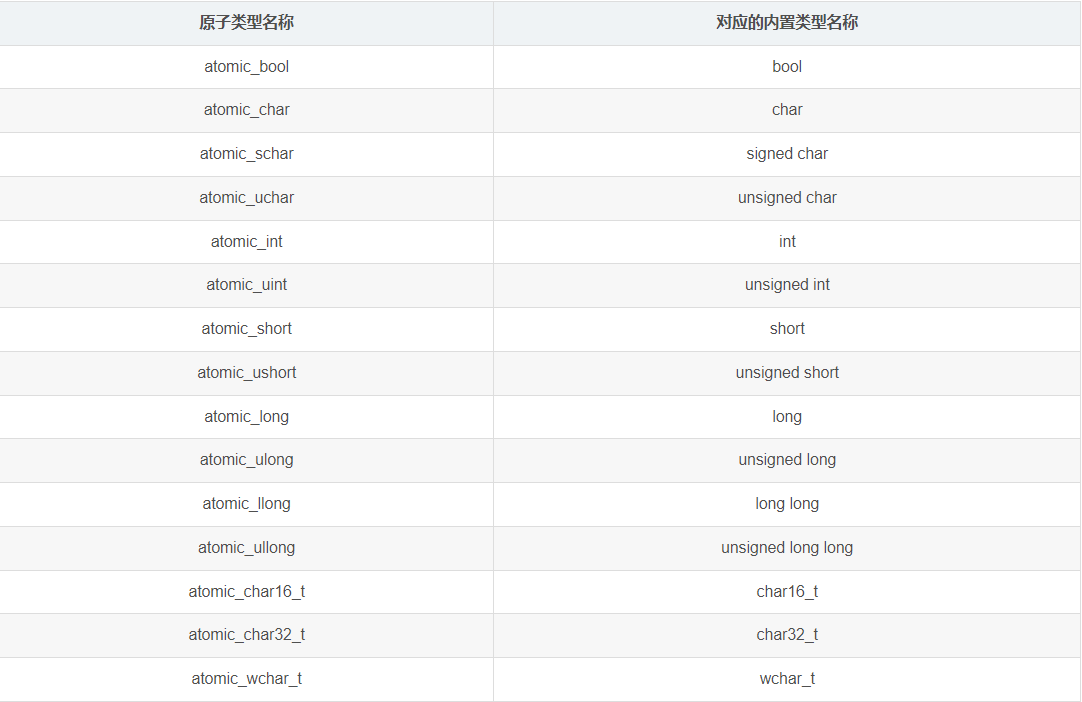
注意:需要使用以上原子操作变量时,必须添加头文件
#include<atomic>
可以通过atomic类模板,定义出对应内置类型的原子类型
atomic<T> t;
//atomic_int gval=0;
atomic<int>gval=0;
void func1(int val)
{
for (int i = 0; i < val; i++)
{
gval++;
}
}
int main()
{
int m = 1000000;
thread t1(func1, m);
thread t2(func1, 2 * m);
t1.join();
t2.join();
cout << "val: " << gval << endl;
return 0;
}
- 在C++11中,不需要对原子类型变量进行加锁解锁操作,线程能够对原子类型变量互斥的访问。
- 原子类型通常属于"资源型"数据,多个线程只能访问单个原子类型的拷贝。因此在C++11 中,原子类型只能从其模板参数中进行构造,不允许原子类型进行拷贝构造、移动构造以及 operator=等。
- 为了防止意外,标准库已经将atmoic模板类中的拷贝构造、移动构造、赋值运算 符重载默认删除掉了。
cas操作
CAS:Compare and Swap,即比较再交换。
例如多个线程对同一个数据进行加加操作,线程将数据放到寄存器中,寄存器保存一份原来的数据,然后放数据到cpu上进行加加,通过比对内存中的数据,当保存的原来的数据与此时内存中的数据相同时,就将加加后的数据放回内存;当保存的原来的数据与此时的内存中的数据不相同时,意味着其他线程已经将改变后的数据放回内存了,那么当前线程就不能将数据放回去了。
cas的缺点:CPU开销大。在并发量比较高的情况下,如果许多线程反复尝试更新某一个值,却又一直更新不成功,循环往复,会给CPU带来很大的压力。
windows和Linux创建进程的区别
在上层调用线程库,通过条件编译区分调用windows线程库还是linux线程库。