redis开发中的常见问题-缓存穿透-缓存雪崩-redis脑裂-缓存击穿
前言
在我们日常的开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题,可是一旦涉及大数据量的需求,比如一些商品抢购的情景,或者是主页访问量瞬间较大的时候,单一使用数据库来保存数据的系统会因为面向磁盘,磁盘读/写速度比较慢的问题而存在严重的性能弊端,一瞬间成千上万的请求到来,需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题。为了克服上述的问题,项目通常会引入NoSQL技术,这是一种基于内存的数据库,并且提供一定的持久化功能。
redis技术就是NoSQL技术中的一种,但是引入redis又有可能出现缓存穿透,缓存雪崩、缓存击穿等问题。本文就对这几种问题进行较深入剖析
一、Redis的缓存穿透
什么是缓存穿透 ?
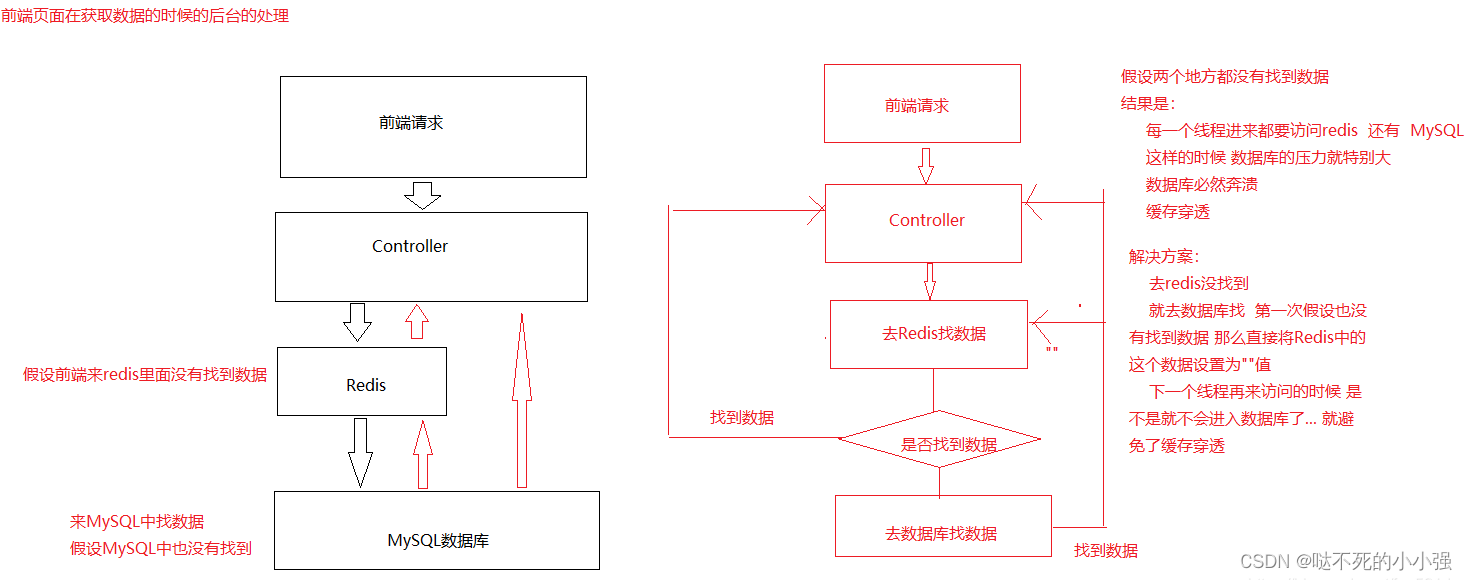
简单的说就是获取数据的时候后 先去redis找数据 结果没找到 又去MySQL中找数据 结果还是没有找到 这样的话 那么 每一个线程进来都要去访问数据库、这样的话数据库的压力就很大 数据库就会奔溃 这种现象就叫做 缓存穿透
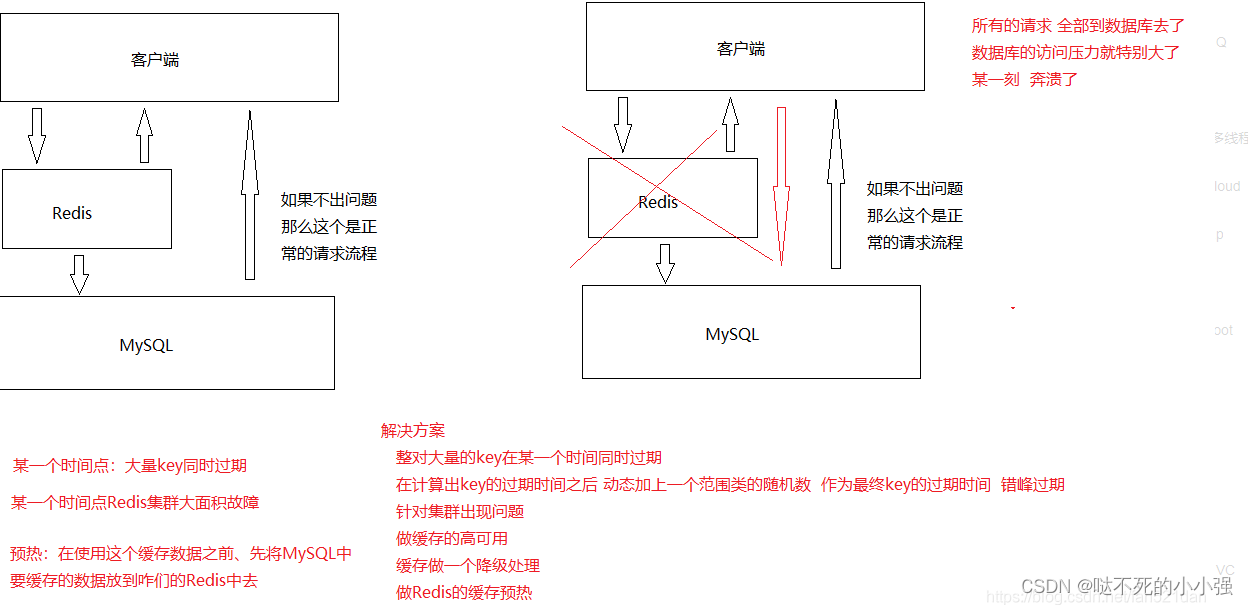
二、Redis下的缓存雪崩
三、Redis的脑裂问题

客户端向主服务器写入了数据 但是主服务器还没有来得及同步的情况下 主服务器死了 那么这个时候就会选举新的主服务器 原来的主服务器在一段时间之后 又好了 那么这个时候 原来的主服务器 只能作为从服务器了 原来主服务器的数据 没有办法进行同步 这种问题 就是redis的脑裂问题
解决方案
min-slaves-to-write 1 这个表示的意思是:在我们客户端写入数据的时候 至少保证 主服务器上有一个从服务器 处于正常连接才能写入这个数据
min-slaves-max-lag 10 :这个表示的的意思是 主从同步的时间 10s
四、缓存击穿
这里需要注意和缓存穿透的区别。缓存击穿,是指一个 key 非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个 key 在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
当某个 key 在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新的数据,并回写缓存,会导致数据库瞬间压力过大。
解决方案:
1、设置热点数据永不过期
从缓存层来看,没有设置过期时间,所以不会出现热点 key 过期后产生的问题。
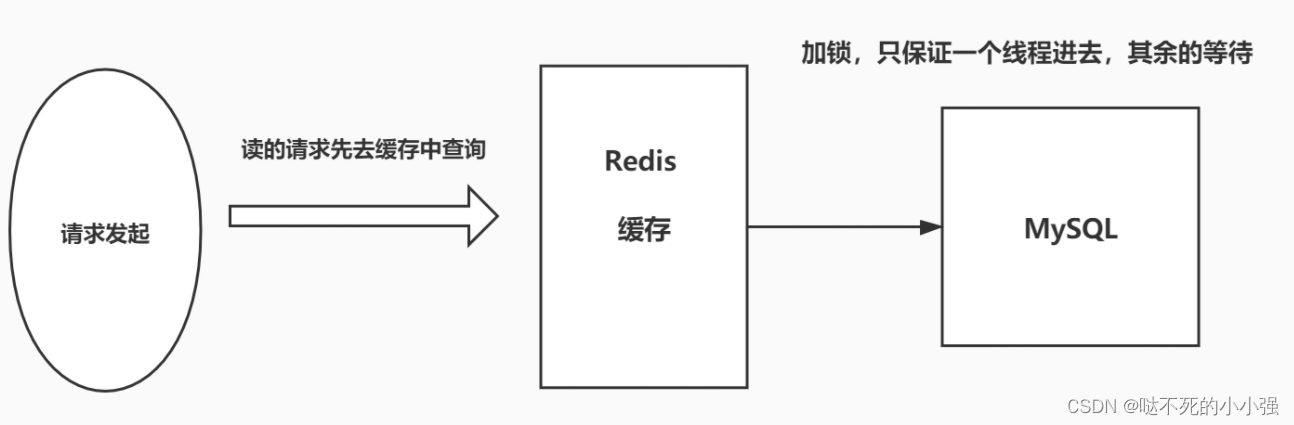
2、加互斥锁
分布式锁:使用分布式锁,保证对于每个 key 同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因对分布式锁的考验很大。
JAVA代码实现
static Lock reenLock = new ReentrantLock();
public String findPubConfigByKey1(String key) throws InterruptedException {
PubConfig result = new PubConfig();
// 从缓存读取数据
result = redisService.getObject(PubConfigKeyConstants.TABLE_NAME + "_"+key, PubConfig.class) ;
if (result== null ) {
if (reenLock.tryLock()) {
try {
System.out.println("拿到锁了,从DB获取数据库后写入缓存");
// 从数据库查询数据
result = pubConfigRepository.queryPubConfigInfoByKey(key);
// 将查询到的数据写入缓存
Gson g = new Gson();
String value = g.toJson(result);
redisService.setNx(PubConfigKeyConstants.TABLE_NAME + "_"+key, value);
} finally {
reenLock.unlock();// 释放锁
}
} else {
// 先查一下缓存
result = redisService.getObject(PubConfigKeyConstants.TABLE_NAME + "_"+key, PubConfig.class) ;
if (result== null) {
System.out.println("我没拿到锁,缓存也没数据,先小憩一下");
Thread.sleep(100);// 小憩一会儿
return findPubConfigByKey1(key);// 重试
}
}
}
return result.getValue();
}
总结
针对业务系统,永远都是具体情况具体分析,没有最好,只有最合适。
于缓存其它问题,缓存满了和数据丢失等问题,大伙可自行学习。最后也提一下三个词LRU、RDB、AOF,通常我们采用LRU策略处理溢出,Redis的RDB和AOF持久化策略来保证一定情况下的数据安全。
原文链接:https://blog.csdn.net/fan521dan/article/details/104782315?spm=1001.2014.3001.5501