RabbitMQ+keepalived+haproxy搭建高可用集群
一、集群简介
1.1 RabbitMQ 集群
通常情况下,在集群中我们把每一个服务称之为一个节点,在 RabbitMQ 集群中,节点类型可以分为两种:
- 内存节点:元数据存放于内存中。为了重启后能同步数据,内存节点会将磁盘节点的地址存放于磁盘之中,除此之外,如果消息被持久化了也会存放于磁盘之中,因为内存节点读写速度快,一般客户端会连接内存节点。
- 磁盘节点:元数据存放于磁盘中(默认节点类型),需要保证至少一个磁盘节点,否则一旦宕机,无法恢复数据,从而也就无法达到集群的高可用目的。
PS:元数据,指的是包括队列名字属性、交换机的类型名字属性、绑定信息、vhost等基础信息,不包括队列中的消息数据。
RabbitMQ 中的集群主要有两种模式:普通集群模式和镜像队列模式。
普通集群模式
在普通集群模式下,集群中各个节点之间只会相互同步元数据,也就是说,消息数据不会被同步。那么问题就来了,假如我们连接到 A 节点,但是消息又存储在 B 节点又怎么办呢?
不论是生产者还是消费者,假如连接到的节点上没有存储队列数据,那么内部会将其转发到存储队列数据的节点上进行存储。虽然说内部可以实现转发,但是因为消息仅仅只是存储在一个节点,那么假如这节点挂了,消息是不是就没有了?因此这种普通集群模式并没有达到高可用的目的。
镜像队列模式(本次选择)
普通集群模式下不同节点之间只会相互同步元数据(交换机、队列、绑定关系、vhost的定义)而不会同步消息。例如,队列 1 的消息只存储在节点 1 上,节点 2 和节点 3只 同步了交换机和队列的元数据,但是没有同步消息。
假如生产者连接的是节点 3,要将消息通过交换机A路由到队列 1,最终消息还是会转发到节点 1 上存储;同理如果消费者连接的是节点 2,要从队列 1 上拉取消息,最终消息会从节点1转发到节点 2,其它节点起到一个路由的作用;如果节点1挂掉,则队列 1 的全部数据就会丢失。
镜像队列模式下,节点之间不仅仅会同步元数据,消息内容也会在镜像节点间同步,可用性更高。这种方案提升可用性的同时,也会因为同步数据带来的网络开销从而在一定程度上影响到性能。
1.2 集群架构
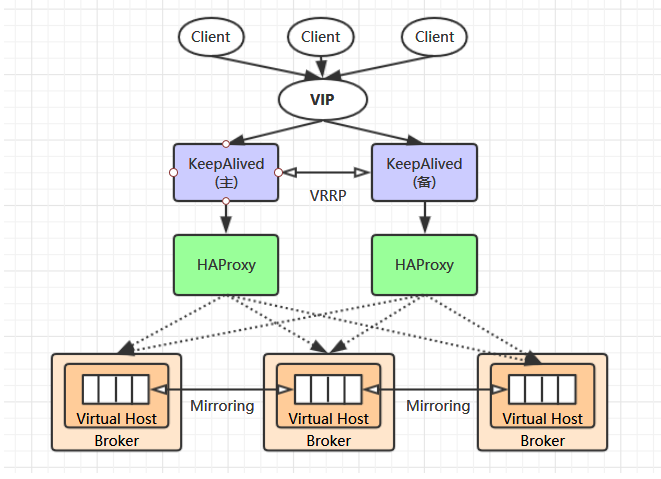
假如一个 RabbitMQ 集群中,有多个内存节点,我们应该连接到哪一个节点呢?这个选择的策略如果放在客户端做,那么会有很大的弊端,最严重的的就是每次扩展集群都要修改客户端代码,所以这种方式并不是很可取,所以我们在部署集群的时候就需要一个中间代理组件,这个组件要能够实现服务监控和转发,比如 Redis 中的 Sentinel(哨兵)集群模式,哨兵就可以监听 Redis 节点并实现故障转移。
在 RabbitMQ 集群中,通过 Keepalived 和 HAProxy 两个组件实现了集群的高可用性和负载均衡功能。
HAProxy
HAProxy 是一个开源的、高性能的负载均衡软件,同样可以作为负载均衡软件的还有 nginx,lvs 等。 HAproxy 支持 7 层负载均衡和 4 层负载均衡。
具体使用参考:HAProxy的安装和配置详解
Keepalived
为了实现 HAProxy 的高可用,需要再引入一个 Keepalived 组件,Keepalived 组件主要有以下特性:
- 具有负载功能,可监控集群中的节点状态,如果集群中某一个节点宕机,可以实现故障转移。
- 其本身也可以实现集群,但是只能有一个 master 节点。
- master 节点会对外提供一个虚拟 IP,应用端只需要连接这一个 IP 就行了。可以理解为集群中的 HAProxy 节点会同时争抢这个虚拟 IP,哪个节点争抢到,就由哪个节点来提供服务。
VRRP 协议
VRRP 协议即虚拟路由冗余协议(Virtual Router Redundancy Protocol)。Keepalived 中提供的虚拟 IP 机制就属于 VRRP,它是为了避免路由器出现单点故障的一种容错协议。
具体使用参考:搭建keepalived+nginx热备高可用(主备+双主模式)
负载均衡的 RabbitMQ 集群架构应类似下图:
二、RabbitMQ 集群搭建
RabbitMQ普通集群模式
2.1 环境准备
| IP地址 | 主机名 | 备注 |
|---|---|---|
| 192.168.92.100 | mq01 | 磁盘节点 RabbitMQ |
| 192.168.92.101 | mq02 | 内存节点 keepalived+haproxy+RabbitMQ |
| 192.168.92.110 | mq03 | 内存节点 keepalived+haproxy+RabbitMQ |
2.2 host配置
-
修改主机名 为mq01,其他两台分别修改为mq02、mq03
vim /etc/hostname mq01 #修改完重启并生效 reboot -
配置 hosts
配置三个服务器节点的 /etc/hosts 文件:添加节点名和节点IP的映射关系vim /etc/hosts #注意不能带.注意-主机名称也要更改 192.168.92.100 mq01 192.168.92.101 mq02 192.168.92.110 mq03重启网络
service network restart 测试是否能够互相 ping 通。
2.3 rabbitmq 集群搭建
-
yum安装rabbitmq
yum install -y epel-release yum install -y rabbitmq-server -
拷贝erlang.cookie
Rabbitmq的集群是依附于erlang的集群来工作的,所以必须先构建起erlang的集群景象。Erlang的集群中各节点是经由过程一个magic cookie来实现的,这个cookie存放在/var/lib/rabbitmq/.erlang.cookie中,文件是400的权限。所以必须保证各节点cookie一致,不然节点之间就无法通信
我们首先在mq01上启动单机版RabbitMQ,以生成Cookie文件:systemctl start rabbitmq-server #文件中实际就是字符串 [root@mq01 rabbitmq]# cat /var/lib/rabbitmq/.erlang.cookie KVUEFJJZLEXGPOEBXQKO用scp的方式将mq01节点的.erlang.cookie的值复制到其他两个节点中
scp /var/lib/rabbitmq/.erlang.cookie [email protected]:/var/lib/rabbitmq/.erlang.cookie scp /var/lib/rabbitmq/.erlang.cookie [email protected]:/var/lib/rabbitmq/.erlang.cookie由于你可能在三台主机上使用不同的账户进行操作,为避免后面出现权限不足的问题,这里建议将 cookie 文件原来的 400 权限改为 777,命令如下:
chmod 777 /var/lib/rabbitmq/.erlang.cookie -
分别查看三个节点并添加管理服务,最后启动rabbitmq服务
RabbitMQ提供了一个非常友好的图形化监控页面插件(rabbitmq_management),让我们可以一目了然看见Rabbit的状态或集群状态#查看插件安装情况 /usr/lib/rabbitmq/bin/rabbitmq-plugins list #启用rabbitmq_management服务 /usr/lib/rabbitmq/bin/rabbitmq-plugins enable rabbitmq_management / #启动服务 rabbitmq-server -detached启动错误解决
在创建rabbitmq集群时,需要将当前节点的.erlang.cookie文件数据修改为第一个节点的.erlang.cookie文件内容,这里为了防止手动vim修改导致数据末尾的自动换行符的引入,我使用了文件的直接替换,随后在重启当前的mq节点服务时,报错如下:[root@net-test-leel ~]# systemctl restart rabbitmq-server Redirecting to /bin/systemctl restart rabbitmq-server.service Job for rabbitmq-server.service failed because the control process exited with error code. See "systemctl status rabbitmq-server.service" and "journalctl -xe" for details. [error] Cookie file /var/lib/rabbitmq/.erlang.cookie must be accessible by owner only问题解决
报错的内容是权限问题,当前这个文件只能文件的所有者才能访问,因为这个文件是从其他节点上复制并替换的,所以需要重新赋予权限,在rabbitmq的默认安装路径/var/lib/rabbitmq/下执行如下命令,cd /var/lib/rabbitmq/ sudo chown rabbitmq:rabbitmq .erlang.cookie sudo chmod 400 .erlang.cookie随后,问题解决,可以正常启动mq了
-
查看监听端口
netstat -ntap | grep 5672 -
RabbitMQ 集群的搭建需要选择其中任意一个节点为基准,将其它节点逐步加入。这里我们以 mq01为基准节点,将 mq02和 mq03加入集群。
在 mq02 和 mq03上执行以下命令:# 1.停止服务 rabbitmqctl stop_app # 2.重置状态(可选) rabbitmqctl reset # 3.节点加入 rabbitmqctl join_cluster --ram rabbit@mq01 # 4.启动服务 rabbitmqctl start_app
说明:
a. 默认rabbitmq启动后是磁盘节点,在这个cluster命令下,mq02和mq03是内存节点,mq01是磁盘节点。
b. 如果要使mq02、mq03都是磁盘节点,去掉–ram参数即可。
c. 如果想要更改节点类型,可以使用命令rabbitmqctl change_cluster_node_type disc(ram),前提是必须停掉rabbit应用 -
查看集群状态
rabbitmqctl cluster_status
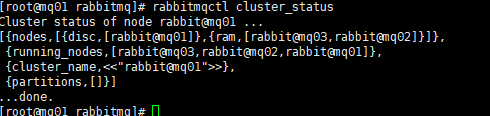
可以看到 nodes 下显示了全部节点的信息,其中 mq01上的节点都是 disc 类型,即磁盘节点;而 mq02、mq03上的节点为 ram,即内存节点。此时代表集群已经搭建成功,默认的 cluster_name 名字为 rabbit@mq01,如果你想进行修改,可以使用以下命令:
rabbitmqctl set_cluster_name my_rabbitmq_cluster -
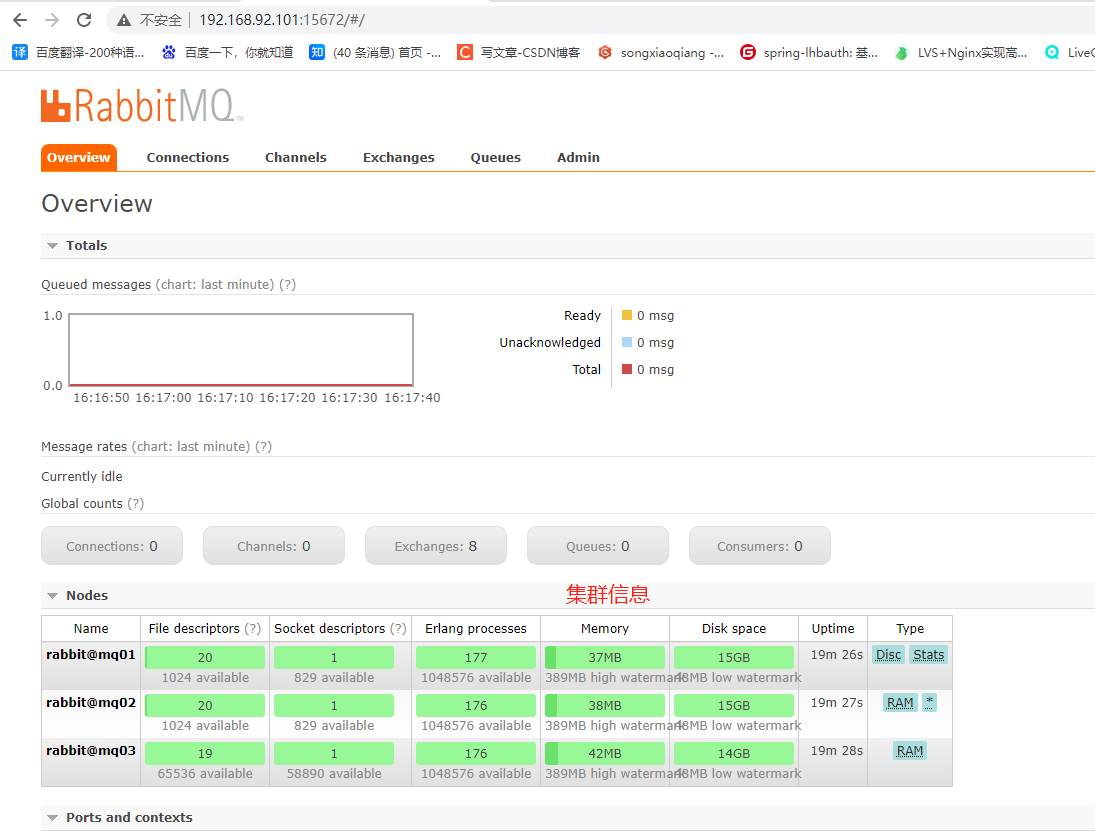
登录rabbitmq web管理控制台查看
打开浏览器输入http://ip:15672, 输入默认的Username:guest,输入默认的Password:guest ,登录后出现如图所示的界面。
RabbitMQ镜像集群配置
2.4 镜像集群配置
概述
上面已经完成RabbitMQ默认集群模式,但并不保证队列的高可用性,尽管交换机、绑定这些可以复制到集群里的任何一个节点,但是队列内容不会复制。虽然该模式解决一项目组节点压力,但队列节点宕机直接导致该队列无法应用,只能等待重启,所以要想在队列节点宕机或故障也能正常应用,就要复制队列内容到集群里的每个节点,必须要创建镜像队列。
镜像队列是基于普通的集群模式的,然后再添加一些策略,所以你还是得先配置普通集群,然后才能设置镜像队列,我们就以上面的集群接着做。
说明
设置的镜像队列可以通过开启的网页的管理端,也可以通过命令,这里说的是其中的通过命令方式。
1.开启镜像队列
在主节点执行如下命令:(添加一个节点,其它节点也都会有该策略)
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
2. 复制系数
在上面我们指定了 ha-mode 的值为 all ,代表消息会被同步到所有节点的相同队列中。这里我们之所以这样配置,因为我们本身只有三个节点,因此复制操作的性能开销比较小。如果你的集群有很多节点,那么此时复制的性能开销就比较大,此时需要选择合适的复制系数。通常可以遵循过半写原则,即对于一个节点数为 n 的集群,只需要同步到 n/2+1 个节点上即可。此时需要同时修改镜像策略为 exactly,并指定复制系数 ha-params,示例命令如下:
rabbitmqctl set_policy ha-two "^" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
除此之外,RabbitMQ 还支持使用正则表达式来过滤需要进行镜像操作的队列,示例如下:
rabbitmqctl set_policy ha-all "^ha\." '{"ha-mode":"all"}'
此时只会对 ha 开头的队列进行镜像。
2.5 集群破坏性测试
-
我们新建一个queue,并且发送一条消息
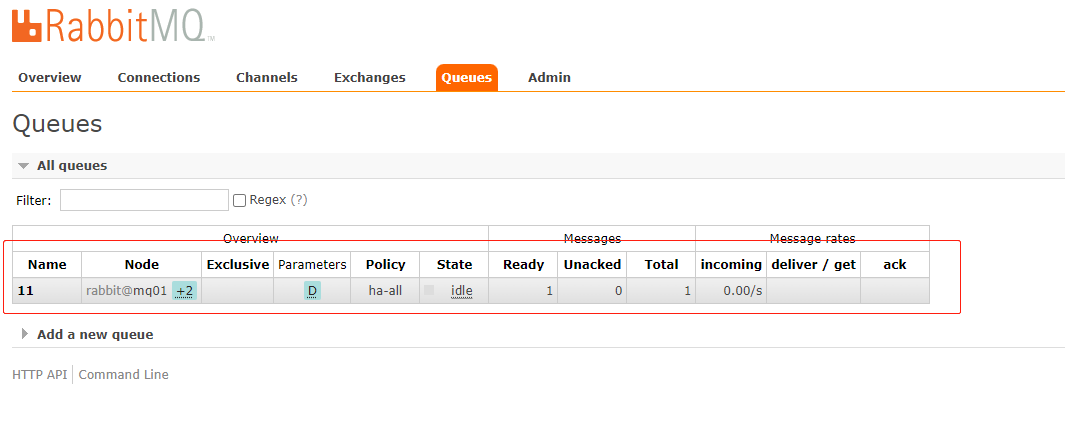
-
将mq01节点的服务关闭,再通过mq02和mq03查看消息记录是否还存在。
rabbitmqctl stop_app
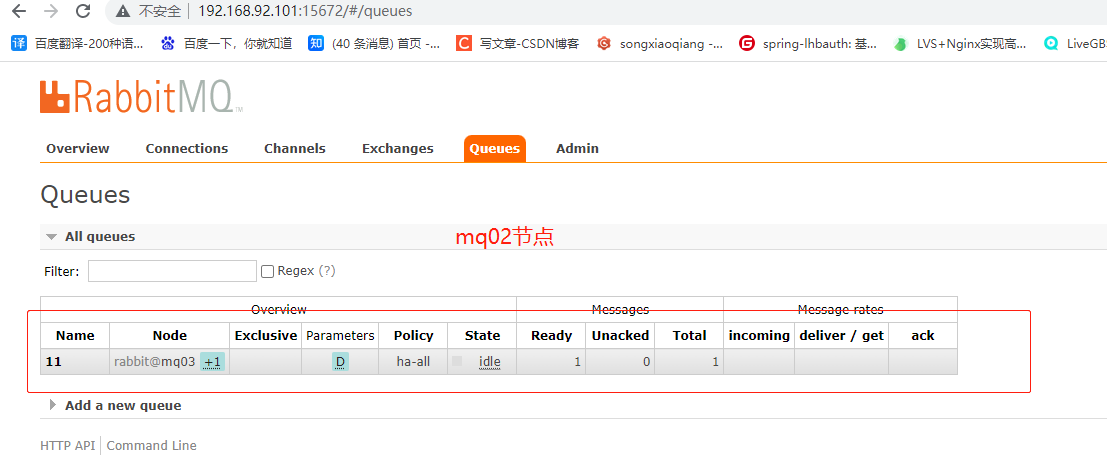
从中可以看到ab队列已经从之前的+2显示成+1了,而且消息记录是存在的。 -
再将mq02节点的服务关闭,通过mq03查看消息记录是否还存在。
rabbitmqctl stop_app
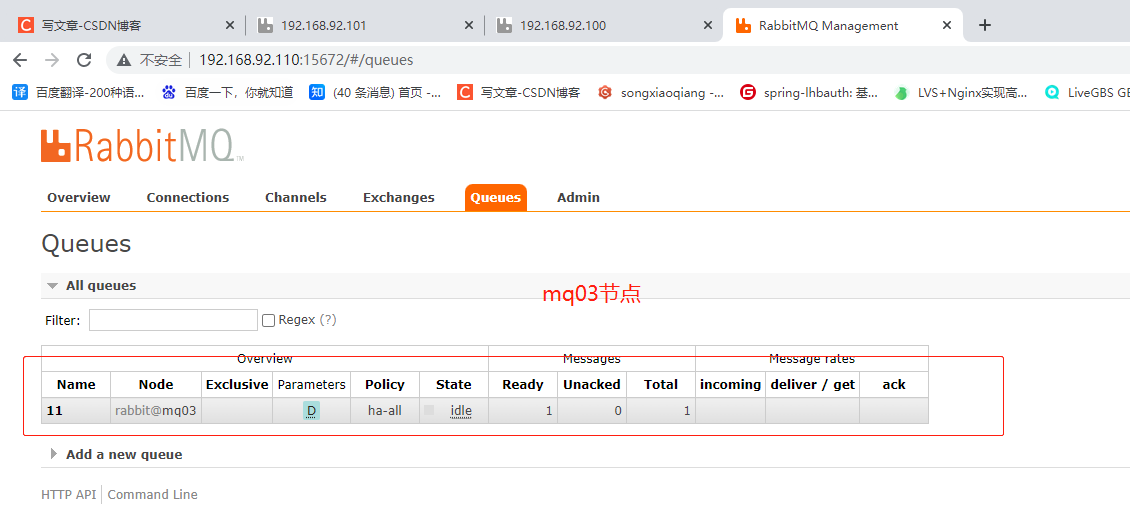
从中可以看到ab队列和消息记录还是存在的,只是变成了一个节点了。 -
将mq01和mq02的服务再启动起来
rabbitmqctl start_app
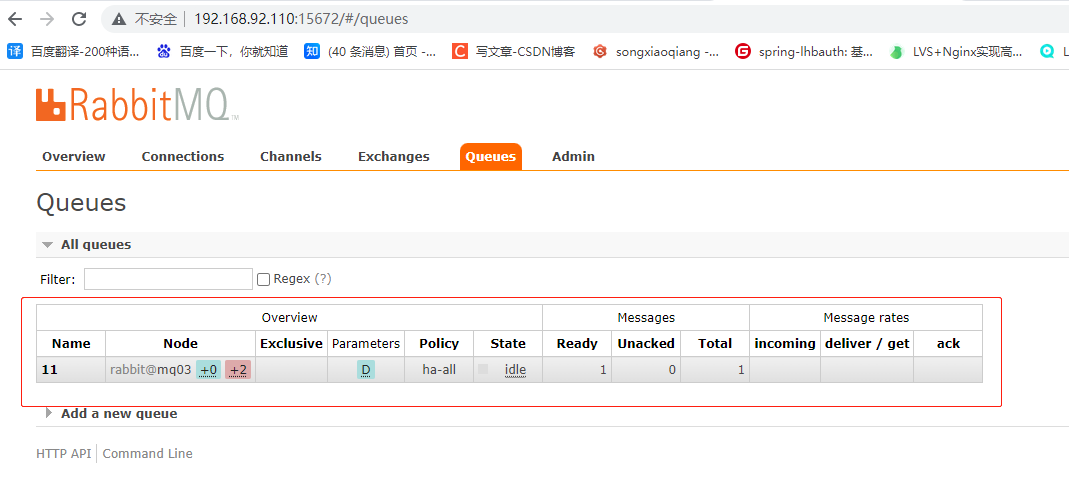
从中可以看到ab队列后面+2变成了粉色,鼠标指上去显示镜像无法同步。如果这时候停掉mq03节点的服务,那么队列里面的消息将会丢失。
采取的解决办法是选择在mq02节点上执行同步命令。
rabbitmqctl sync_queue 11
其中11为队列名
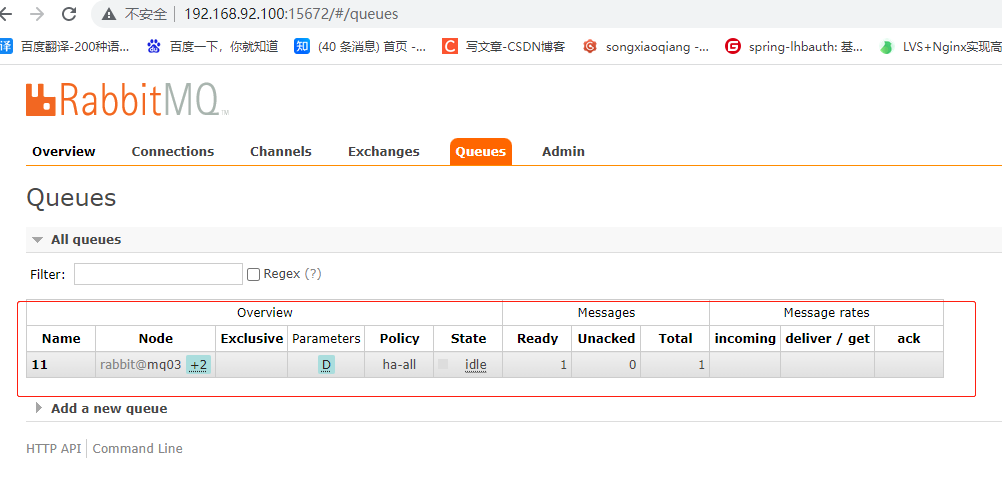
同步完成后,+2又变成了蓝色。
这样,我们就测试了rabbitmq集群的破坏性测试,说明集群配置成功。
2.6 节点下线
以上介绍的集群搭建的过程就是服务扩容的过程,如果想要进行服务缩容,即想要把某个节点剔除集群,有两种可选方式:
第一种:可以先使用 rabbitmqctl stop 停止该节点上的服务,然后在其他任意一个节点上执行 forget_cluster_node 命令。这里以剔除 mq03上的服务为例,此时可以在 mq01或 mq02上执行下面的命令:
rabbitmqctl forget_cluster_node rabbit@mq03
第二种方式:先使用 rabbitmqctl stop 停止该节点上的服务,然后再执行 rabbitmqctl reset 这会清空该节点上所有历史数据,并主动通知集群中其它节点它将要离开集群。
2.7 集群的关闭与重启
没有一个直接的命令可以关闭整个集群,需要逐一进行关闭。但是需要保证在重启时,最后关闭的节点最先被启动。如果第一个启动的不是最后关闭的节点,那么这个节点会等待最后关闭的那个节点启动,默认进行 10 次连接尝试,超时时间为 30 秒,如果依然没有等到,则该节点启动失败。
这带来的一个问题是,假设在一个三节点的集群当中,关闭的顺序为 mq01,mq02,mq03,如果 mq01因为故障暂时没法恢复,此时 mq02 和 mq03就无法启动。想要解决这个问题,可以先将 mq01节点进行剔除,命令如下:
rabbitmqctl forget_cluster_node rabbit@mq01 -offline
此时需要加上 -offline 参数,它允许节点在自身没有启动的情况下将其他节点剔除。
三、HAproxy负载
安装与使用我这里不再赘述,有需要的同学参考:HAProxy的安装和配置详解
3.1 修改HAproxy配置文件
在/etc/haproxy/haproxy.cfg文件末尾新增配置信息
listen admin_stats
bind 0.0.0.0:8189
stats enable
mode http
log global
stats uri /haproxy_stats
stats realm Haproxy\ Statistics
stats auth admin:admin
#stats hide-version
#stats admin if TRUE
stats refresh 30s
listen rabbitmq_admin
bind 0.0.0.0:15673
server mq01 192.168.92.100:15672
server mq02 192.168.92.101:15672
server mq03 192.168.92.110:15672
listen rabbitmq_cluster
bind 0.0.0.0:5673
mode tcp
option tcplog
maxconn 10000
balance roundrobin
server mq01 192.168.92.100:5672 check inter 1000 rise 2 fall 2
server mq02 192.168.92.101:5672 check inter 1000 rise 2 fall 2
server mq03 192.168.92.110:5672 check inter 1000 rise 2 fall 2
并且注释掉option forwardfor
3.2 启动HAproxy负载
systemctl restart haproxy
ps -ef|grep haproxy
可以看到通过15673端口也能访问到
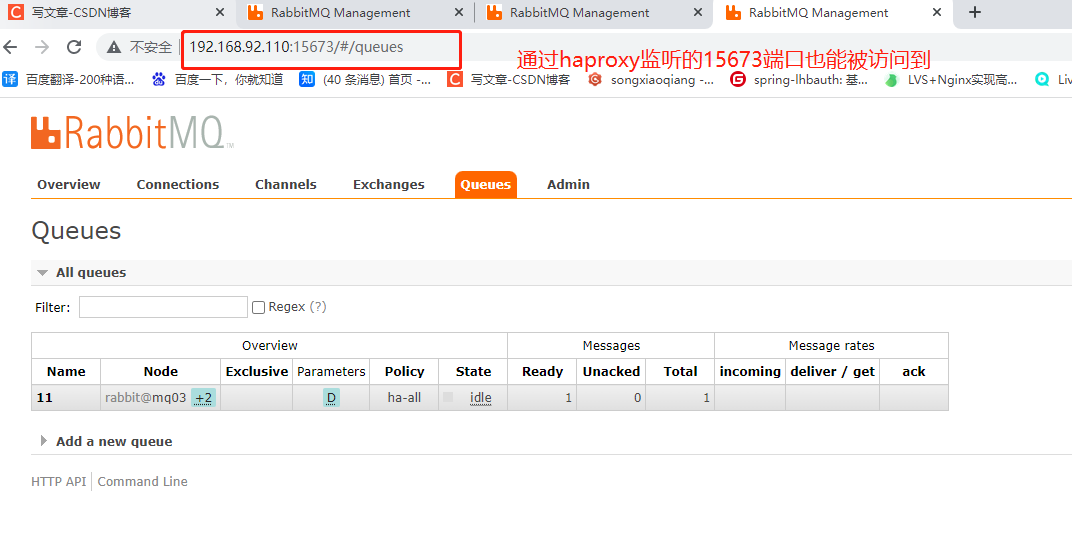
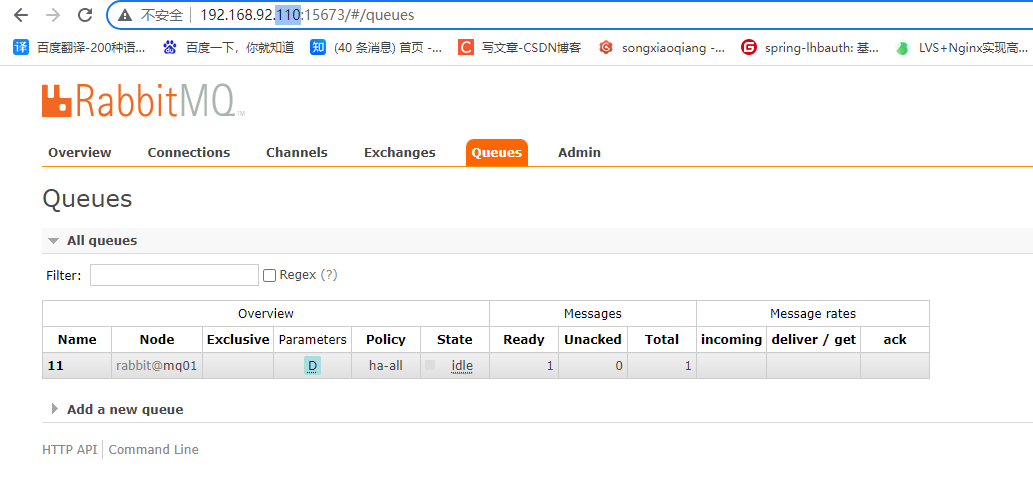
我们给110(mq03)、101(mq02)服务停掉rabbitmqctl stop_app,发现依然能正常访问,到这里我们负载均衡已经实现了。
四、keepalive配置Haproxy负载
原理和nginx一样,有需要的同学可参考:搭建keepalived+nginx热备高可用(主备+双主模式)
接着就可以搭建 Keepalived 来解决 HAProxy 故障转移的问题。这里我在 mq02和 mq03上安装 KeepAlived ,两台主机上的搭建的步骤完全相同,只是部分配置略有不同,具体如下:
4.1 keepalived安装
这里使用yum的方式安装
# 安装ipvs
yum install ipvsadm
# 安装keepalived
yum install keepalived
常用命令
#启动
systemctl start keepalived
#停止
systemctl stop keepalived
重启#
systemctl restart keepalived
#查看状态
systemctl status keepalived
#设置开机启动
systemctl enable keepalived
#关闭开机启动
systemctl disable keepalived
相关配置在/etc/keepalived/目录下编辑keepalived.conf文件中进行修改
vim /etc/keepalived/keepalived.conf
- CentOS 7 默认已经安装了 firewalld 防火墙,关闭防火墙
#启动防火墙
systemctl start firewalld
#关闭防火墙
systemctl stop firewalld
4.2 HAProxy 检查脚本配置
在/etc/keepalived/目下编写脚本 haproxy_check.sh
这个脚本主要用于判断 HAProxy 服务是否正常,如果不正常且无法启动,此时就需要将本机 Keepalived 关闭,从而让虚拟 IP 漂移到备份节点
vim /etc/keepalived/haproxy_check.sh
#!/bin/bash
#!/bin/bash
# 判断haproxy是否已经启动
if [ $(ps -C haproxy --no-heading|wc -l) -eq 0 ] ; then
#如果没有启动,则启动
systemctl start haproxy
fi
#睡眠3秒以便haproxy完全启动
sleep 3
#如果haproxy还是没有启动,此时需要将本机的keepalived服务停掉,以便让VIP自动漂移到另外一台haproxy
if [ $(ps -C haproxy --no-header |wc -l) -eq 0 ] ; then
systemctl stop keepalived
fi
创建后为其赋予执行权限:
chmod +x /etc/keepalived/haproxy_check.sh
4.3 mq03(110服务器) 主keep文件配置
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id happroxy_01 #机器标识,唯一
}
vrrp_script haproxy_check {
script "/etc/keepalived/haproxy_check.sh" #脚本位置
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER # 指定instance(Initial)的初始状态, MASTER 或者BACKUP
interface ens33 #实例绑定的网卡,因为在配置虚拟IP的时候必须是在已有的网卡上添加的,(注意自己系统,我的默认是ens33,有的是eth0)
virtual_router_id 51 #这里设置VRID,这里非常重要,主从需要配置一致
priority 150 #设置本节点的优先级,优先级高的为master
advert_int 1
authentication {
#定义认证方式和密码,主从必须一样
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.92.200 #vip ip 两台需配置一致
}
track_script {
# 引用上面编写的vrrp_script 脚本
haproxy_check
}
}
基础三个模块,global_defs全局模块,vrrp_instance配置vip模块,vrrp_script 脚本模块,用来检测nginx服务。
注:vrrp_script定义脚本后,在vrrp_instance模块必须加上track_script 参数。我就入了这个坑,导致脚本不生效。
global_defs模块参数
notification_email: keepalived在发生诸如切换操作时需要发送email通知地址,后面的 smtp_server 相比也都知道是邮件服务器地址。也可以通过其它方式报警,毕竟邮件不是实时通知的。router_id: 机器标识,通常可设为hostname。故障发生时,邮件通知会用到。
vrrp_instance模块参数
state: 指定instance(Initial)的初始状态, MASTER 或者BACKUP,不是唯一性的,跟后面的优先级priority参数有关。interface: 实例绑定的网卡,因为在配置虚拟IP的时候必须是在已有的网卡上添加的,(注意自己系统,我的默认是ens33,有的是eth0)mcast_src_ip: 发送多播数据包时的源IP地址,这里注意了,这里实际上就是在那个地址上发送VRRP通告,这个非常重要,一定要选择稳定的网卡端口来发送,这里相当于heartbeat的心跳端口,如果没有设置那么就用默认的绑定的网卡的IP,也就是interface指定的IP地址virtual_router_id: 这里设置VRID,这里非常重要,相同的VRID为一个组,他将决定多播的MAC地址priority: 设置本节点的优先级,优先级高的为master(1-255)advert_int: 检查间隔,默认为1秒。这就是VRRP的定时器,MASTER每隔这样一个时间间隔,就会发送一个advertisement报文以通知组内其他路由器自己工作正常authentication: 定义认证方式和密码,主从必须一样virtual_ipaddress: 这里设置的就是VIP,也就是虚拟IP地址,他随着state的变化而增加删除,当state为master的时候就添加,当state为backup的时候删除,这里主要是有优先级来决定的,和state设置的值没有多大关系,这里可以设置多个IP地址track_script: 引用VRRP脚本,即在 vrrp_script 部分指定的名字。定期运行它们来改变优先级,并最终引发主备切换。
vrrp_script模块参数
告诉 keepalived 在什么情况下切换,所以尤为重要。可以有多个 vrrp_script
script: 自己写的检测脚本。也可以是一行命令如killall -0 nginxinterval 2: 每2s检测一次weight -5: 检测失败(脚本返回非0)则优先级 -5fall 2: 检测连续 2 次失败才算确定是真失败。会用weight减少优先级(1-255之间)rise 1: 检测 1 次成功就算成功。但不修改优先级
4.4 mq02(101服务器) 备keep文件配置
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id happroxy_02 #机器标识,唯一
}
vrrp_script check_nginx {
script "/etc/keepalived/haproxy_check.sh" #脚本位置
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state BACKUP #配置为备用
interface ens33
virtual_router_id 51
priority 100 #优先级需要比master低
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.92.200
}
track_script {
haproxy_check
}
}
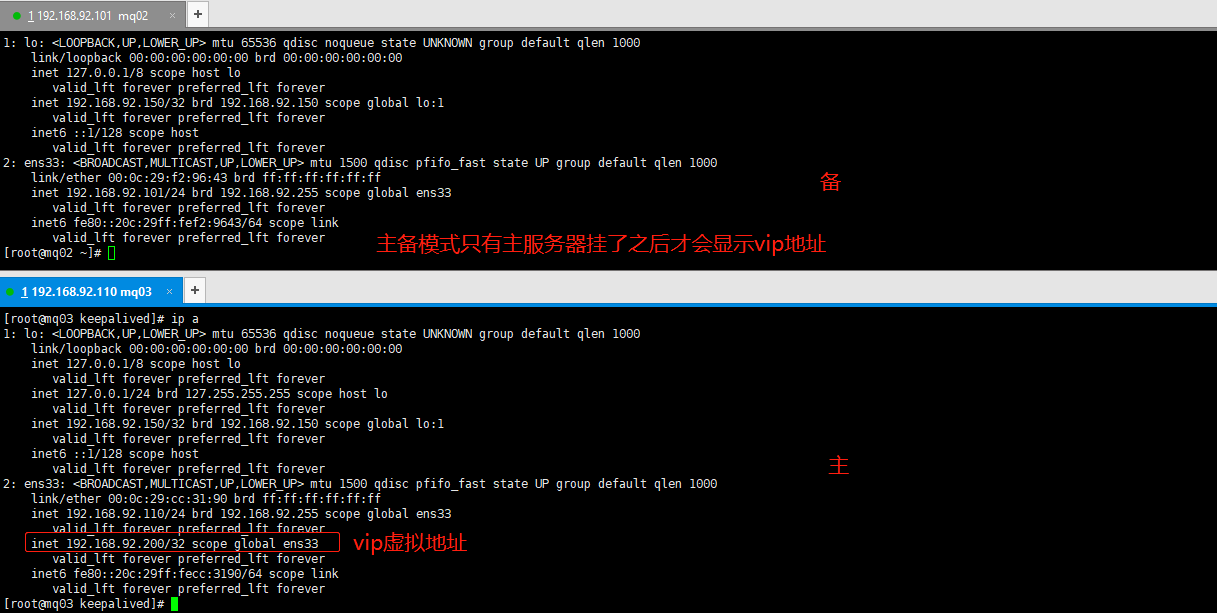
配置完成后重启两台keepalived,查看ip
syetemctl restart keepalived
ip a
4.5 验证故障转移
这里我们验证一下故障转移,因为按照我们上面的检测脚本,如果 HAProxy 已经停止且无法重启时 KeepAlived 服务就会停止,也可以直接使用以下命令停止 Keepalived 服务:
[root@mq03 keepalived]# systemctl stop haproxy
[root@mq03 keepalived]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet 127.0.0.1/24 brd 127.255.255.255 scope host lo
valid_lft forever preferred_lft forever
inet 192.168.92.150/32 brd 192.168.92.150 scope global lo:1
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:cc:31:90 brd ff:ff:ff:ff:ff:ff
inet 192.168.92.110/24 brd 192.168.92.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.92.200/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fecc:3190/64 scope link
valid_lft forever preferred_lft forever
可以发现手动停止haproxy后vip并没有漂移,这是因为脚本haproxy_check.sh中代码是先判断haproxy状态如果挂掉后先重启,3秒后重启没有成功则停止keepalived,这时才会实现珍珍的vip漂移
停掉主keepalived
所以这里要本地测试直接手动停掉mq03中的keepalived
systemctl stop keepalived
#手动停掉keepalived
[root@mq03 keepalived]# systemctl stop keepalived
[root@mq03 keepalived]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet 127.0.0.1/24 brd 127.255.255.255 scope host lo
valid_lft forever preferred_lft forever
inet 192.168.92.150/32 brd 192.168.92.150 scope global lo:1
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:cc:31:90 brd ff:ff:ff:ff:ff:ff
inet 192.168.92.110/24 brd 192.168.92.255 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fecc:3190/64 scope link
valid_lft forever preferred_lft forever
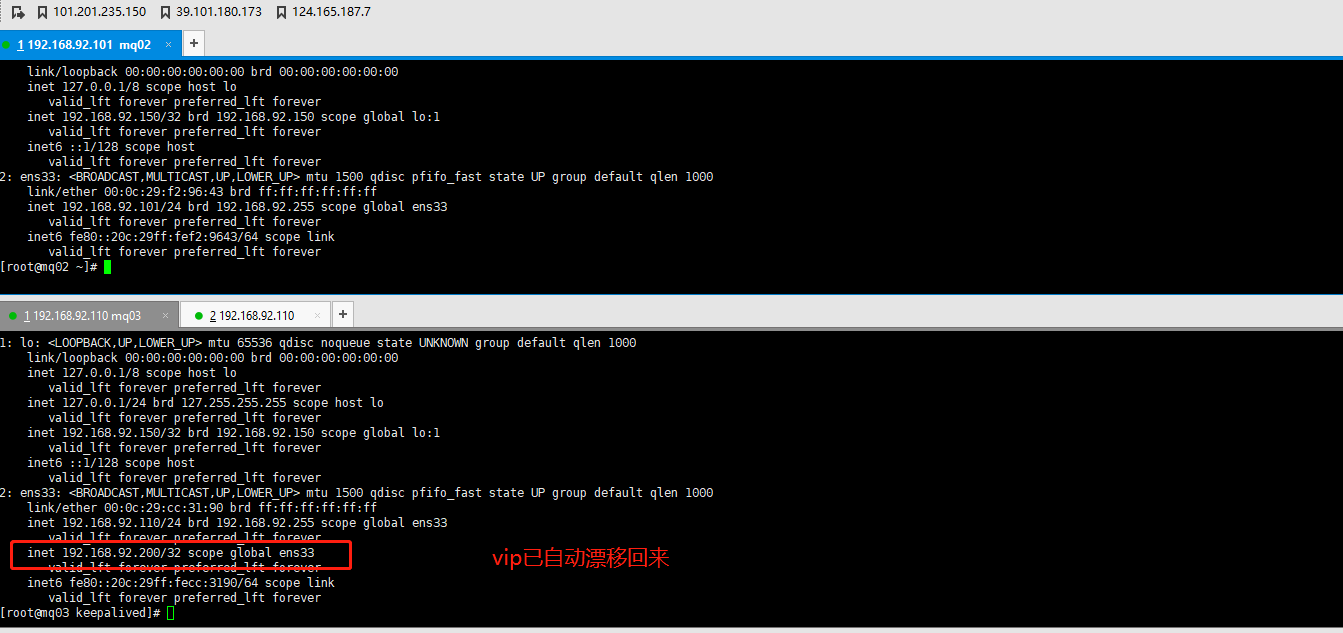
这个时候发现ip已经漂移,查看mq02服务器ip
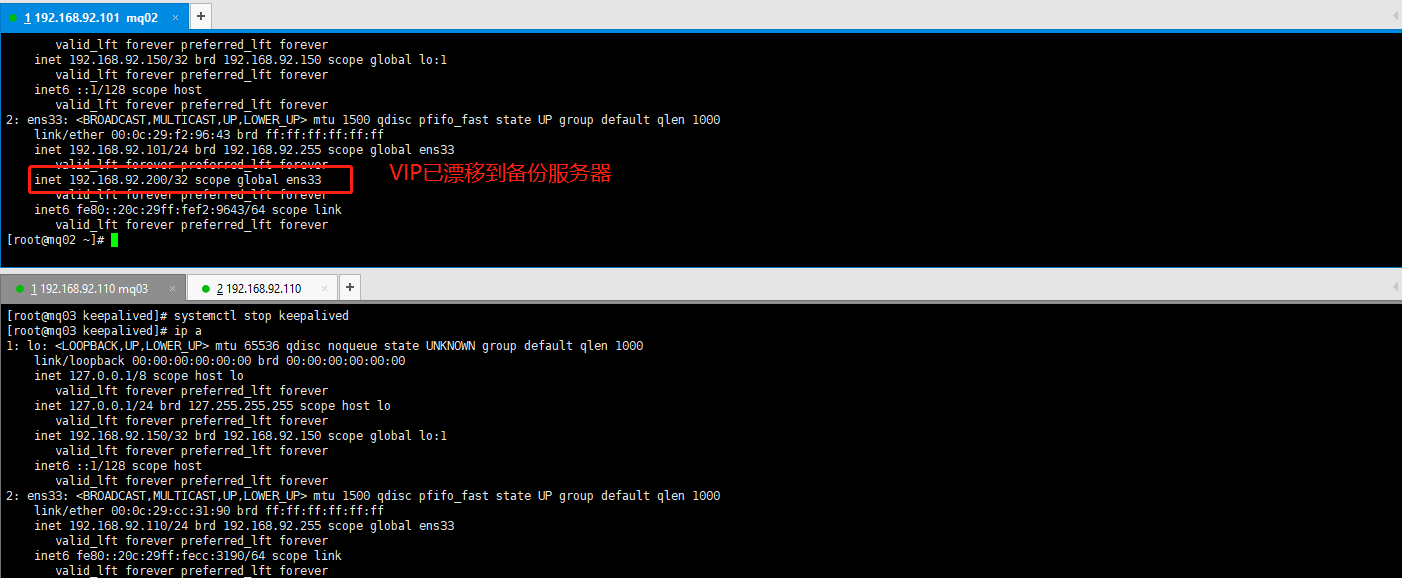
页面是正常访问的
重启主keepalived
可以发现VIP已经自动漂移回来
[root@mq03 keepalived]# systemctl start keepalived
[root@mq03 keepalived]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet 127.0.0.1/24 brd 127.255.255.255 scope host lo
valid_lft forever preferred_lft forever
inet 192.168.92.150/32 brd 192.168.92.150 scope global lo:1
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:cc:31:90 brd ff:ff:ff:ff:ff:ff
inet 192.168.92.110/24 brd 192.168.92.255 scope global ens33
valid_lft forever preferred_lft forever
inet 192.168.92.200/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fecc:3190/64 scope link
valid_lft forever preferred_lft forever
总结
以上配置的主备模式,双主模式具体使用参考:搭建keepalived+nginx热备高可用(主备+双主模式)
此时对外服务的 VIP 依然可用,代表已经成功地进行了故障转移。至此集群已经搭建成功,任何需要发送或者接受消息的客户端服务只需要连接到该 VIP 即可,示例如下:
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.92.200");