目标
- 搭建一款三节点的Rabbitmq服务集群,满足高可用的要求
- 要求高可用,保活,镜像队列,负载均衡。
主要组件
- RabbitMQ 用于存储转发消息及镜像队列,
- HAProxy 用于负载均衡到达rabbitmq的流量,
- Keepalived 用于保活HAProxy(也可以保活rabbitmq),并对外提供VIP用于访问。
- 下载地址
- RabbitMQ
- HAProxy
- KeepAlived
架构模型
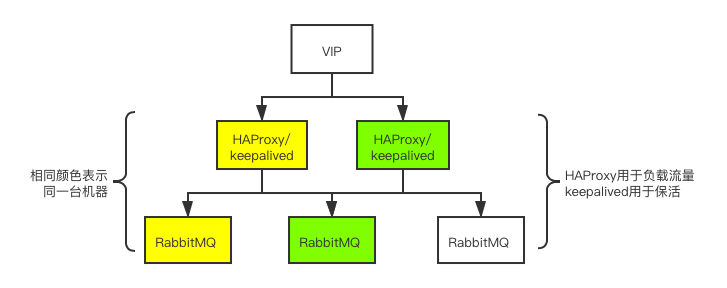
访问链路
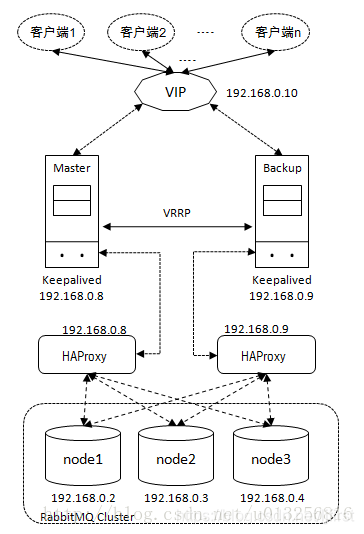
图片选自:RabbitMQ负载均衡(3)——Keepalived+HAProxy实现高可用的负载均衡
- 客户端通过VIP建立通信链路;通信链路通过Keeaplived的Master节点路由到对应的HAProxy之上;HAProxy通过负载均衡算法将负载分发到集群中的各个节点之上。
- 正常情况下客户端的连接通过图中左侧部分进行负载分发。
- 当Keepalived的Master节点挂掉或者HAProxy挂掉无法恢复,那么Backup提升为Master,客户端的连接通过图中右侧部分进行负载分发
选型原因
- 为什么要搭建多节点的消息队列?
单节点rabbitmq存在宕机风险,因此需要搭建三台互相备份
- 如何做到消息镜像的?
镜像其实是一种策略,首先是将三台rabbitmq设置为集群,然后开启镜像策略,使得消息传递到一个队列时,会自动拷贝到其他镜像的队列。
- 如果某一台接受到的压力过大,如何做到负载均衡?
rabbitmq集群本身不具备负载均衡的功能,需要配合其他软件使用,比如HAProxy,同样的道理,为了防止出现宕机问题,需要在集群中配置多台HAProxy。
- 如果HAProxy宕机了,另外一台如何感知?并切换流量请求?
HAProxy在宕机时,keepalived有保活脚本,大概意思就是发现keepalived发现HAProxy不存在,就会启动它,过三秒发现还是没启动,那就关闭它,关闭它的时候,会触发vip漂移到另外一台上。HAProxy 之间需要能够自动进行故障转移,通常的解决方案就是 KeepAlived。KeepAlived也是两台,一主一从,对外提供vip,主机宕机,从机会接管vip(具体见文末的彩蛋2)。
- 本案例中选取了两台HAProxy做负载均衡,负载方式是每台HAProxy都负载三台Rabbitmq,还是每台负载其中的两台?
负载均衡三台。满足极端情况下的高可用。
- 万一有一台Rabbitmq挂了,那么HAProxy是否还会向其发送消息导致消息丢失?
HAProxy的.cfg文件中定义的有健康检查机制,参数fall在指定多少次不成功的健康检查后,认为该服务宕掉了。配置文件中:server node3 hadoop003:5672 check inter 5000 rise 2 fall 3 weight 1,这里的rise 2 fall 3 就是用于判断死活的。haproxy健康检查rabbitmq,keepalived的ha_check.sh脚本检测haproxy
- 如果keepalived挂了,另一台keepalived如何work?
这个问题我没有仔细研究,应该是两台keepalived互相有心跳保活,主机宕机,从机会立刻抢占vip.
简易搭建流程
- 第一步:分别在不同虚拟机上安装RabbitMQ
- 第二步:验证RabbitMQ安装成功
- 第三步:搭建RabbitMQ镜像队列
- 第四步:设置RabbitMQ镜像规则并验证
- 第五步:搭建HAProxy
- 第六步:HAProxy权限相关的操作
- 第七步:搭建Keepalived
- 第八步:keepalived权限相关的操作
- 第九步:分别测试在不同宕机情况下,对消息传递的影响
详细搭建流程
- 第一步:分别在不同虚拟机上安装RabbitMQ
# 安装rabbitmq之前的依赖erlang和socat
rpm -ivh erlang-22.0.7-1.el7.x86_64.rpm
yum -y install socat
rpm -ivh rabbitmq-server-3.7.17-1.el7.noarch.rpm
# 启动服务 和 设置开机自启
service rabbitmq-server start
chkconfig rabbitmq-server on
# 新增用户并授权,第三句的 / 表示在vhost ”/“ 上的permission
rabbitctl add_user username password
rabbitctl set_user_tags username administrator
rabbitctl set_permissions -p / username ".*" ".*" ".*"
- 第二步:验证RabbitMQ安装成功
# 配置rabbitmq的浏览器插件
rabbitmq-plugins enable rabbitmq_management
# 在浏览器输入 IP:15672 输入用户名和密码 登录验证是否成功
# 点击浏览器中admin模块,看一下权限是否正确
- 第三步:搭建RabbitMQ镜像队列。
# 保持三台机器的.erlang.cookie一致,通过find / -iname .erlang.cookie 全局搜,然后copy到其他两台的root下,一般在/var/lib/rabbitmq/下可以找到,scp到其他两台上
scp xx/.erlang.cookie root@IP:/root/
# 分别在各自节点的/etc/hosts下设置相同的配置信息(copy),然后重启机器
IP1 hostname1
IP2 hostname2
IP3 hostname3
# 后台启动方式
rabbitmq-server -detached #说明:该命令会同时启动 Erlang 虚拟机和 RabbitMQ 应用服务。而后文用到的 rabbitmqctl start_app 只会启动 RabbitMQ 应用服务, rabbitmqctl stop_app 只会停止 RabbitMQ 服务
# 集群模式,设置镜像队列,下面四句话分别在三台机器上执行,只有主机需要改成内存运行模式,才运行第三句的--ram
rabbitmqctl stop_app # 1.停止服务
rabbitmqctl reset # 2.重置状态
# 3.节点加入,rabbit@hadoop001是集群的名字,请起的响亮点
rabbitmqctl join_cluster --ram rabbit@hadoop001
rabbitmqctl start_app # 4.启动服务
# 查看镜像队列状态
rabbitmqctl cluster_status
-
第四步:设置RabbitMQ镜像规则并验证
# 设置policy
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
# 验证
任意选取一台Rabbitmq登陆,创建一个队列,然后去其他两台看看,该队列是否存在
- 第五步:搭建HAProxy
# 找个文件夹解压
tar -zxvf haproxy-2.0.3.tar.gz
# 编译,其中TARGET=Linux26 是通过uname -a 来查看Linux内核版本的,我的版本是31,PREFIX的地址自己指定
make TARGET=Linux31 PREFIX=/usr/app/haproxy-2.0.3
make install PREFIX=/usr/app/haproxy-2.0.3
# haproxy.cfg是haproxy的配置文件,需要自己创建,然后去网上找别人写好的配置文件,启动的时候可能会引起报错,解决不了的直接删除
touch haproxy.cfg #这个文件后续会用于启动haproxy,位置最好放在haproxy/conf下,haproxy文件就是刚才的PREFIX指定的位置。
# 启动:就是用haproxy/sbin/haproxy去启动刚才的配置文件
/usr/app/haproxy-2.0.3/sbin/haproxy -f /usr/app/haproxy-2.0.3/conf/haproxy.cfg # 启动报错见下方的 《haproxy安装过程中的坑》
- 第六步:HAProxy权限相关的操作及验证
# HAproxy设置开机自启【源码包安装方式是没有启动脚本的,是能通过命令的方式进行启动和关闭,什么都不会输出,只能通过netstat 的方式进行验证】
#将HAProxy服务启动脚本放置到/etc/init.d/,启动脚本见下方【HAProxy服务启动脚本】
cp haproxy /etc/init.d/
chkconfig --add haproxy
chkconfig --list haproxy
service haproxy start|restart|stop|status
# 验证
浏览器输入IP:8100/stats 就可以看见haproxy的界面 #stats是你在haproxy.cfg的lister起的名字
- HAProxy服务启动脚本
- haproxy安装过程中的坑
# 启动报错
解决办法:先看报错信息中的数字,它对应哪一行出错,然后去配置文件中,要么删除要么修改,具体可以见下面的链接:HAProxy实战搭建
# 访问ip:8100/stats空页面:
解决办法:修改bind 为 0.0.0.0:8080
# 出现:Proxy 'monitor(就是你起的lister名)': in multi-process mode, stats will be limited to process assigned to the current request
解决办法:修改:nbproc=1
-
第七步:搭建Keepalived
#解压
tar -zxvf keepalived-2.0.18.tar.gz
cd keepalived-2.0.18
#安装keepalived的相关依赖
yum -y install libnl libnl-devel
#--prefix是指定安装路径,没有的话会帮你创建,/usr/app/是路径,也可以安装在/etc/local
./configure --prefix=/usr/app/keepalived-2.0.18
#编译
make && make install #这一步可能会报错,需要你安装gcc或者openssl-devel,甚至涉及到换yum源,需要你yum repolist all. yum clean all. yum makecache. yum install -y gcc-c++ tcl. yum install -y openssl-devel.
#进行环境配置,Keepalived 默认会从 /etc/keepalived/keepalived.conf 路径读取配置文件,所以需要将安装后的配置文件拷贝到该路径
make /etc/keepalived
#/usr/app选择自己的安装路径,keepalived.conf的配置见下面的链接
cp /usr/app/keepalived-2.0.18/etc/keepalived/keepalived.conf /etc/keepalived/
#将所有 Keepalived 脚本拷贝到 /etc/init.d/ 目录下:
#编译目录中的脚本,/usr/software/是之前你安装tar包的地方
cp /usr/software/keepalived-2.0.18/keepalived/etc/init.d/keepalived /etc/init.d/
#安装目录中的脚本
cp /usr/app/keepalived-2.0.18/etc/sysconfig/keepalived /etc/sysconfig/
cp /usr/app/keepalived-2.0.18/sbin/keepalived /usr/sbin/
- 第八步:keepalived权限相关的操作
#加入系统:
chmod +x /etc/init.d/keepalived
chkconfig --add keepalived 或者 chkcoonfig keepalived on
#设置/取消开机自动启动
systemctl enable/disable keepalived.service
#启动/停止
systemctl start/stop keepalived.service
#haproxy的存活情况的判断脚本,记住这个路径,需要写入到keepalived.conf中
chmod +x /etc/keepalived/haproxy_check.sh
#查看keepalived状态
service keepalived status 或者 systemctl status keepalived.service
- keepalived安装过程中的坑
- keepalived的配置文件的权限只能是644,否则就行报错
- keepalived.conf 配置文件和keepalived用于监控haproxy的存活情况的脚本haproxy_check.sh,可以参考这篇文档:基于 HAProxy + KeepAlived 搭建 RabbitMQ 高可用集群
测试方案
-
测试方案:
- 方案一:在下列情形下,访问VIP:15672,看看是否可以登陆rabbitmq的浏览器端。
- 方案二:在下列情形下,分别发送消息至rabbitmq,看看是否有消息投递失误。
-
测试情形:
- 情景一:关闭某一台机器上的rabbitmq服务
- 情景二:关闭某两台机器上的rabbitmq服务
- 情景三:关闭某一台机器上的haproxy服务
- 情景四:关闭某一台机器上的keepalived服务
- 情景五:同时关闭某一台机器上的haproxy+keepalived服务
- 情景六:同时分别关闭某一台机器上的haproxy和另一台机器上的keepalived服务
- 情景七:关闭这样一台机器(同时含有rabbitmq+haproxy+keepalived服务)
- 情景八:关闭这样两台机器(一台同时含有rabbitmq+haproxy+keepalived服务,一台仅含有rabbitmq)
-
测试结果:
- 方案一:全部通过
- 方案二:待和RabbitMQ实现消息100%投递一起测试
-
彩蛋1:
- 全量安装脚本请参考:常见中间件安装语句
-
彩蛋2:
扫描二维码关注公众号,回复: 11686522 查看本文章
- 在做测试一的时候,我是采用浏览器登录来查询的,但是发现宕掉rabbitmq1的时候,浏览器访问不了,我一度以为haproxy不起作用,实际上是haproxy的配置文件仅配置了5672,却没有对15672的端口进行配置,要么我改方案,不要浏览器测试,采用代码链接测试,要么在haproxy.cfg中增加15672的端口转发listen规则,在.cfg文件增加如下内容:
# 绑定配置
listen rabbitmq_browser
# 注意此处的15671,你也可以用任何不冲突的端口,然后浏览器访问vip:15671就可以了
bind :15671
# 注意此处的http
mode http
# 采用加权轮询的机制进行负载均衡
balance roundrobin
# RabbitMQ 集群节点配置
server 节点名 hadoop001:15672 check inter 5000 rise 2 fall 3 weight 1
server node2 hadoop002:15672 check inter 5000 rise 2 fall 3 weight 1
server node3 hadoop003:15672 check inter 5000 rise 2 fall 3 weight 1
- 彩蛋3:
- 在做测试的时候,我使用systemctl stop Haproxy.server 和 service Haproxy stop 去关闭Haproxy,但是再用service Haproxy status查看状态的时候,发现依旧在运行,我一度以为指令无效或者我装了一个假Haproxy。
- 实际原因是:我在keepalived里面配置的那个ha_check.sh脚本,会不停检查Haproxy,一旦查不到就重启Haproxy,sleep三秒还是不起来,就停掉该服务,然后keepalived的其他组件会发现检测的服务关闭,就会通知另一台备份的Haproxy开始承担主角工作。
- keepalived的配置文件中,有个state参数,一般文章建议设置主为master,从为backup,此处建议都设置为backup,这样的话,先启动的是主,当发生vip漂移的时候,原来的主启动不会再次发生漂移,减少网络抖动。
- 在做测试的时候,我使用systemctl stop Haproxy.server 和 service Haproxy stop 去关闭Haproxy,但是再用service Haproxy status查看状态的时候,发现依旧在运行,我一度以为指令无效或者我装了一个假Haproxy。