栅栏密码
所谓栅栏密码,就是把要加密的明文分成N个一组,然后把每组的第1个字连起来,形成一段无规律的话。 不过栅栏密码本身有一个潜规则,就是组成栅栏的字母一般不会太多。(一般不超过30个,也就是一、两句话)
凯撒密码
在密码学中,恺撒密码(英语:Caesar cipher),或称恺撒加密、恺撒变换、变换加密,是一种最简单且最广为人知的加密技术。它是一种替换加密的技术,明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移后被替换成密文。例如,当偏移量是3的时候,所有的字母A将被替换成D,B变成E,以此类推。
MD5
MD5算法的原理可简要的叙述为:MD5码以512位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了一系列的处理后,算法的输出由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值。
#include<iostream>
#include<string>
using namespace std;
#define shift(x, n) (((x) << (n)) | ((x) >> (32-(n))))//右移的时候,高位一定要补零,而不是补充符号位
#define F(x, y, z) (((x) & (y)) | ((~x) & (z)))
#define G(x, y, z) (((x) & (z)) | ((y) & (~z)))
#define H(x, y, z) ((x) ^ (y) ^ (z))
#define I(x, y, z) ((y) ^ ((x) | (~z)))
#define A 0x67452301
#define B 0xefcdab89
#define C 0x98badcfe
#define D 0x10325476
//strBaye的长度
unsigned int strlength;
//A,B,C,D的临时变量
unsigned int atemp;
unsigned int btemp;
unsigned int ctemp;
unsigned int dtemp;
//常量ti unsigned int(abs(sin(i+1))*(2pow32))
const unsigned int k[]={
0xd76aa478,0xe8c7b756,0x242070db,0xc1bdceee,
0xf57c0faf,0x4787c62a,0xa8304613,0xfd469501,0x698098d8,
0x8b44f7af,0xffff5bb1,0x895cd7be,0x6b901122,0xfd987193,
0xa679438e,0x49b40821,0xf61e2562,0xc040b340,0x265e5a51,
0xe9b6c7aa,0xd62f105d,0x02441453,0xd8a1e681,0xe7d3fbc8,
0x21e1cde6,0xc33707d6,0xf4d50d87,0x455a14ed,0xa9e3e905,
0xfcefa3f8,0x676f02d9,0x8d2a4c8a,0xfffa3942,0x8771f681,
0x6d9d6122,0xfde5380c,0xa4beea44,0x4bdecfa9,0xf6bb4b60,
0xbebfbc70,0x289b7ec6,0xeaa127fa,0xd4ef3085,0x04881d05,
0xd9d4d039,0xe6db99e5,0x1fa27cf8,0xc4ac5665,0xf4292244,
0x432aff97,0xab9423a7,0xfc93a039,0x655b59c3,0x8f0ccc92,
0xffeff47d,0x85845dd1,0x6fa87e4f,0xfe2ce6e0,0xa3014314,
0x4e0811a1,0xf7537e82,0xbd3af235,0x2ad7d2bb,0xeb86d391};
//向左位移数
const unsigned int s[]={7,12,17,22,7,12,17,22,7,12,17,22,7,
12,17,22,5,9,14,20,5,9,14,20,5,9,14,20,5,9,14,20,
4,11,16,23,4,11,16,23,4,11,16,23,4,11,16,23,6,10,
15,21,6,10,15,21,6,10,15,21,6,10,15,21};
const char str16[]="0123456789abcdef";
void mainLoop(unsigned int M[])
{
unsigned int f,g;
unsigned int a=atemp;
unsigned int b=btemp;
unsigned int c=ctemp;
unsigned int d=dtemp;
for (unsigned int i = 0; i < 64; i++)
{
if(i<16){
f=F(b,c,d);
g=i;
}else if (i<32)
{
f=G(b,c,d);
g=(5*i+1)%16;
}else if(i<48){
f=H(b,c,d);
g=(3*i+5)%16;
}else{
f=I(b,c,d);
g=(7*i)%16;
}
unsigned int tmp=d;
d=c;
c=b;
b=b+shift((a+f+k[i]+M[g]),s[i]);
a=tmp;
}
atemp=a+atemp;
btemp=b+btemp;
ctemp=c+ctemp;
dtemp=d+dtemp;
}
/*
*填充函数
*处理后应满足bits≡448(mod512),字节就是bytes≡56(mode64)
*填充方式为先加一个1,其它位补零
*最后加上64位的原来长度
*/
unsigned int* add(string str)
{
unsigned int num=((str.length()+8)/64)+1;//以512位,64个字节为一组
unsigned int *strByte=new unsigned int[num*16]; //64/4=16,所以有16个整数
strlength=num*16;
for (unsigned int i = 0; i < num*16; i++)
strByte[i]=0;
for (unsigned int i=0; i <str.length(); i++)
{
strByte[i>>2]|=(str[i])<<((i%4)*8);//一个整数存储四个字节,i>>2表示i/4 一个unsigned int对应4个字节,保存4个字符信息
}
strByte[str.length()>>2]|=0x80<<(((str.length()%4))*8);//尾部添加1 一个unsigned int保存4个字符信息,所以用128左移
/*
*添加原长度,长度指位的长度,所以要乘8,然后是小端序,所以放在倒数第二个,这里长度只用了32位
*/
strByte[num*16-2]=str.length()*8;
return strByte;
}
string changeHex(int a)
{
int b;
string str1;
string str="";
for(int i=0;i<4;i++)
{
str1="";
b=((a>>i*8)%(1<<8))&0xff; //逆序处理每个字节
for (int j = 0; j < 2; j++)
{
str1.insert(0,1,str16[b%16]);
b=b/16;
}
str+=str1;
}
return str;
}
string getMD5(string source)
{
atemp=A; //初始化
btemp=B;
ctemp=C;
dtemp=D;
unsigned int *strByte=add(source);
for(unsigned int i=0;i<strlength/16;i++)
{
unsigned int num[16];
for(unsigned int j=0;j<16;j++)
num[j]=strByte[i*16+j];
mainLoop(num);
}
return changeHex(atemp).append(changeHex(btemp)).append(changeHex(ctemp)).append(changeHex(dtemp));
}
unsigned int main()
{
string ss;
// cin>>ss;
string s=getMD5("abc");
cout<<s;
return 0;
}
Base64
最常见的加密方式,python和burp suite中有相对应的插件
十六进制
#include <stdio.h>
#include <string.h>
int strToHex(char *ch, char *hex);
int hexToStr(char *hex, char *ch);
int hexCharToValue(const char ch);
char valueToHexCh(const int value);
int main(int argc, char *argv[])
{
char ch[1024];
char hex[1024];
char result[1024];
char *p_ch = ch;
char *p_hex = hex;
char *p_result = result;
printf("please input the string:");
scanf("%s",p_ch);
strToHex(p_ch,p_hex);
printf("the hex is:%s\n",p_hex);
hexToStr(p_hex, p_result);
printf("the string is:%s\n", p_result);
return 0;
}
int strToHex(char *ch, char *hex)
{
int high,low;
int tmp = 0;
if(ch == NULL || hex == NULL){
return -1;
}
if(strlen(ch) == 0){
return -2;
}
while(*ch){
tmp = (int)*ch;
high = tmp >> 4;
low = tmp & 15;
*hex++ = valueToHexCh(high); //先写高字节
*hex++ = valueToHexCh(low); //其次写低字节
ch++;
}
*hex = '\0';
return 0;
}
int hexToStr(char *hex, char *ch)
{
int high,low;
int tmp = 0;
if(hex == NULL || ch == NULL){
return -1;
}
if(strlen(hex) %2 == 1){
return -2;
}
while(*hex){
high = hexCharToValue(*hex);
if(high < 0){
*ch = '\0';
return -3;
}
hex++; //指针移动到下一个字符上
low = hexCharToValue(*hex);
if(low < 0){
*ch = '\0';
return -3;
}
tmp = (high << 4) + low;
*ch++ = (char)tmp;
hex++;
}
*ch = '\0';
return 0;
}
int hexCharToValue(const char ch){
int result = 0;
//获取16进制的高字节位数据
if(ch >= '0' && ch <= '9'){
result = (int)(ch - '0');
}
else if(ch >= 'a' && ch <= 'z'){
result = (int)(ch - 'a') + 10;
}
else if(ch >= 'A' && ch <= 'Z'){
result = (int)(ch - 'A') + 10;
}
else{
result = -1;
}
return result;
}
char valueToHexCh(const int value)
{
char result = '\0';
if(value >= 0 && value <= 9){
result = (char)(value + 48); //48为ascii编码的‘0’字符编码值
}
else if(value >= 10 && value <= 15){
result = (char)(value - 10 + 65); //减去10则找出其在16进制的偏移量,65为ascii的'A'的字符编码值
}
else{
;
}
return result;
}
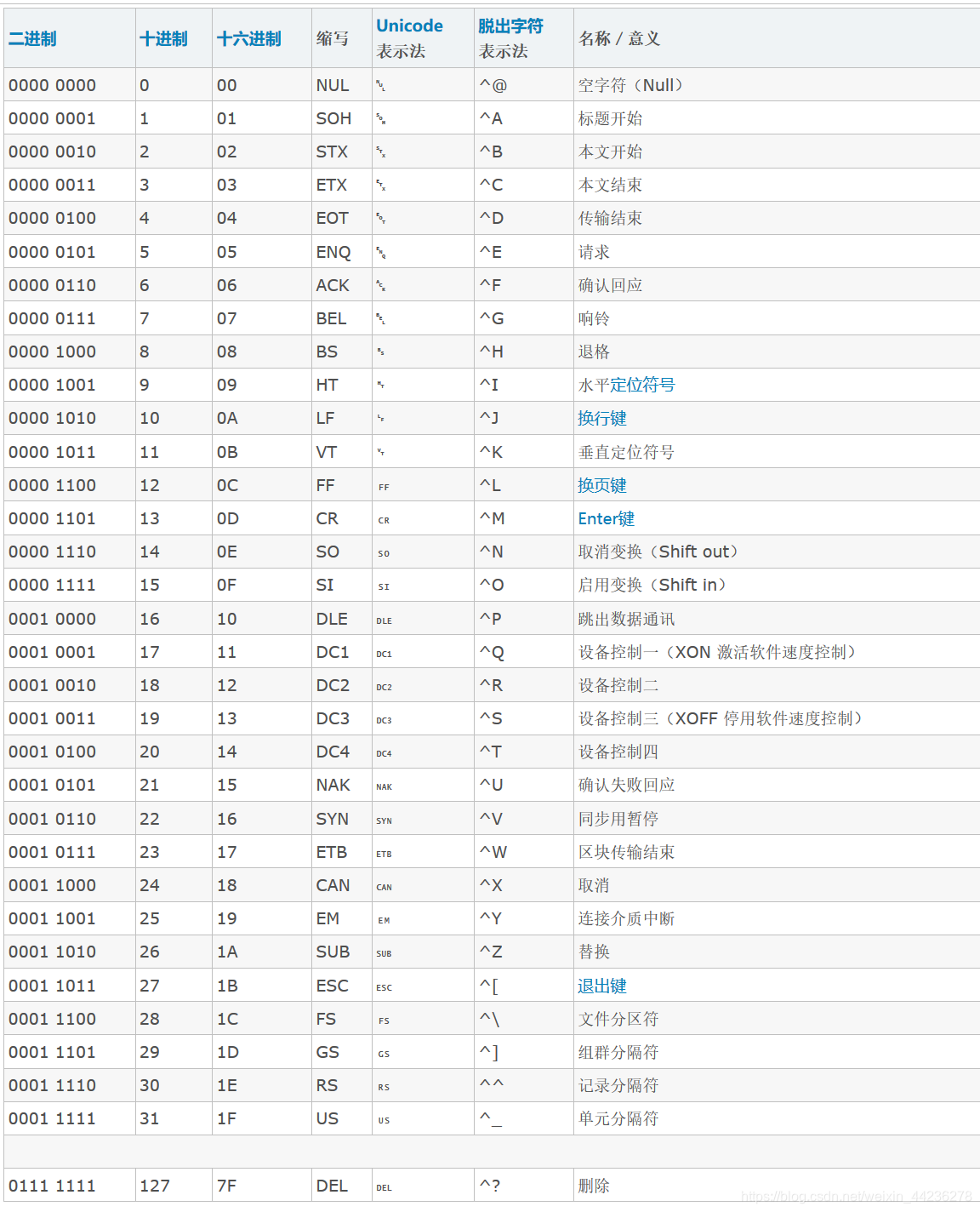
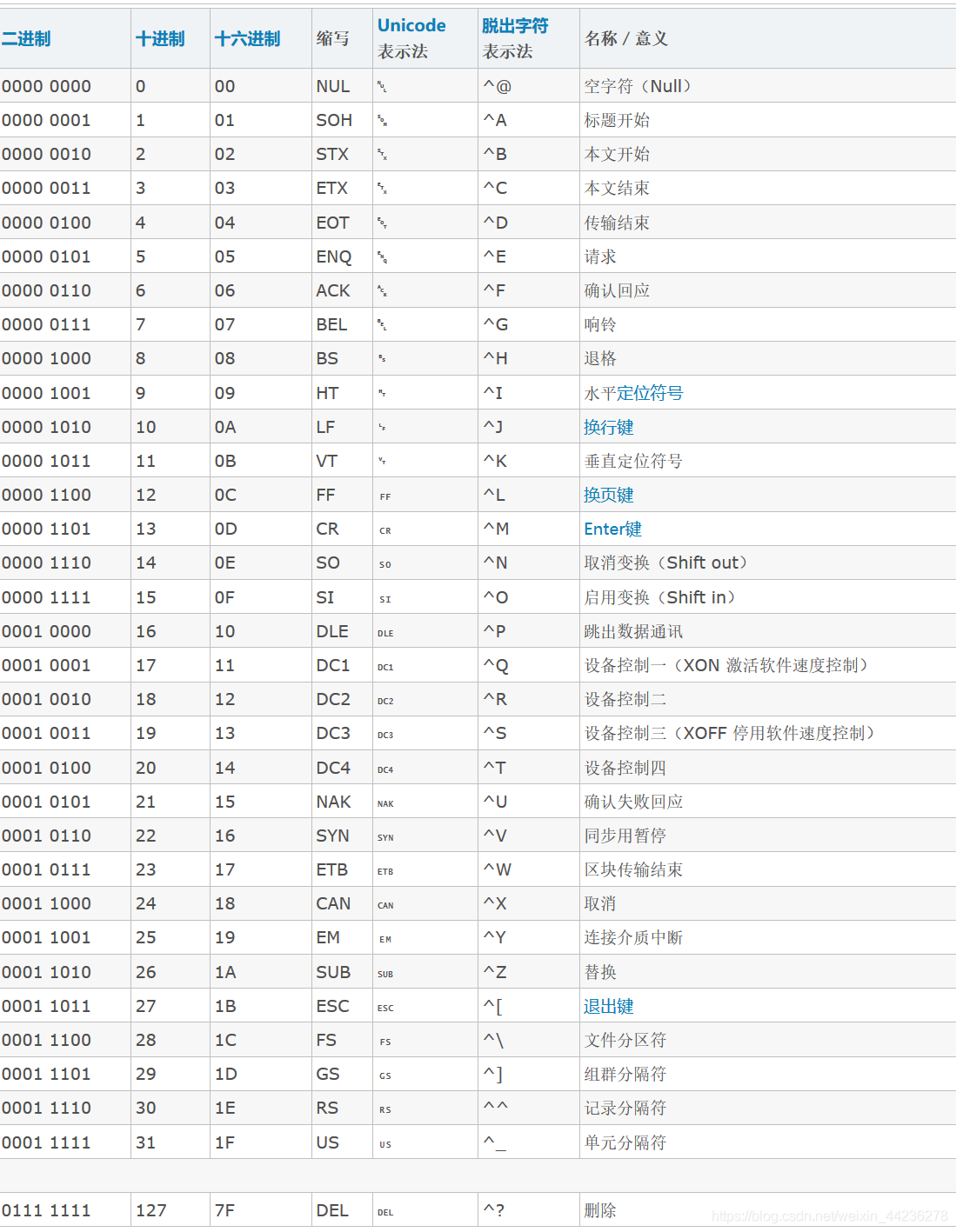
Unicode编码
Unicode 编码共有三种具体实现,分别为utf-8,utf-16,utf-32,其中utf-8占用一到四个字节,utf-16占用二或四个字节,utf-32占用四个字节。
URL编码
Escape编码
escape() 函数可对字符串进行编码,这样就可以在所有的计算机上读取该字符串。其中某些字符被替换成了十六进制的转义序列。
该编码不会对 ASCII 字母和数字进行编码,也不会对下面这些 ASCII 标点符号进行编码: * @ - _ + . / 。其他所有的字符都会被转义序列替换。

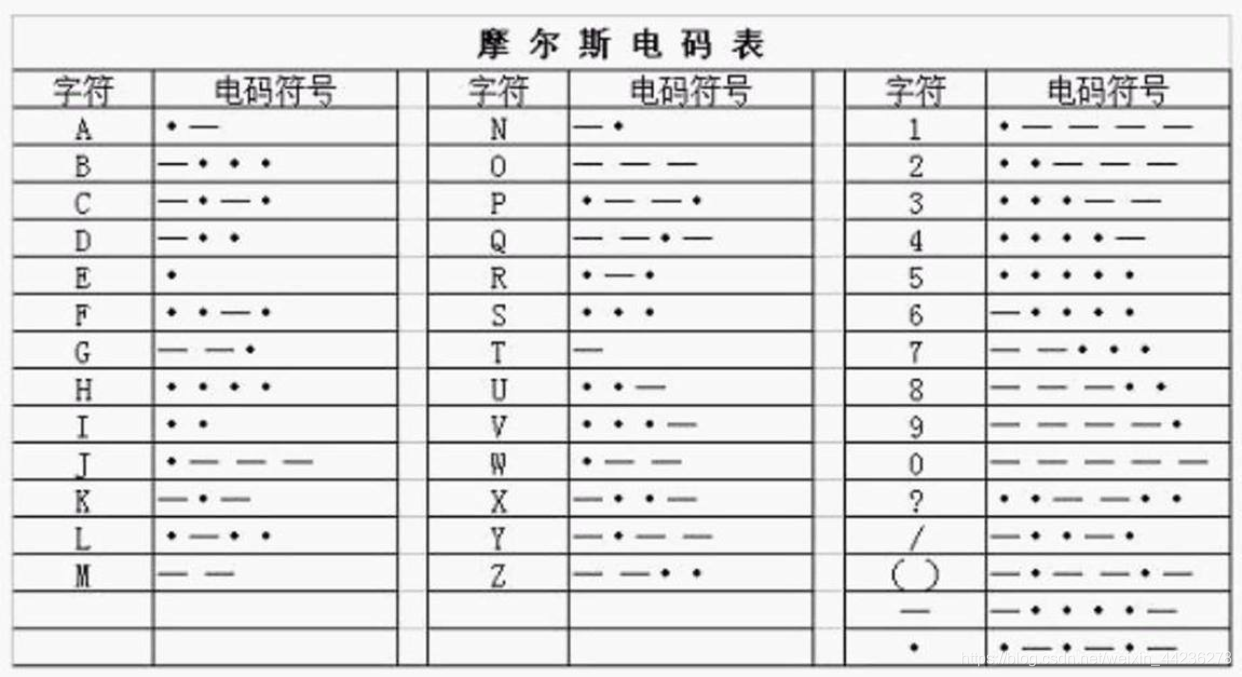
摩斯密码
培根密码
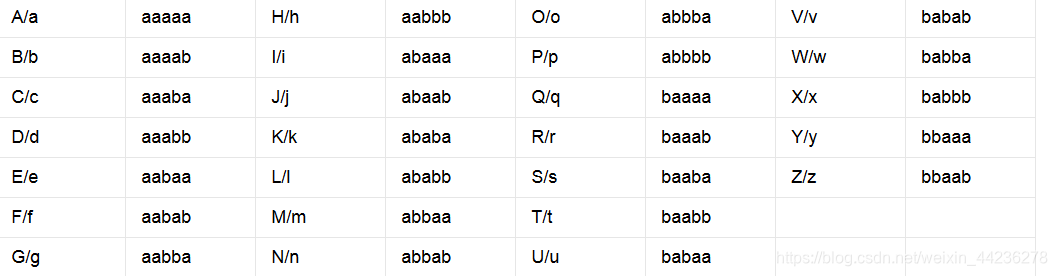 培根密码实际上就是一种替换密码,根据所给表一一对应转换即可加密解密 。它的特殊之处在于:可以通过不明显的特征来隐藏密码信息,比如大小写、正斜体等,只要两个不同的属性,密码即可隐藏。
培根密码实际上就是一种替换密码,根据所给表一一对应转换即可加密解密 。它的特殊之处在于:可以通过不明显的特征来隐藏密码信息,比如大小写、正斜体等,只要两个不同的属性,密码即可隐藏。
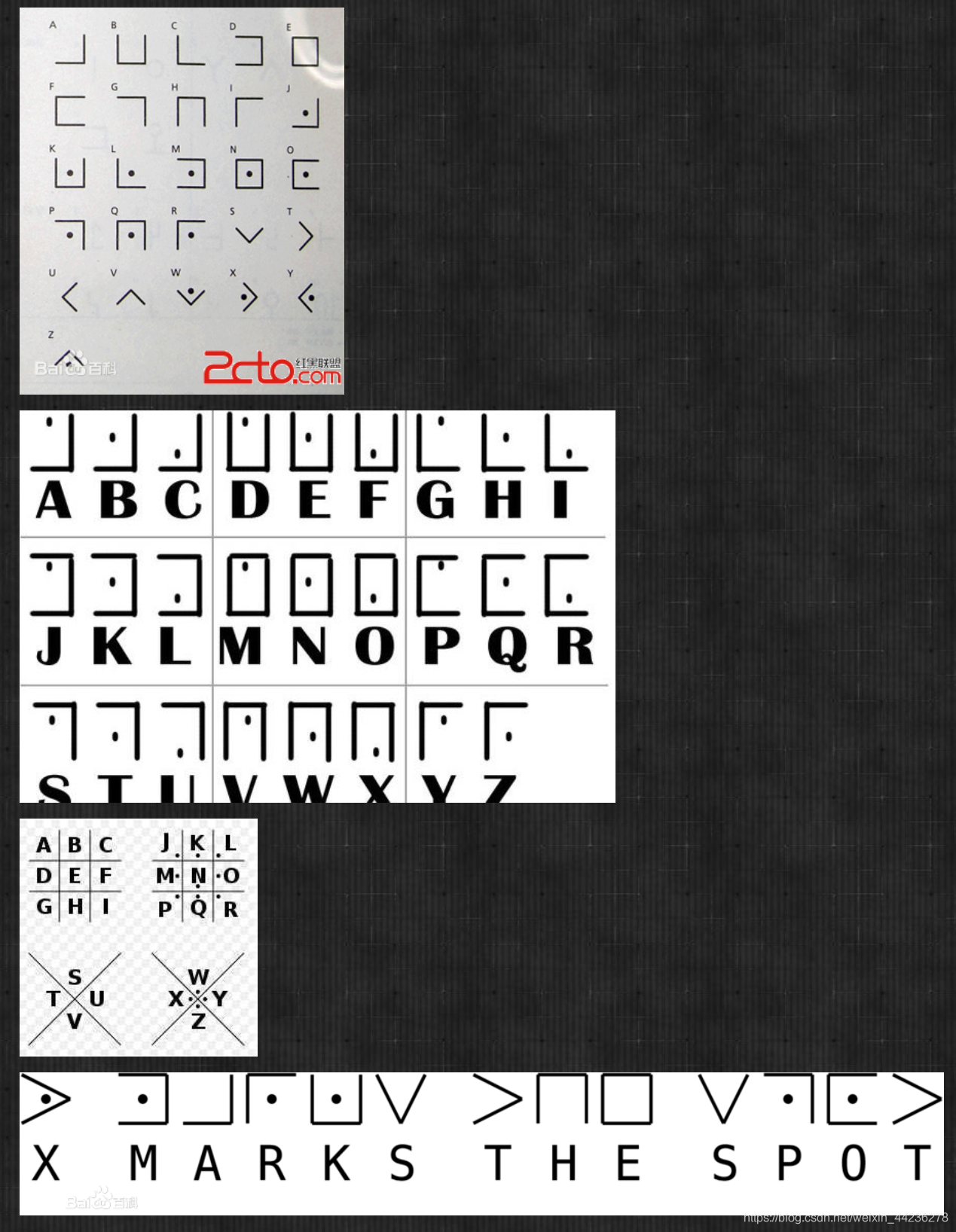
猪圈密码
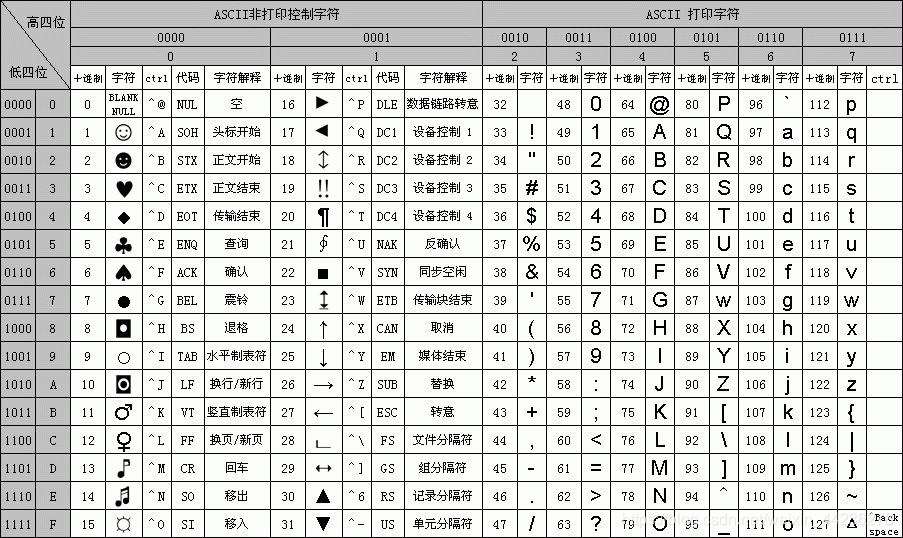
ASCII编码