一、ES的基本使用
1.创建索引
创建一个test索引http://localhost:9200/test
2.删除索引
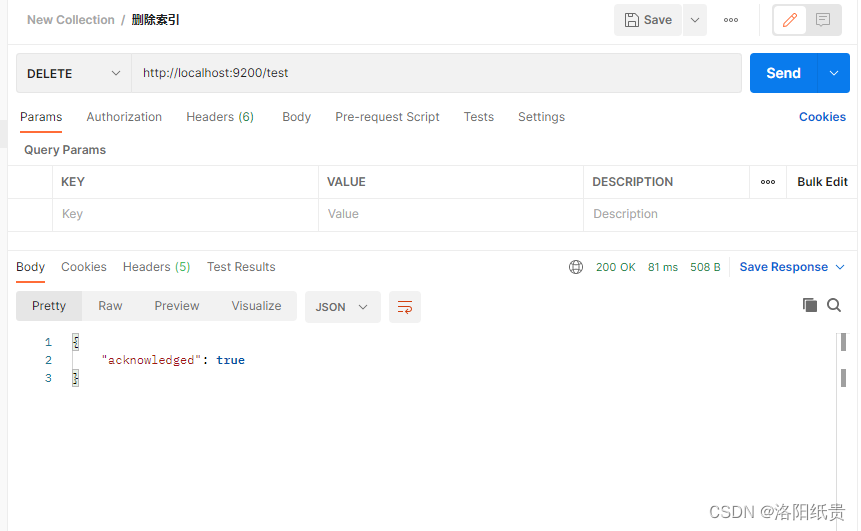
3.查看索引
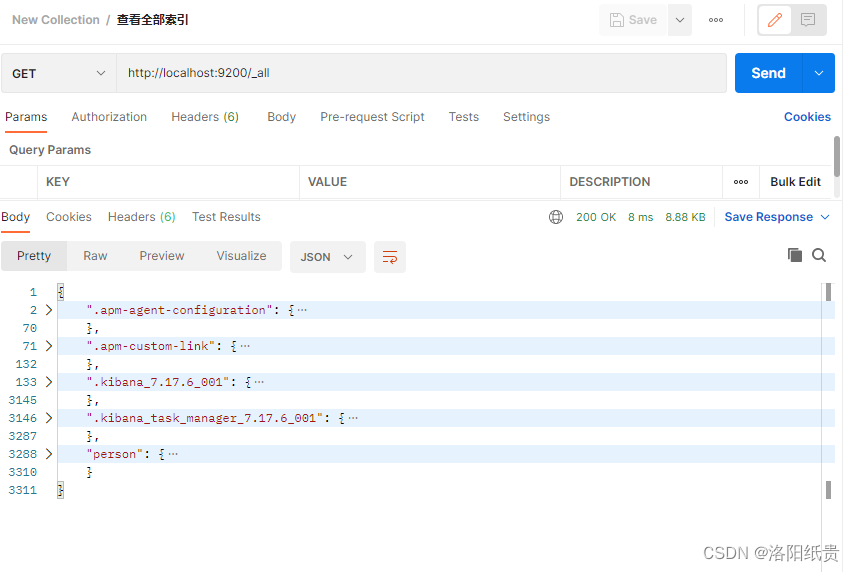
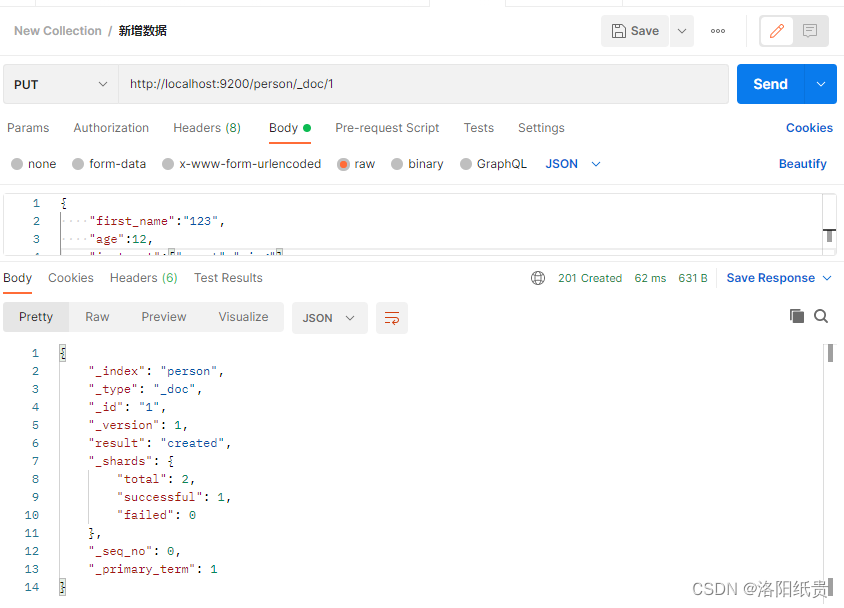
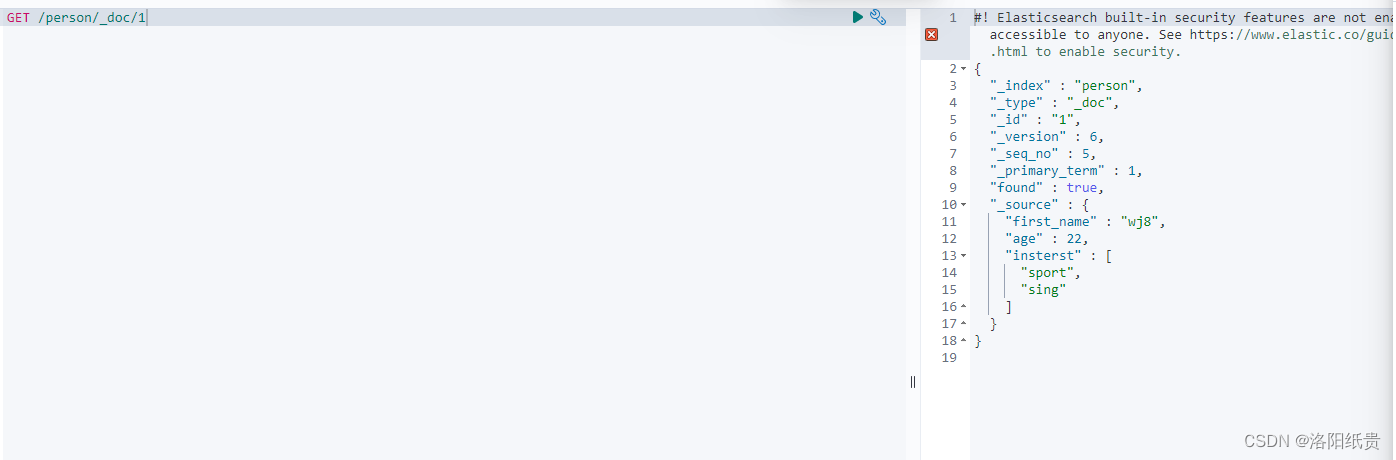
4.向索引中新增数据
http://localhost:9200/person/_doc/
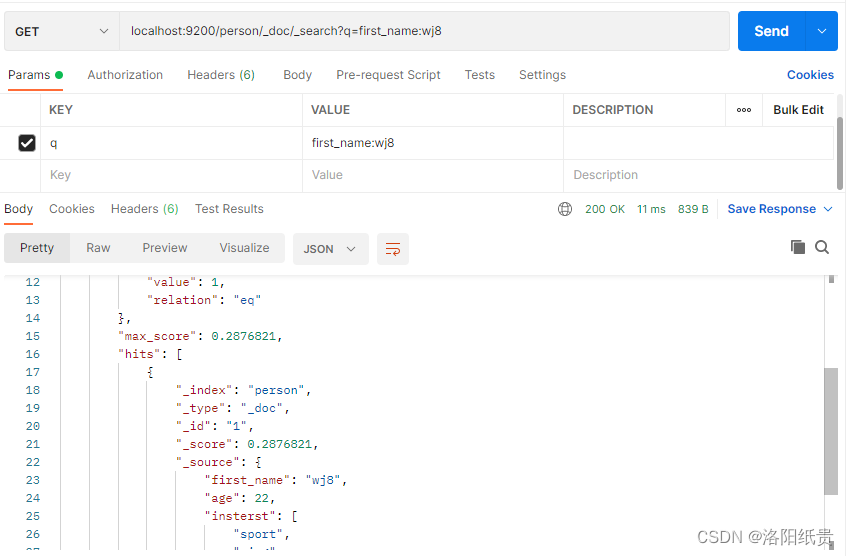
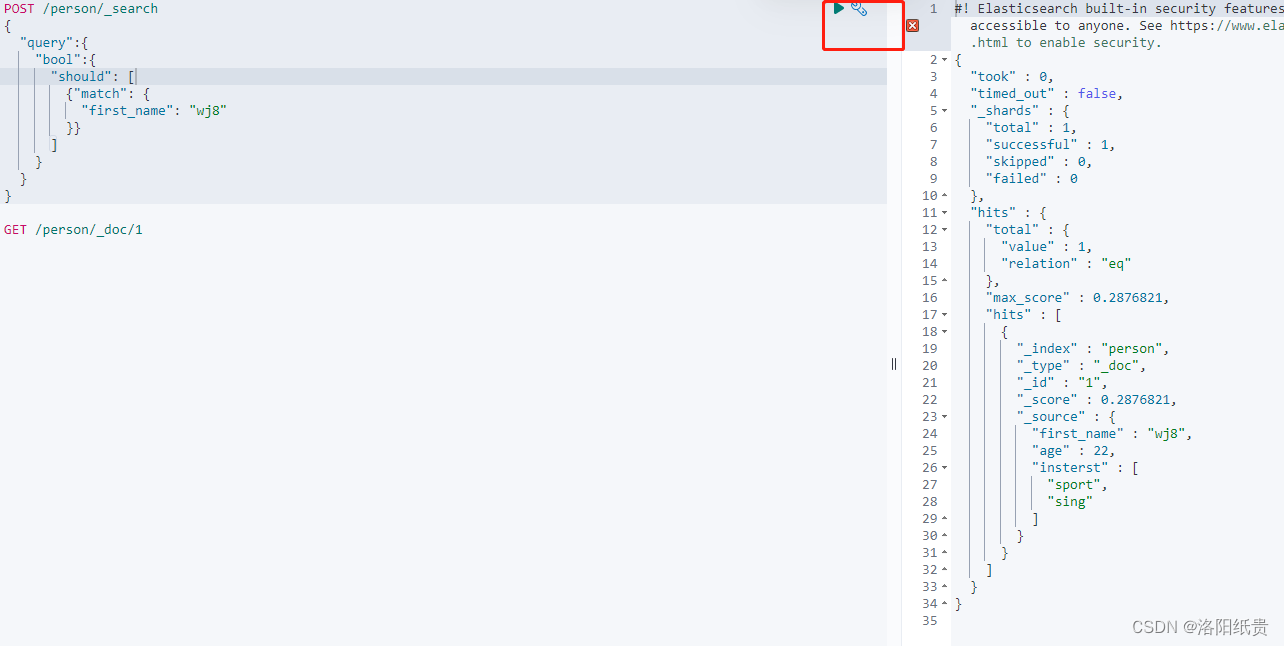
5.搜索数据
http://localhost:9200/person/_doc/_search?q=first_name:wj
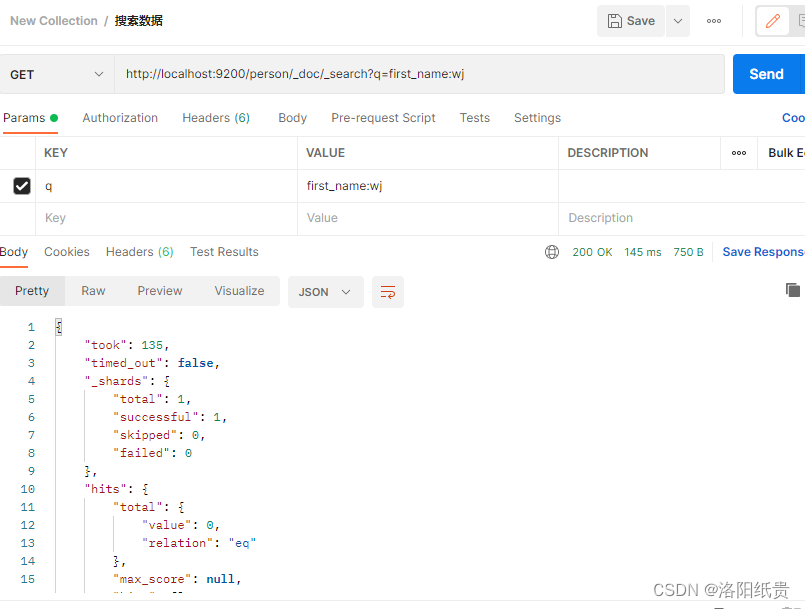
但是我并没匹配到,后面发现必须写成之前新增的wj8,
二、Kibana使用
http://localhost:5601/app/home#/
Kibana默认连接启动的ES

三、ES实现搜索的原理(待更)

Elasticsearch(非关系型数据库) ⇒ 索引(index) ⇒ 文档 (document)⇒ 字段(Fields)
一个运行的ES实例为一个节点。
四、Mysql、ES 数据同步
mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步。
常见的数据同步方案有三种:
1.同步调用

-
优点:实现简单,粗暴
-
缺点:业务耦合度高
2.异步通知
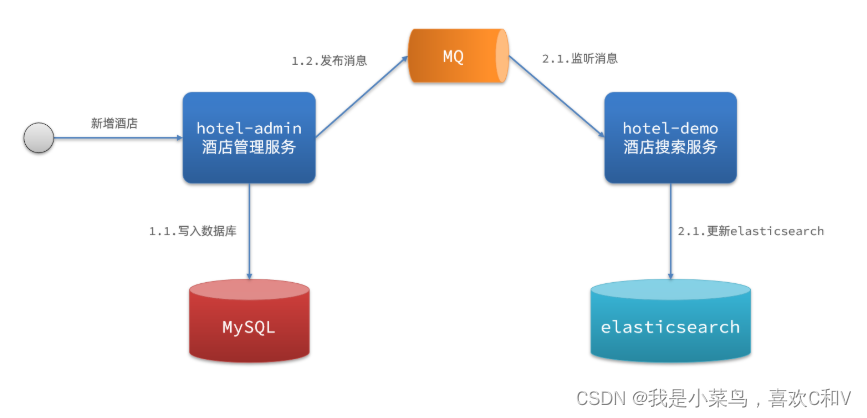
-
优点:低耦合,实现难度一般
-
缺点:依赖mq的可靠性
3.监听binlog
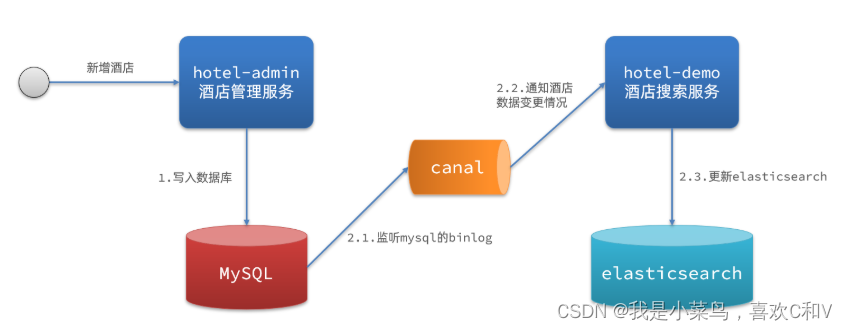
-
优点:完全解除服务间耦合
-
缺点:开启binlog增加数据库负担、实现复杂度高
转载于:ES和MYSQL实现数据同步_我是小菜鸟,喜欢C和V的博客-CSDN博客_es+mysql
其中,开源中间件binlog:
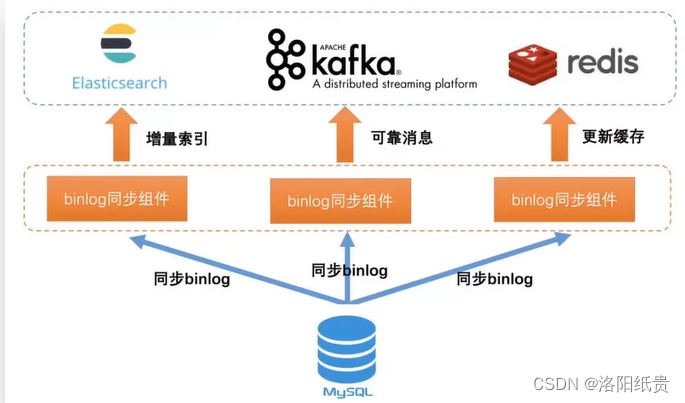
目前国内有做得比较好的,Canal,是阿里开源的binlog同步工具。可以解析binlog,并将解析后的数据同步到任何目标存储中。
还有一个,
但是,go-mysql-elasticsearch对 mysql 和 es 有版本要求
MySQL supported version < 8.0
ES supported version < 6.0其次,ES官网还有一个 logstash

Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
Logstash 是一个功能强大的工具,可与各种部署集成。 它提供了大量插件,可帮助你解析,丰富,转换和缓冲来自各种来源的数据。 如果你的数据需要 Beats 中没有的其他处理,则需要将 Logstash 添加到部署中。
下载地址:Logstash 7.17.6 | Elastic
需要连接jdbc,我引入了jar。
五、ES中文分词器
| 分词器 | 作用 |
| Standard | ES默认分词器,按单词分类并进行小写处理 |
| Simple | 按照非字母切分,然后去除非字母并进行小写处理 |
| Stop | 按照停用词过滤并进行小写处理,停用词包括the、a、is |
| Whitespace | 按照空格切分,不支持中文 |
| Language | 据说提供了30多种常见语言的分词器,不支持中文 |
| Patter | 按照正则表达式进行分词,默认是\W+ ,代表非字母 |
| Keyword | 不进行分词,作为一个整体输出 |
Standard分词器:
英文:
POST _analyze
{
"analyzer":"standard",
"text": "hello world"
}
结果:
{
"tokens" : [
{
"token" : "hello",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "world",
"start_offset" : 6,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 1
}
]
}
中文:
POST _analyze
{
"analyzer":"standard",
"text": "我是中国人"
}
结果: 拆成单个字了,不理想
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "中",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "国",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "人",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}显然中文极不友好,所以开源IK分词器,将解决这个问题。IK是当前中文支持度最好的插件。
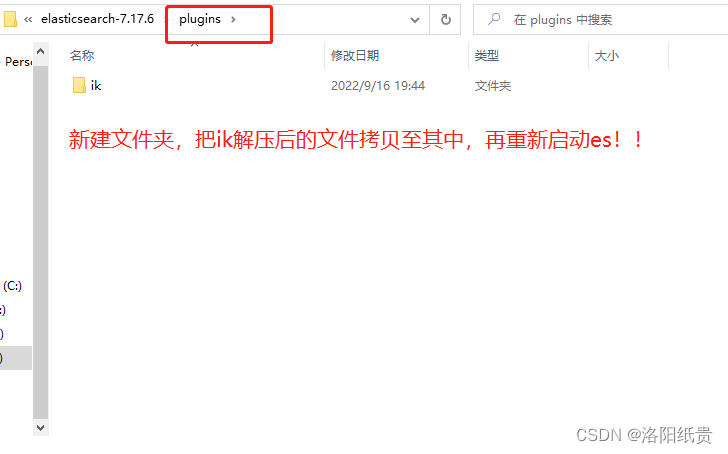
POST _analyze
{
"analyzer":"ik_smart",
"text": "我是中国人"
}
POST _analyze
{
"analyzer":"ik_max_word",
"text": "我是哪里人呢"
}
结果:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}