2022年全国研究生数学建模竞赛华为杯
B题 方形件组批优化问题
原题再现:
背景介绍
智能制造被“中国制造2025”列为主攻方向, 而个性化定制、更短的产品及系统生命周期、互联互通的服务模式等成为目前企业在智能制造转型中的主要竞争点。以离散行业中的产品为例,如电子器件、汽车、航空航天零部件等,这些产品均是依赖于机械设计、可分散加工、可灵活组装且同类产品款式极多。对于此类产品,客户可能提出的产品需求难以穷举、订单规模难以预测且产品质量要求极高。此时“个性化定制”的服务需求则要求企业具有高效快速的需求分析及产品设计能力、具有柔性且精益的生产流程、具有完整且精细的全流程生产管控能力。
方形件产品(也称板式类产品)是以板材为主要原片、通过平面加工后的几种板式配件装配而形成的一类产品。常见方形件产品制造企业,如3C(计算、通讯、消费电子)、板式家具、玻璃、钣金件等行业,多采用“多品种小批量”的个性化定制生产,由于企业订单数量庞大,生产组织通常采用“订单组批+批量生产+订单分拣”的模式,通过使用订单组批来实现批量切割,提高原材料的利用率,加工完成后再按不同客户订单进行分拣。
上述个性化定制生产模式中的订单组批与排样优化至关重要,订单组批是将不同订单组成若干批次,实现订单的批量化生产。在对小批量、多品种、大规模的订单进行组批生产时,如果组批批次太小,材料利用率低,生产效率低;如果组批批次太大,材料利用率会提高,但订单交货期得不到保证,订单分拣难度提高,生产效率降低,缓冲区容量不足而造成堵塞等,需要解决个性化与生产高效性之间的矛盾。
排样优化本质上一个下料问题(也称切割填充问题),优化的目的是合理规划方形件在板材上的布局,以减少下料过程中存在板材浪费,简化切割过程。此问题是一种计算复杂度很高的组合优化问题,也是运筹学中的一个重要分支。下料作为众多制造企业生产链中产品及零部件生产的第一道工序,消耗的材料和资源不容小视,如何提高材料利用率,降低原材料消耗,是企业减少资源和能源浪费,承担环境责任所要解决的关键问题。
问题描述
订单组批问题:在考虑订单交货期、设备产能负荷、仓储容量、材料利用率、生产效率、生产工艺约束等因素下,对生产订单进行组批优化。使具有相同材质、交货期相近、工艺相似的订单安排在同一个生产批次, 通过订单组批优化来保证交货期, 提高原材料的利用率,提高设备生产效率等。为便于统一处理数据和体现问题本质,本次赛题所有订单的交货期均相同,不做区分。批次的定义为完成若干订单全部任务且不含任何不完整订单任务的订单集合。
下料优化问题(也称排样优化问题):根据同一生产批次内方形件的尺寸与数量,选择原片的规格和数量,进行下料排样优化,最大化板材原片利用率。依据切割工序的工艺要求,排样方案必须满足“一刀切”(也称齐头切,Guillotine cut)约束(任何一次直线切割都要保证板材可分离,换言之,每次直线切割使得板材分成两块)。下料优化问题属于具有“一刀切”约束的板型材方形件排样优化问题。
考虑切割工艺的方式不同,分齐头切(guillotine cut)和非齐头切(如图1),齐头切又可以细分精确方式和非精确方式(涉及到切割的阶段数,如图2).图2中的三阶段排样方式主要有三种不同的类型:三阶段非精确(3NE)排样方式、三阶段匀质排样方式(3E)、三阶段同质排样方式(3H)。其中 3E 和 3H 排样方式可在三个阶段内切割出准确尺寸的方形件,因此都属于精确排样方式。3NE 排样方式中,部分方形件还需要额外的第四阶段切割才能得到满足规格尺寸要求。
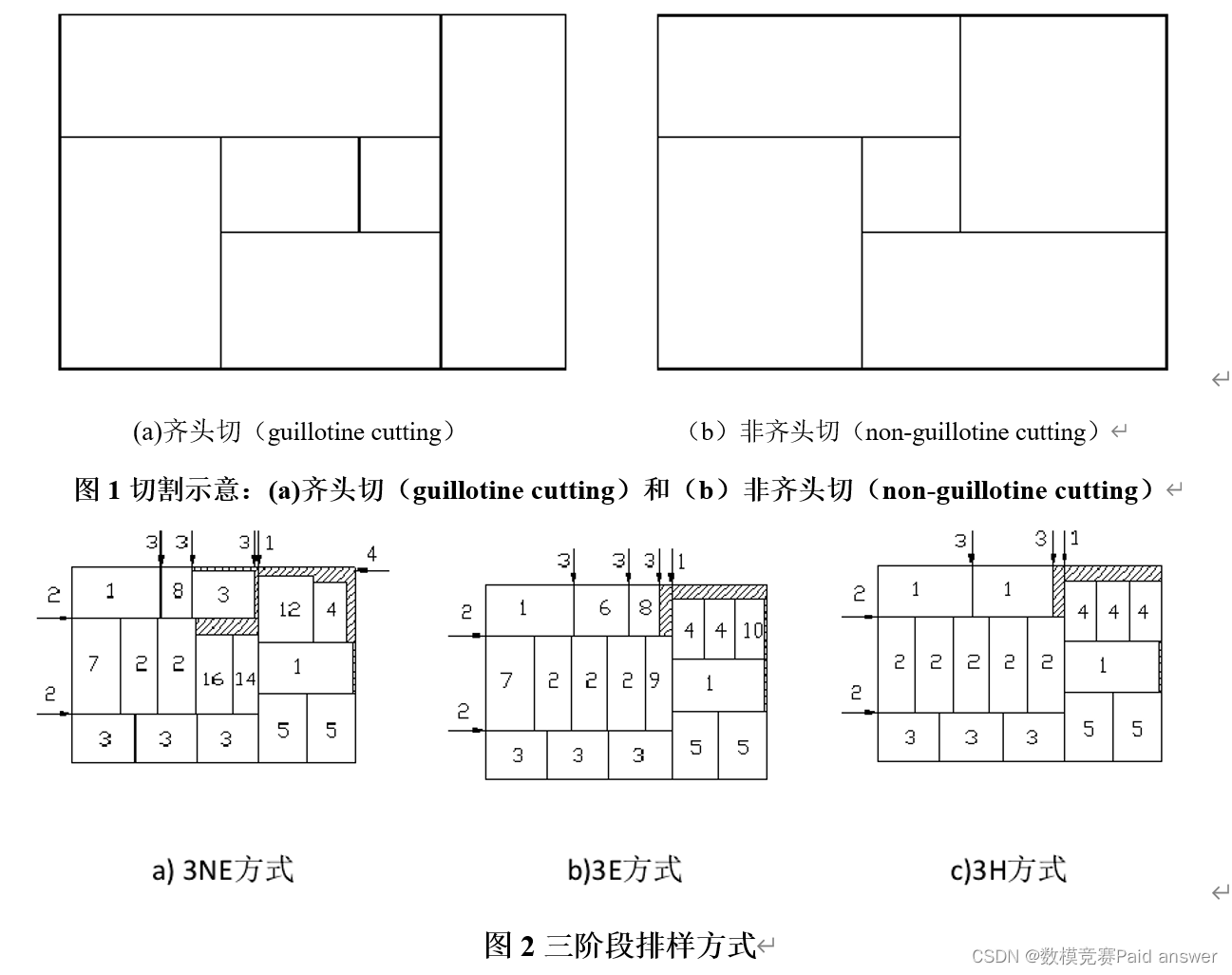
由于涉及到阶段数不同,不同文献对于切割每个阶段的称呼不一样,为了便于理解和统一表述形式,采用英文的方式形容关键阶段模块的描述,具体可参见图3(实际切割过程中,第一刀可能垂直于长边,也可能垂直于短边,图3以垂直于其中一条边为例)。
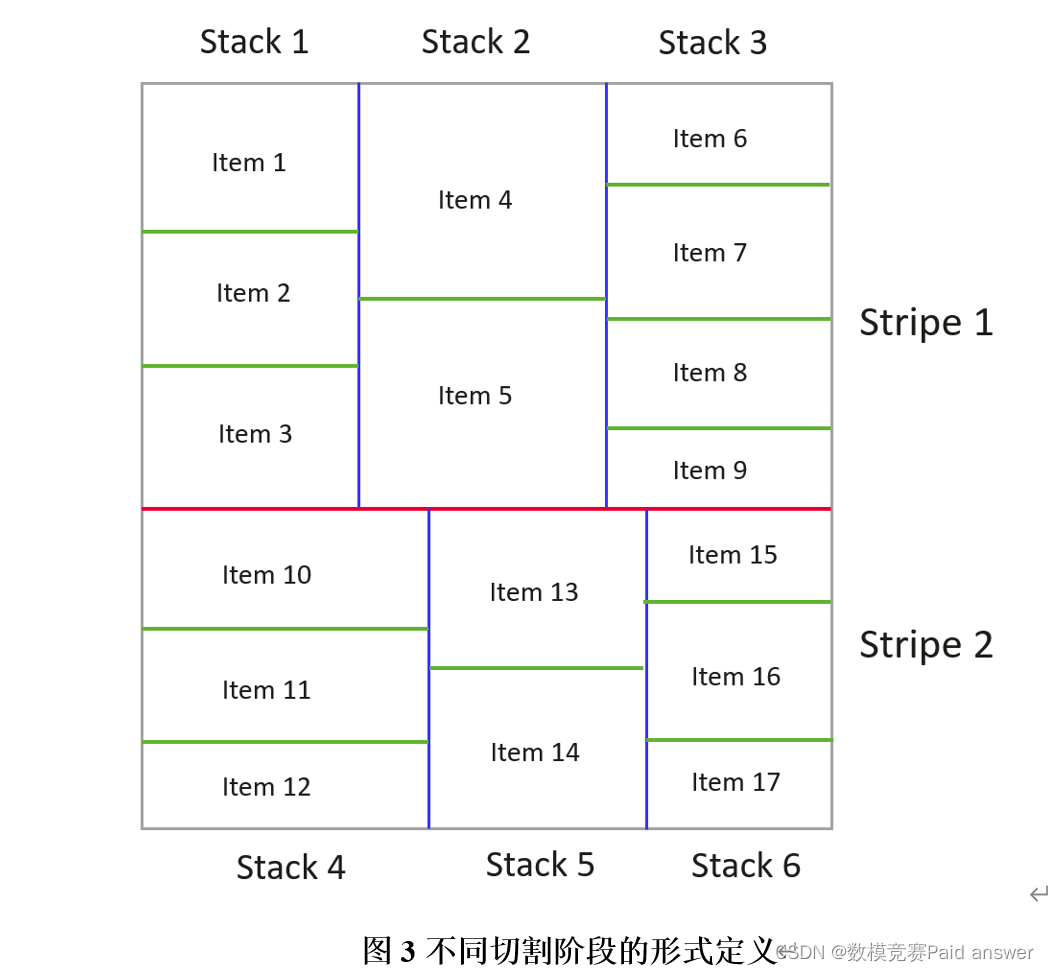
因为常见的阶段最多为3-4个,因此以3阶段的切割方式为例(如图3),第1阶段的横向切割生成模块称之为stripe(条带),如Stripe1和Strip2;第2阶段纵向切割生成模块称之为stack(栈),如Strip1继续被切割分成Stack1、Stack2和Stack3;第三阶段横向切割生成模块称之为item(产品项),如Stack1继续被切割分成Item1、Item2和Item3。
问题
本赛题由两个子问题组成,第二个子问题的约束都基于第一个子问题并与之相容,但两个子问题所提供的数据不相关。如果概念定义和过程描述与业界有所出入,皆以本赛题为准。本题假定:
1. 只考虑齐头切的切割方式(直线切割、切割方向垂直于板材一条边,并保证每次直线切割板材可分离成两块);
2. 切割阶段数不超过3,同一个阶段切割方向相同;
3. 排样方式为精确排样;
4. 假定板材原片仅有一种规格且数量充足;
5. 排样方案不用考虑锯缝宽度(即切割的缝隙宽度)影响。
子问题1:排样优化问题。要求建立混合整数规划模型,在满足生产订单需求和相关约束条件下,尽可能减少板材用量。
约束:
1. 在相同栈(stack)里的产品项(item)的宽度(或长度)应该相同;
2. 最终切割生成的产品项是完整的,非拼接而成。
本子问题要求编程,以数据集A为输入,输出结果要求见第五部分。
子问题2:订单组批问题。要求建立混合整数规划模型,对数据集B中全部的订单进行组批,然后对每个批次进行独立排样,在满足订单需求和相关约束条件下,使得板材原片的用量尽可能少。
在满足子问题1约束的基础上进一步要求:
1) 每份订单当且仅当出现在一个批次中;
2) 每个批次中的相同材质的产品项(item)才能使用同一块板材原片进行排样;
3) 为保证加工环节快速流转,每个批次产品项(item)总数不能超过限定值;
4) 因工厂产能限制,每个批次产品项(item)的面积总和不能超过限定值;
本子题要求编程,以数据集B为输入,输出结果要求见第五部分。
整体求解过程概述(摘要)
本文通过采用迭代法、K-Means 聚类分析法求解混合整数规划模型,对方形件的排布优化和组批问题进行研究。
在问题一中,将板材的切割问题视为一个项目件的堆叠问题。首先以最小原片耗材量为目标函数,建立给定约束条件的混合整数规划模型Ⅰ。规定每个项目件必须完成一次堆叠,堆叠的高度必须合理,因此设置虚拟变量α 、β、γ 、来判断 item、stack、stripe、bin 是否依次存在被包含关系,限定项目件的堆叠高度beite不应超过栈的高度,堆栈的宽度不得超过原片的宽度,条带的高度不能超过原片的高度。在在实际应用中,以 item 的高度 h 作为排样依据,放入模型Ⅰ中求得虚拟变量参数值α 、β、γ 、 。由于stack 的数值指标未知,设置调整参数 H、均值、中位数对模型进行优化,最终,发现采用高度进行排序、均值、中位数作为调整参数的模型拟合效果最好,在数据集 A 中的平均板材利用率达到了 94.06%。
在问题二中,需要考虑在订单号不可分批与板材材质存在差异的基础上,解决数据量较大时订单件有约束条件的组批问题。首先将相同的订单号放在一起,设定与材质相关的指标构建矩阵作为 K-Means 聚类的依据,同时约束单个批次产品项总数 1000件和单个批次产品面积总上限 250 平方米。通过欧氏距离和类平均距离来划分簇族,找到符合分类要求的最小类别数 K, 并不断调整超参数 max_order、min_order、K,直至找到最优可行解,完成产品项分批。将产品项分批完成后,对每一个批次中不同材质的产品项进行分组,对每一组单独采用模型Ⅰ中的排样优化方法,最终得到输出结果为 83.32%。
本文问题一中的迭代法求解代码未调用第三方库,全部自行写入封装,具有运算速度快、可修改性强的特点。本文中对方形件的订单组批以及排样优化建模求解的效果均较为稳健,对箱包问题、下料问题可提供一定指导意义,对于 PCB 电路板、板氏家具、3C 家电等领域的实际应用具有一定参考价值。
模型假设:
1. 原片规格统一且材质均匀分布,没有杂质区域;
2. 切割工艺采用齐头切方式;
3. 成品件互相独立,各产品项没有交叠[3];
4. 切割得到的产品完整,不可由拼接而成;
5. 第一刀与原片短边的水平方向平行;
6. 每一刀总与上一刀的切割方向垂直[4];
7. 最多只考虑三阶段切割;
8. 排样方式只考虑精确排样;
问题分析:
问题一的分析
问题一要求建立混合整数规划模型,对板材的排布进行优化,求得尽可能小的板材原片消耗量。为达到这一目标,我们将最小的原片耗材量视为目标函数,在充分考虑约束条件的基础上,寻找 bin(原片)、stripe(条带)、stack(栈)、item(产品项)之间存在的关系,通过解读各个切割阶段之间的具体联系,设定与之匹配的参数,从而构建与本题目标相关的方程组。采用逆推的思维方法,把原片的切割问题看成是订单件的组合问题, 将需要的订单件进行堆叠,item 组合成 stack、stack 组合成 stripe、再将 stripe 进行堆叠组合,补足部分余料后,最终构成题目所设定的原片。在确定模型以后,首先考虑使用迭代法,通过不断的输入订单需求,寻求局部最优解。
问题二的分析
在问题一的基础上,问题二增加了新的约束条件,一是关于批次项的限定条件,要求每个批次产品项数量不得大于 1000 且单个批次产品项的总面积不得大于 250 平方米,二是给出订单号和材质作为批次的划分依据,要求同一份订单不能被拆分为不同批次,且每个订单的材质可能存在差异。这要求我们先将订单按照约束条件进行分类,再对分类后的各个批次单独进行排样优化。若将排样优化视为一个主问题,则组批问题可视为一个三阶段排样的子问题。面对订单的组批问题[1],我们考虑先将产品件按订单号归为一类,再进行有约束条件的K-Means 聚类,在 K-Means 聚类的过程中,为了使板材原片的利用率较高,要尽可能使相同材质的在同一组批中。完成聚类后,将每一类归为一个批次,对每个批次中不同材质的产品项采用问题一中的混合整数规划模型进行迭代,最终求出每个批次的近似解[2]。
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:
部分Python程序如下:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import time
import pandas as pd
from demo import Cycle_solution_A
# 衡量指标
def metrics(data, number, max_length, max_width):
"""
:parameter
data:[[序号:index, 订单 id:item_id, 订单材料:item_material, 订单所需要数
量:item_num, 材料长度:item_length, 材料宽度:item_width, 订单号:item_order]*size]
number:消耗的总板材
max_length:板材长
max_width:板材宽
"""
total_item = 0.
for vector in data:
total_item += vector[4] * vector[5]
run_rate = total_item / (number*max_length*max_width)
return run_rate
# 问题一
# 加载数据
file_A = []
for i in range(1, 5):
file_path = os.path.join(r"E:\python document\challenge\2022 年 B 题\子问题 1-数
据集 A", "dataA"+str(i)+".csv")
if os.path.exists(file_path):
file_A.append(pd.read_csv(file_path))
data_A_lis = []
avg_length = []
for i in file_A:
avg_length.append(i['item_length'].mean())
j = i.sort_values(by='item_length', ascending=False)
j = j.values.tolist()
data_A_lis.append(j)
# [序号:index, 订单 id:item_id, 订单材料:item_material, 订单所需要数量:item_num,
材料长度:item_length, 材料宽度:item_width, 订单号:item_order]
print(data_A_lis)
# 参数
max_length = 2440
max_width = 1220
path = r"E:\python document\challenge\2022 年 B 题\solution_A"
f_txt = open(r"E:\python document\challenge\2022 年 B 题\solution_A\min_n.txt", "w")
# 求解
min_n_data_A = []
rate_A_lis = []
run_time_lis = []
_time = time.time()
for A_index, data_set in enumerate(data_A_lis):
data_size = len(data_set)
paths = os.path.join(path, "A{0}".format(A_index+1))
solution = Cycle_solution_A(data_size, paths, avg_length[A_index], max_length,
max_width)
min_n, cut_program = solution.cycle_com(data_set)
cut_program.to_csv(r"E:\python document\challenge\2022 年 B 题
\solution_A\A{
0}\data_A{
0}_cut_program.csv".format(A_index+1), index=None,
encoding='utf_8_sig')
rate = metrics(data_set, min_n, max_length, max_width)
run_time_lis.append(time.time() - _time)
min_n_data_A.append(min_n)
rate_A_lis.append(rate)
print("data_A{0}:finish".format(A_index+1))
f_txt.write("min_n_data_A:" + "\n")
f_txt.write(str(min_n_data_A) + "\n" + "\n")
f_txt.write("rate_A_lis:" + "\n")
f_txt.write(str(rate_A_lis) + "\n" + "\n")
f_txt.write("run_time:" + "\n")
f_txt.write(str(run_time_lis) + "\n" + "\n")
print(min_n_data_A)
print(rate_A_lis)
class Cycle_solution_A():
def __init__(self, data_size, path, average_length, max_length=2440,
max_width=1220):
self.max_length = max_length
self.path = path
self.average_length = average_length
self.max_width = max_width
self.data_size = data_size
# alpha、beta、gamma 的定义
self.alpha = []
self.beta = []
self.gamma = []
for j in range(data_size):
self.alpha.append([0 if j > i else 1 for i in range(data_size)])
for j in range(data_size):
self.beta.append([0 if j > i else 1 for i in range(data_size)])
for j in range(data_size):
self.gamma.append([0 if j > i else 1 for i in range(data_size)])
def cycle_com(self, data):
"""
:parameter
data:[[序号:index, 订单 id:item_id, 订单材料:item_material, 订单所需要
数 量 :item_num, 材 料 长 度 :item_length, 材料宽度 :item_width, 订 单
号:item_order]*size]
"""
stack_lis, info_stack_lis, alpha = self.item_into_stack(data, self.alpha)
stripe_lis, stripe_index_lis, info_stripe_lis, beta =
self.stack_into_stripe(stack_lis, info_stack_lis, self.beta)
bin_lis, bin_lis_index, info_bin_lis, gamma = self.stripe_into_bin(stripe_lis,
info_stripe_lis, self.gamma)
file = self.picture(data, stack_lis, info_stack_lis, stripe_lis, info_stripe_lis,
bin_lis)
min_number = 0
for index, i in enumerate(gamma):
min_number += i[index]
return min_number, file
def item_into_stack(self, data, alpha):
# 构造出 stack stak:[list1, list2,....],list 的第一个元素为 stack 的计算标号
stack_lis = []
for item_index, item in enumerate(data):
if len(stack_lis) == 0:
stack_lis.append([item_index+1])
else:
for index, i in enumerate(stack_lis):
if data[i[0] - 1][5] == item[5]:
stack_length = 0
for j in i:
stack_length += data[j-1][4]
if stack_length + item[4] <= self.average_length:
stack_lis[index].append(item_index+1)
else:
# 转换 h 和 w
# if data[i[0] - 1][5] == item[4]:
# data[item_index][4], data[item_index][5] =
data[item_index][5], data[item_index][4]
# if stack_length + item[4] <=
self.average_length:
# stack_lis[index].append(item_index + 1)
# else:
# stack_lis.append([item_index+1])
stack_lis.append([item_index+1])
break
else:
continue
sum = 0
for i in stack_lis:
for j in i:
if item_index + 1 == j:
sum += 1
if sum == 0:
stack_lis.append([item_index + 1])
# 处理 alpha
for vector in stack_lis:
# 计算序号变为 python 序号
set_vector = []
for number in vector:
set_vector.append(number - 1)
cycle_set = list(set(range(self.data_size)) - set(set_vector))
for j in cycle_set:
alpha[vector[0] - 1][j] = 0
if len(vector) > 1:
for j in vector[1:]:
for k in range(self.data_size):
alpha[j - 1][k] = 0
# 输出 stack 的高度和宽度信息(先高后宽)
info_stack = [[],[]]
for i in stack_lis:
stack_length = 0
for j in i:
stack_length += data[j - 1][4]
info_stack[0].append(stack_length)
info_stack[1].append(data[i[0] - 1][5])
return stack_lis, info_stack, alpha
def stack_into_stripe(self, stack, info_stack, beta):
# 先对 stack 做一次排序
stack_length = info_stack[0]
stack_width = info_stack[1]
sort_stack = []
for index, i in enumerate(stack_width):
sort_stack.append([stack_length[index], i, stack[index]])
# 排序
n = len(sort_stack)
for i in range(n):
min = i
for j in range(i+1, n):
if sort_stack[j][0] < sort_stack[min][0]:
min = j
sort_stack[min], sort_stack[i] = sort_stack[i], sort_stack[min]
sort_stack = sort_stack[::-1]
# 分出数据
finish_sort_stack = []
sort_info_stack = []
for i in sort_stack:
sort_info_stack.append([i[0], i[1]])
finish_sort_stack.append(i[2])
# 构造出 stripe, stripe:[[number,element1, element2, ....], .....],number 为其
序号,element 为包含的 stack 序号
stripe_lis = []
for item_index, item in enumerate(finish_sort_stack):
if len(stripe_lis) == 0:
stripe_lis.append([item_index])
else:
for i_index, i in enumerate(stripe_lis):
stripe_width = 0
for j in i:
stripe_width += sort_info_stack[j][1]
if stripe_width + sort_info_stack[item_index][1] <=
self.max_width:
stripe_lis[i_index].append(item_index)
break
else:
continue
sum = 0
for i in stripe_lis:
for j in i:
if item_index == j:
sum += 1
if sum == 0:
stripe_lis.append([item_index])
# 输出 stripe 的宽度信息
info_stripe = []
max_length_index = []
for v_index, vector in enumerate(stripe_lis):
stripe_width = 0
stripe_length = []
for j_index, j in enumerate(vector):
stripe_length.append(sort_info_stack[j][0])
stripe_width += sort_info_stack[j][1]
info_stripe.append([max(stripe_length), stripe_width])
max_length_index.append(stripe_length.index(max(stripe_length)))
# 将 stripe 做序号转变
true_stripe_lis = []
for v_index, vector in enumerate(stripe_lis):
max_index = max_length_index[v_index]
true_stripe_lis.append([finish_sort_stack[vector[max_index]][0]])
for j_index, j in enumerate(vector):
true_stripe_lis[v_index].append(finish_sort_stack[j][0])
# 处理 beta
first_vector = []
for vector in true_stripe_lis:
# 计算序号变为 python 序号
first_vector.append(vector[0]-1)
set_vector = []
for number in vector[1:]:
set_vector.append(number - 1)
cycle_set = list(set(range(self.data_size)) - set(set_vector))
for j in cycle_set:
beta[vector[0] - 1][j] = 0
zero_lis = list(set(range(self.data_size)) - set(first_vector))
for i in zero_lis:
for j in range(self.data_size):
beta[i][j] = 0
return true_stripe_lis, stripe_lis, info_stripe, beta
def stripe_into_bin(self, stripe, info_stripe, gamma):
# 先对 stack 做一次排序
sort_stripe = []
for index, i in enumerate(stripe):
sort_stripe.append([info_stripe[index][0], info_stripe[index][1], i])
# 排序
n = len(sort_stripe)
for i in range(n):
min = i
for j in range(i + 1, n):
if sort_stripe[j][0] < sort_stripe[min][0]:
min = j
sort_stripe[min], sort_stripe[i] = sort_stripe[i], sort_stripe[min]
sort_stripe = sort_stripe[::-1]
# 分出数据
finish_sort_stripe = []
sort_info_stripe = []
for i in sort_stripe:
sort_info_stripe.append([i[0], i[1]])
finish_sort_stripe.append(i[2])
# 构造出 bin, bin:[[number,element1, element2, ....], .....],number 为其序
号,element 为包含的 bin 序号
bin_lis = []
for item_index, item in enumerate(finish_sort_stripe):
if len(bin_lis) == 0:
bin_lis.append([item_index])
else:
for i_index, i in enumerate(bin_lis):
bin_length = 0
for j in i:
bin_length += sort_info_stripe[j][0]
if bin_length + sort_info_stripe[item_index][0] <=
self.max_length:
bin_lis[i_index].append(item_index)
break
else:
continue
sum = 0
for i in bin_lis:
for j in i:
if item_index == j:
sum += 1
if sum == 0:
bin_lis.append([item_index])
# 输出 bin 的高宽信息
info_bin = []
max_length_index = []
for v_index, vector in enumerate(bin_lis):
bin_width = []
bin_length = 0
for j_index, j in enumerate(vector):
bin_width.append(sort_info_stripe[j][1])
bin_length += sort_info_stripe[j][0]
info_bin.append([bin_length, max(bin_width)])
max_length_index.append(bin_width.index(max(bin_width)))
# 将 bin 做序号转变
true_bin_lis = []
for v_index, vector in enumerate(bin_lis):
true_bin_lis.append([finish_sort_stripe[vector[max_length_index[v_index]]][0]])
for j_index, j in enumerate(vector):
true_bin_lis[v_index].append(finish_sort_stripe[j][0])
# 处理 gamma
first_vector = []
for vector in true_bin_lis:
# 计算序号变为 python 序号
first_vector.append(vector[0] - 1)
set_vector = []
for number in vector[1:]:
set_vector.append(number - 1)
cycle_set = list(set(range(self.data_size)) - set(set_vector))
for j in cycle_set:
gamma[vector[0] - 1][j] = 0
zero_lis = list(set(range(self.data_size)) - set(first_vector))
for i in zero_lis:
for j in range(self.data_size):
gamma[i][j] = 0
return true_bin_lis, bin_lis, info_bin, gamma
def picture(self, data, stack_lis, info_stack_lis, stripe_lis, info_stripe_lis, bin_lis):
# 找出每个 bin 所含的订单 id
# 制作 bin、stripe、stack 的高宽信息字典
info_stack_dict = {
}
for stack_index, stack_i in enumerate(stack_lis):
info_stack_dict[stack_i[0]] = [info_stack_lis[0][stack_index],
info_stack_lis[1][stack_index]]
info_stripe_dict = {
}
for stripe_index, stripe_i in enumerate(stripe_lis):
info_stripe_dict[stripe_i[0]] = info_stripe_lis[stripe_index]
stripe_dict = {
}
for v_index, vector in enumerate(stripe_lis):
tem in enumerate(stack):
all_bin_lis[b_index][sp_index + 1][sc_index + 1][it_index]
= [item, stack_dict.get(item)]
# 制作 cut_program.csv 表
# 小心计算序号是 1 到 n,引用序号要变成 0 到 n-1
# [材质, bin_index, item_index, 起点 x 坐标, 起点 y 坐标, x 方向长度(width),
y 方向长度(length)]
cut_program_lis = []
for bin_index, bin in enumerate(all_bin_lis):
# 整个图
fig, ax = plt.subplots()
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.plot([0, 1220], [0, 0], color="k", linewidth=2.5)
ax.plot([1220, 1220], [0, 2440], color="k", linewidth=2.5)
ax.plot([0, 0], [0, 2440], color="k", linewidth=2.5)
ax.plot([0, 1220], [2440, 2440], color="k", linewidth=2.5)
# stripe 的直线位置
total_stripe_length = 0.
for stripe_index, stripe in enumerate(bin[1:]):
stripe_length, stripe_width = info_stripe_dict.get(stripe[0])[0],
info_stripe_dict.get(stripe[0])[1]
total_stripe_length += stripe_length
ax.plot([0, 1220], [total_stripe_length, total_stripe_length], color="k",
linewidth=2)
# stack 的竖线位置
total_stack_width = 0.
for stack_index, stack in enumerate(*stripe[1:]):
stack_length, stack_width = info_stack_dict.get(stack[0])[0],
info_stack_dict.get(stack[0])[1]
total_stack_width += stack_width
ax.plot([total_stack_width, total_stack_width],
[total_stripe_length - stripe_length, total_stripe_length], color="g", linewidth=1.5)
# item 的位置
total_item_length = 0.
for item_index, item in enumerate(*stack[1:]):
item_length, item_width = data[item - 1][4], data[item - 1][5]
total_item_length += item_length
cut_program_lis.append([data[item - 1][2], bin[0], data[item - 1][1],
total_stack_width - stack_width, total_item_length - item_length + total_stripe_length -
stripe_length, stack_width, item_length])
ax.plot([total_stack_width - stack_width, total_stack_width],
[total_item_length + total_stripe_length - stripe_length, total_item_length+
total_stripe_length - stripe_length], color="y", linewidth=1)
adjust_text([ax.text(x=(total_stack_width - stack_width +
total_stack_width) / 2, y= (total_item_length - 3*item_length/10) + total_stripe_length -
stripe_length , rotation=60, s="id:{0}".format(data[item - 1][1]), ha="left")])
ax.fill_between([total_stack_width - stack_width, total_stack_width],
total_item_length + total_stripe_length - stripe_length, stripe_length + total_stripe_length
- stripe_length, facecolor='dimgray', alpha=1)
ax.fill_between([total_stack_width, 1220], total_stripe_length - stripe_length,
total_stripe_length, facecolor='dimgray', alpha=1)
ax.fill_between([0, 1220], total_stripe_length, 2440, facecolor='dimgray', alpha=1)
paths = os.path.join(self.path, "cutting_pic{0}.jpg".format(bin[0]))
plt.savefig(paths)
plt.close()
cut_program = pd.DataFrame(cut_program_lis)
cut_program.columns = ['原片材质', '原片序号', '产品 id', '产品 x 坐标', '产品 y 坐标', '
产品 x 方向长度', '产品 y 方向长度']
return cut_program