用const 修饰函数的参数
如果参数作输出用,不论它是什么数据类型,也不论它采用“指针传递”还是“引用传递”,都不能加const 修饰,否则该参数将失去输出功能。const 只能修饰输入参数:
- 如果输入参数采用“指针传递”,那么加const 修饰可以防止意外地改动该指针,起到保护作用。
- 如果输入参数采用“值传递”,由于函数将自动产生临时变量用于复制该参数,该输入参数本来就无需保护,所以不要加const 修饰。例如不要将函数void Func1(int x) 写成void Func1(const int x)。同理不要将函数void Func2(A a) 写成void Func2(const A a)。其中A 为用户自定义的数据类型。
- 对于非内部数据类型的参数而言,象void Func(A a) 这样声明的函数注定效率比较底。因为函数体内将产生A 类型的临时对象用于复制参数a,而临时对象的构造、复制、析构过程都将消耗时间。为了提高效率,可以将函数声明改为void Func(A &a),因为“引用传递”仅借用一下参数的别名而已,不需要产生临时对象。但是函数void Func(A &a) 存在一个缺点:“引用传递”有可能改变参数a,这是我们不期望的。解决这个问题很容易,加const修饰即可,因此函数最终成为void Func(const A &a)。
- 以此类推,是否应将void Func(int x) 改写为void Func(const int &x),以便提高效率?完全没有必要,因为内部数据类型的参数不存在构造、析构的过程,而复制也非常快,“值传递”和“引用传递”的效率几乎相当。
总结如下:
- 对于非内部数据类型的输入参数,应该将“值传递”的方式改为“const 引用传递”,目的是提高效率。例如将void Func(A a) 改为void Func(const A &a)。
- 对于内部数据类型的输入参数,不要将“值传递”的方式改为“const 引用传递”。否则既达不到提高效率的目的,又降低了函数的可理解性。例如void Func(int x) 不应该改为void Func(const int &x)。
用const 修饰函数的返回值
- 如果给以“指针传递”方式的函数返回值加const 修饰,那么函数返回值(即指针)的内容不能被修改,该返回值只能被赋给加const 修饰的同类型指针。
- const 成员函数任何不会修改数据成员的函数都应该声明为const 类型。如果在编写const 成员函数时,不慎修改了数据成员,或者调用了其它非const 成员函数,编译器将指出错误,这无疑会提高程序的健壮性。
- 关于Const函数的几点规则:
a. const对象只能访问const成员函数,而非const对象可以访问任意的成员函数,包括const成员函数.
b. const对象的成员是不可修改的,然而const对象通过指针维护的对象却是可以修改的.
c. const成员函数不可以修改对象的数据,不管对象是否具有const性质.它在编译时,以是否修改成员数据为依据,进行检查.
加上mutable修饰符的数据成员,对于任何情况下通过任何手段都可修改,自然此时的const成员函数是可以修改它的
explict关键字
- 指定构造函数或转换函数 (C++11起)为显式, 即它不能用于隐式转换和复制初始化.
- explicit 指定符可以与常量表达式一同使用. 函数若且唯若该常量表达式求值为 true 才为显式. (C++20起)
- 构造函数被explicit修饰后, 就不能再被隐式调用了.
构造函数=delete或者default
=delete表示删除默认构造函数=default表示默认构造函数
std::optional
std::optional<T>类型的变量要么是一个T类型的变量,要么是一个表示“什么都没有”的状态。
https://blog.csdn.net/yuejisuo1948/article/details/118440275
std::make_optional
std::make_optional
定义于头文件 <optional>
template< class T >
constexpr std::optional<std::decay_t<T>> make_optional( T&& value ); (1) (C++17 起)
template< class T, class... Args >
constexpr std::optional<T> make_optional( Args&&... args ); (2) (C++17 起)
template< class T, class U, class... Args >
constexpr std::optional<T> make_optional( std::initializer_list<U> il, Args&&... args ); (3) (C++17 起)
- 从value 创建 optional 对象。等效地调用 std::optional<std::decay_t>(std::forward(value)) 。
- 从 args… 创建原位构造的 optional 对象。等价于 return std::optional(std::in_place, std::forward(args)…); 。
- 从 il 和 args… 创建原位构造的 optional 对象。等价于 return std::optional(std::in_place, il, std::forward(args)…); 。
std::move()
std::move并不能移动任何东西,它唯一的功能是将一个左值强制转化为右值引用,继而可以通过右值引用使用该值,以用于移动语义。
try_emplace()
由于std::map中,元素的key是唯一的,我们经常遇到这样的场景,向map中插入元素时,先检测map指定的key是否存在,不存在时才做插入操作,如果存在,直接取出来使用,或者key不存在时,做插入操作,存在时做更新操作。
通用的做法,可以直接用emplace操作,判断指定的key是否存在,如果不存在,则插入元素,当元素存在的时候,emplace依然会构造一次带待插入元素,判断不需要插入后,将该元素析构,这样导致的后果是,产生了多余的构造和析构操作。
鉴于此,C++17引入了std::try_emplace,在参数列表中,把key和value分开,该方法会检测指定的key是否存在,如果存在,什么也不做,不存在,则插入相应的value。
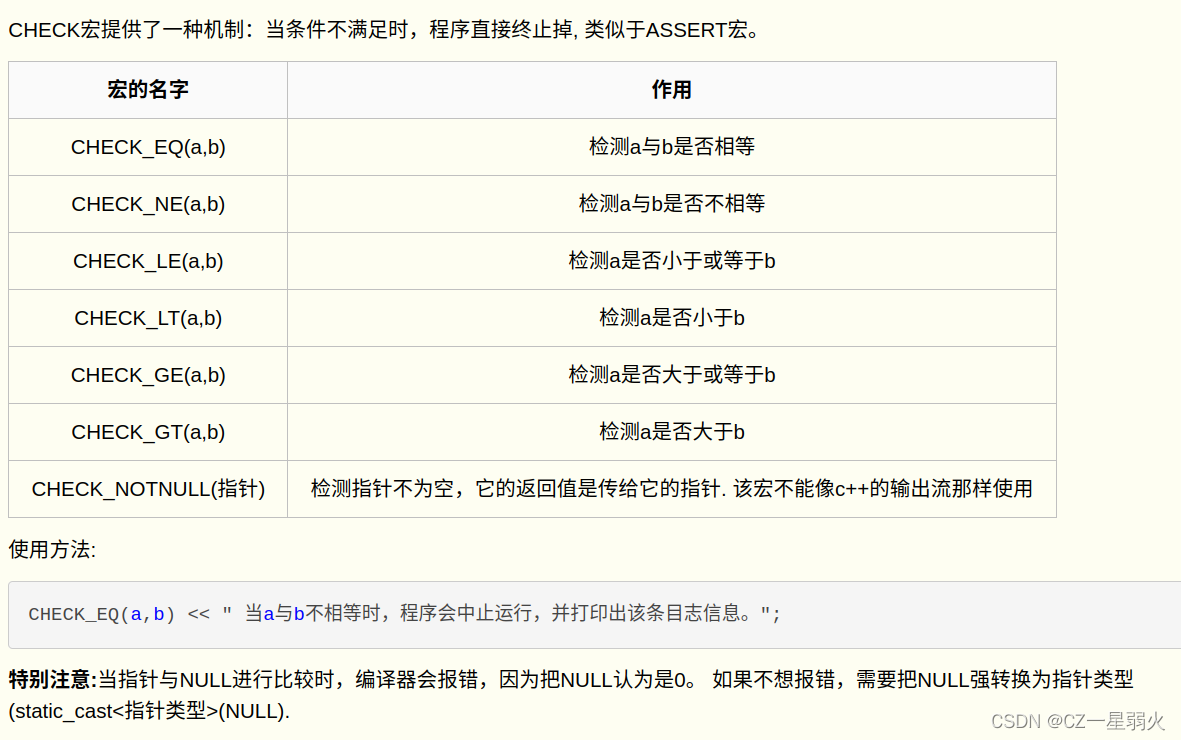
CHECK宏与Debug宏(DCHECK宏)
- DCHECK
- DCHECK_GE
- DCHECK_GT
- DCHECK_LE
- DCHECK_LT
参考:
https://www.cnblogs.com/yinheyi/p/12243832.html
https://www.cnblogs.com/DesignLife/p/16918862.html
mutable关键字
mutable是为了突破const的限制而设置的。被mutable修饰的变量,将永远处于可变的状态,即使在一个const函数中.
std::generate()
以给定函数对象 g 所生成的值赋值范围 [first, last) 中的每个元素。
void generate( ForwardIt first, ForwardIt last, Generator g );
https://zhuanlan.zhihu.com/p/597486495
constexpr用法
const 与 constexpr 变量之间的主要 difference(区别)是,const 变量的初始化可以推迟到运行时进行。 constexpr 变量必须在编译时进行初始化。 所有的 constexpr 变量都是 const。
https://learn.microsoft.com/zh-CN/cpp/cpp/constexpr-cpp?view=msvc-140
enum class
enum class Color{
black,white,red}; //black、white、red作用域仅在大括号内生效
auto white = false; //正确,这个white并不是Color中的white
Color c = white; //错误,在作用域范围内没有white这个枚举量
Color c = Color::white; //正确
auto c = Color::white; //正确
https://blog.csdn.net/weixin_42817477/article/details/109029172
std::remove_if
c.erase(std::remove_if(t.begin(),t.end(),lambda判断函数),e):可实现将t中满足条件的元素全部删掉
如:
trimmers_.erase(
std::remove_if(trimmers_.begin(), trimmers_.end(),
[](std::unique_ptr<PoseGraphTrimmer>& trimmer) {
return trimmer->IsFinished();
}),
trimmers_.end());
remove_if的参数是迭代器,前两个参数表示迭代的起始位置和这个起始位置所对应的停止位置。最后一个参数:传入一个回调函数,如果回调函数返回为真,则将当前所指向的参数移到尾部。返回值是 被移动区域的首个元素
https://zhuanlan.zhihu.com/p/141177036
运算符重载
混淆解决方案eval()
在eigen中,不能使用a=a.transpose();这样的写法!在原本的内存地址上直接操作会导致读写冲突!可以用a=a.transpose().eval();来解决这个问题。
eval()能够用临时变量来解决左右变量内存地址相同时产生的混淆问题。
C++ std::vector::resize()
C++ 11:
void resize (size_type n); void resize (size_type n, const value_type& val);
C++ 98:
void resize (size_type n, value_type val = value_type());
- 如果n小于当前容器的大小,则将内容减少到其前n个元素,并删除超出范围的元素(并销毁它们)。
- 如果n大于当前容器的大小,则通过在末尾插入所需数量的元素来扩展内容,以达到n的大小。如果指定了val,则将新元素初始化为val的副本,否则将对它们进行值初始化。
- 如果n也大于当前容器容量,将自动重新分配已分配的存储空间。
std::is_arithmetic
功能:如果 T 是算术类型(即整数类型或浮点类型)或其 cv 限定版本(cv-qualified version thereof),则提供等于 true 的成员常量值。 对于任何其他类型,值为 false。
https://blog.csdn.net/BIT_HXZ/article/details/124246675
vector的reserve方法
reserve的作用是更改vector的容量(capacity),使vector至少可以容纳n个元素。
如果n大于vector当前的容量,reserve会对vector进行扩容。其他情况下都不会重新分配vector的存储空间
std::get
std::get除了通过索引(C++11)获取std::tuple的元素,还能通过元素类型获取元素(C++14)
https://blog.csdn.net/luoshabugui/article/details/118681579
std::isfinite
检查具有有限值,即它是正规的、次正规的或零的,但不是无限的或null的。
std::optional -->value_or
value_or 要么返回存储在可选项中的值,要么在没有存储的情况下返回参数。
This lets you take the maybe-null optional and give a default behavior when you actually need a value. By doing it this way, the “default behavior” decision can be pushed back to the point where it is best made and immediately needed, instead of generating some default value deep in the guts of some engine.
https://riptutorial.com/cplusplus/example/14080/value-or
Eigen中的noalias()
矩阵相乘,Eigen默认会解决混淆问题,如果你确定不会出现混淆,可以使用noalias()来提效。
完美转发 std::forward()
https://blog.csdn.net/coolwriter/article/details/80970718
当我们将一个右值引用传入函数时,他在实参中有了命名,所以继续往下传或者调用其他函数时,根据C++ 标准的定义,这个参数变成了一个左值。那么他永远不会调用接下来函数的右值版本,这可能在一些情况下造成拷贝。为了解决这个问题 C++ 11引入了完美转发,根据右值判断的推倒,调用forward 传出的值,若原来是一个右值,那么他转出来就是一个右值,否则为一个左值。
这样的处理就完美的转发了原有参数的左右值属性,不会造成一些不必要的拷贝。
std::clamp
函数声明:
template<typename T>
constexpr const T& clamp(const T& value, const T& min_value, const T& max_value);
区间限定函数。
可以简化成如下定义:
template<class T>
T clamp(T x, T min, T max)
{
if (x > max)
return max;
if (x < min)
return min;
return x;
}
std::lower_bound()和std::upper_bound()
-
两个函数返回的结果都是迭代器
-
std::lower_bound(start, end, value)是在区间内找到第一个大于等于 value 的值的位置并返回,如果没找到就返回end()位置。 -
而
std::upper_bound(start,end,value)是找到第一个大于 value 值的位置并返回,如果找不到同样返回end()位置。
https://blog.csdn.net/albertsh/article/details/106976688
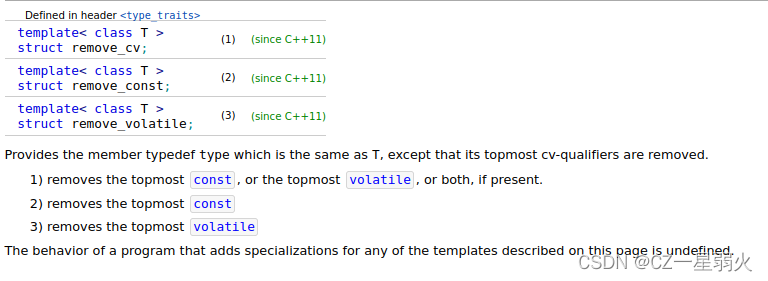
std::remove_cv, std::remove_const, std::remove_volatile
https://en.cppreference.com/w/cpp/types/remove_cv
std::distance()
作用于同一容器的 2 个同类型迭代器可以有效指定一个区间范围。在此基础上,如果想获取该指定范围内包含元素的个数,就可以借助 distance() 函数。
distance() 函数用于计算两个迭代器表示的范围内[start,end)包含元素的个数.
#include <iostream> // std::cout
#include <iterator> // std::distance
#include <list> // std::list
using namespace std;
int main() {
//创建一个空 list 容器
list<int> mylist;
//向空 list 容器中添加元素 0~9
for (int i = 0; i < 10; i++) {
mylist.push_back(i);
}
//指定 2 个双向迭代器,用于执行某个区间
list<int>::iterator first = mylist.begin();//指向元素 0
list<int>::iterator last = mylist.end();//指向元素 9 之后的位置
//获取 [first,last) 范围内包含元素的个数
cout << "distance() = " << distance(first, last);
return 0;
}
https://blog.csdn.net/u014072827/article/details/119456066
std::prev()
https://blog.csdn.net/qq_36268040/article/details/111036214
-
new_iterator = prev(iterator,n)当“n“为正数时,返回传入迭代器“iterator”左边,距离”iterator“ n个单位的迭代器”new_iterator“。
当“n“为负数时,返回传入迭代器“iterator”右边,距离”iterator“ n个单位的迭代器"new_iterator"。
-
new_iterator = prev(iterator)不写n的话,默认向“iterator”左边移动1个单位。
std::back_inserter()
back-inserter()是一种用于为容器添加元素的迭代器,其设计目的是避免容器中的原元素被覆盖,在容器的末尾自动插入新元素。
https://en.cppreference.com/w/cpp/iterator/back_inserter.
boost::make_optional
boost::optional使用容器语义,包装了可能产生无效值的对象,实现了未初始化的概念,未这种无效值的情况提供了解决方案。optional在c++17中可以直接使用。optional位于boost/optional.hpp中。
boost::optional库的核心类是optional,它很像是个仅能存放一个元素的容器,如果元素未初始化,那么容器就是空的,否则容器内的值就是有效的,已经初始化的值。
https://zhuanlan.zhihu.com/p/337180080.
DCHECK相关知识
DCHECK 是一个宏,通常在 C++ 代码中使用,用于进行调试期间的断言检查。它在许多开源项目中使用,例如 Chromium、Google Test 等。
-
断言:断言是一种在程序中插入的检查,用于验证某个条件是否为真。如果条件为假,断言将触发一个错误,通常导致程序终止或进入调试模式。断言的目的是帮助开发者在开发期间捕获错误和不可预期的情况。
-
DCHECK 宏:DCHECK 宏是一种用于调试目的的断言检查。它类似于 assert 宏,但与 assert 不同,DCHECK 宏在调试构建中始终执行断言检查,并在断言失败时触发错误。在发布构建中,DCHECK 宏被编译为无操作(no-op),从而避免运行时开销。
-
DCHECK_EQ、DCHECK_NE、DCHECK_LT 等:除了 DCHECK,还有一系列的宏用于执行不同类型的断言检查。这些宏以 _EQ、_NE、_LT 等结尾,表示等于、不等于、小于等关系。例如,DCHECK_EQ(a, b) 表示检查 a 是否等于 b。
-
编译标志:为了启用或禁用 DCHECK 的检查,可以使用编译器标志或宏定义。在调试构建中,默认情况下会启用 DCHECK 检查,而在发布构建中会禁用。可以根据需要调整编译标志以控制 DCHECK 的行为。
-
DCHECK 的使用场景:DCHECK 宏通常用于开发过程中进行调试和错误检查。它可以帮助开发者在开发期间捕获潜在的错误或不符合预期的情况,并提供有关错误发生位置的信息。
CHECK相关知识
-
CHECK 宏:CHECK 宏用于进行运行时的断言检查。与 DCHECK 不同,CHECK 宏在调试构建(debug build)和发布构建()realise build中都执行断言检查,因此在任何构建中都会触发错误。它可以用于在运行时检查关键条件的合法性,并在条件不满足时终止程序执行。
-
CHECK_EQ、CHECK_NE、CHECK_LT 等:除了 CHECK,还有一系列的宏用于执行不同类型的断言检查,类似于 DCHECK。这些宏以 _EQ、_NE、_LT 等结尾,表示等于、不等于、小于等关系。例如,CHECK_EQ(a, b) 表示检查 a 是否等于 b。
-
CHECK 的使用场景:CHECK 宏通常用于运行时检查关键条件的合法性,并在条件不满足时终止程序执行。它可以帮助开发者捕获运行时错误,并提供有关错误发生位置的信息。CHECK 通常用于执行必要但不可忽略的检查,以确保程序的正确性和安全性。
-
CHECK 的影响:当 CHECK 检查失败时,它会触发一个错误消息,并终止程序的执行。在调试构建中,通常会输出错误消息并进入调试模式,以便开发者进行调试。在发布构建中,错误消息通常被记录下来,然后程序终止。
constexpr和const
constexpr和const都用于在C++中声明常量,但它们有不同的使用情况和语义。
const用于声明一个不可修改的值,它可以用于变量、函数参数、函数返回类型以及类成员变量。
const int MAX_VALUE = 100; // 声明一个常量
const int* ptr = &MAX_VALUE; // 指向常量的指针,指针本身可修改
void foo(const int value); // 声明一个接收常量参数的函数
在上面的示例中,const确保了声明的值不可修改。但是,const常量在编译时并不一定会被求值,而是在运行时。
相比之下,constexpr用于声明一个可以在编译时求值的常量表达式。它可以用于变量、函数、构造函数和类成员函数(C++11之后)。使用constexpr可以提供编译时计算的能力,这在一些需要在编译时获得结果的场景下非常有用。
constexpr int square(int x) {
return x * x;
}
constexpr int MAX_VALUE = square(10); // 编译时计算常量
在上面的示例中,constexpr函数square在编译时被计算,并且可以用于初始化constexpr变量MAX_VALUE。这样,MAX_VALUE将在编译时被求值为100,并且可以被用作编译期间的常量。
因此,constexpr适用于那些在编译时已知且可以进行常量表达式计算的情况,而const适用于需要在运行时声明不可修改的值的情况。
std::get_if用法
std::get_if 是 C++ 标准库 头文件中的函数,用于从 std::variant 类型的对象中提取特定类型的值。std::variant 是 C++17 中引入的一种多态值类型,可以容纳多个不同的类型,并且在运行时可以确定当前容纳的是哪种类型。
std::get_if 函数的声明如下所示:
template< class T, class... Types >
constexpr std::add_pointer_t<const T> get_if( std::variant<Types...>* pv ) noexcept;
该函数接受一个指向 std::variant 对象的指针,并尝试从中提取类型为 T 的值。如果提取成功,则返回指向提取值的指针,否则返回 nullptr。
下面是一个示例,演示了如何使用 std::get_if 函数:
#include <iostream>
#include <variant>
int main() {
std::variant<int, double, std::string> var = 3.14;
if (auto pval = std::get_if<double>(&var)) {
std::cout << "Double value: " << *pval << std::endl;
} else if (auto pval = std::get_if<int>(&var)) {
std::cout << "Int value: " << *pval << std::endl;
} else if (auto pval = std::get_if<std::string>(&var)) {
std::cout << "String value: " << *pval << std::endl;
}
return 0;
}
在这个示例中,std::variant 对象 var 包含一个 double 类型的值。通过使用 std::get_if 函数,我们首先尝试提取一个 double 类型的指针。由于 var 中实际存储的是一个 double 值,提取成功,因此会打印出 Double value: 3.14。如果 var 中存储的是其他类型的值,相应的 get_if 分支将不会匹配,并且该分支的条件将被忽略。
需要注意的是,std::get_if 函数只能提取指向常量值的指针,因此返回类型是 std::add_pointer_t,即指向 const T 的指针。如果要修改 std::variant 中存储的值,可以使用 std::get 函数。
std::any_of()
当有一个元素范围并且想要检查范围中的任何给定元素是否满足给定条件时,此 STL 算法很有用。
参考博客:https://www.cnblogs.com/Galesaur-wcy/p/15589922.html
TRACE_EVENT_SCOPE
TRACE_EVENT_SCOPE是一个用于性能分析和调试的宏。它是Chrome浏览器中的一部分,也被许多C++应用程序和框架使用。该宏可以用于测量代码块的执行时间,并生成事件跟踪数据,以便在性能分析工具中进行分析和可视化。
TRACE_EVENT_SCOPE宏的用法如下:
TRACE_EVENT_SCOPE(category, name)
-
category是事件的分类,用于组织和过滤事件数据。通常可以使用自定义的分类名称,如"planner"、"rendering"等。
-
name是事件的名称,用于标识具体的代码块或操作。
-
使用TRACE_EVENT_SCOPE宏时,它会在代码块的开始处插入一个事件跟踪数据点,并在代码块结束时自动关闭该事件跟踪数据点。通过测量这两个数据点之间的时间差,可以得到代码块的执行时间。
-
事件跟踪数据通常由性能分析工具(如Chrome浏览器的开发者工具)进行捕获和分析。这些工具可以将事件的时间戳、持续时间、分类和名称等信息进行可视化,以便开发人员分析代码的性能特征和瓶颈。
在使用TRACE_EVENT_SCOPE宏之前,需要在代码中包含相应的头文件,如:
#include "base/trace_event/trace_event.h"
c++函数内部使用{}不需要增加分号
举个例子:
void foo() {
{
// code block 1
}
{
// code block 2
}
}
在每个代码块结束的}后面,都不需要加分号。