MetaAI开源模型和工具
MetaAI
Meta 首席执行官扎克伯格表示,与其他研究者分享 Meta 公司开发的模型可以帮助该公司促进创新、发现安全漏洞和降低成本。他今年 4 月对投资者说:「对我们来说,如果行业对我们正在使用的基本工具进行标准化,那么我们就可以从他人的改进中受益。」
Llama
2023.02.24
LLaMA:开放高效的基础语言模型
这是一个基础语言模型的集合,参数范围从 7B 到 65B。我们在数万亿个代币上训练我们的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而无需诉诸专有的和无法访问的数据集。特别是,LLaMA-13B 在大多数基准测试中都优于 GPT-3 (175B),而 LLaMA-65B 可以与最好的模型 Chinchilla-70B 和 PaLM-540B 竞争。
Meta开源的LLaMa到底好不好用?最全测评结果来了-夕小瑶科技说
开源MMS模型可识别1100+语言-新智元
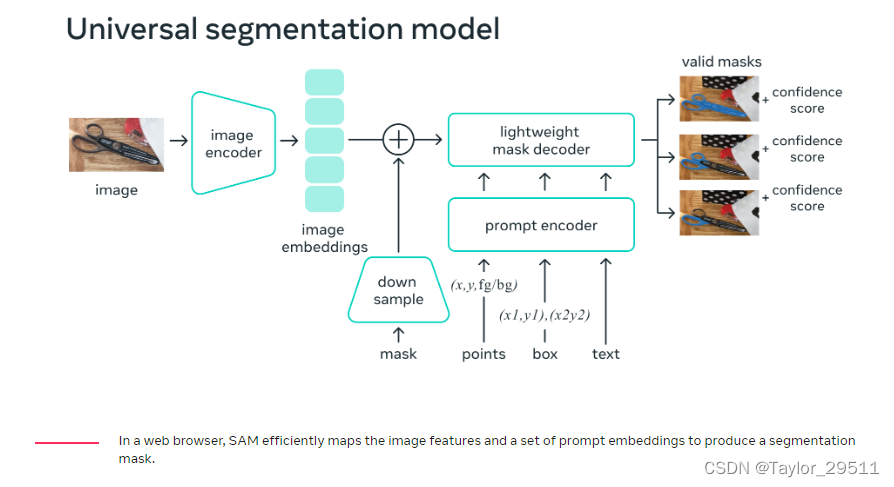
Segment Anything
2023.04.05
Segment Anything (SAM) 是一种通用分割模型
https://arxiv.org/abs/2304.02643
【segment-anything】- Meta 开源万物可分割 AI 模型,之前写的一篇博客
DINOv2
2023.04.18
具有自我监督学习功能的最先进的计算机视觉模型
- Meta AI 构建了 DINOv2,这是一种训练高性能计算机视觉模型的新方法。
- DINOv2 提供强大的性能并且不需要微调。这使得它适合用作许多不同计算机视觉任务的backbone。
- 因为它使用自我监督,DINOv2 可以从任何图像集合中学习。它还可以学习当前标准方法无法学习的特征,例如深度估计。
- 我们正在开源我们的模型并分享交互式演示。

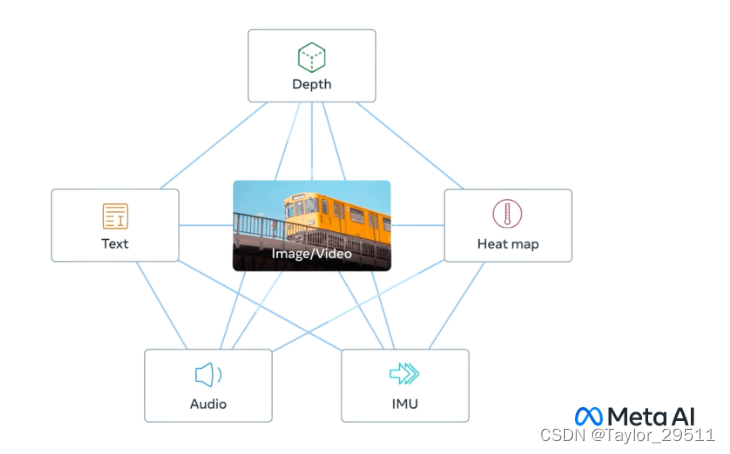
ImageBind
2023.05.09
文章地址
GitHub仓库
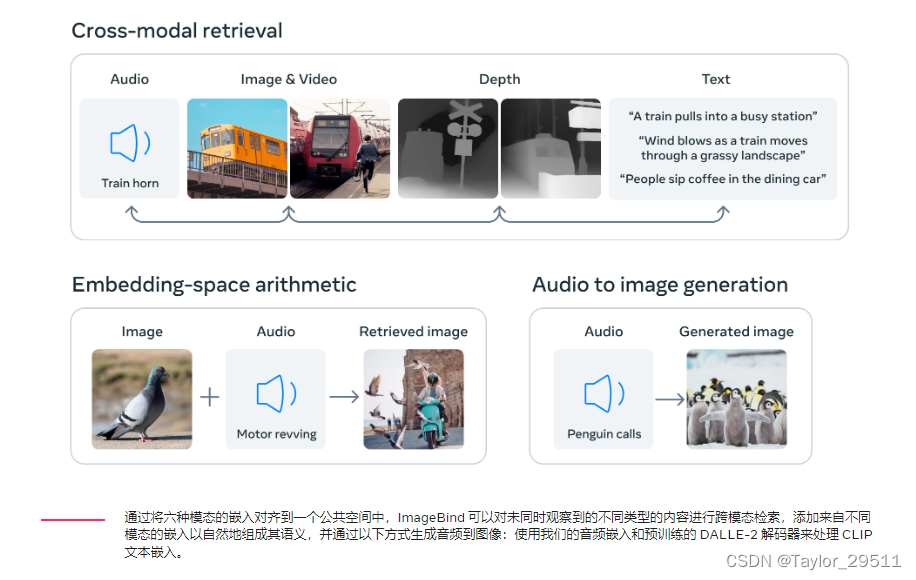
可让模型跨 6 种不同的模态(图像、文本、音频、深度、热能和 IMU 数据)进行交流! 基于该项目,开发者可以「开箱即用」实现包括跨模态检索、使用算术合成模态、跨模态检测和生成等各类新兴应用。
ImageBind是一种多模态AI模型,能够将文本、音频、视觉、热量(红外),还有IMU数据,嵌入到一个向量空间中。
从演示看,可以做到图片转音频、音频转图像、文本转图像和音频、图像和音频转图像、音频配合其他模型生成图像。
MMS
2023.05.23
Github仓库地址
开源MMS模型可识别1100+语言-新智元
Massively Multilingual Speech:大规模多语言语音
使用wav2vec 2.0的自监督学习,MMS将语音技术扩展到1100到4000种语言。
- 从文本到语音
- 以及语音到文本的互转
- 可以讲 1100 种语言,听懂 4000 种语言
在这之前最流行的模型应该是 Whisper
Meta 在文档中提到比 Whisper 的错误率低了 50%
Lima
2023.05.23
论文地址
没有RLHF,一样媲美GPT-4、Bard,Meta发布650亿参数语言模型LIMA-机器之心
Lima是llama的一个改进。感觉LIMA的思路就是够强的预训练,加几个你任务的例子SFT,就可以激活你任务上的效果
LIMA是Meta的新型大型语言模型(LLM),它基于65B的LLAMA,只在1000个样本上进行了训练,它的表现和当前最先进的LLM一样好。LLM不需要太多的示例,大型模型也不需要真的"很大"。
LLaMa的微调大模型LIMA,号称只用了1000个精心策划的提示和反馈进行微调,就达到了非常好的效果。
我们通过训练LIMA,一个参数为650亿的LLaMa语言模型,仅使用标准的监督学习损失对1000个精心策划的提示和反馈进行微调,无需任何强化学习或人类偏好模型,来衡量这两个阶段的相对重要性。
LIMA表现出了极强的性能,能从训练数据中只有少量的样本学习特定的响应格式,包括从规划旅行行程到推测历史替代情景的复杂查询。
此外,该模型往往能很好地推广到未出现在训练数据中的新任务。在一个受控的人类研究中,
43%的情况下,LIMA的反馈与GPT-4相当或被严格优先选择
与Bard比较时,这个比例高达58%,与接受人类反馈训练的DaVinci003比较时,这个比例达到65%。
综合来看,这些结果强烈表明,大型语言模型中几乎所有的知识都是在预训练阶段学习的,只需要有限的指令调整数据就可以教授模型产生高质量的输出。
Voicebox
2023.06.16
文章地址
Meta AI开发出一种各方面都表现非常先进的语音生成AI模型:Voicebox
与别的生成语音的 AI 需要使用精心准备的训练数据对每项任务进行特定训练不同。
Voicebox使用一种新方法来仅从原始音频和随附的转录中学习。这种方法提高了模型的灵活性,使其能够更好地适应各种任务
MusicGen
简单可控的音乐生成模型
MusicGen是一个单阶自回归Transformer模型,它是通过一个在32kHz EnCodec tokenizer上进行训练,具有4个以50Hz采样的码本。
- 用于条件音乐生成的单语言模型 (LM)
- 使用压缩音乐令牌运行,无需多个模型
- 在文本或旋律的引导下生成高质量的样本
- 广泛的评估表明 MusicGen 优于基线模型
- 研究强调了 MusicGen 中每个组件的重要性
Llama 2
2023.07.18
文章地址
Meta 发布免费可商用版本 Llama 2,大模型格局再次发生巨变
- 包含3个规模:LLAMB 700亿参数、LLAMM 130亿参数、LLAMS 70亿参数。采用Transformer架构。
- 相比Llama 1,训练数据增加40%,模型上下文长度加倍。性能显著提升,几乎可与专有模型GPT-3.5匹敌。
- Llama 2-Chat是对话优化版本,通过监督微调和RLHF方法,在单轮和多轮对话的自然性、连贯性上胜过其他开源模型,可媲美ChatGPT。
- 强化了模型安全性,使用各种技术减少有害输出,安全性评估结果优于其他开源模型
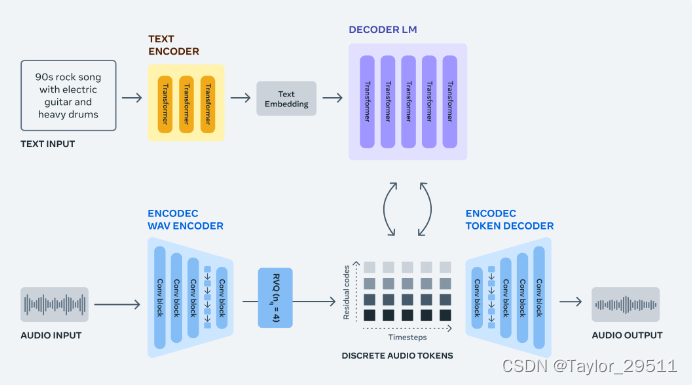
AudioCraft
2023.08.02
文章地址
AudioCraft 是一个简单框架,在对原始音频信号(而不是 MIDI 或钢琴卷轴)进行训练后,根据基于文本的用户输入生成高质量、逼真的音频和音乐。
AudioCraft 包含三个模型:MusicGen、AudioGen和EnCodec。MusicGen 使用 Meta 拥有且专门授权的音乐进行训练,根据基于文本的用户输入生成音乐,而 AudioGen 使用公共音效进行训练,根据基于文本的用户输入生成音频。今天,我们很高兴发布 EnCodec 解码器的改进版本,它可以用更少的音损生成更高质量的音乐;我们预先训练的 AudioGen 模型,可让您生成环境声音和声音效果,例如狗叫声、汽车喇叭声或木地板上的脚步声;以及所有 AudioCraft 模型权重和代码。这些模型可用于研究目的并加深人们对该技术的理解。
SeamlessM4T
2023.08.22
文章地址
这是一种基础的多语言和多任务模型,可以无缝翻译和转录语音和文本。SeamlessM4T 支持:
- 自动语音识别近百种语言
- 近 100 种输入和输出语言的语音到文本翻译
- 语音翻译,支持近100种输入语言和35种(+英语)输出语言
- 近 100 种语言的文本到文本翻译
- 文本转语音翻译,支持近100种输入语言和35种(+英语)输出语言
