原创 | 文 BFT机器人

内容提要
-
事件背景:
2023年4月5日,MetaAI研究团队发布论文“分割一切”一《Segment Anything》并在官网发布了图像分割基础模型一Segment Anything Model(SAM)以及图像注释数据集Segment-Anything 1-Billion(SA-1B)。
-
论文核心观点 :
目标:
MetaAI的目标是通过引入三个相互关联的部分来构建一个用于图像分割的基础模型:1)可提示的图像分割任务;2)数据标注并通过提示实现零样本到一系列任务的分割模型-SAM ;3)拥有超过10亿个掩码的数据集-SA-1B。
功能:
1)SAM允许用户仅通过单击或通过交互式单击点来包含和排除对象来分割对象,也可以通过边界框进行提示
2)当分割对象存在歧义时,SAM可以输出多个有效掩码,是解决现实世界中分割的重要和必要能力之一
3)SAM可以自动查找并掩盖图像中的所有对象;4)SAM可以在预计算图像嵌入之后即时为任何提示生成分割掩码,从而允许与模型实时交互。结论:SAM模型试图将图像分割提升到基础模型时代,而SAM是否能达到基础模型的地位还有待观察它在社区中的使用情况,但无论该项目前景如何,超过1B的掩码以及可提示的分割模型为其未来发展奠定了基础。
启发: 我们认为,SAM模型在SA-1B强大分割数据集的支撑下,可以通过各种形式的提示对图像下,无需额外训练即可自动完成分割任务,这一通用特性使得SAM模型在相关领域的推广应用达指令成为可能。
我们认为,SAM模型有望作为效率提升的工具,赋能自动驾驶、医疗健康、安防监控农业科技等领域,跨视觉模态和相关场景将从中收益。游戏娱乐、农业科技等领域,跨视觉模态和相关场景将从中收益。
2023年4月5日,MetaAI发布论文《Segment Anything》。论文指出MetaAI的目标是通过引入三个相互关联的部分来构建一个用于图像分割的基础模型:
1)可提示的图像分割任务。
2)数据标注并通过提示实现零样本到一系列任务的分割模型SAM。
3)拥有超过10亿个掩码的数据集-SA-1B。

论文介绍Segment Anything(SA)项目主要包括了用于图像分割的新任务、模型和数据集。指出AI团队发现SAM在多任务上具备竞争力,且它的零样本性能让人印象深刻。
通过在数据收集循环中使用高效模型AI团队构建了迄今为止最大的分割数据集,在1100万张许可和尊重隐私的图像上有超过10亿个掩码。该模型被设计和训练为可提示的,因此它可以将零样本转移到新的图像分布和任务中。
文章提到,MetaAI研究团队在https://segment-anything.com上发布了Segment AnythingModel(SAM)和相应的1B掩模和11M图像数据集(SA-1B),以促进对计算机视觉基础模型的研究
01 介绍:
根据论文表述,SA的目标是建立一个图像分割的基础模型,即寻求开发一个可提示的模型,并使用能够实现强大泛化的任务在广泛的数据集上对其进行预训练,从而可以通过使用提示工程解决新数据分布上的一系列下游分割问题。
文章认为,SA项目成功的关键在于3个部分:任务、模型和数据,由此,团队需要解决以下问题:
1、什么任务可以实现零样本泛化?
首先需要定义一个可提示的分割任务,该任务足够通用,以提供强大的预训练目标并支持广泛的下游应用程序。
2、对应的模型架构是怎样的?
需要一个支持灵活提示的模型,并且可以在提示时实时输出分割掩码,以供交互使用。
3、哪此数据可以为这项任务和模型提供支持?
文章提出,训练模型需要多样化、大规模的数据源,为解决这一问题,可以构建一个“数据引擎”,即在使用高效模型来协助数据收集和使用新收集的数据来改进模型之间进行选代。
02 任务
论文提到,团队是从NLP中获得了灵感,希望可以将NLP领域的Prompt范式延展到计算机视觉(CV)领域。其中:
图像分割的提示(Prompt) : 可以是一组前景/背景点、粗略框或掩码自由格式的文本,或者指示分割图像的任何信息。
可提示的分割任务(promptablesegmentation task): 指在给定任何提示的情况下返回有效的分割掩码。有效掩码是指,即使提示不明确、并且可能涉及多个对象,输出也应该是其中至少一个对象的合理掩码。
文章通过展示下图,介绍了SAM模型在1个不明确的提示下,生成了3个有效掩码。其中,绿色圆点代表提示,红色框线所呈现的图形代表有效掩码。

2023年4月5日,MetaAI同时发布博客,将SAM与过去2种图像分割方法进行了对比,具体如下:

博客介绍,SAM主要有以下突出功能:
1)SAM允许用户仅通过单击或通过交互式单击点来包含和排除对象来分割对象,也可以通过边界框进行提示。
2)当分割对象存在歧义时,SAM可以输出多个有效的掩码,这是解决现实世界中分割的重要和必要能力之一。
3)SAM可以自动查找并掩盖图像中的所有对象。
4)SAM可以在预计算图像嵌入之后即时为任何提示生成分割掩码,从而允许与模型实时交互。
03 模型
论文指出,SAM是可提示分割模型,包括3部分:图像编码器、灵活提示编码器和快速掩码解码器SAM建立在Transformer视觉模型的基础上,并在实时性能方面进行了一定的权衡。

图像编码器(Image encoder): 受可扩展性和强大的预训练方法的启发,团队使用MAE预训练的视觉转换器,该转换器最低限度地适用于处理高分辨率输入。每输入1个图像,图像编码器就运行一次,并且可以在提示模型之前应用。
提示编码器(Prompt encoder): 包括两组提示--sparse ( 点、框、文本)和dense( 码 )通过位置编码来表示点和框,其中位置编码与每个提示类型的学习嵌入相结合,用CLIP的现成文本编码器表示自由格式文本。掩码等dense提示使用卷积嵌入,并与图像嵌入元素结合。
掩码解码器(Mask decoder): 掩码解码器有效地将图像嵌入、提示入和输出令牌映射到掩码该设计的灵感来源于对Transformer解码器块的修改。修改的解码器块在两个方向上使用提示自注意和交叉注意来更新所有嵌入。在运行两个块之后,对图像嵌入进行上采样,MLP将输出令牌映射到动态线性分类器,然后动态线性分类器计算每个图像位置的掩码前景概率。
04 数据引擎:
论文提到,由于互联网上的分割掩码并不丰富,因此,MetaAI团队构建了一个数据引擎来收集1.1B掩码数据集SA-1B,数据引擎分为3个阶段:模型辅助手动注释阶段、混合自动预测掩码和模型辅助注释的半自动阶段、全自动阶段。
阶段1一手动阶段: 数据集通过使用SAM收集,标注者使用SAM交互地注释图像,新的注释数据反过来更新SAM,实现了相互促进。在该方法下交互式地注释一个掩码约需要14秒与之前大规模分割数据收集工作相比Meta的方法比COCO完全手动基于多边形的掩码注释快6.5倍,比之前最大的数据注释工作快2倍,这正是基于SAM模型辅助的结果。


阶段2-半自动阶段:帮助增加掩码的多样性,提高模型分割任何图像的能力。
阶段3-全自动阶段: 完全自动的掩模创建使得数据集扩展。最终数据集包括了在约1100万受许可和保护隐私的图像上收集的超11亿个分割掩模,SA-1B比任何现有分割数据集的掩模数量多400倍经人工评估验证,其具有高质量和多样性,在某些情况下甚至与以前规模较小.手动注释的数据集的质量相当。


05 数据集
论文介绍了数据集SA-1B包含1100万张多样化、高分辨率、许可和隐私保护图像,以及使用数据引擎收集的1.1B高质量分割掩码,SA-1B数据集有助于帮助未来开发计算机视觉(CV基础模型。文章将SA-1B数据集与现有数据集进行比较,分析了各个掩码数据集的质量和特性。例如,下图展示了SA-1B数据集与现有最大分割数据集相比的标准化图像大小下的掩码中心分布情况:



每张图像的掩码数: 经过数据对比,文章得出结论,SA-1B比第二大的Open Images多11倍的图像和400倍的掩码,平均下来每张图像的掩码比Open Images多36倍在这方面最接近的数据集ADE20K,每张图像的掩码仍少3.5倍。SA-1B数据集在掩码数量上具备强大优势
掩码相对于图像大小: 论文通过计算掩码相对于图像的大小,即掩码面积除以图像面积的平方根,发现由于SA-1B数据集每个图像有更多的掩码,它因此也拥有更大比例的中小掩码。
掩码凹度: 为解释图像形状的复杂性,文章通过对比掩码凹度进行了分析。掩码凹度=1-(掩码面积/掩码凸包面积。由于形状复杂度与掩码大小相关,通过首先从分箱掩码大小进行分层抽样来控制数据集的掩码大小分布。观察到SA-1B掩码的凹度分布与其他数据集的凹度分布基本一致。
06 RAI分析
论文进行RAI分析( Responsible AI-负责任的人工智能),旨在调查使用SA-1B和SAM时潜在的公平议题和偏见情况。
跨区域代表性 : 论文发现SA-1B的图像来自多个国家的照片提供商,跨越多个地区认为SA-1B具有比以前分割数据集更多的图像数量和更好的跨地区代表性。
文章通过展示下图,表明世界上大多数国家的SA-1B图像超过了1000张,下图显示了图像最多的三个国家来自世界不同的地区,分别为俄罗斯、泰国和美国。


论文发现SA-1B数据集的图像跨越了多样化的地理和收入水平: 通过比较SA-1BCOCO和Open Images的地理和收入代表性,可以得出SA-1B在欧洲、亚洲和大洋洲以及中等收入国家/地区的图像比例要高得多。
所有数据集都没有充分代表非洲和低收入国家。而在SA-1B中,包括非洲在内的所有地区至少有2800万个掩码比之前任何数据集的掩码总数多10倍。
文章分析了模型在人们的外表性别呈现、肤色外观和预期年龄范围等方面的潜在偏见,发现SAM在不同群体之间的表现相似,认为这将有助于促进公平,以便在实际应用场景中使用。

07 零样本传输实验
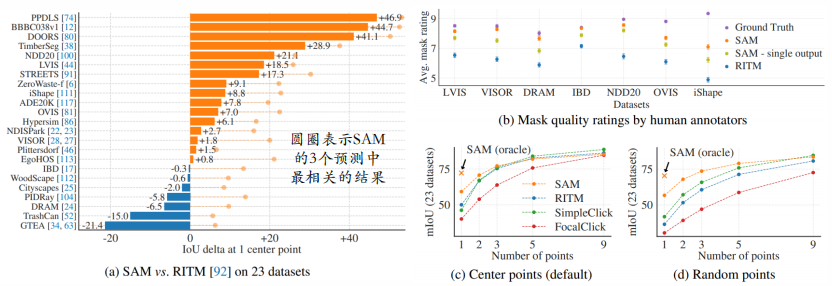
论文展示了来自23个不同分割数据集的用于评估SAM零样本传输能力的samples : 结果表明SAM在23个数据集样本中有167高达近47IoU产生了更高的结果,文章指出,最相关SAM3个掩码是通过将它们与地面实况进行比较来选择的而不是选择最有置信的掩码,这表明歧义对自动评估的影响,通过oracle执行歧义消解,SAM在所有数据集上都优于RITM。

08 讨论
1.基础模型(Foundation models)方面,论文讨论了如下几点 :
-
自机器学习早期以来,预训练模型已适应下游任务。近年来,随着对规模的日益重视,这种范式变得越来越重要并且此类模型最近被重新命名为基础模型,即“在大规模广泛数据上训练并适应广泛下游务”的模型。MetaA的工作与基础模型有很好的相关性,尽管图像分割的基础模型是一个有限的范围,因为它只代表了计算机视觉中重要却一小部分的子集。
-
SAM模型经过了自监督技术初始化,其绝大多数能力来自大规模监督训练,在数据引擎可以扩展可用注释的情况下SAM模型的监督训练提供了一个有效的解决方案。
2.组合/合成(Compositionality)方面
文章指出经过预训练的模型可以提供新能力,甚至超出训练时的想象。一个著名的例子是CLIP如何在更大的系统中用作组件,如DALL·E。MetaAI的目标是通寸SAM使合成变得简单,通过要求SAM预测各种分割提示的有效掩码来实现这一点。
SAM和其他组件之间可以创建一个可靠的接口。如:MCC可以使用SAM来分割感兴趣的对象、实现对看不见的对象的强泛化,以便从单个RGB-D图像进行3D重建;SAM可以通过可穿戴设备检测到的注视点来提示,从而启用新的应用程序。由于SAM能够推广到以自我为中心的图像等新领域,因此此类系统无需额外培训即可工作。
3.在局限方面,文章认为SAM模型总体表现良好,但可以更完美
-
有时会产生幻觉,或者不会清晰地产生边界;
-
SAM是为通用性和使用广度设计的,而不是为高IoU交互式分割而设计的;
-
SAM可以实时处理提示,但在使用重型图像编码器时,SAM的整体性能并不是实时的;
-
对text-to-mask任务的尝试是探索性的,并不完全可靠,需要更多努力使其改进;
-
SAM可以执行许多任务,但尚不清楚如何设计实现语义和全景分割的简单提示;
-
在特定领域,其他工具的表现可能优于SAM。
经过以上分析,论文得出以下结论:
结论一: Segment Anything项目试图将图像分割提升到基础模型时代,主要是得益于新任务( 可提示分割 )、模型 (SAM) 和数据集(SA-1B)。
结论二: SAM是否达到基础模型的地位还有待观察它在社区中的使用情况,无论该项目的前景如何,超过1B的掩码以及可提示的分割模型都将有助于未来为其铺平道路。
4. 对当下的启发
根据以下Demo,我们可以发现,通过在图像中指定要分割的内容提示,SAM可以实现各种分割任务,且无需额外的训练、做到零样本泛化,即SAM学会了辨别物体、具备图像理解力、对不熟悉的图像和物体能进行零样本概括,这一通用特性使得SAM模型在有关领域的推广应用成为可能。


我们认为,SAM模型有望将NLP领域的Prompt范式延展到计算机视觉(CV)领域,在SA-B强大分割数据集的支撑下,通过各种形式的提示对图像下达指令,无需额外训练即可自动完成分割任务。SAM模型有望进一步推动夸视觉模态的发展。
从应用角度看,我们认为SAM模型将作为效率提升的工具,解锁数字大脑视觉区,赋能自动驾驶医疗健康、安防监控、游戏娱乐、农业科技等领域,跨视觉模态和相关场景有望从中受益。
文章来源:西南证券