-
一、前言
1 热图介绍
通常,热图是对所获得的数据或其他因素进行归一化处理后,用颜色的变化来直观表示不同样本间的变化情况。本质上其是由一个个用预设颜色表示数值大小的小方格组成的数据矩阵,并通过对因子或样本的聚类,观察不同样品数据间的相似性。
2 热图绘制方式
常用的绘图软件:origin,excel,Tbtools,GraphPadPrism
R语言绘制聚类热图的R包:pheatmap,heatmap,corrplot,complexHeatmap
其中,pheatmap是R语言中使用最广泛的用于绘制聚类热图的绘图包。使用该绘图包可以帮助我们快速生成包含聚类结果的热图。
二、用pheatmap包绘制聚类热图
1 数据准备
数据输入格式(csv格式):

2 R包加载及数据导入
#下载包#
install.packages("pheatmap")
install.packages("RColorBrewer")
#加载包#
library("pheatmap")
library("RColorBrewer")
#加载绘图数据#
data<-read.table(file='C:/Rdata/jc/pheatmap.csv',header=TRUE,row.names= 1,sep=',')
head(data) #查看数据 
#data=log2(data[,1:6]+1) #对基因表达量数据处理
#data <- as.matrix(data) #转变为matrix格式矩阵
#head(data)3 热图绘制
3.1基础热图及标准化
pheatmap(data) #基础热图绘制 

图1 数据未均一化的热图
3.2进行归一化绘图
3.2.1热图绘制准备——均一化
绘制热图通常需对数据进行归一化操作,以使差别较大的因子处于同一个数量级,从而便于观察不同因子在不同样本之间的变化规律。一般来说,一个因子在不同样本间的分布会在热图的行方向上进行展示,所以为了展示一个因子在不同样本间的分布,均一化处理会按 “row”进行。
pheatmap(data, scale='row') #标准化的方法,row是按照进行标准化(归一化),column是按照列进行标准化,none为不进行标准化 
图2经过归一化处理的热图
3.3 热图聚类方式及聚类树调整
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为“euclidean”,也可为 "correlation"即按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = 6, #若进行了行、列聚类,根据行、列聚类数量分隔热图行
treeheight_row = 30, treeheight_col = 30) #、行、列聚类树高度调整 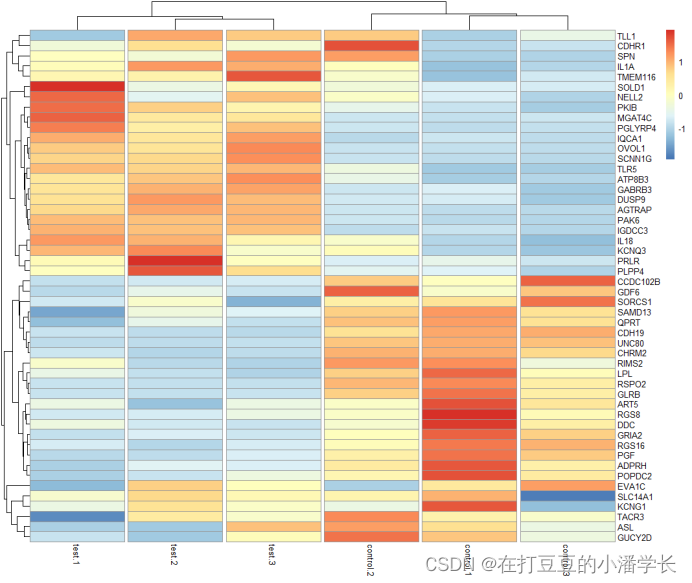
图3设置完热图聚类方式及聚类树调整的热图
3.4聚类热图单元格格式调整
3.4.1单元格长度与宽度及边框颜色调整
使用“cellwidth”、“cellheight”、“border_color”设置热图单元格的宽度、高度及单元格边框的颜色:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = 6, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = NA, #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5) #表示单个单元格的宽度\高度,默认为 “NA”
图4 设置完单元格宽度、高度及边框颜色的热图
3.4.2 单元格内数值显示及数值字体大小等调整
使用“display_numbers”、“ fontsize_number”、“ number_format”、“number_color”设置热图单元格上数值显示、数值字体大小、数值格式及字体颜色:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = 6, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = NA, #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = T, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30") #表示热图单元格上显示的数据字体颜色
图5 设置完单元格内数值显示及数值字体大小等的热图
3.4.3 热图单元格区分标记
使用“display_numbers” 根据热图单元格的数值进行标记,若该单元格原始数值大于1,则为 “***”,否则为 " ";
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = 6, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = NA, #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = matrix(ifelse(data > 1, "***", ""), nrow = nrow(data)),#使用“display_numbers” 根据热图单元格的数值进行标记,若该单元格原始数值大于1,则为 “***”,否则为 " ";
fontsize_number = 10, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30") #表示热图单元格上显示的数据字体颜色
图6 设置完热图单元格区分标记的热图
3.5 热图美化及个性化设置
3.5.1 热图标题及行列标签
使用“show_rownames ”、“show_colnames”、“main”设置行名、列名显示以及标题:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = 6, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = "grey60", #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = T, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30", #表示热图单元格上显示的数据字体颜色
show_rownames = F, show_colnames = T, #表示是否显示行名、列名
main = "Gene标题") #表示热图的标题名字
图7 设置完热图行名、列名显示和标题的热图
3.5.2热图字体大小设置
使用“fontsize”、“fontsize_row”、“fontsize_row”设置热图中字体大小、行名、列名字体大小,默认与fontsize一致:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = 6, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = "grey60", #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = T, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30", #表示热图单元格上显示的数据字体颜色
fontsize =10, fontsize_row = 6, fontsize_col = 10, #热图中字体大小、行、列名字体大小
show_rownames = T, show_colnames = T, #表示是否显示行名、列名
main = "Gene标题") #表示热图的标题名字
图8 设置完热图中字体大小、行名、列名字体大小的热图
3.5.3热图个性化设置
3.5.3.1热图颜色设置图例
使用“color”、“legend”、“legend_breaks ”等设置热图颜色、图例显示,图例的范围等:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = NA, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = "grey60", #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = F, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30", #表示热图单元格上显示的数据字体颜色
fontsize =10, fontsize_row = 6, fontsize_col = 10, #热图中字体大小、行、列名字体大小
show_rownames = T, show_colnames = T, #表示是否显示行名、列名
main = "Gene标题", #表示热图的标题名字
color = colorRampPalette(c("navy","white","firebrick3"))(100), #表示热图颜色,(100)表示100个等级
legend = T, #表示是否显示图例,值为TRUE或FALSE
legend_breaks = NA, #设置图例的范围legend_breaks=c(-2.5,0,2.5)表示图例断点的设置,默认为NA,
legend_labels = NA) #表示图例断点的标签

图9 设置完热图颜色和图例的热图
3.5.3.2标签角度及未聚类条件下热图的隔断位置
使用“angle_col”设置列标签的角度;“gaps_row”和“gaps_col”设置在未进行行和列聚类时,在行和列方向上热图的隔断位置:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = F, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = NA, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = "grey60", #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = F, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30", #表示热图单元格上显示的数据字体颜色
fontsize =10, fontsize_row = 6, fontsize_col = 10, #热图中字体大小、行、列名字体大小
show_rownames = T, show_colnames = T, #表示是否显示行名、列名
main = "Gene标题", #表示热图的标题名字
color = colorRampPalette(c("navy","white","firebrick3"))(100), #表示热图颜色,(100)表示100个等级
legend = T, #表示是否显示图例,值为TRUE或FALSE
legend_breaks = NA, #设置图例的范围legend_breaks=c(-2.5,0,2.5)表示图例断点的设置,默认为NA,
legend_labels = NA, #表示图例断点的标签
angle_col = "45", #表示列标签的角度
gaps_row = NULL, #仅在未进行行聚类时使用,表示在行方向上热图的隔断位置
gaps_col = c(1,2,3,4,5,6)) #仅在未进行列聚类时使用,表示在列方向上热图的隔断位置
图10 设置完列标签角度、列隔断的热图
3.5.3.3自定义行列标签
使用“gaps_row”、“gaps_col”自定义行列标签:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = NA, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = "grey60", #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = F, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30", #表示热图单元格上显示的数据字体颜色
fontsize =10, fontsize_row = 6, fontsize_col = 10, #热图中字体大小、行、列名字体大小
show_rownames = T, show_colnames = T, #表示是否显示行名、列名
main = "Gene标题", #表示热图的标题名字
color = colorRampPalette(c("navy","white","firebrick3"))(100), #表示热图颜色,(100)表示100个等级
legend = T, #表示是否显示图例,值为TRUE或FALSE
legend_breaks = NA, #设置图例的范围legend_breaks=c(-2.5,0,2.5)表示图例断点的设置,默认为NA,
legend_labels = NA, #表示图例断点的标签
angle_col = "45", #表示列标签的角度
gaps_row = NULL, #仅在未进行行聚类时使用,表示在行方向上热图的隔断位置
gaps_col = c(1,2,3,4,5,6), #仅在未进行列聚类时使用,表示在列方向上热图的隔断位置
labels_row = NULL, #表示使用行标签代替行名
labels_col = c("sample1","sample2","sample3","sample4","sample5","sample6")) #表示使用列标签代替列名

图11 自定义完列标签的热图
3.6热图保存
使用“filename”、“width”和“height”对热图进行保存:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = NA, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = "grey60", #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = F, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30", #表示热图单元格上显示的数据字体颜色
fontsize =10, fontsize_row = 6, fontsize_col = 10, #热图中字体大小、行、列名字体大小
show_rownames = T, show_colnames = T, #表示是否显示行名、列名
main = "Gene标题", #表示热图的标题名字
color = colorRampPalette(c("navy","white","firebrick3"))(100), #表示热图颜色,(100)表示100个等级
legend = T, #表示是否显示图例,值为TRUE或FALSE
legend_breaks = NA, #设置图例的范围legend_breaks=c(-2.5,0,2.5)表示图例断点的设置,默认为NA,
legend_labels = NA, #表示图例断点的标签
angle_col = "45", #表示列标签的角度
gaps_row = NULL, #仅在未进行行聚类时使用,表示在行方向上热图的隔断位置
gaps_col = c(1,2,3,4,5,6), #仅在未进行列聚类时使用,表示在列方向上热图的隔断位置
labels_row = NULL, #表示使用行标签代替行名
labels_col = c("sample1","sample2","sample3","sample4","sample5","sample6"), #表示使用列标签代替列名
filename = NA, #表示保存图片的位置及命名
width = NA, height = NA) #表示输出绘制热图的宽度/高度好了本次分享就到这里,下一期将分享聚类热图分组的绘制。

扫码关注公众号获取更多内容,以及相应代码与演示数据。