数据并行及任务并行
数据并行是将大规模的计算任务划分为多个子任务,并将这些子任务同时应用于不同的数据集上。每个子任务在独立的处理器上执行,通过对不同的数据集进行并行处理来提高计算性能。数据并行特别适用于对大规模数据集进行相同操作的情况,例如矩阵乘法、图像处理等。
任务并行是将计算任务划分为多个子任务,每个子任务执行不同的操作或指令序列。不同的子任务在不同的处理器上同时执行,通过并行执行多个不同的操作来提高计算性能。任务并行特别适用于复杂的计算任务,其中不同的子任务之间存在依赖关系,需要协同工作完成。
异构编程语言的共性
 在高性能计算中,"内核"是指计算任务的最小执行单元或最小计算单元。它代表了一系列指令的集合,可以在处理器上执行,完成特定的计算或操作。
在高性能计算中,"内核"是指计算任务的最小执行单元或最小计算单元。它代表了一系列指令的集合,可以在处理器上执行,完成特定的计算或操作。
内核通常是针对某个特定的计算问题或算法进行优化的实现。它可以包含许多计算和数据处理操作,如矩阵乘法、向量运算、排序算法等。内核的设计旨在充分利用硬件资源(如处理器、内存等),通过并行执行多个内核实例,以提高计算性能和效率。
内核执行时通常独立于主程序运行,并且可以在多个处理器上并行执行。内核的优化包括利用数据局部性、向量化指令、缓存优化等技术,以最大程度地利用处理器的计算能力。
在高性能计算中,通过合理地划分和管理任务的内核,可以充分发挥并行计算的潜力,提高程序的执行效率和整体性能。内核的优化是高性能计算中关键的一环。

opencl的划分方式
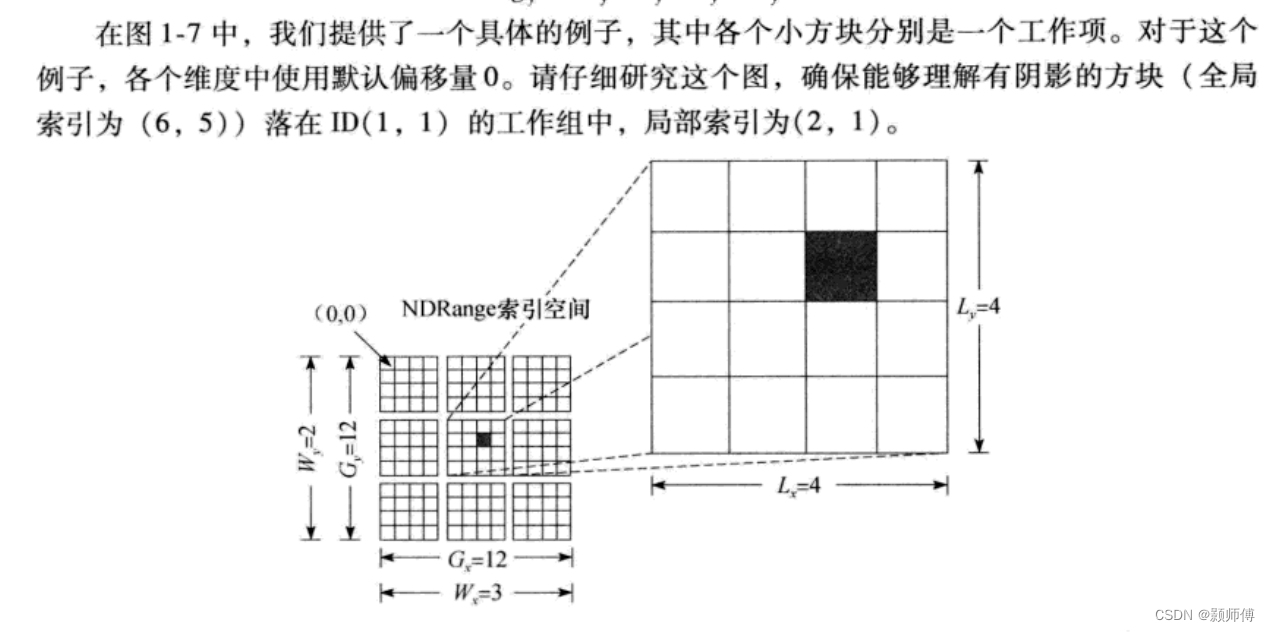
(1)全局索引:对图示整个方阵而言,坐标位置在(6,5)。
(2)工作组(localSize),是对全局工作项的二次粗划分。
(3)局部索引,是工作项在工作组内部的索引。
在核函数内使用工作组,可以通过获取每个工作项的全局和局部索引来访问数据。索引的计算和访问逻辑如下:
-
获取全局索引:使用内置变量
get_global_id(dim)可以获取当前工作项在维度dim上的全局索引。dim的值通常是0,表示第一个维度。 -
获取局部索引:使用内置变量
get_local_id(dim)可以获取当前工作项在维度dim上的局部索引。dim的值通常是0,表示第一个维度。 -
获取全局范围:使用内置变量
get_global_size(dim)可以获取整个执行范围(全局工作项数量)在维度dim上的大小。dim的值通常是0,表示第一个维度。 -
获取局部范围:使用内置变量
get_local_size(dim)可以获取工作组在维度dim上的大小。dim的值通常是0,表示第一个维度。
通过这些索引和范围,您可以根据需要访问全局和局部内存中的数据。下面是一个简单的示例:
__kernel void myKernel(__global float* input, __global float* output)
{
// 获取全局索引和局部索引
size_t globalId = get_global_id(0);
size_t localId = get_local_id(0);
// 获取全局范围和局部范围
size_t globalSize = get_global_size(0);
size_t localSize = get_local_size(0);
// 计算对应全局索引的输入和输出数据索引
size_t inputIndex = globalId;
size_t outputIndex = globalId;
// 计算对应局部索引的输入和输出数据索引
size_t localInputIndex = localId;
size_t localOutputIndex = localId;
// 在此处使用索引访问输入和输出数据,并进行计算
output[outputIndex] = input[inputIndex] + localInput[localInputIndex];
// 等待所有工作项完成局部计算
barrier(CLK_LOCAL_MEM_FENCE);
// 在此处进行工作组级别的计算或协作
}
在这个示例中,我们在核函数myKernel中获取了全局索引和局部索引。使用这些索引,我们可以计算出要访问的输入和输出数组的索引,并在核函数内执行相应的计算操作。还可以使用局部索引进行工作组级别的计算或者协作(例如使用局部内存进行数据共享)。最后的barrier函数用于等待所有工作项完成局部计算,以确保所有工作项能够同步执行。
opencl上下文定义
设备(device):宿主机使用的 OpenCL设备集合。
内核 (kernel):在 OpenCL 设备上运行的 OpenCL 函数。
程序对象 (program object):实现内核的程序源代码和可执行文件。
内存对象(memory object):内存中对OpenCL设备可见的组对象,包含可以由内核实
例处理的值。
以字符串为主的程序对象
上下文中还包括一个或多个程序对象 (program object),程序对象包含内核的代码。程序对
象这个名字的选择容易让人混淆。最好把它想象成一个动态库,可以从中取出内核使用的函
数。程序对象会在运行时由宿主机程序构建。对于不是从事图形领域的程序员来说,这看起来
可能有些奇怪。可以考虑一下 OpenCL程序员面对的挑战。他编写了 OpenCL应用程序并把这个
应用程序交给最终用户,但是这些用户可能选择在其他地方运行这个应用程序。程序员根本无
法控制最终用户在哪里运行应用程序 (可能是 CPU、CPU 或者其他芯片)。OpenCL 程序员所知
道的只是目标平台符合OpenCL规范。
对于这个问题,解决方法就是在运行时从源代码构建程序对象。宿主机程序定义上下文中
的设备。只有那时才有可能知道如何编译程序源代码来创建内核代码。对于源代码本身
OpenCL 在形式上相当灵活。在很多情况下,这会是一个常规的字符串,可以在宿主机程序中静
态定义,或者在运行时从一个文件加载,也可能在宿主机程序中动态生成。
同一设备,多个命令队列
在OpenCL中,您可以在一个设备上创建多个命令队列。这样做主要有以下几个优点:
1. 并发执行:通过使用多个命令队列,您可以并行地执行多个内核或命令,从而提高程序的性能和效率。
2. 独立管理:每个命令队列都有自己的内核执行顺序和状态,因此您可以更灵活地管理和调度不同的内核和任务。
3. 异步操作:使用多个命令队列可以实现异步操作。您可以将多个命令添加到不同的队列中,并在需要时进行同步。
然而,创建多个命令队列也可能有一些注意事项:
1. 设备限制:每个设备的命令队列数量是有限的,具体取决于硬件和驱动程序,超出限制可能导致错误。可以使用`clGetDeviceInfo`函数查询设备支持的最大命令队列数。
2. 内存和资源管理:每个命令队列都有独立的内存和资源管理,因此需要确保系统中的总资源使用不超过设备的限制。
3. 同步和数据共享:不同命令队列之间的同步和数据共享可能需要额外的机制,如事件或内存对象的共享。
为了示范在同一个设备上创建多个命令队列,下面是一个简单的代码片段:
```cpp
cl_device_id device;
cl_context context;
cl_command_queue queue1, queue2;
// 创建设备和上下文
clGetDeviceIDs(NULL, CL_DEVICE_TYPE_GPU, 1, &device, NULL);
context = clCreateContext(NULL, 1, &device, NULL, NULL, NULL);
// 创建命令队列
queue1 = clCreateCommandQueue(context, device, 0, NULL);
queue2 = clCreateCommandQueue(context, device, 0, NULL);
// 在命令队列1中提交命令
clEnqueueNDRangeKernel(queue1, kernel1, ...);
// 在命令队列2中提交命令
clEnqueueNDRangeKernel(queue2, kernel2, ...);
在这个示例中,我们通过调用clCreateCommandQueue函数两次来创建了两个命令队列:queue1和queue2。然后,我们可以在这两个命令队列中分别提交不同的内核或任务。
需要注意的是,不同命令队列之间的执行顺序是不确定的,除非您使用额外的同步机制,如事件或屏障,来确保它们的顺序和同步。另外,多个命令队列的使用可能需要更复杂的任务和数据管理,以确保正确的同步和协调。
```cpp
queue:命令队列对象,用于提交命令。
num_events_in_wait_list:等待事件列表中事件的数量。通常为0,表示没有等待的事件。
event_wait_list:指向等待事件列表的指针,用于指定在执行标记之前需要等待的事件。通常为NULL,表示没有等待的事件。
event:返回的事件对象,用于标识标记命令的事件。在事件完成之前,可以使用该事件来等待或查询内核的执行状态。
同时执行多个核函数的示例
#include <CL/cl.h>
#include <iostream>
#define NUM_ELEMENTS 1000
// 在这段代码中,R"(...)" 是一种称为原始字符串字面量(raw string literals)的C++11特性。这种特性允许在字符串中包含特殊字符而无需进行转义。
// 在您给出的代码中,R"( 和 ")" 包围的部分是一个原始字符串字面量,其中包含了一个内核函数的定义。
// 使用原始字符串字面量的好处是,您可以在字符串中直接使用特殊字符,例如反斜杠和双引号,而无需对它们进行转义。这在编写包含许多转义字符的长字符串时特别方便。
const char* kernelSource[] = {
R"(
__kernel void copy(__global int* input, __global int* output) {
int gid = get_global_id(0);
output[gid] = input[gid];
}
)",
R"(
__kernel void doublevalue(__global int* output) {
int gid = get_global_id(0);
output[gid] = output[gid]+1;
}
)"
};
int main() {
cl_platform_id platform;
cl_device_id device;
cl_context context;
cl_command_queue queue;
cl_program program;
cl_kernel kernel;
cl_kernel kernel2;
cl_mem inputBuffer, outputBuffer;
cl_event syncEvent;
int input[NUM_ELEMENTS];
int output[NUM_ELEMENTS];
// 初始化输入数据
for (int i = 0; i < NUM_ELEMENTS; i++) {
input[i] = i;
}
// 创建平台、设备和上下文
clGetPlatformIDs(1, &platform, NULL);
clGetDeviceIDs(platform, CL_DEVICE_TYPE_CPU, 1, &device, NULL);
context = clCreateContext(NULL, 1, &device, NULL, NULL, NULL);
queue = clCreateCommandQueue(context, device, 0, NULL);
// 创建内存对象
inputBuffer = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(int) * NUM_ELEMENTS, input, NULL);
outputBuffer = clCreateBuffer(context, CL_MEM_READ_WRITE, sizeof(int) * NUM_ELEMENTS, NULL, NULL);
cl_int err;
// 创建内核程序并构建
program = clCreateProgramWithSource(context, 2, kernelSource, NULL, &err);
if (program == NULL || err != CL_SUCCESS) {
std::cout << "Failed to create program object." << std::endl;
}
//1即num_devices:构建程序的设备数量。
clBuildProgram(program, 1, &device, NULL, NULL, NULL);
// 创建内核,第2个参数需要对应核函数名
kernel = clCreateKernel(program, "copy", NULL);
kernel2 = clCreateKernel(program, "doublevalue", NULL);
// 设置内核参数
clSetKernelArg(kernel, 0, sizeof(cl_mem), &inputBuffer);
clSetKernelArg(kernel, 1, sizeof(cl_mem), &outputBuffer);
clSetKernelArg(kernel2, 0, sizeof(cl_mem), &outputBuffer);
// 创建同步事件
// syncEvent = clCreateUserEvent(context, NULL);
size_t globalSize[1]={
NUM_ELEMENTS};
//注意:在同一个命令队列中,对于相同的命令队列上的内核函数,它们通常是按顺序执行的。
//这意味着在命令队列中提交的内核函数将按照它们被插入的顺序进行执行。
//执行第一个内核
clEnqueueNDRangeKernel(queue, kernel, 1, NULL, globalSize, NULL, 0, NULL, NULL);
// 执行第二个内核(在第一个内核完成后执行)第二个1为在内核程序执行前等待的数量
clEnqueueNDRangeKernel(queue, kernel2, 1, NULL, globalSize, NULL, 0, NULL, NULL);
// 读取结果
clEnqueueReadBuffer(queue, outputBuffer, CL_TRUE, 0, sizeof(int) * NUM_ELEMENTS, output, 0, NULL, NULL);
// 打印结果
for (int i = 0; i < NUM_ELEMENTS; i++) {
std::cout << "Output[" << i << "] = " << output[i] << std::endl;
}
// 释放资源
clReleaseMemObject(inputBuffer);
clReleaseMemObject(outputBuffer);
clReleaseKernel(kernel);
clReleaseKernel(kernel2);
clReleaseProgram(program);
clReleaseCommandQueue(queue);
clReleaseContext(context);
return 0;
}