在传统的TensorFlow开发中,我们需要首先通过变量和Placeholder来定义一个计算图,然后启动一个Session,通过TensorFlow引擎来执行这个计算图,最后给出我们需要的结果。相信大家在入门阶段,最困惑的莫过于想要打印某些向量或张量的值,在Session之外或未执行时,其值不可打印的问题。TensorFlow采用这种反人性的设计方式,主要是为了生成基于符号的计算图,然后通过C++的计算图执行引擎,进行各种性能优化、分布式处理,从而获取优秀的运行时性能。与此形成对照的是以PyTorch为代表的动态图方式,其不用生成基于符号表示的计算图,直接计算结果,与我们平常编程的处理方式类似,无疑这种方式学习曲线会低很多。TensorFlow实际上也注意到了这一问题,在2017年11月,推出的Eager Execution就是这种动态图机制在TensorFlow中的实现。目前虽然Eager Execution在性能上还没有达到静态计算图的效率,但是由于其编程调试的方便性,会在实际应用中得到越来越广泛的应用。
大家还记得深度学习大佬Yann Lecun在前一段时间说的“深度学习已死,可微编程永生”的话吧?实际上Yann Lecun所说的可微编程(Differentiable Programming)还处在非常早期的阶段,Lecun的意思是说这种编程范式具有比深度学习更好的灵活性,有希望解决更为复杂的问题,提醒大家重点关注这一领域。而可微编程这种范式,在TensorFlow的Eager Execution下是可以比较方便实现的。
- 矩阵乘法TensorFlow传统实现方式
我们先来以矩阵相乘这一简单的功能为例,来看一下使用TensorFlow传统方法和Eager Execution方法的实现方式。
我们首先来看TensorFlow传统实现方式:
def tfsess1(args={}):
v1 = tf.constant([[1, 2], [3, 4]])
v2 = tf.constant([[5, 6], [7, 8]])
v3 = tf.matmul(v1, v2)
with tf.Session() as sess:
rst = sess.run([v3])
print('v3:{0}'.format(rst))运行结果如下所示:

由上面的代码可以看出,只有启动Session后,我们才能看到矩阵乘法的结果。正是这一点,是许多初学者非常不适应的地方。
- Eager Execution模式
如果采用Eager Execution模式,程序如下所示:
def tfee1(args={}):
tf.enable_eager_execution()
v1 = [[1, 2],[3, 4]]
v2 = [[5, 6],[7, 8]]
v3 = tf.matmul(v1, v2)
print('v3={0}'.format(v3))
print('v3 type:{0}'.format(type(v3)))
print('v3 shape:{0}'.format(v3.shape))
print('v3 dtype:{0}'.format(v3.dtype))
print('v3=>ndarray:{0}'.format(v3.numpy()))运行结果如下所示:

由上面的代码可以看出,我们直接采用普通的程序形式,就可以求出矩阵乘法的结果,而且TensorFlow中的Tensor和numpy中的ndarray可以互相无缝转换,非常方便使用。更加有用的是,我们还可以利用使用机器中的GPU。
- 自动微分
根据高等数学的知识可知,我们求一个函数的极值,我们可以求函数对自变量的一阶导数,然后令导数为零,此时解出的自变量的取值,就是对应的极值点,我们可以根据极值点邻域值的特点,确定该极值点是极大值还是极小值。当然在有些情况下,我们可以求出二阶导数,根据二阶导数在极值点的符号来判断是极大值点还是极小值点。我们知道,在机器学习和深度学习中,有很大一部分问题都是求极值问题,而非机器学习和深度学习领域,也有大量的求极值问题,因此Yann Lecun才会说“深度学习已死,可微编程永生”的话,就是可微编程比深度学习和机器学习的应用范围要广得多,具有更大的发展前景。而微分编程的基础就是自动微分,我们在这一部分中,将向大家展示一下TensorFlow下怎样实现自动微分。
在这里我们先来看一个最简单的例子,我们要求导数的函数为:
对于这个式子,我们只要略懂高等数学,我们不难看出其导数为:
但是如果使用计算图来计算导数,那么就需要有一定技巧才能求出这一正确的导数形式了。上式所对应的计算图如下图所示:
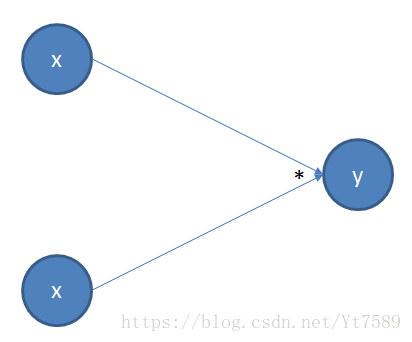
我们将
视为两个独立的变量x相乘。我们先来看正向传播,如下图所示:

我们将
和
代入左边两个节点,然后根据计算图到达右边的y节点,执行乘法操作
,最后得到最终的计算结果,与函数
的计算值相同。
我们接下来看求导的反向传播,如下图所示:
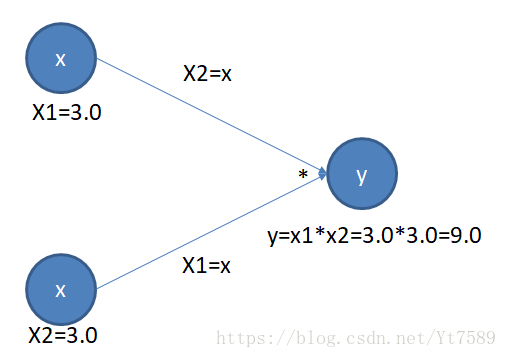
因为在我们的计算图中的公式为
,所以
,同理
,我们将导数结果写在对应的边上。根据计算图求导规则,对从最终节点到输入节点的全部路径,每条路径上边的导数值相乘,再将所有路径的导数值相加,根据这个计算图,可以得到如下算式:
由此可以看出,这与我们通过高等数学求导公式算出的结果相同。
有了这些知识,我们再来看深度学习框架中静态图和动态图的争论,我们可以有一个更清晰的认识。对于动态图来说,就是每次正向传播还是反向传输,均通过图的遍历方式进行。而静态图则通过对计算的编译,将正向传播和反向传播变为公式,这样就不用再来遍历计算图了,效率因此会提高不少。静态图虽然有很多优点,但是计算图不能动态调整结构,要学习一种元语言才能在计算图中引入条件和循环结构,在模型理解和编程复杂性方面,存在很大的问题。
有了上面这些知识,我们就可以来看一下,怎样通过TensorFlow Eager Execution技术来实现求导问题了。我们在这里假设想求出 的极值,代码如下所示:
def f1(x):
return x**2
def ad1(args={}):
tf.enable_eager_execution()
tfe = tf.contrib.eager
grad_f1 = tfe.gradients_function(f1)
threshold = 0.001
delta_x = 0.0001
x = 3.0
done = False
while not done:
rst = grad_f1(x)
dval = rst[0]
if dval > threshold:
x -= delta_x
elif dval < -threshold:
x += delta_x
else:
done = True
y = f1(x)
rst = grad_f1(x)
print('x={0}, y={1}; d={2}!'.format(x, y, rst[0]))运行结果如下所示:

需要指出的是,我们这里给出的代码实现,绝对是效率相当低的一种,如果我们真的想求极值,我们应该采用牛顿法等,收敛速度会成数量级的提高,具体可以参见我写的书《深度学习算法实践》。
我们在这篇博文里讨论了自动微分概念,这是可微编程的基础,在下面的博文中我们用这种新技术来实现各种机器学习和深度学习算法。