这里写目录:
一、Ubuntu中大数据开发【系统环境】搭建:
1、虚拟机只有一个Linux系统的开发(不推荐):
如果需要在一个Linux系统中进行开发,推荐独立出一个用户空间来进行开发(避免干扰)。
为什么要创建新用户:
用户之间是相互独立的,就像不同的分身系统一样,创建新用户方便我们独立进行开发工作。
但是这种方法是不推荐的,原因如下:
提示:在虚拟机里其实不建议一个虚拟机设置第二个用户来进行大数据开发,因为如果系统一崩,其他用户也用不了了,所以还是建议自己新开一个系统来独立进行大数据开发
虽然不推荐,但是我们还是需要把过程写出来给大家参考
(1)、命令行创建新用户(可选):
1、新建一个用户:
sudo useradd -m 用户名 -s /bin/bash
2、设置用户密码:
sudo passwd 用户名
3、给用户添加管理员权限(将用户加入到“sudo”组中):
sudo adduser 用户名 sudo
(2)、在系统设置中创建新用户(可选):
首先在设置中找到【用户】Users里,进行解锁,然后点击右上角【添加】add
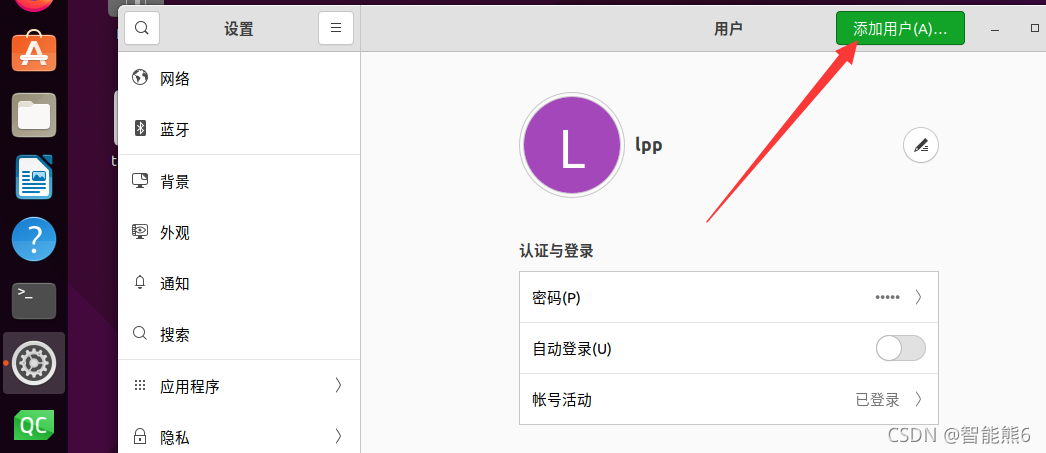
管理员方便我们进行开发。
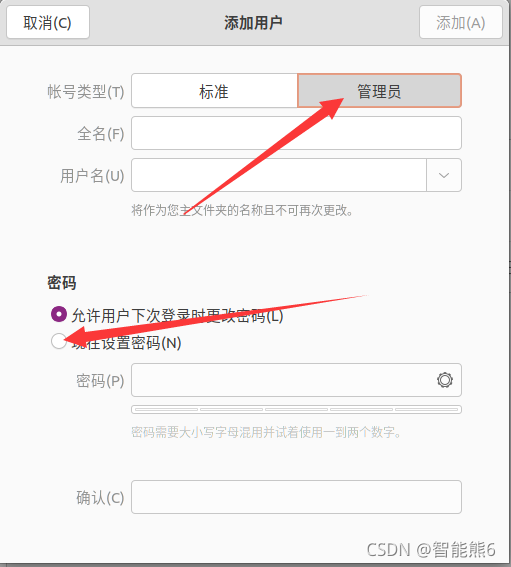
然后重启虚拟机,选择我们的新创建的用户,进入新用户(就像一个新的系统一样)
上面方法仅供参考,但不推荐,大家根据自己实际情况选择。
2、虚拟机独立一个Linux系统的开发(推荐):
在VM虚拟机中再开一个Ubuntu,然后再在这个系统中开发。
在这个“新”系统中,我们还需要:
(1)更新apt工具
sudo apt-get update
(2)使用apt工具安装Vim编辑器(写代码要用):
sudo apt-get install vim
(3)安装ssh服务端(客户端应该默认已经安装了)
sudo apt-get install openssh-server
//因为已经默认安装了客户端(client),所以我们只需要安装服务端(server)即可
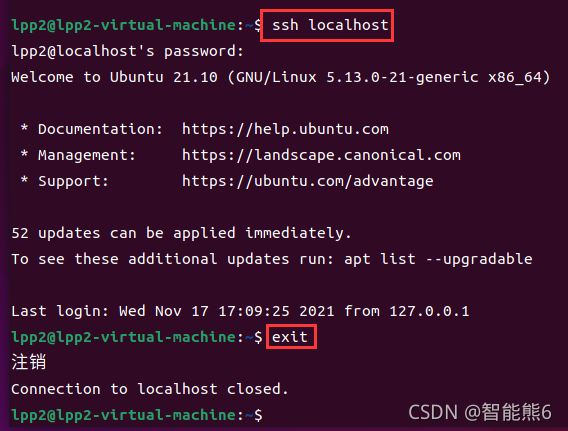
(4)安装完以后,使用ssh命令尝试登录(看看是否已经安装成功):
ssh localhost
如果有验证输入yes即可,下载配置完成以后重新登录即可。
(5)退出登录:
exit
设置无密码登录ssh服务端:
退出后,
(1)用ssh-keygen命令生成密钥:
cd ~/.ssh/
ssh-keygen -t rsa
然后一直按回车就行。
(2)将密钥加入授权:
cat ./id_rsa.pub >> ./authorized_keys
如果不会操作的可以参考下图我i的做法:
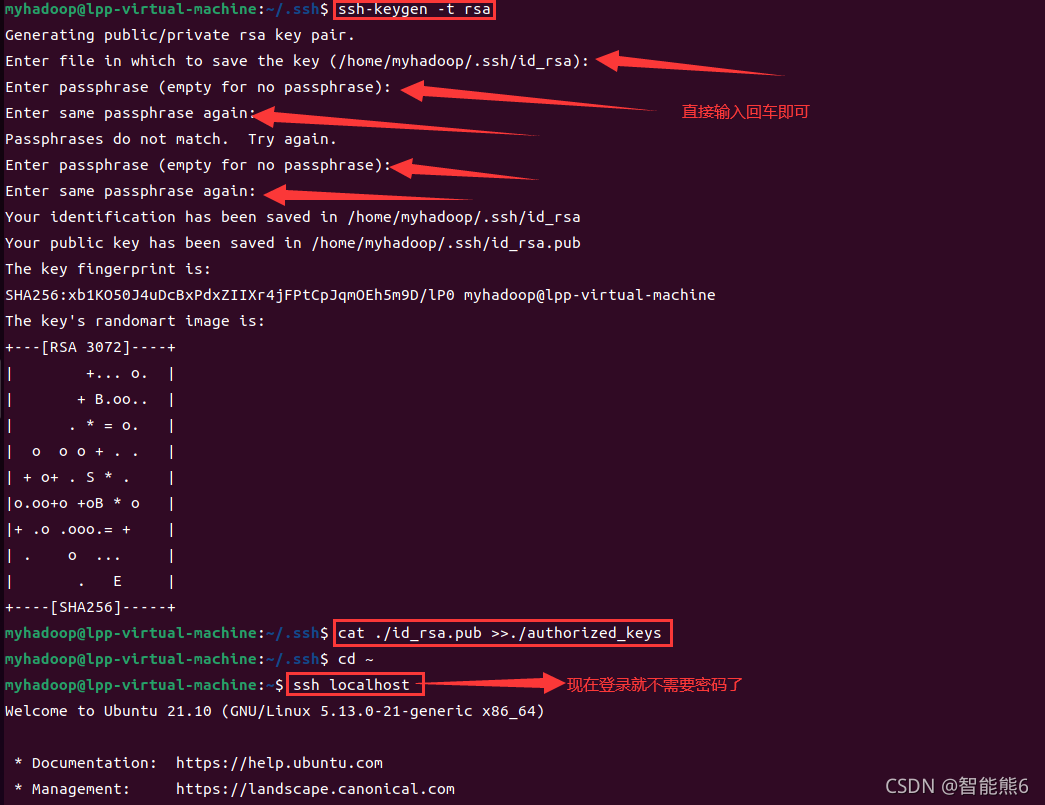
完成!!!如图,现在登录ssh就不需要输入密码了。
二、【Java环境】jdk下载安装和问题排查:
大数据框架依赖于Java语言,所以还需要再系统中搭建Java开发环境:
三、【大数据框架环境】下载安装Hadoop框架
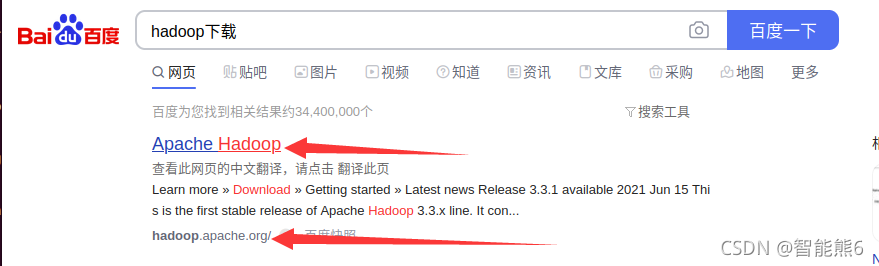
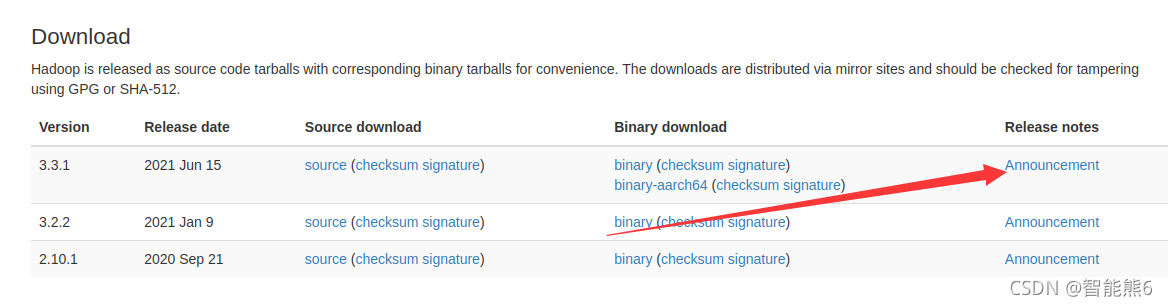
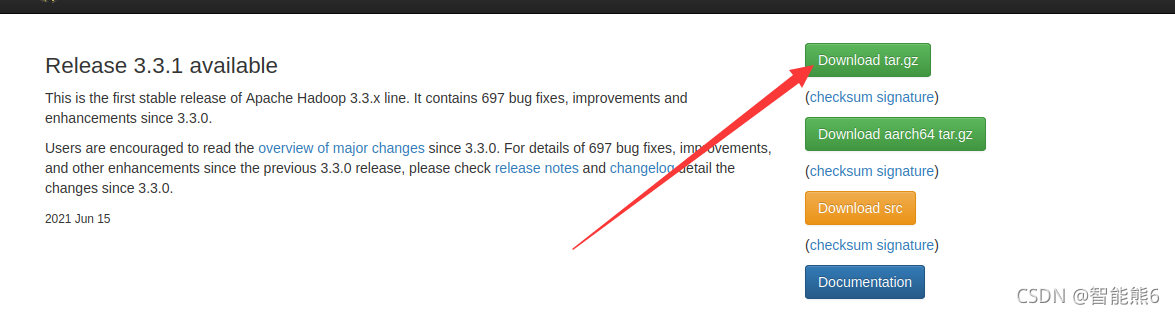
1、百度安装:

然后:
(1)解压安装:
注意,如果你的 目录以及变成中文,则需要(c是大写):
sudo tar -zxf ~/下载/hadoop-3.3.1.tar.gz -C /usr/local
sudo tar -zxf ~/Downloads/hadoop-3.3.1.tar.gz -C /usr/local
(2)修改文件名:
cd /usr/local
sudo mv ./hadoop-3.3.1/ ./hadoop
(3)修改文件权限:
sudo chown -R 用户名 ./hadoop
(4)查看当前版本(同时检查是否安装成功):
./hadoop/bin/hadoop version
(5)新建一个文件夹(input)来方便管理我们的文件:
cd /usr/local/hadoop
mkdir input
(6)将配置文件copy复制到新建文件夹下:
cp ./etc/hadoop/*.xml ./input
(7)运行Grep实例检查是否真的安装成功:
./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar grep ./input ./output 'dfs[a-z.]+'
(8)查看结果:
cat ./output/*
2、Hadoop的伪(一个Linux系统)分布式文件系统安装:
(1)、进入Hadoop安装目录(usr/local/hadoop)
(2)、一般配置文件都放在etc目录下,所以我们找一下:
(3)、最后配置成这样(复制即可,但是要注意版本名、路径要对应):
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
这是第二个配置文件:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
(4)、保存好上面两个配置文件的修改。
然后,
(5)、初始化——分布式文件系统(HDFS):
cd /usr/local/hadoop
./bin/hdfs namenode -format
然后
(6)、启动——分布式文件系统(HDFS):
如果目录不在这,先cd到这
cd /usr/local/hadoop
./sbin/start-dfs.sh
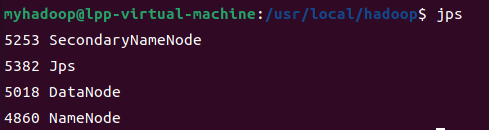
(7)、启动以后,输入jps即可查看当前正在运行的Java进程:
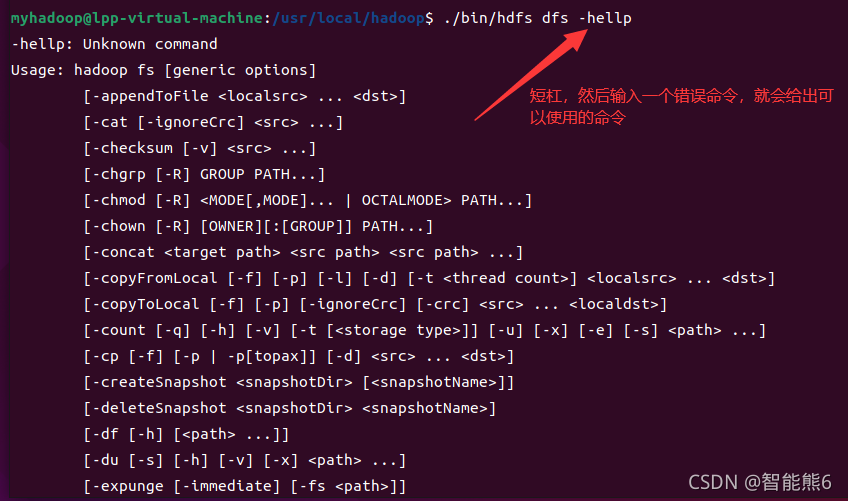
【可选】另外大家可以输入下面格式命令,来查看可以在分布式文件系统里使用的相关命令:
然后:hdfs端(分布式文件系统)的配置:
1、在hdfs端,使用它的命令,创建文件夹目录:
./bin/hdfs dfs -mkdir -p /user/hadoop/input
2、用put命令上传本地的配置文件到hdfs端(分布式文件系统)新建的文件夹
./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
3、运行Grep实例测试一下:
./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+'
4、查看结果:
./bin/hdfs dfs -cat /user/hadoop/output/*

注意:需要重新运行程序的时候,需要把之前在hdfs端创建的input文件夹删除:
在分布式文件系统端删除文件夹的命令如下:
./bin/hdfs dfs -rm -r /user/hadoop/input
停止hdfs端运行(如果需要):
/usr/local/hadoop/sbin/stop-dfs.sh
四、在linux下安装Idea(Java IDE)
因为需要编写Java语言,所以这个Java的集成开发环境(IDE)是必不可少的:
首先你也可以在应用商店里安装,有手就行,我就不啰嗦了。
下面只介绍官网安装方法:
(1)、首先当然是百度idea,然后进入官网,下载社区版(这就不用我多说了吧)
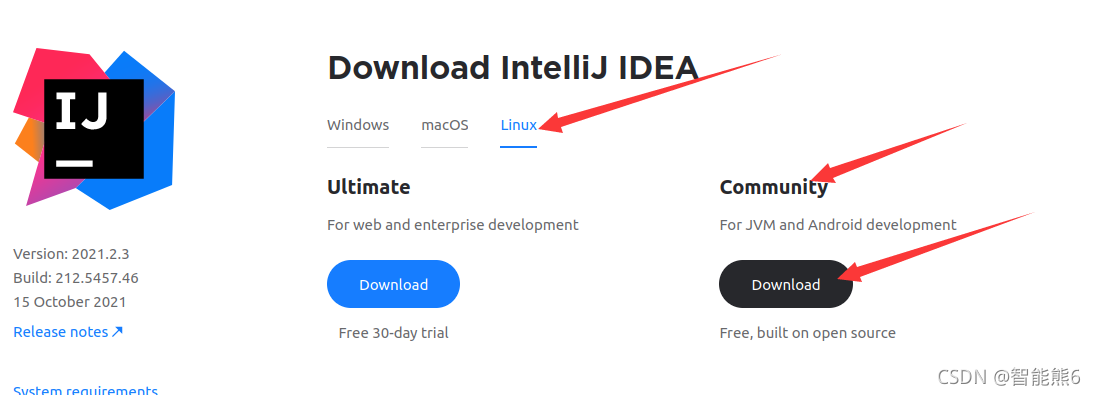
(2)、点击download之后:
(3)、下载完成后是一个tar.gz压缩包,一听到压缩包,首先我们应该解压(因为我们需要使用它):
这里我们直接解压到local目录下。
sudo tar -zxf ~/Downloads/ideaIC-2021.2.3.tar.gz -C /usr/local
如果你的目录是中文的话,需要改成:
sudo tar -zxf ~/下载/ideaIC-2021.2.3.tar.gz -C /usr/local
(4)、解压之后,我们就进入它的目录,就会发现它自带一个安装方法:
(5)、打开看看,看见它说要运行 ./idea.sh
那简单,直接输入命令的路径就能运行命令:
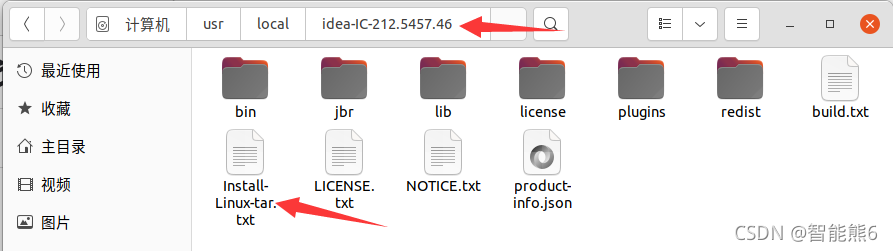
/usr/local/idea-IC-212.5457.46/bin/idea.sh
这样就会看到它弹出来安装界面了。
一般下一步就行。
五、【Hive环境】安装:
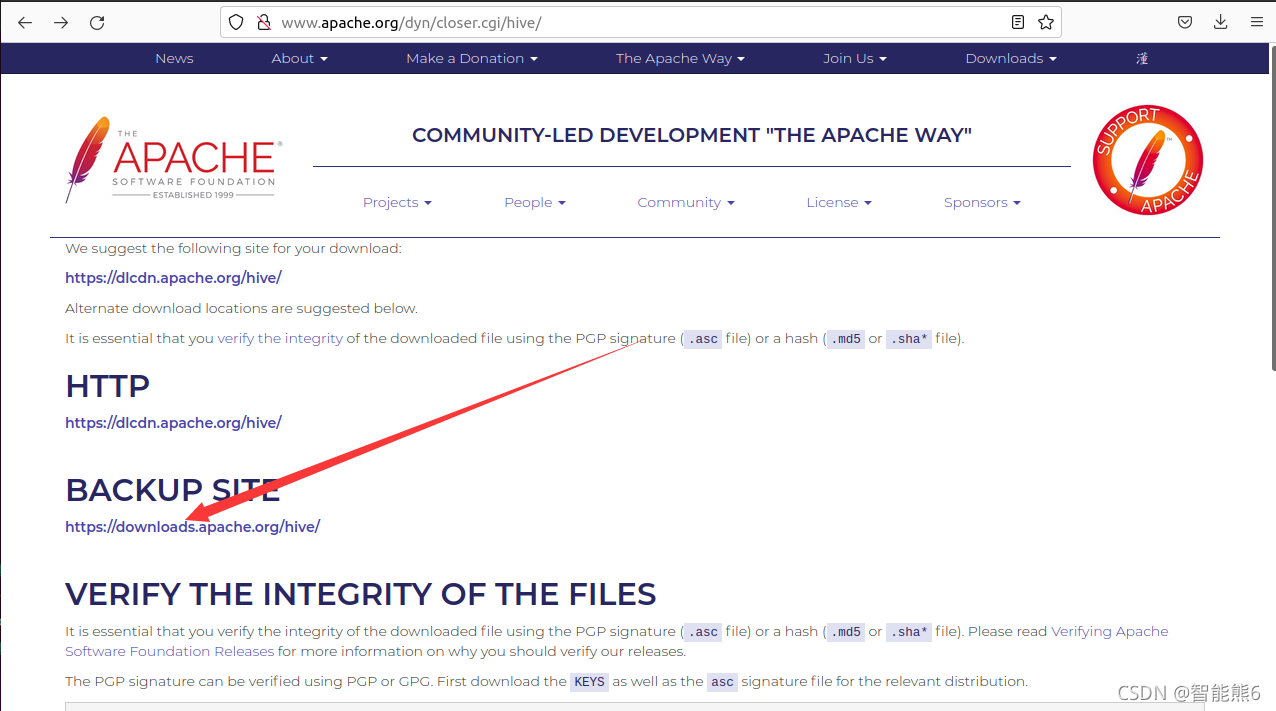
1、百度进入官网:
http://www.apache.org/dyn/closer.cgi/hive/
2、进入下载页面:
3、选择一个版本:
4、下载它的bin二进制版本:
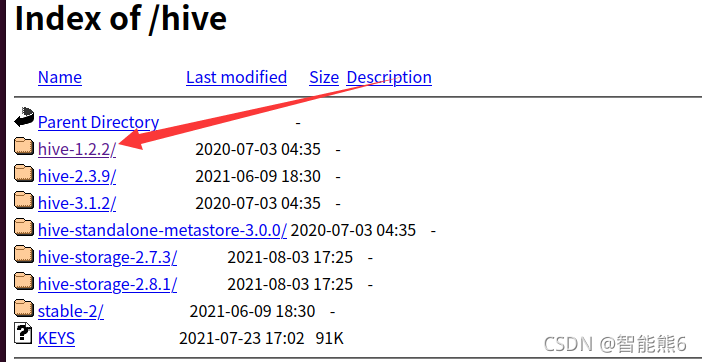
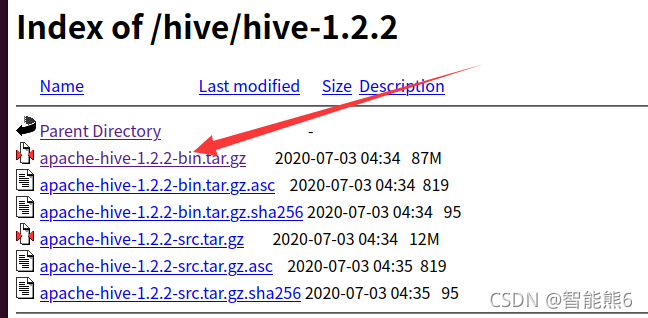
5、解压.tar.gz压缩包,解压到/usr/local,然后改一下文件名,和前面一样:
复制:
(1)解压安装:
注意,如果你的 目录已经变成中文,则需要(c是大写):
sudo tar -zxf ~/下载/apache-hive-1.2.2-bin.tar.gz -C /usr/local
sudo tar -zxf ~/Downloads/apache-hive-1.2.2-bin.tar.gz -C /usr/local
(2)修改文件名(原名太长了):
cd /usr/local
sudo mv ./apache-hive-1.2.2-bin/ ./hive
(3)修改文件权限(给权限):
sudo chown -R 用户名 ./hive
(4) 为了更方便使用命令,设置环境变量:
打开配置文件:
vim ~/.bashrc
输入环境变量,并保存退出:
(如果不知道,请参考:链接 》》》)
#定义它的路径
export HIVE_HOME=/usr/local/hive
#将他的bin路径给环境变量
export PATH=${
PATH}:${HIVE_HOME}/bin
#hadoop也要给个路径:
export HADOOP_HOME=/usr/local/hadoop
然后是配置立即生效:
source ~/.bashrc
然后输入:hive 命令就能看到效果。
(5)修改配置文件:/usr/local/hive/conf下的hive-site.xml
执行如下命令:
cd /usr/local/hive/conf
更改文件名字:把最后的.template删掉。
mv hive-default.xml.template hive-default.xml
当然,你也可以不使用命令:
新建一个配置文件hive-site.xml文件:使用vim编辑器:
cd /usr/local/hive/conf
vim hive-site.xml
在hive-site.xml中添加如下配置信息:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>
然后,冒号,wq保存 退出。
六、【MySql】
1、安装:
sudo apt-get install mysql-server
2、启动mysql
service mysql start
3、使用root命令(如果没有,请输入sudo passwd root设置密码)
su

4、登陆mysql的shell界面
mysql -u root -p
5、新建hive数据库。
mysql>下:
create database hive;
#这个hive数据库与hive-site.xml中localhost:3306/hive的hive对应,用来保存hive元数据
6.、配置mysql允许hive接入:
mysql>下:
grant all on *.* to hive@localhost identified by 'hive';
#将所有数据库的所有表的所有权限赋给hive用户,后面的hive是配置hive-site.xml中配置的连接密码
7、刷新mysql系统权限关系表
mysql>下:
flush privileges;
8、启动hive
(1)先启动hadoop集群:
start-all.sh
(2)再启动hive
hive