动机
- 全量训练的问题,样本量大,训练时间长,特征量大,同步时间长,每日全量训练,花费高,生效迟
- 增量训练的好处,增量训练花销低,生效块
发展
OGDFOBOS
RDA
FTRL
FTML
全部代码:https://github.com/YEN-GitHub/OnlineLearning_BasicAlgorithm
下面以逻辑回归为例实现每种在线学习
逻辑回归
1. 目标函数为交叉熵,
2. 预测输出为
3. 梯度更新公式为
代码如下:
class LR(object):
@staticmethod
def fn(w, x):
''' sigmod function '''
return 1.0 / (1.0 + np.exp(-w.dot(x)))
@staticmethod
def loss(y, y_hat):
'''cross-entropy loss function'''
return np.sum(np.nan_to_num(-y * np.log(y_hat) - (1-y)*np.log(1-y_hat)))
@staticmethod
def grad(y, y_hat, x):
'''gradient function'''
return (y_hat - y) * xOGD
更新公式为:
代码如下:
class OGD(object):
def __init__(self,alpha,decisionFunc=LR):
self.alpha = alpha
self.w = np.zeros(4)
self.decisionFunc = decisionFunc
def predict(self, x):
return self.decisionFunc.fn(self.w, x)
def update(self, x, y,step):
y_hat = self.predict(x)
g = self.decisionFunc.grad(y, y_hat, x)
learning_rate = self.alpha / np.sqrt(step + 1) # damping step size
# SGD Update rule theta = theta - learning_rate * gradient
self.w = self.w - learning_rate * g
return self.decisionFunc.loss(y,y_hat)TG
SGD方法无法保证解的稀疏性,而大规模数据集与高维特征又需要稀疏解,比较直观的方法是梯度截断法,当参数小于阈值时赋0,或者往0走一步,可以每k步进行一次截断

代码如下:
def update(self, x, y, step):
y_hat = self.predict(x)
g = self.decisionFunc.grad(y, y_hat, x)
if step % self.K == 0:
learning_rate = self.alpha / np.sqrt(step+1) # damping step size
temp_lambda = self.K * self.lambda_
for i in range(4):
w_e_g = self.w[i] -learning_rate * g[i]
if (0< w_e_g <self.theta) :
self.w[i] = max(0, w_e_g - learning_rate * temp_lambda)
elif (-self.theta< w_e_g <0) :
self.w[i] = min(0, w_e_g + learning_rate * temp_lambda)
else:
self.w[i] = w_e_g
else:
# SGD Update rule theta = theta - learning_rate * gradient
self.w = self.w - self.alpha * g
return self.decisionFunc.loss(y,y_hat)FOBOS
L1-fobos可以认为是TG的一种特殊情况,当,L1-FOBOS与TG等价,也是每次朝着梯度方向走一步,朝着0的方向走一步。相对于TG,FOBOS有了一套优化理论的框架,权重的更新分成以下两步

求解过程见博客:https://zr9558.com/2016/01/12/forward-backward-splitting-fobos/
得到算法更新公式:

转化为代码:
def update(self, x, y, step):
y_hat = self.predict(x)
g = self.decisionFunc.grad(y, y_hat, x)
learning_rate = self.alpha / np.sqrt(step + 1) # damping step size
learning_rate_p = self.alpha / np.sqrt(step + 2) # damping step size
for i in range(len(x)):
w_e_g = self.w[i] - learning_rate * g[i]
self.w[i] = np.sign(w_e_g) * max(0.,np.abs(w_e_g)-learning_rate_p * self.lambda_)
return self.decisionFunc.loss(y,y_hat)RDA
L1-RDA与L1-FOBOS不同的是考虑累积梯度的平均值,因此更容易产生稀疏解,具体算法介绍参见博客:
https://zr9558.com/2016/01/12/regularized-dual-averaging-algorithm-rda/
优化目标:

算法更新:
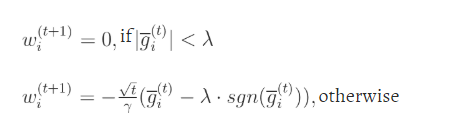
代码实现:
def update(self, x, y, step):
y_hat = self.predict(x)
g = self.decisionFunc.grad(y, y_hat, x)
self.g = (step-1)/step * self.g + (1/step) * g
for i in range(len(x)):
if (abs(self.g[i])<self.lambda_):
self.w[i] = 0
else:
self.w[i] = -1* (np.sqrt(step)/self.gamma)*(self.g[i] - self.lambda_ * np.sign(self.g[i]))
return self.decisionFunc.loss(y,y_hat)FTRL
ftrl综合考虑了RDA和FOBOS的梯度和正则方式,既考虑了之前所有的梯度,又考虑了L1正则与L2正则,优化目标如下:



self.w = np.array([0 if np.abs(self.z[i]) <= self.l1
else (np.sign(self.z[i] * self.l1) * self.l1 - self.z[i]) / (self.l2 + (self.beta + np.sqrt(self.q[i]))/self.alpha)
for i in range(self.dim)])
y_hat = self.predict(x)
g = self.decisionFunc.grad(y, y_hat, x)
sigma = (np.sqrt(self.q + g*g) - np.sqrt(self.q)) / self.alpha
self.z += g - sigma * self.w
self.q += g*g
return self.decisionFunc.loss(y,y_hat)