MHA
简介
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
原理
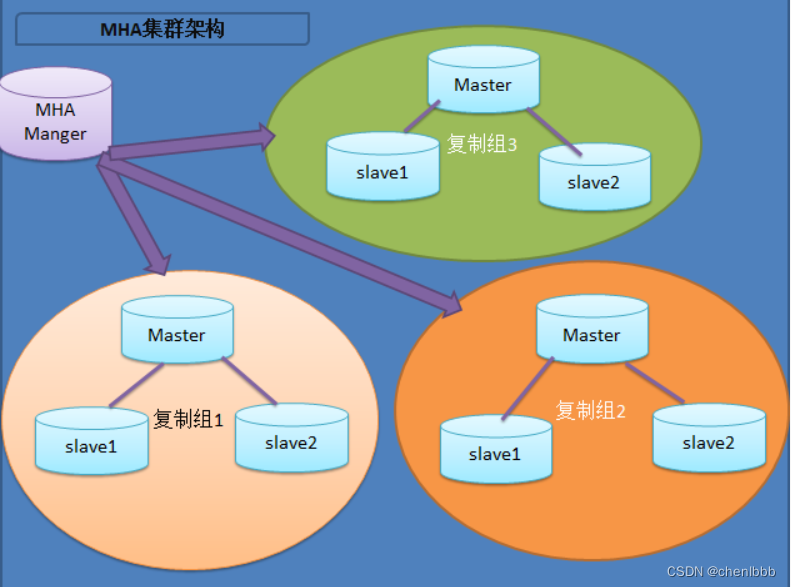
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
**在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。**例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
mha大致原理是manager进程会定期(一般是1s一次)探测主库节点,当主库出现故障时,mha会找到应用了最新日志的slave的binlog位置,并且拉取主库和最新从库的差异日志并应用到该从库上。,然后将该从库提升为master,并且将其他从库指向新主库,切换过程配合vip的漂移。

(1)从宕机崩溃的master保存二进制日志事件(binlog events);
(2)识别含有最新更新的slave;
(3)应用差异的中继日志(relay log)到其他的slave;
(4)应用从master保存的二进制日志事件(binlog events);
(5)提升一个slave为新的master;
(6)使其他的slave连接新的master进行复制;
软件架构
Manager工具包主要包括以下几个工具:
master_ip_failover 配置vip相关信息
masterha_check_ssh 检查MHA的SSH配置状态
masterha_check_repl 检查MySQL复制的状态
masterha_check_status 检查MHA当前的运行状态
masterha_manger 启动MHA
masterha_master_monitor 检测master是否宕机
masterha_master_switch 控制故障转移(手动或者自动)
masterha_conf_host 添加或者删除配置的server信息
Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs 保存和复制master的二进制日志
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave服务器
filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已经不在使用这个工具了)
purge_relay_logs 清除中继日志(不会阻塞SQL线程)
MHA如何保持数据的一致性呢?主要通过MHA node的以下几个工具实现,但是这些工具由mha manager触发:
save_binary_logs 如果master的二进制日志可以存取的话,保存复制master的二进制日志,最大程度保证数据不丢失
apply_diff_relay_logs 相对于最新的slave,生成差异的中继日志并将所有差异事件应用到其他所有的slave
软件部署原则
1.manager可以单独装在任意一台机器上;
2.一个manager可以管理多套mysql集群;
3.建议不要将manager装在主库上(防止主库断电,断网);
4.所有数据库必须安装node包;
5.manager的依赖有node
工作流程
monitor node 监控节点
(1) 监控所有节点,重点是master
(2) 监控到master宕机(实例(ssh能),主机(ssh不能连))
(3) 监控主从状态
failover 故障转移
(1) 对比各节点的GTID号码。
(2) 数据补偿1:如果ssh能连,从节点立即保存自己缺失部分的二进制日志
(3) 选主:对比各节点的GTID号码即可,选一个最接近于主库数据的从节点,恢复缺失的日志,并将从库切换为主库 stop slave reset slave all
(4) 数据补偿2:如果ssh不能连,计算两个从库的relaylog的差异,恢复到数据少的从库中.
(5) 2号从库change master to 到 新主,开启新的主从关系
故障切换备选主库的算法
1、一般判断从库的是从(position/GTID)判断优劣,数据有差异,最接近于master的slave,成为备选主。
2、数据一致的情况下,按照配置文件顺序,选择备选主库。
3、设定有权重(candidate_master=1),按照权重强制指定备选主。
默认情况下如果一个slave落后master 100M的relay logs的话,即使有权重,也会失效。
如果check_repl_delay=0的话,即使落后很多日志,也强制选择其为备选主。