本文作者本人,首发在 "便利蜂产品技术" 微信公众号。欢迎各位关注。
便利蜂校招内推链接:https://app-tc.mokahr.com/m/recommendation-apply/bianlifenghr/8007?sharePageId=9193&recommendCode=NTAANCF&codeType=1&hash=%23%2Frecommendation%2Fpage%2F9193
便利蜂社招内推链接:http://bianlifeng.gllue.me/portal/share_url/0b9e0fe4-a3ec-4bbb-a541-e65d83cf6364
首发链接:基于MySQL binlog日志,实现Elasticsearch近实时同步实践
当前页面内容非企业官方发布渠道,仅为作者自行分发。
背景
在我们的开发过程中,经常会在一个项目中使用多种数据库系统。在一些特定场景下,我们希望把数据从一种数据库,同步到另一种异构的数据库,以便进行数据分析统计、完成实时监控、实时搜索等功能。这个异构数据源同步的过程称为Change Data Capture(变化数据捕获)。
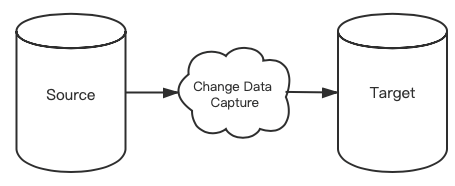
我们本文讨论的是Source为MySQL、Target为ElasticSearch的场景下,进行增量和全量同步操作过程。众所周知,MySQL数据库凭借其性能卓越、服务稳定、开放源代码、社区活跃等因素,成为当下最流行的关系型数据库,但是在数据量级较大或涉及到多表操作时,亦或是需要根据地理位置进行查询时,MySQL通常不能给我们很好的支持。
为了解决MySQL查询缓慢、无法查询的问题,我们通常采用ElasticSearch等进行配合检索。在传统方式中,将MySQL同步数据到ElasticSearch通常采用的是双写、MQ消息等形式,这些形式都存在着耦合高、性能差、丢失数据等风险。
所以我们需要探索出一套对业务无侵入的MySQL同步至ElasticSearch异构数据库的解决方案。本文将分别从增量同步、全量同步两个层面进行探讨。
增量同步
架构
将MySQL数据实时增量同步至ElasticSearch中,一般会借助MySQL增量日志binlog实现。目前比较流行的binlog解析获取中间件是由Alibaba开源的Canal,Canal译意为水道/管道/沟渠,主要用途是基于MySQL数据库增量日志解析,提供增量数据订阅和消费。
所以我们整体的解决方案为:上游通过Canal将解析好的binlog消息发送到Kafka中,下游通过一个Adapter进行解析配置、消费消息。
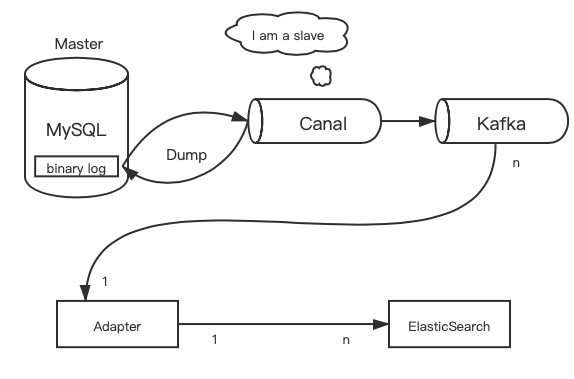
参考上面的图片,我们可以知道整体分成了三个步骤:
-
Canal通过伪装成MySQL Slave,模拟MySQL Slave的交互协议,向MySQL Master发送dump协议,MySQL Master收到Canal发送过来的dump请求,开始推送binlog给Canal,然后Canal解析binlog;
-
Canal将解析序列化好的binlog信息发送到Kafka;
-
Adapter根据用户配置信息,接收Kafka中的信息解析处理,将最终数据更新到ElasticSearch的操作。
Adapter设计思路
经过调研,Adapter决定采用通过SQL语句配置,系统根据SQL进行解析获得所需表及字段映射关系形式。解析这一过程利用开源数据库连接池Druid实现。
比如下面的演示,用户配置了一条SQL语句,系统自动解析确定ElasticSearch的字段信息,并缓存MySQL的表和字段与ElasticSearch的字段映射关系。
使用者可以通过定义字段的别名设置在ElasticSearch中的对应字段名,同名字段则不需要别名。

Adapter的整体流程可以用下图表示:
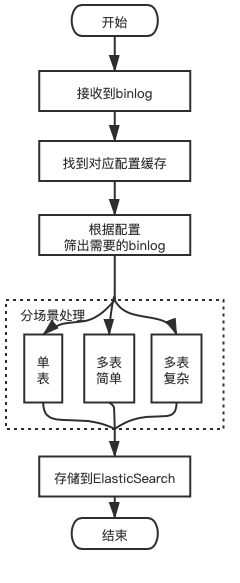
分场景处理
我们已经明确了整体的架构思路,接下来我们需要考虑需要在编写Adapter的过程中,让他具备哪些解析能力。
单表场景
单表同步是最简单的同步场景,当数据库中一张表内容发生变化,将需要的字段提取并写入ElasticSearch中。
举个例子,我们现在有一张student表,我们希望将其中的id、name、age、birthday字段信息信息同步到ElasticSearch,如下图:
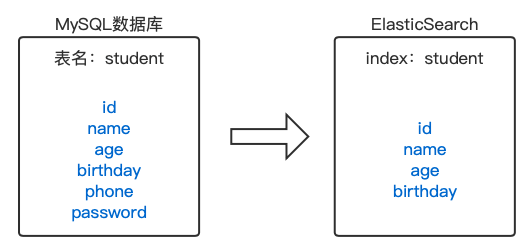
那么需要配置的语句是:
SELECT
s.id AS _id,
s.id,
s.name,
s.age,
s.birthday
FROM
student s;其中_id表示的是ElasticSearch唯一标识;id是ElasticSearch中实际的字段。
我们需要做的也相对简单,只是将原有数据进行过滤,将需要的数据写入ElasticSearch中即可。
多表简单场景
多表同步是指两张表利用Left Join进行关联的场景,一般是左表的一个字段记录了右表的id信息,将两张表Left Join后即可获取到所有需要的信息。
举个例子,我们希望记录下学生的班级信息,所以在学生表中添加了class_id字段,字段对应class表的id字段;
如下图两张表,我们希望将student表和class表关联,在ElasticSearch中储存其中的id、name、class_id、class_name信息。
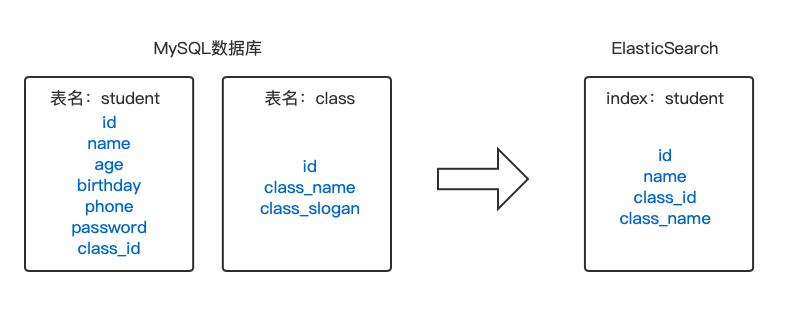
那么我们可以配置成下面的形式:
SELECT
s.id AS _id,
s.id,
s.name,
c.class_id,
c.class_name
FROM
student s
LEFT JOIN class c
ON s.class_id = c.id;首先,我们约定将具有关联性质的字段称为关联字段,比如上面SQL的student表的class_id字段和class表的id字段都是关联字段。
针对这种场景,Adapter会同时监听两张表的更新,分别是:student和class,并针对更改的字段确定需要解决的方式:
-
左表非关联字段:直接通过binlog中的信息更新到ElasticSearch中;
-
右表非关联字段:搜索ElasticSearch确定影响范围后,将修改数据写入ElasticSearch中;
-
关联字段更新:通过在SQL语句后拼接where条件查询MySQL后更新。
多表复杂场景
多行变一行
将多行数据变为一行数据也是多表关联的一种形式,一般会将多条数据使用指定的拼接符号进行连接。
比如:一个同学需要学习的多种课程、一个联系人的多个手机号码等。
举个例子,我们现在还有一张学生家长表:parent,我们期望在ElasticSearch中储存学生的全部家长姓名信息,包括student的id、name、age和parentNames。parentNames是此学生的所有家长姓名,并用逗号分隔。如下图:
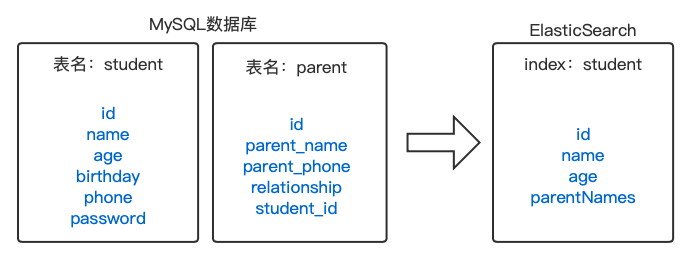
那么我们可以通过配置下面的语句实现这种效果:
SELECT
s.id AS _id,
s.id,
s.name,
s.age,
p.parentNames
FROM
student s
LEFT JOIN (
SELECT
student_id,
group_concat( parent_name ORDER BY id DESC SEPARATOR ',' ) AS parentNames
FROM
parent
GROUP BY
student_id
) p
ON s.id = p.student_id字段子查询
上面多行变一行的例子还可以通过字段子查询来实现,我们可以配置下面的语句:
SELECT
s.id AS _id,
s.id,
s.name,
s.age,
(
SELECT
group_concat(
p.parent_name
ORDER BY
p.id DESC SEPARATOR ','
) AS parentNames
FROM
parent p
WHERE
p.student_id = s.id
GROUP BY
p.student_id
) parentNames
FROM
student sAdapter会在解析配置的时候缓存子查询表和外层数据表的关联关系,并在感知到不同数据表变化时做出不同动作:
-
parent表更新:获取关联字段student_id信息,在整个SQL后拼接外层表的字段限定条件,比如s.id = ××。查询后更新;
-
student表更新:获取主表的id字段,在整个SQL后拼接限制条件查询后更新。
当然,Adapter也支持更加复杂的形式,比如在子查询中是Left Join或外层查询是Left Join的场景。
储存到ElasticSearch
从获取binlog到储存至ElasticSearch,我们需要保证一些特性,解决一些问题。
关注特性
顺序性
在单表和多表的部分场景,我们并不会回到MySQL中再次查询最新的数据,直接将binlog中的数据置入ElasticSearch意味着我们必须保证整体的顺序性。
如果我们错误的处理了两条binlog的顺序,我们很有可能导致写入的数据只是更新过程的一个中间版本而不是最终版本。
顺序性包括了binlog本身有序性和Adapter处理的顺序性。
MySQL5.6之前版本通过prepare_commit_mutex锁保证MySQL数据库上层二进制日志和Innodb存储引擎层的事务提交顺序一致。在5.6及之后版本通过引入BLGC(Binary Log Group Commit), 将二进制日志的提交过程分成三个阶段,Flush stage、Sync stage、Commit stage,实现二进制日志和实际提交顺序一致。
而Adapter的有序解析我们可以通过数据库关联分组分topic传递实现。那么什么是具有关联性的数据表呢?举个例子,用户配置了以下三条SQL语句:
SELECT
a.id AS _id,
a.student_name,
a.student_age,
a.class_id,
b.class_name,
b.teacher_name
FROM
student a
LEFT JOIN teacher b
ON a.teacher_id = b.id;
SELECT
b.id AS _id,
b.teacher_name,
b.teacher_age,
b.campus_id,
c.campus_address,
c.campus_name
FROM
teacher b
LEFT JOIN campus c
ON b.campus_id = c.id;
SELECT
d.id AS _id,
d.class_name,
d.class_introduce
FROM
class d;我们可以看到前两条语句都涉及到了teacher表,另外还分别涉及student表和campus表;第三条语句仅涉及到class表。由于前两条语句同步时都需要依赖teacher的binlog,所以我们将student、teacher、campus设为一组,将class设为一组。同组的binlog数据需要保证有序性。
由于Adapter通过下游的定义很难影响上游Kafka的Partition分配,所以我们推荐的做法是每组都采用单topic单Partition进行传递。当然,Adapter内部也有分组的机制,如果多组混合传递我们也能够完美的进行分组多线程高效解析处理。
可靠性
我们如果期望保证ElasticSearch和MySQL数据库中的数据一致,我们就需要完整的处理每一条binlog,不会出现丢消息的场景。所以,我们需要保证可靠性。
可靠性即保证每一条消息都被消费,不会出现丢消息或因重复消费带来的错误,所以我们需要实现消费幂等性。
考虑到Adapter同步程序可能面临各种正常或因异常情况出现的退出,所以我们利用Kafka的手动Offset机制,在确定一条Message数据被成功写入ElasticSearch后,才Commit该条Message的Offset,这样就保证了不会丢消息。
对于不回表查询直接向ElasticSearch置入数据且类型是Update的场景中,我们会对ElasticSearch中数据初始态进行判断,确认和binlog数据中oldData信息一致时,我们才会进行更新;对于回表场景已经获得最新数据,所以重复消费也不会造成影响。
解决问题
批量提交
为了提高速度,ElasticSearch将采取批量提交的形式提高整体速度,调用添加方法将会自动根据不同ElasticSearch服务集群储存进入不同的BulkRequest对象,在该组全部处理完成后进行提交。
JSON数据
我们必须承认,在MySQL中储存JSON并不是一种优雅的问题解决方案,但是在一些场景下我们依旧会在MySQL中储存JSON字符串。
在我们的Adapter中,我们提供了自动识别JSON并以嵌套文档的形式进行插入的能力;当然,在使用这项功能之前我们必须保证同一个名称的对应内容都是相同类型。
Geo数据
在MySQL中,经纬度通常是两个字段,但是我们在储存到ElasticSearch中期望储存为一个geo_point类型;亦或是MySQL中将一个多边形数据储存为了一个字符串,我们在储存到ElasticSearch中期望储存为一个geo_shape类型。
这时候仅靠简单的同步更新并不能解决,尤其是地理位置多边形等geo_shape场景。我们最终选择通过标记函数的形式进行处理,配置用户通过自定义的geo_shape标记函数示意系统需要对字段进行解析,Adapter解析SQL的时候通过用户自定义的函数获取需要被解析处理的字段。
例如下面这条SQL:
SELECT a.id as _id, geo_shape(a.geo_shape) FROM geography;
值得一提的是,在ElasticSearch中,经常会因为地理坐标图形构建不合法导致无法存储,所以我们在更新地理类的数据类型之前都会利用spatial4j提前进行判断,如果存在问题直接上报监控中心实现自动感知和通知。
内容过滤
我们的Adapter更希望能够根据用户的定义,灵活选择转储到ElasticSearch的数据。其中不乏很常见的使用场景逻辑删除,但是目前开源的Adapter对于where条件的支持通常都存在问题。
我们结合已有开源Adapter的issue分析了一下导致where删除逻辑失效的原因:①单表更新不回表查询,所以没有机会拼接where查询 ②回表查询到符合条件的更新进ElasticSearch,但是ElasticSearch原有符合但现在不符合数据不能及时删除。
为了解决这两个问题且提高效率,我们选定方案为允许用户配置MVEL表达式,在提交前解析表达式对即将提交数据进行校验,符合则提交,如果不符合就根据 _id 将ElasticSearch中对应数据进行删除,并停止向ElasticSearch更新本条数据信息。
小结
目前我们已经支持了以上功能,从线上的监控来看,单条消息平均处理时长在30ms左右;P99在80ms左右,基本符合线上实际业务需求。
全量同步
概述
全量同步相比于增量同步简单了许多,全量同步的主要功能是将MySQL中的数据优雅且完整的置入到ElasticSearch中。
这看起来也十分容易,通过SQL查询的形式,将查询结果写到ElasticSearch中就可以,在这个过程中我们需要提前考虑哪些问题呢?
关注点
深分页和丢数据
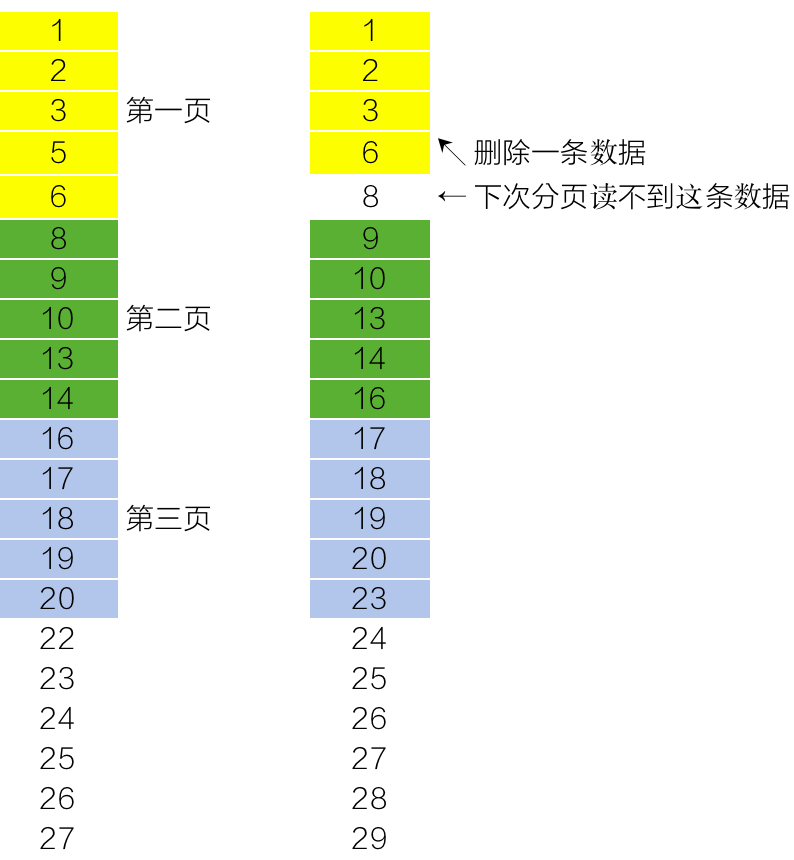
深分页会造成较大负担比较容易理解,深分页可能还会带来漏处理的问题。比如在id较小的部分删除一条数据,深分页可能导致分页接缝出现变化,当前处理页和下一页可能出现丢失数据。
比如下图中的例子,我们深分页每次获取5条数据,由于第一次获取之后用户删除了第4条信息为 “5” 的数据,导致下一次分页直接从“9”开始,造成信息为 “8” 的数据被漏处理。我们的解决办法就是采用根据id范围进行更新。
全量增量互相影响
我们来举一个场景的例子来更好的理解这种影响:
-
程序读取 id 为 1 ~ 1000 的数据到内存准备全量更新
-
MySQL修改 id = 100 的数据其中 name 由“张三”改为“李四”
-
程序正常进行增量更新,校验ElasticSearch中_id为100的数据name为“张三”,将其更新为“李四”
-
程序全量处理完毕,将1 ~ 1000 条数据写入ElasticSearch,其中_id为100的数据name被写为“张三”
-
全量继续进行,直至结束
在此过程中,数据库中id为100的数据name是“李四”,但是由于全量更新和增量更新彼此影响导致ElasticSearch的数据被误写为“张三”。
我们可以通过分段锁的形式细化锁的粒度,实现全量同步同时进行增量同步。
结语
异构数据库的同步一直以来都是一个相对复杂的问题,希望能够对通过本文帮助大家对于异构数据库同步有更多了解,同时为大家提供更多的思路和帮助。
作者
齐同学,便利蜂营建和设备技术团队的2021届校园招聘应届生。
最后,便利蜂正在寻找优秀的伙伴,每一份简历我们都会认真对待,期待遇见。
-
邮箱地址:[email protected]
-
邮件标题:营建和设备技术团队
PS:可以直接从文章最上面内推链接投递呀~