在MapReduce作业中,框架保证Reducer收到的key是有序的。利用这一点,我们可以对Avro文件进行排序。
假设我们有如下的Schema:
{"namespace": "me.lin.avro.mapreduce",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]
]
}现在我们有一个无需的avro文件,样例如下:
如何生成这些数据,请参考这里。
我们现在需求是根据favorite_color进行排序。
Avro不同于其他序列化框架的地方之一就是读写的Schema可以不一样。用前面的Schema写入的文件,我们再读取的时候,可以使用另一个兼容的Schema来读取,为了排序,我们再favorite_color字段加上顺序:
{"namespace": "me.lin.avro.mapreduce",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"] , "order":"descending"}
]
}注意order设置为descending倒序,也就是根据字母倒序。我们使用这个带顺序的Schema去读取原来没有顺序的文件,并利用MapReduce的shuffle过程中会进行排序这一点,实现最终的排序目标。
Mapper和Reducer
Mapper的逻辑是读取文件中的记录(作为key输入),针对每一对key-value,往Context中写入key-key的形式,也就是说将输入的key同时作为输出,传送到Reducer。代码如下:
public static class SortMapper<K> extends
Mapper<AvroKey<K>, NullWritable, AvroKey<K>, AvroValue<K>> {
@Override
protected void map(AvroKey<K> key, NullWritable value, Context context)
throws IOException, InterruptedException {
context.write(key, new AvroValue<K>(key.datum()));
}
}Reducer收到根据key分值的键值对,是根据key排序过的,由于Mapper中每一个key对应输出了相同值的value,因此对于Reducer收到的一个key,其列表值也是对应有序的,直接输出到avro文件即可完成排序,代码如下:
public static class SortReducer<K> extends
Reducer<AvroKey<K>, AvroValue<K>, AvroKey<K>, NullWritable> {
@Override
protected void reduce(AvroKey<K> key, Iterable<AvroValue<K>> values,
Context context) throws IOException, InterruptedException {
for (AvroValue<K> val : values) {
context.write(new AvroKey<K>(val.datum()), NullWritable.get());
}
}
}运行作业
我们通过Tool来运行作业,代码如下:
@Override
public int run(String[] args) throws Exception {
if (args.length != 3) {
System.err
.printf("Usage: %s [generic options] <input> <output> <schema-file>\n",
getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
String input = args[0];
String output = args[1];
String schemaFile = args[2];
@SuppressWarnings("deprecation")
Job job = new Job(getConf());
job.setJarByClass(getClass());
job.getConfiguration().setBoolean(
Job.MAPREDUCE_JOB_USER_CLASSPATH_FIRST, true);
FileInputFormat.setInputPaths(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output));
AvroJob.setDataModelClass(job, GenericData.class);
Schema schema = new Schema.Parser().parse(new File(schemaFile));
AvroJob.setInputKeySchema(job, schema);
AvroJob.setMapOutputKeySchema(job, schema);
AvroJob.setMapOutputValueSchema(job, schema);
AvroJob.setOutputKeySchema(job, schema);
job.setInputFormatClass(AvroKeyInputFormat.class);
job.setOutputFormatClass(AvroKeyOutputFormat.class);
job.setOutputKeyClass(AvroKey.class);
job.setOutputValueClass(NullWritable.class);
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String... args) throws Exception {
int exitCode = ToolRunner.run(new AvroSort(), args);
System.exit(exitCode);
}所有代码都放在AvroSort.java中。
将项目打包,准备好待排序文件及有序的Schema,然后运行作业:
hadoop jar avro-mapreduce-0.0.1-SNAPSHOT-jar-with-dependencies.jar me.lin.avro.mapreduce.AvroSort /input/avro/users.avro /output/avro/mr-sort ./user.avsc入口类AvroSort接受三个参数:输入文件,输出目录及schema文件。注意shcema文件配置的路径是当前机器的路径,不是HDFS上的路径。运行效果如下:

使用Avro tool包的tojson工具查看排序后的结果:
java -jar avro-tools-1.8.1.jar tojson part-r-00000-sort.avro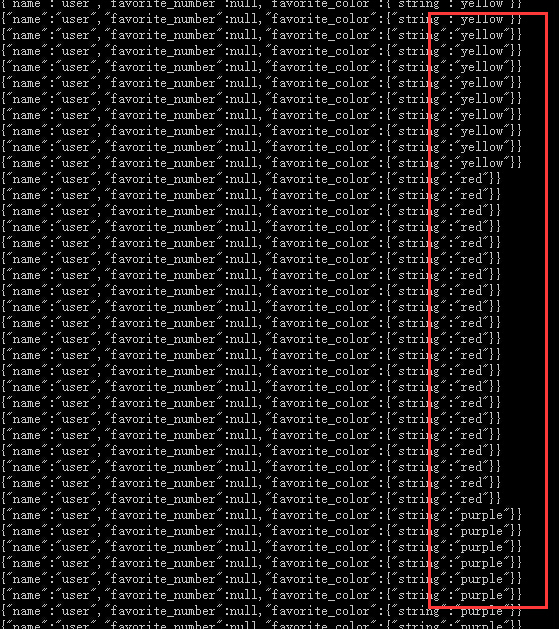
可以看到是根据favorite_color倒排的。
原文:https://blog.csdn.net/bingduanlbd/article/details/52013941
参考官方文档:http://avro.apache.org/docs/current/mr.html