为什么要用Redis实现商户查询缓存?
- 缓存是数据交换的缓冲区,是存储频繁用的数据的临时区,要求读写性能高,redis基于内存读写的高性能特点恰恰满足这一要求
- 用redis实现缓存可以降低后端负载,提高读写效率
- 增加缓存功能会增加成本,如数据一致性成本,代码维护成本,运维成本等,因此要根据业务场景选择合适的redis功能和机制
用Redis实现商户查询缓存的基本思路?
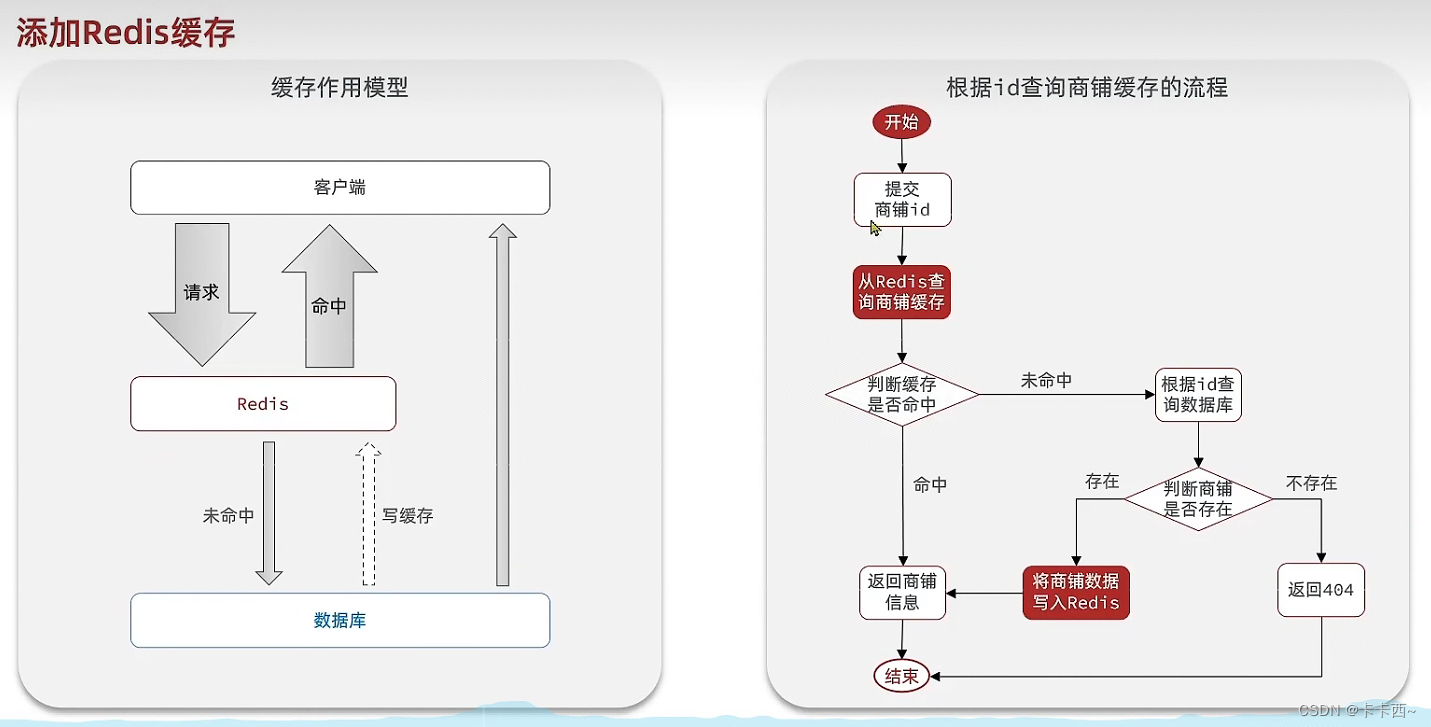
- 如果没有缓存,客户端频繁发出请求查询一个数据时,每次请求都会直接到达数据库,数据库的压力会很大
- Redis缓存相当于在客户端和数据库之间增加了一个拦截,当客户端发出请求查询数据时,先到达Redis查询,如果命中直接返回查询结果,因此该请求就不会到达数据库,降低了数据库的压力
- 如果在Redis中请求没有命中,该请求才会继续去数据库,将数据库的查询结果返回客户端
- 若该客户端多次重复请求这个在Redis中不存在的数据,还是会多次请求数据库,这并不是我们希望的结果,因此数据库应该将查询结果返回客户端的同时,将查询结果也写入redis缓存中
使用Redis缓存的问题及解决方法?
一、如何保持数据库数据和Redis缓存数据的一致性?
- 数据一致性要求较低:数据变化频率较低,用内存淘汰机制就行
- 数据一致性要求较高:数据变化频率较高,用主动更新,并用超时剔除当兜底
1 内存淘汰机制
- redis为了解决内存不足的问题,自带的一种功能,会在内存不足时自动淘汰部分数据,下次查询该数据时更新缓存,在一定程度上可以保持数据的一致性
- 优点:维护成本几乎为0,全程有Redis自己管
- 缺点:不知道会淘汰掉哪些数据,什么时候淘汰,所以数据一致性比较差
2 超时剔除机制
- 给缓存数据添加TTL时间,到期后自动删除缓存,下次查询时更新缓存
- 优点:维护成本较低,只需要在原来数据的基础上增加一个过期时间
- 缺点:可以控制哪些数据什么时候淘汰,数据一致性比内存淘汰机制好一些,但也不强
3 主动更新机制(胜)
- 在修改数据库中数据的同时,更新缓存
- 优点:数据一致性比较好
- 缺点:维护成本高,需要自己编写大量的业务逻辑,比较难
如何实现主动更新机制?
- 实现的第一种方案:自己写代码,在更新数据库的同时更新缓存(实际业务中用的最多)。
- 实现的第二种方案:将缓存与数据库整合成一个服务,只需调用该服务,数据一致性由服务内部自己实现。但维护该服务比较难,也较难找到现成的服务可用
- 实现的第三种方案:调用者不管数据库,只在缓存中增删改查,缓存一直保持最新的数据。由一个专门的线程通过异步的方式将缓存的数据更新到数据库中,保证数据最终一致。异步机制可以大大提升效率,主要体现的场景为,假如缓存中的某个数据更新了n次,此时异步线程来检查缓存中的数据有没有变化,然后将最新的数据写入数据库,相当于数据库只更新了1次,而数据库的读写比缓存读写费劲多,所以节省了更新n-1次数据库浪费的时间。缺点是维护异步线程的成本、Redis宕机丢失数据、在异步线程更新数据库之前数据完全不一致。
操作缓存和数据库时应该更新缓存还是删除缓存?
- 更新缓存:每次更新数据库时都需要更新缓存,对于缓存来说无效的写操作比较多
- 删除缓存:更新数据库时删除缓存中的数据,更新n次也只删一次,只有客户端用到该数据时,访问redis缓存,redis中没有该数据,才会从数据库中取最新的数据写到缓存中。
如何保证缓存与数据库的操作的原子性?
- 意思就是更新数据库的时候必须保证删除缓存也成功执行,二者要么都成功,要么都失败
- 对于单体系统:将缓存与数据库操作放在一个事务中
- 对于分布式系统:利用TCC等分布式事务方案
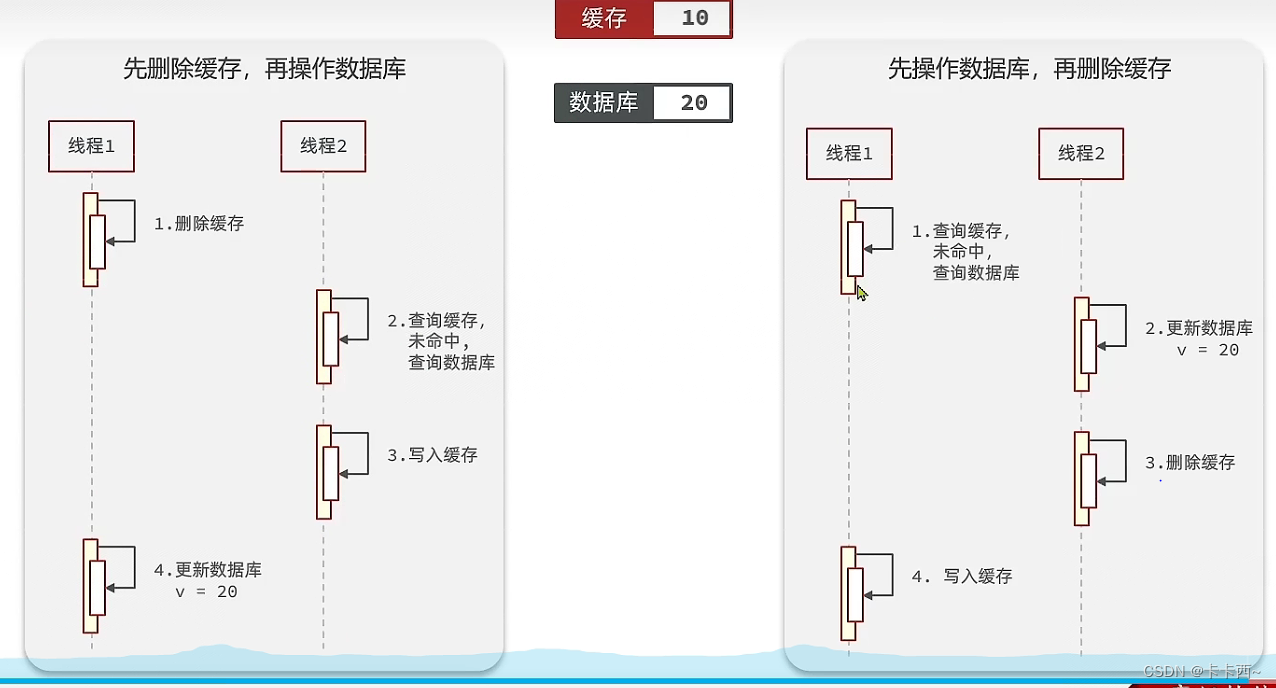
先删除缓存还是先操作数据库?
- 在多线程情景下,二者的执行顺序不一样会造成不一样的后果
- 先删除缓存:假设线程1先删缓存后更新数据库,线程2在线程1刚删完缓存还没更新数据库时突然请求,此时缓存中的数据已经被删,线程2会去数据库中查询,但线程1还没更新数据库,因此线程2查到的是旧数据,还会把旧数据按照流程写入缓存,此时线程1再更新数据库,就会造成数据不一致
- 先更新数据库:假设线程1先更新数据库后删除缓存,线程2在线程1更新数据库之前请求,恰好缓存由于某些原因失效,线程2便查询数据库返回客户端一个旧数据,此时线程2正常更新数据库删除缓存,线程1再继续将刚才从数据库中读到的旧数据写入缓存,此时就会造成数据不一致
- 先更新数据库造成的数据不一致的可能性更低,且可以为缓存增加TTL,在一定程度上避免该问题的发生,因此应该先更新数据库后删除缓存
二、缓存穿透?
客户端请求的数据在缓存和数据库中都没有,无法建立缓存,如果多次请求这个不存在的数据,这些请求就会全部打到数据库,给数据库造成压力
解决方案1 缓存空对象
- 简单暴力,返回一个空值null,下次请求再来时会在缓存命中null,不会继续请求数据库
- 优点:实现简单,好维护
- 缺点1:如果有很多不同的请求的数据不存在,就会在缓存中存很多null,造成额外的内存消耗。解决方法:可以给null也增加一个TTL,避免长期占用缓存空间。
- 缺点2:在null过期之前的请求得到的数据都是null,如果此时数据库更新了数据,就会造成短期的不一致。解决方法:用主动更新机制,在更新数据库的同时替换掉null
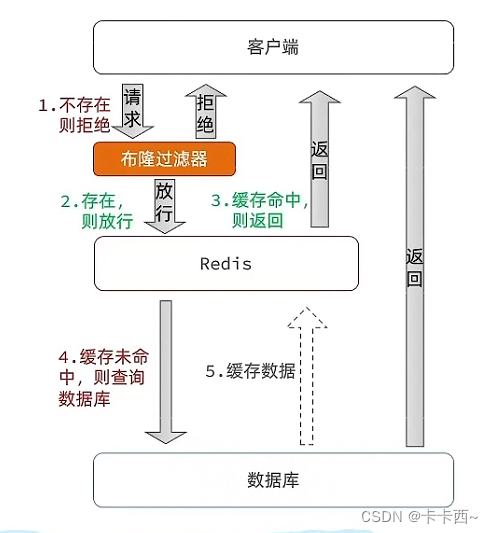
解决方案2 布隆过滤器
- 在客户端和Redis之间增加布隆过滤器,当客户端发出一个请求时,首先由布隆过滤器判断该数据是否存在,若存在则放行,请求会继续执行正常流程,若不存在则拒绝,禁止请求频繁访问缓存和数据库
- 布隆过滤器是一个bit数组,每一位非0即1,可以快速判断一个元素是否存在
- 存数据:根据k个不同的hash函数将数据映射到bit数组的k个位置上,将k个位置置1
- 判断数据:根据k个不同的hash函数将数据映射到bit数组的k个位置上,若k个位置有0,则该数据肯定不存在,拦截,若k个位置全为1,则该数据可能存在(hash可能冲突,所以存在误判),允许通过
- 优点:速度快,占用空间小
- 缺点:实现复杂,存在误判
三、缓存雪崩?
大量redis缓存中的key同时失效或过期,或者redis服务器宕机,大量请求直接到达数据库,给数据库造成巨大压力
解决方案1 随机TTL值
如果给大量key设置一样的TTL,就会在同一时间大量key同时失效,因此可以给不同的key添加分布较均匀的随机TTL
解决方案2 redis集群
宕机一个redis还有其他redis
解决方案3 服务熔断和降级
- redis宕机时暂停redis缓存服务(熔断),预防出现雪崩
- 若redis直接爆炸,只能降级服务,不理睬请求,直接返回错误
解决方案4 多级缓存
在多个层面建立缓存(比如浏览器、数据库等),一级缓存和二级缓存失效时间不同,一级缓存失效用二级缓存
四、缓存击穿?热点key问题?
部分热点key(被高并发访问且缓存重建业务较复杂的key)在缓存中失效或过期,如果第一次请求未命中,会去数据库查询并写入缓存,但若在此期间有大量同样的请求涌入,就会有大量请求涌到数据库要求查询,给数据库造成巨大压力
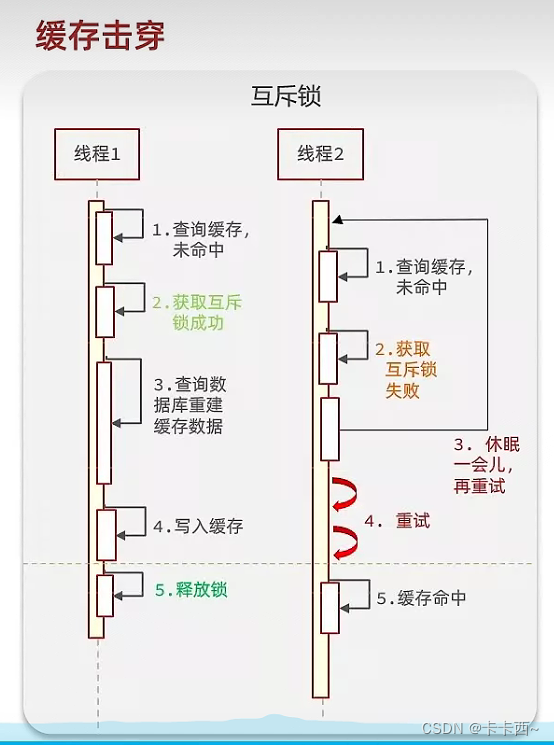
解决方案1 互斥锁
- 当线程1查询缓存未命中时,尝试获取锁,获取成功才能去数据库查询,写缓存后释放锁。在此期间,其他同样的请求查询缓存未命中时,同样尝试获取锁,但获取失败,就会等待一段时间重新尝试查询缓存并获取锁
- 优点:没有额外的内存消耗,数据一致性更好,实现简单
- 缺点:其他线程需要一直等待,直到获取到锁的线程写入缓存或释放锁,还有死锁风险
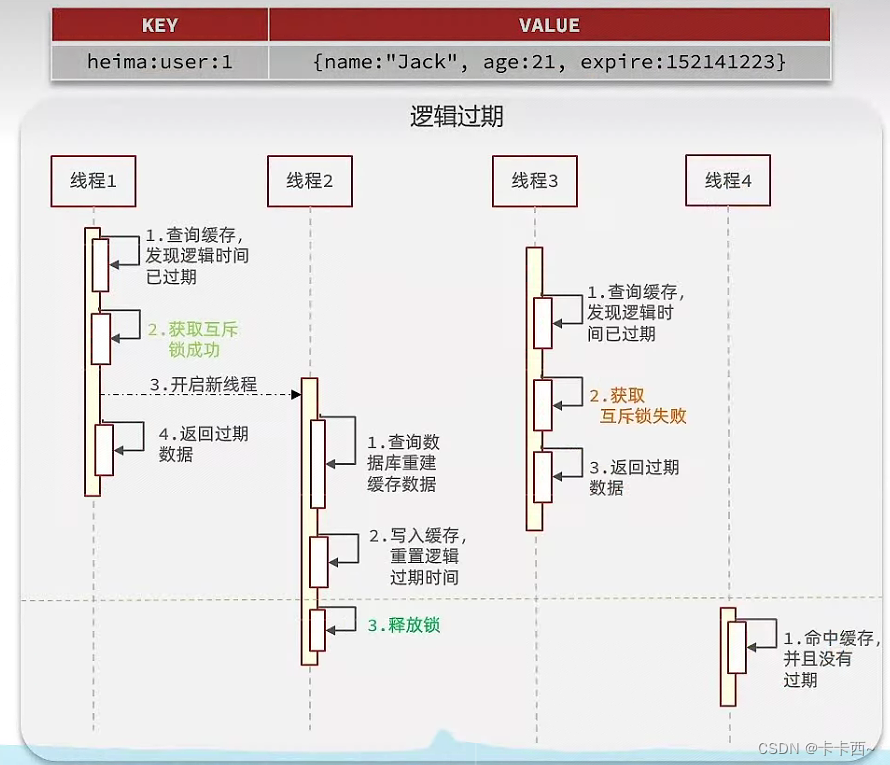
解决方案2 逻辑过期
- 不再设置TTL,而是设置一个逻辑过期时间,TTL相当于倒计时,逻辑过期时间相当于一个具体的时间
- 当线程1查询缓存时,发现该缓存的逻辑时间已经过期,便尝试获取互斥锁,并开启一个新线程2来进行查询数据库重建缓存,无需等待线程2执行完,直接返回一个过期的数据
- 线程3若紧跟线程1之后也来查询该缓存,发现逻辑时间已过期,也尝试获取互斥锁,但此时锁被线程2占用,获取失败,则直接放弃,返回过期数据
- 只有在释放锁之后到来的线程4才能命中缓存中没有过期的数据
- 优点:线程无需等待,性能较好
- 缺点:数据一致性较差,有额外的内存消耗,实现复杂