前言,有需要省市区的业务支持,网上大部分的地址库都是固定的,不会更新,所以通过Python爬取地址数据,进行分析,来获取每年最新的地址库,做此记录,记录学习python爬取数据的过程。
准备工作
实现逻辑
- 利用requests访问地址库,获取地址信息资源
- 根据地址信息页面标签拆分并分组数据
- 循环遍历已经获取的数据,进行所需数据的转换封装
- 链接数据库,进行数据插入
代码片段
- 所需引用
import requests # 请求的包
from bs4 import BeautifulSoup # 分析爬取的数据
import pymysql #数据库连接库
import time
- request网页请求方法
def get_response(self, url, attr):
headers = {
'Connection': 'close',
} # 封装请求头
response = requests.get(url, headers=headers) # 发送请求并获得返回
response.encoding = 'UTF-8' # 编码转换
soup = BeautifulSoup(response.text, 'html.parser') #分析数据
table = soup.find_all('tbody')[1].tbody.tbody.table
if attr:
trs = table.find_all('tr', attrs={
'class': attr})
else:
trs = table.find_all('tr')
return trs
request发送请求获取地址资源,BeautifulSoup对返回数据分析,并根据标签分析组装。
- 数据库连接并处理sql语句
def connect_mysql(self, sql, data):
cursor = self.db.cursor()
try:
result = None
if data:
if isinstance(data[0], list): #批量或单条执行
cursor.executemany(sql, data)
else:
cursor.execute(sql, data)
else:
cursor.execute(sql) # sql执行
result = cursor.fetchall()
except Exception as e:
print("sql execute error is "+e)
self.db.rollback();
finally:
cursor.close() # 关闭连接
self.db.commit(); # 提交操作
return result
连接数据库,并执行入参的sql(这里是插入语句和数据),进行数据操作,并关闭数据库连接
- 主方法 调用并处理数据
def main(self):
base_url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2021/'# 地址数据url
trs = self.get_response(base_url, 'provincetr') #获取返回值
for tr in trs: # 循环每一行
datas = []
for td in tr: # 循环每个省
province_name = td.a.get_text()
province_url = base_url + td.a.get('href')
print("省名:" + province_name)
trs = self.get_response(province_url, None)
for tr in trs[1:]: # 循环每个市
city_code = tr.find_all('td')[0].string
city_name = tr.find_all('td')[1].string
city_url = base_url + tr.find_all('td')[1].a.get('href')
trs = self.get_response(city_url, None)
for tr in trs[1:]: # 循环每个区
county_code = tr.find_all('td')[0].string
county_name = tr.find_all('td')[1].string
data = [province_name, city_code, city_name, county_code, county_name] #封装一条数据
print("省市区:" + data)
datas.append(data)#封装数组
time.sleep(1)
sql = "insert into china_address_library (province_name,city_code,city_name,county_code,county_name) values (%s,%s,%s,%s,%s)" #数据入库
self.connect_mysql(sql, datas) # 执行数据
获取模拟请求的返回,然后遍历返回体,对层级处理,封装成数据库的格式,然后做成数组,使用sql 调用数据插入方法。
- 数据展示
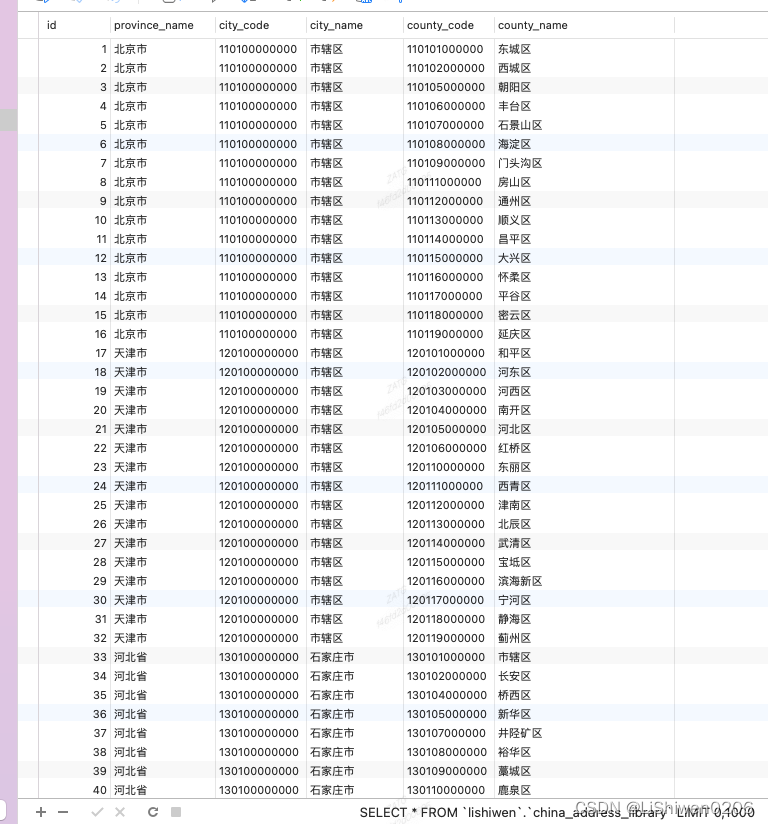
小结
整个处理还是比较清晰,一个很简单的爬虫逻辑,需要注意的是需要理清数据页面的标签结构,并深入获取更深层的数据,执行完sql也不要忘记关闭链接;就可以拿到自己想要的数据了。发挥你的想象,想爬啥爬啥去吧。