ResNet

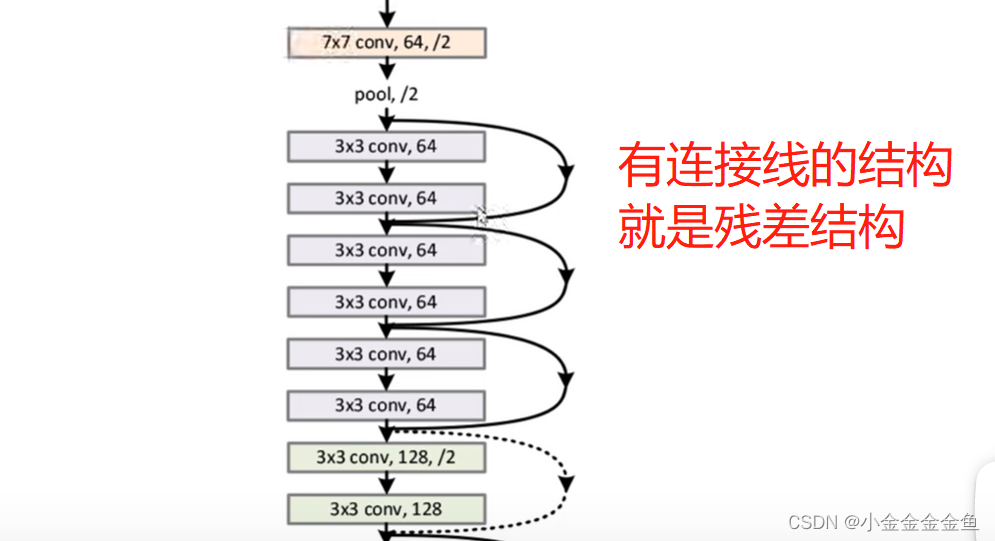
- 亮点:网络结构特别深
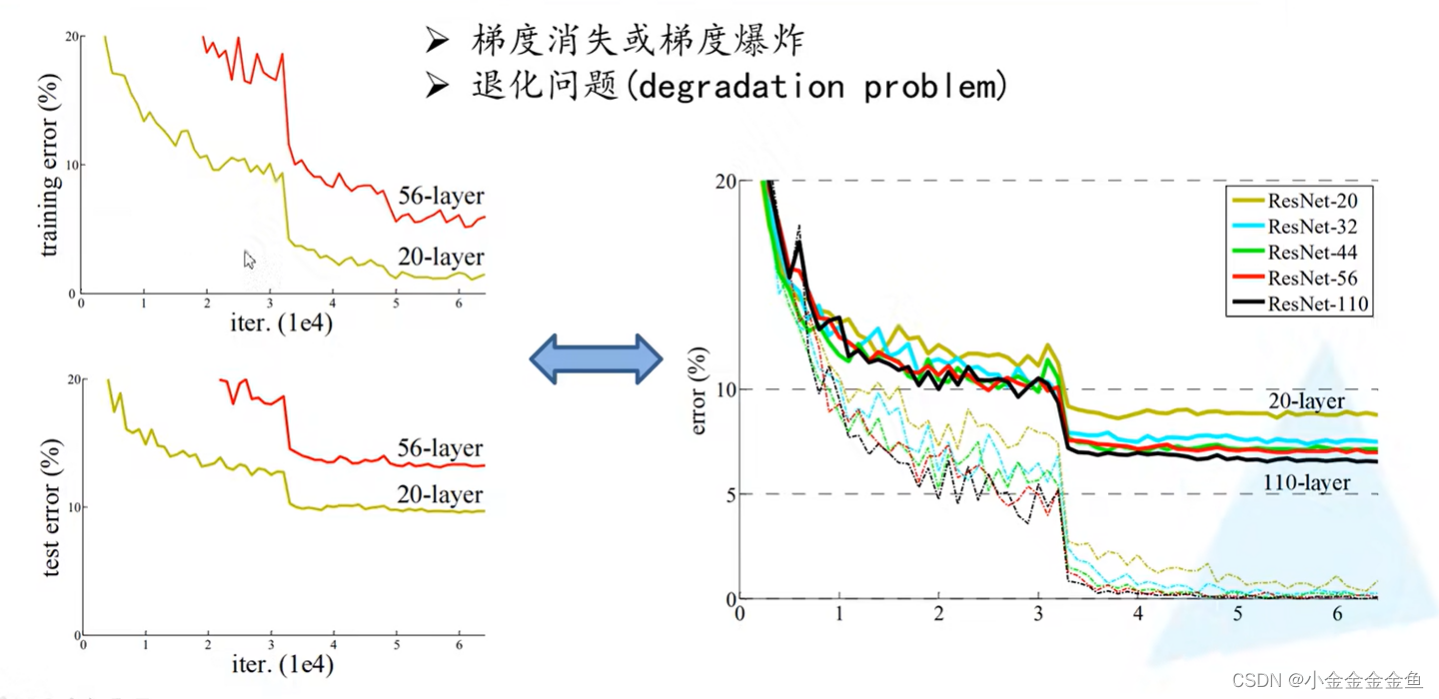
(突变点是因为学习率除0.1?)
梯度消失:假设每一层的误差梯度是一个小于1的数,则在反向传播过程中,每向前传播一层,都要乘以一个小于1的误差梯度。当网络越来越深的时候,相乘的这些小于1的系数越多,就越趋近于0,这样梯度就会越来越小。
梯度爆炸:反之,如果梯度是一个大于1的数,则在反向传播过程中,每经过一层都要乘一个大于1的数,随着层数不断加深,梯度会越来越大。
解决方法:对数据进行标准化处理,权重初始化,BN(Batch Normalization)处理。
但是在解决梯度消失、梯度爆炸之后仍然存在退化问题:层数深的网络效果仍然没有层数少的网络效果好。
解决退化问题:残差结构。
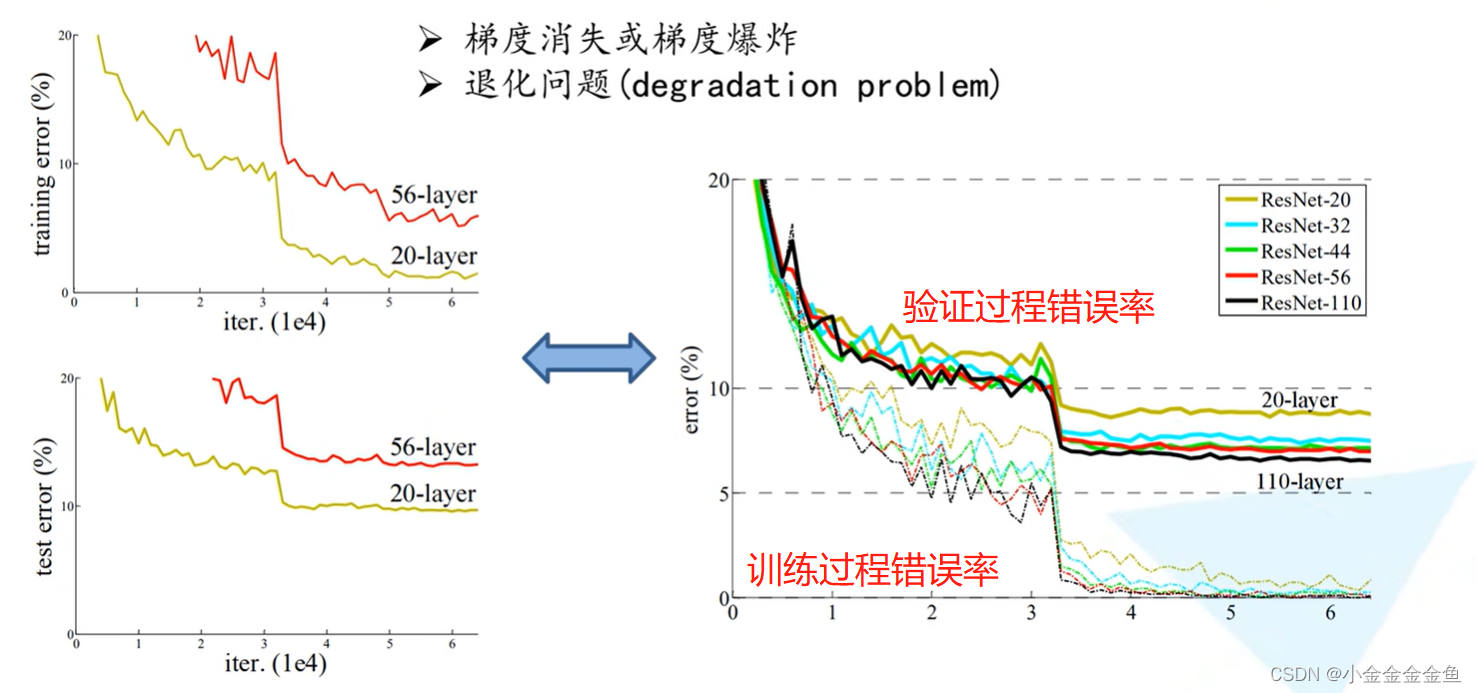
(???
有突变应该是前期冻结了网络主干进行训练
突变是迭代到一定次数,学习率会改变,一般是乘以0.1
)
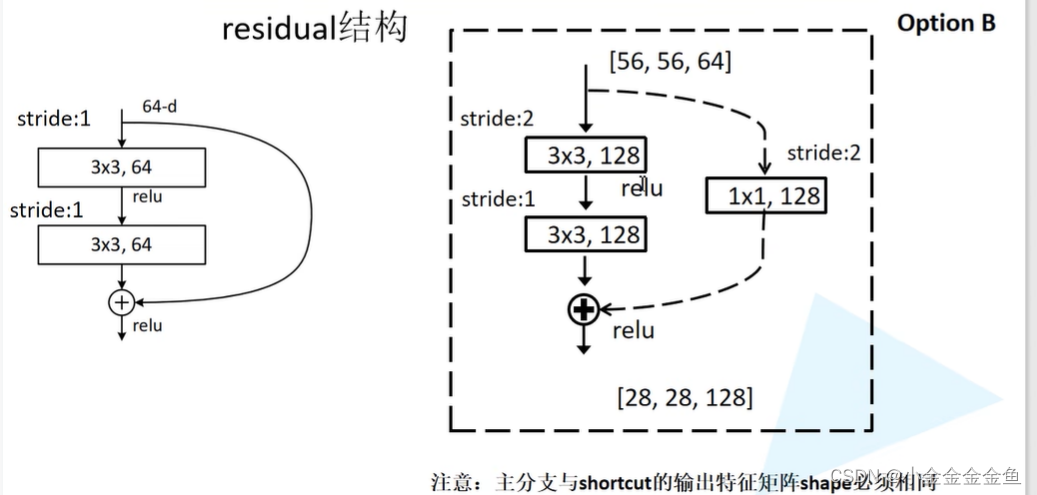
- 残差结构
左边:对网络层数较少的使用的残差结构
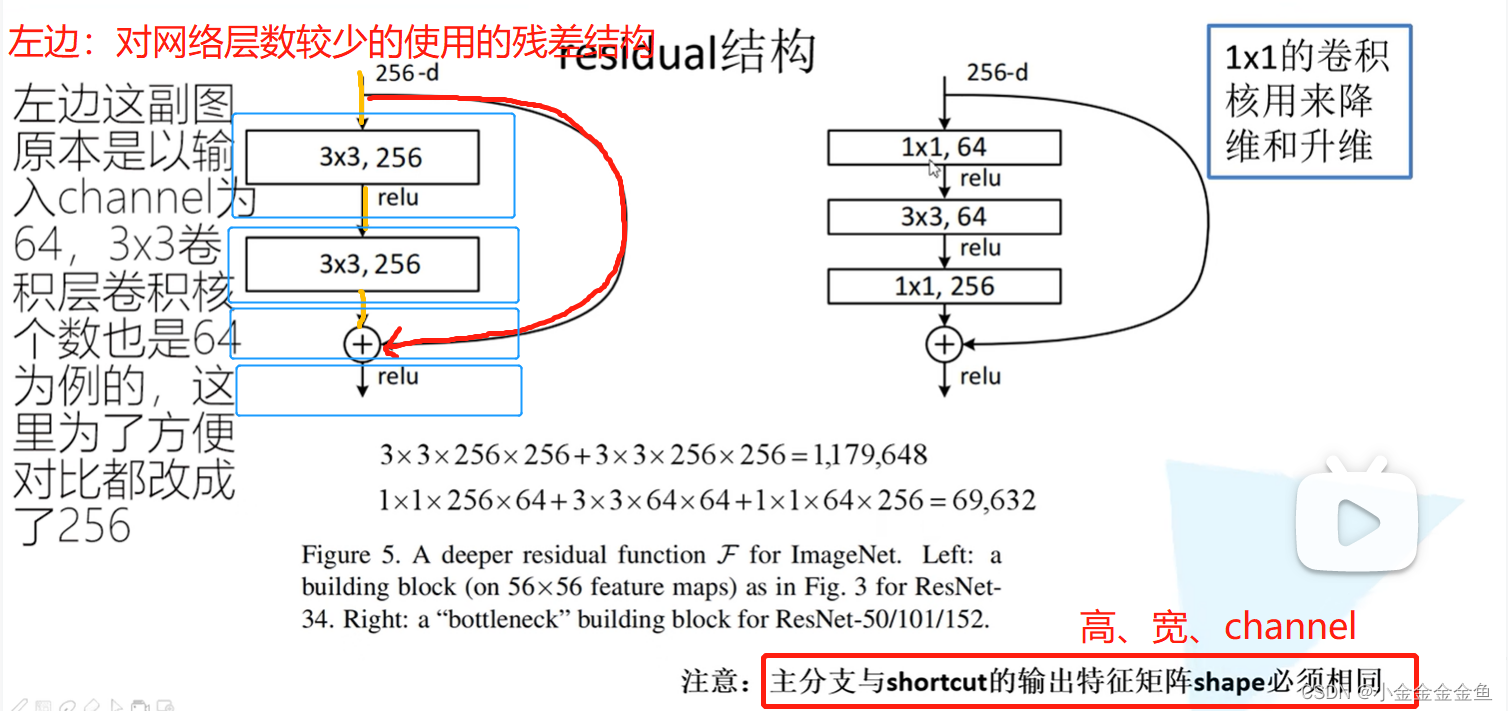
在主分支上经过一系列卷积层后得到的特征矩阵,再与输入特征矩阵进行相加(两个矩阵在相同维度的位置上加法运算(googlenet:深度方向拼接)),相加之后再通过relu函数。
右边:对网络层数较多的使用的残差结构
两个1x1的卷积层:输入矩阵深度(channel)为256,通过第一个1x1的卷积层后深度变为64(—>降维),……,通过第二个1x1的卷积层后深度变为256(—>升维)。
—> 这样原矩阵跟输出的矩阵宽度高度深度是一样的,即可相加。
左右两边所用到的参数对比:

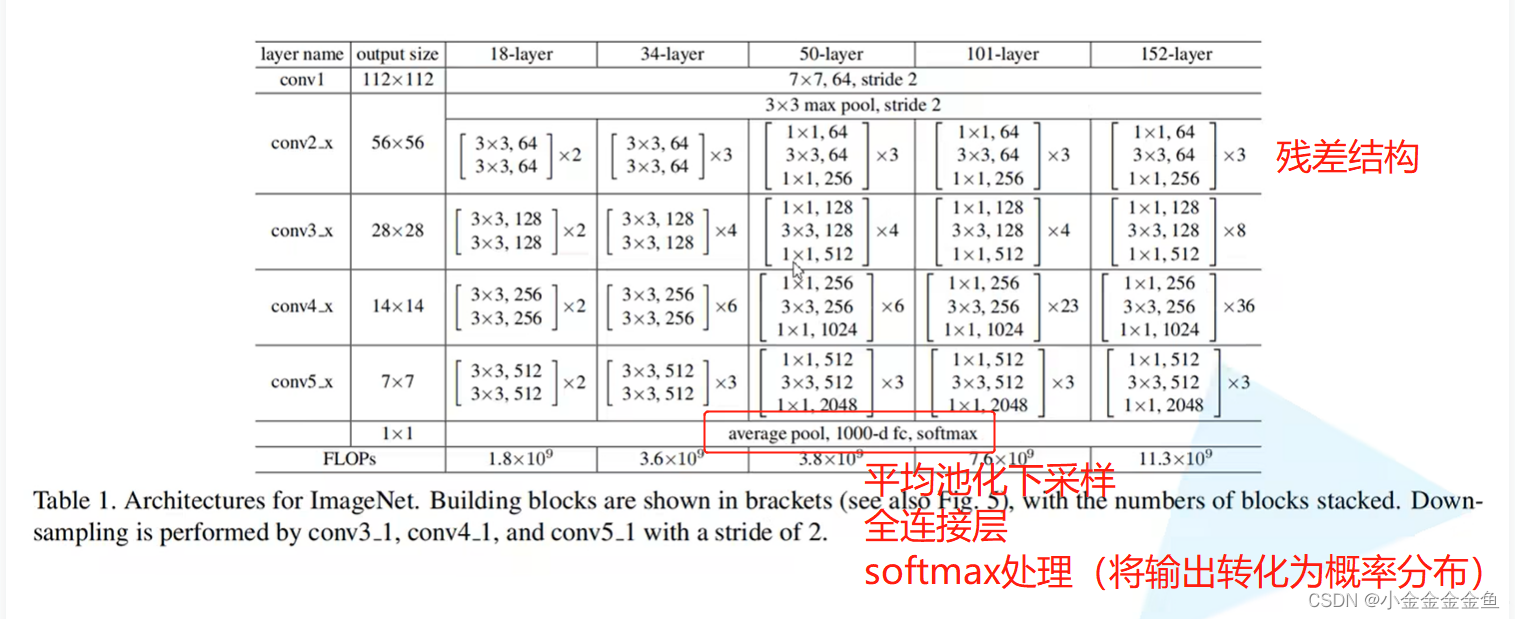
原文中的参数列表:
网络框架类似
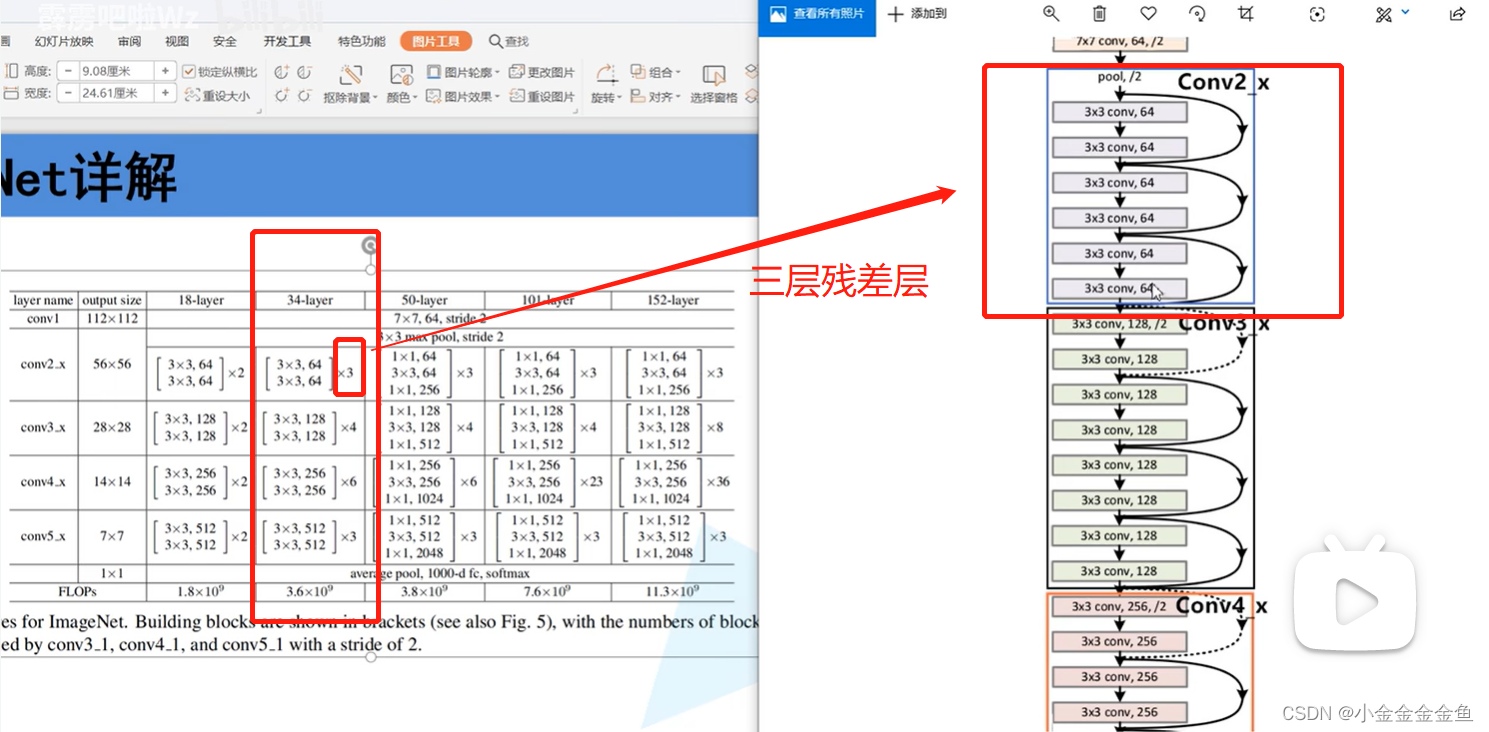
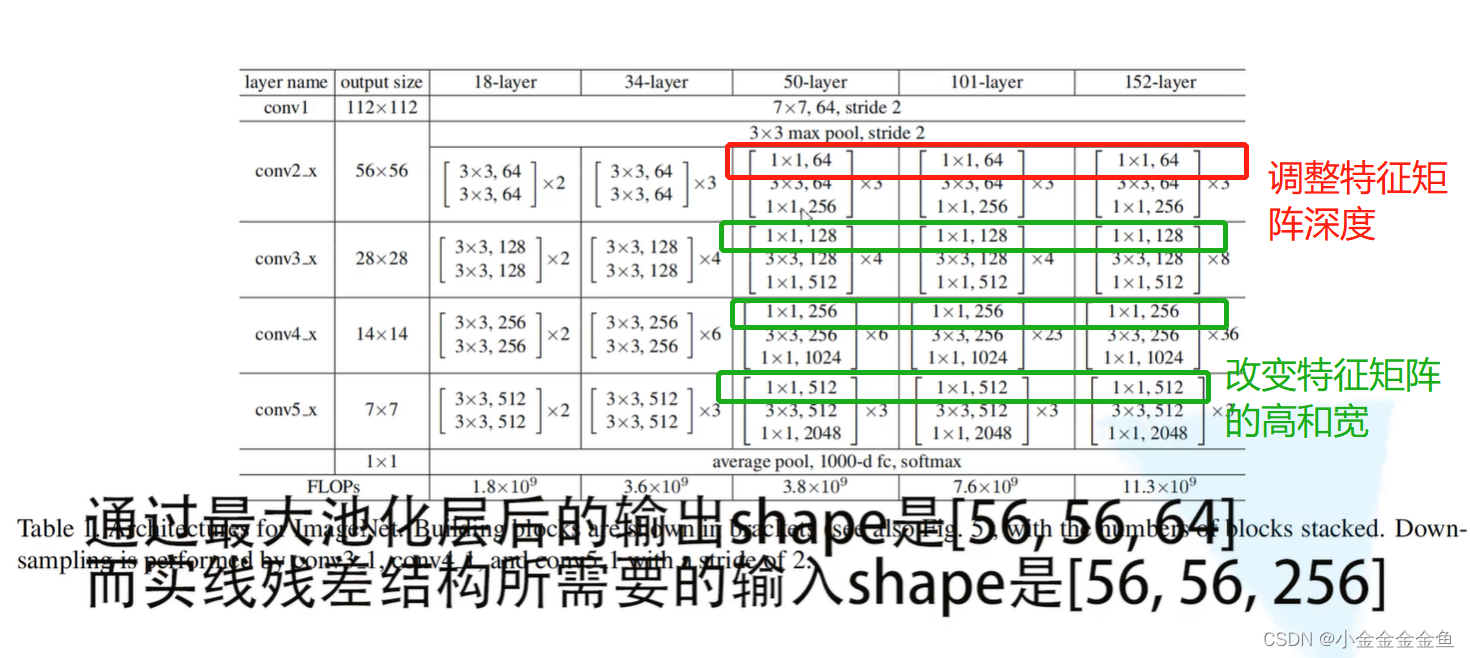
- 实线与虚线:
实线结构:输入和输出的特征矩阵形状shape一样,可以直接进行相加。
虚线结构:输入输出shape不一致,需要调整stride和kernel size。
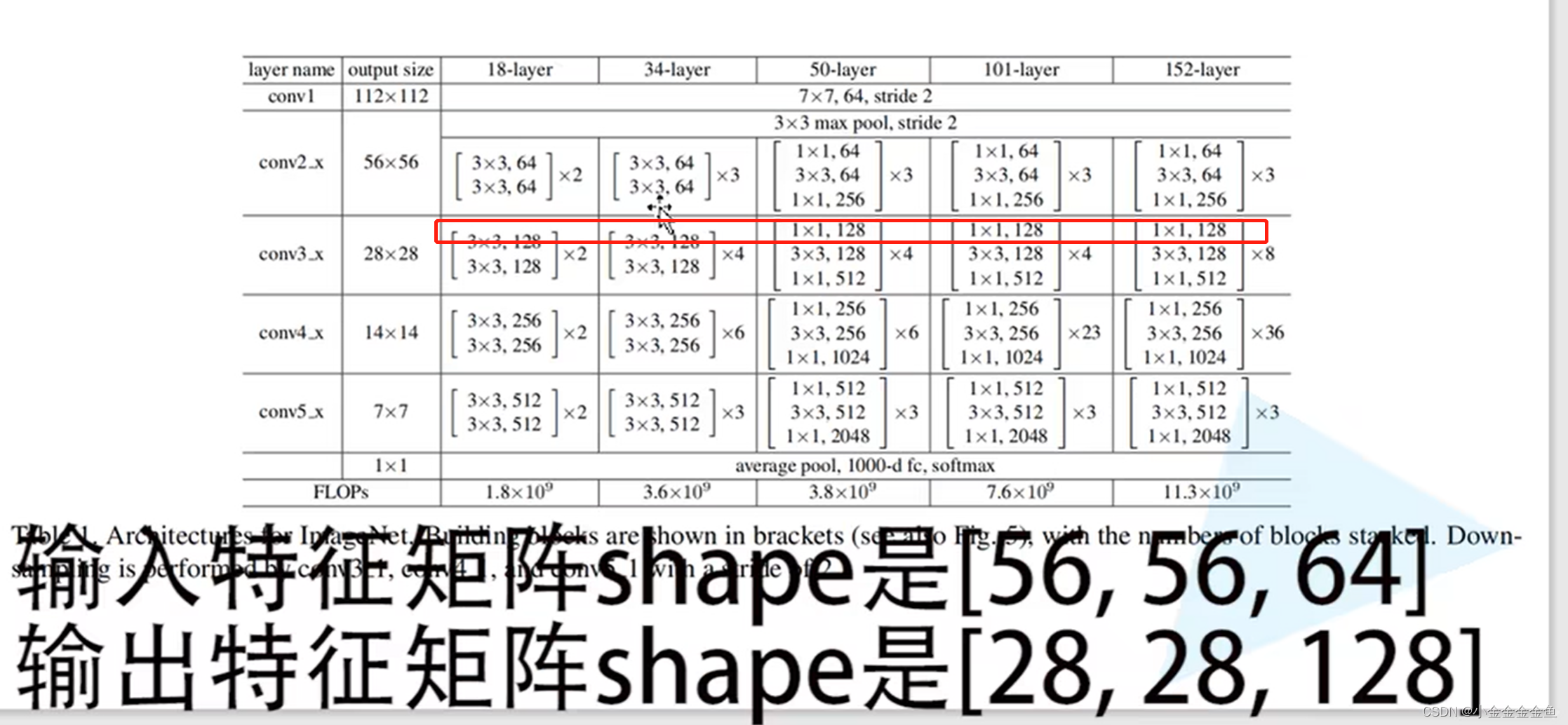

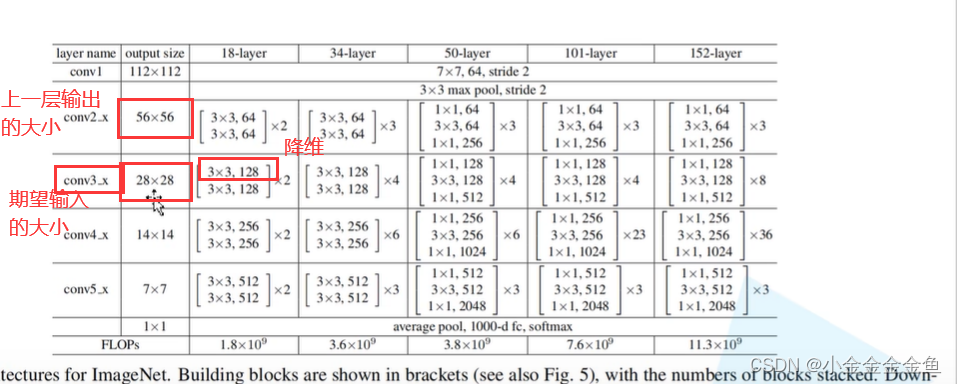
输入:56x56x64
输出:28x28x128
通过虚线残差结构得到输出后,再将输出输入到实线残差结构中,才能保证输入、输出特征矩阵的shape是一模一样的。
(
就算是虚线也不一样,有的层是高宽、通道数都调整,有的只调整深度。
)

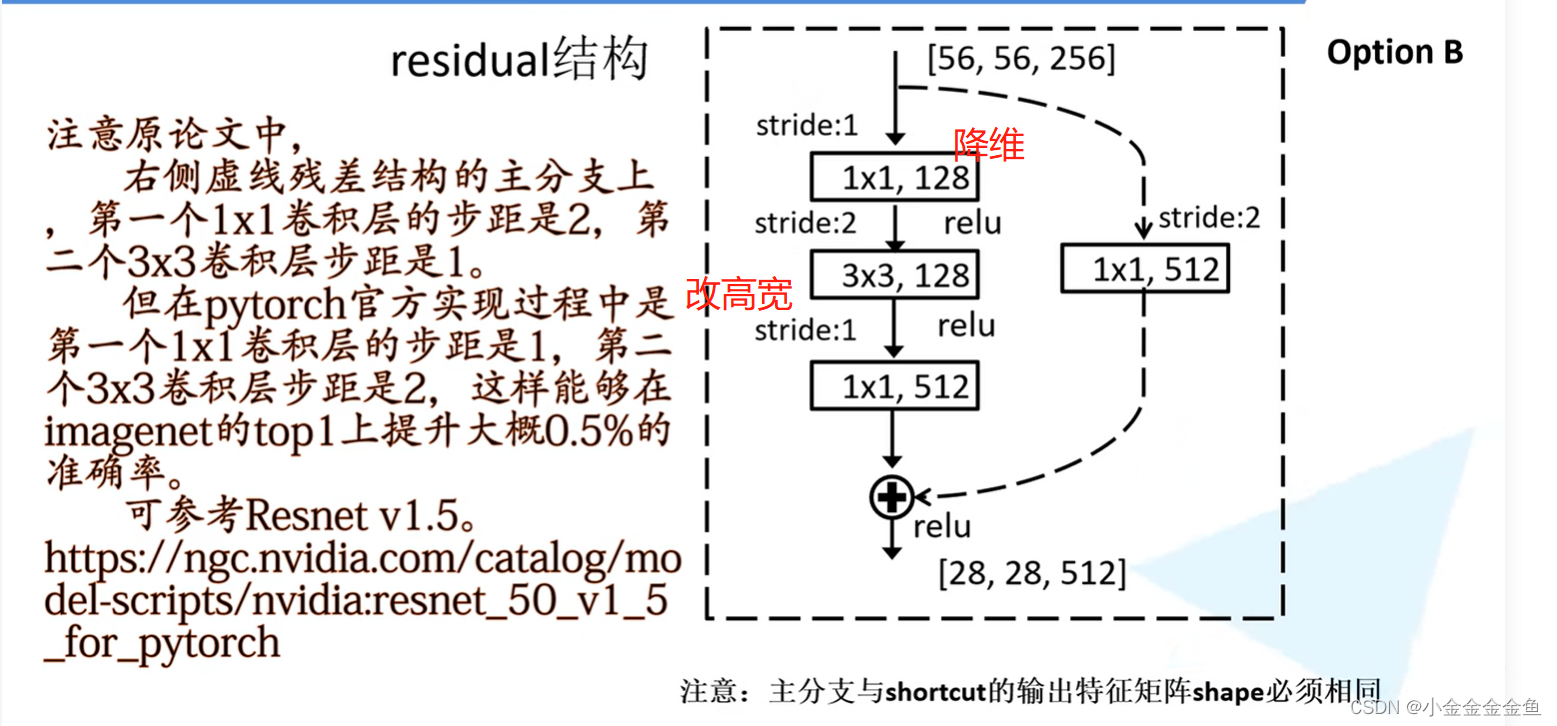
虚线残差结构有一个额外作用:将输入矩阵的高、宽、深度都进行变换。
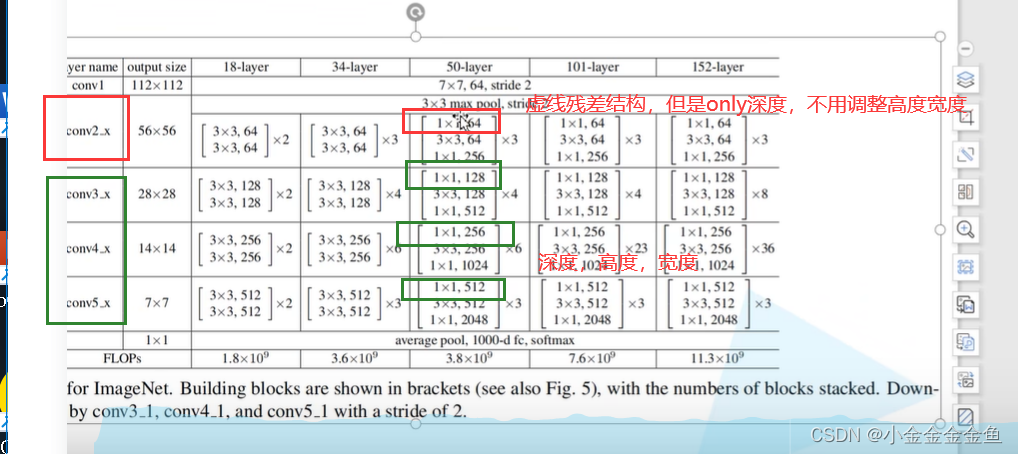
对于实线部分,它所输入的特征矩阵和输出的特征矩阵是一模一样的,所以在conv3_x、conv4_x、conv5_x对应的残差结构第一层都是指的虚线残差结构。因为第一层必须要将上一层的输出矩阵的高宽深度调整为当前层所需要的特征矩阵的高宽深度。
————————————————————————
对于18层和34层的网络而言,通过池化层后所得到的特征矩阵就是56x56x64,而残差结构所需要的刚好也是这个shape。所以对这种浅层网络而言,不需要在第一层使用虚线的残差结构的。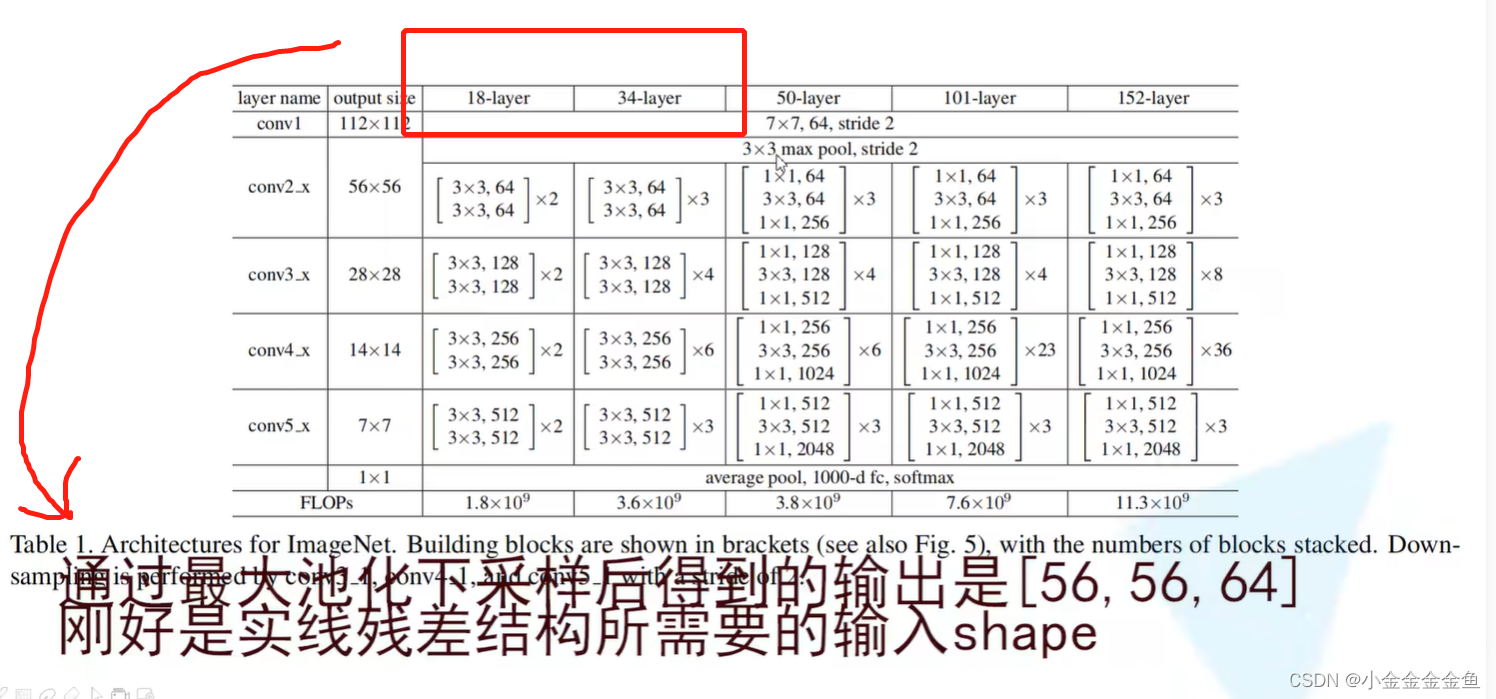
但是对50层、101层、152层这样的深层结构而言,通过最大池化下采样后,所得到的特征矩阵深度是56x56x64,但是所期望的输入特征矩阵是 56x56x256。
BN

目的:
①使一批(batch)数据所对应的feature map(特征矩阵)每个channel所对应的维度满足均值为0、方差为1的分布规律。
②加速网络的训练,提升准确率。
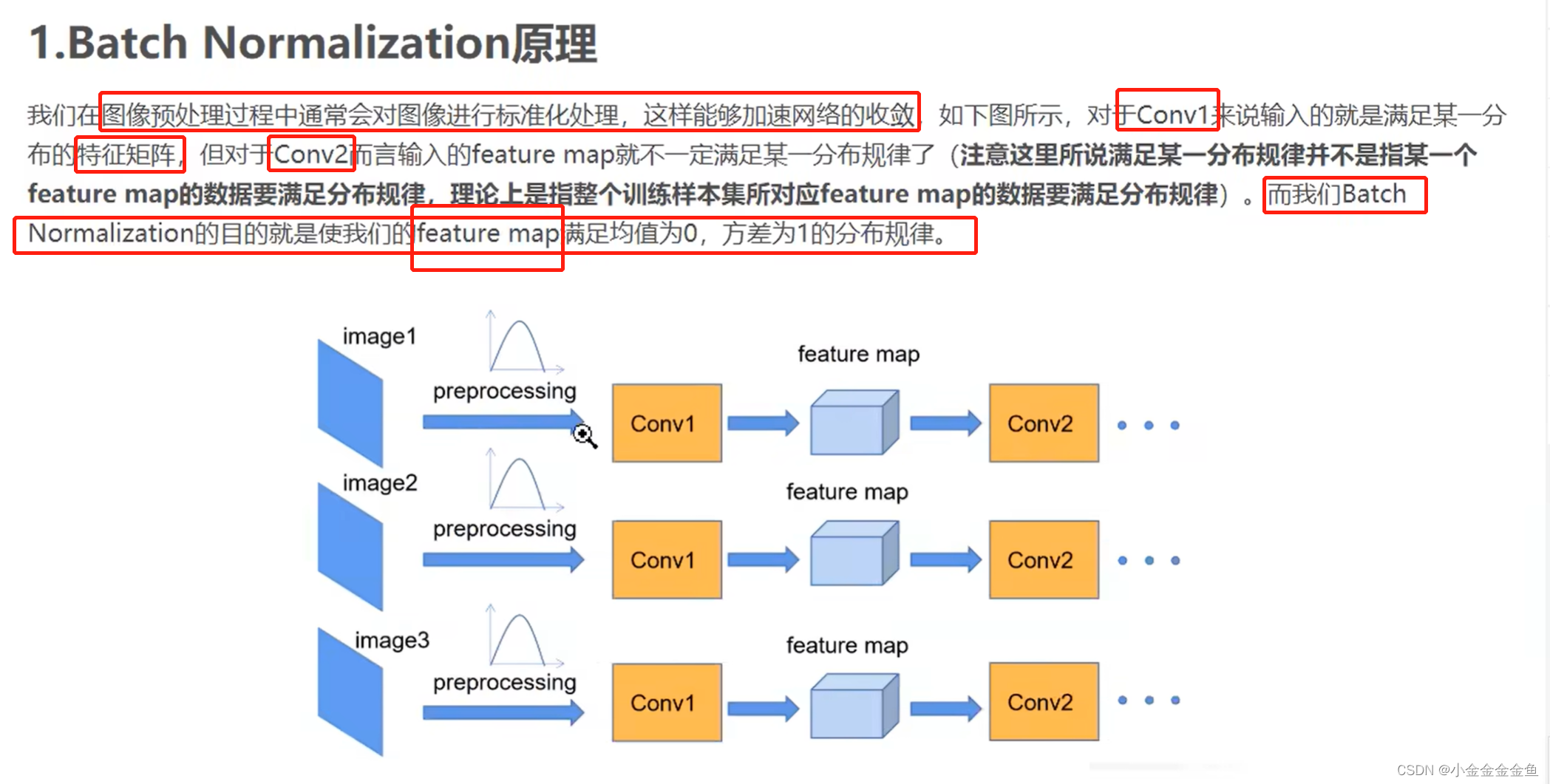
调整feature map,让每一层的feature map都能满足均值为0、方差为1的分布规律。
调整的是输入的一批数据的feature map的每一层的分布,并不是单独去调整某一个图像的feature map所对应的每一层的的分布。

假设batch size设置为2,输入两张图片之后所得到的特征矩阵:feature1、feature2。
对这两个特征矩阵进行BN处理:
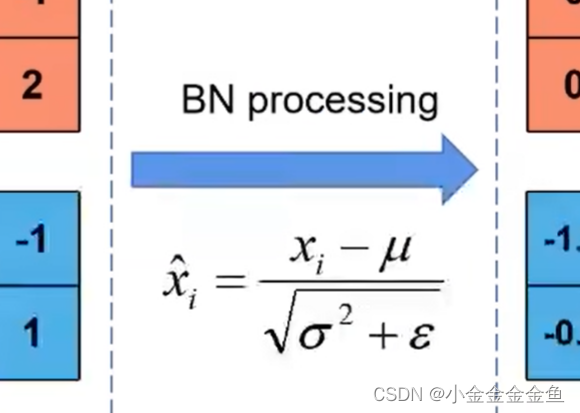
①计算均值和方差。
对channel1:计算整个batch中channel为1的均值和方差。

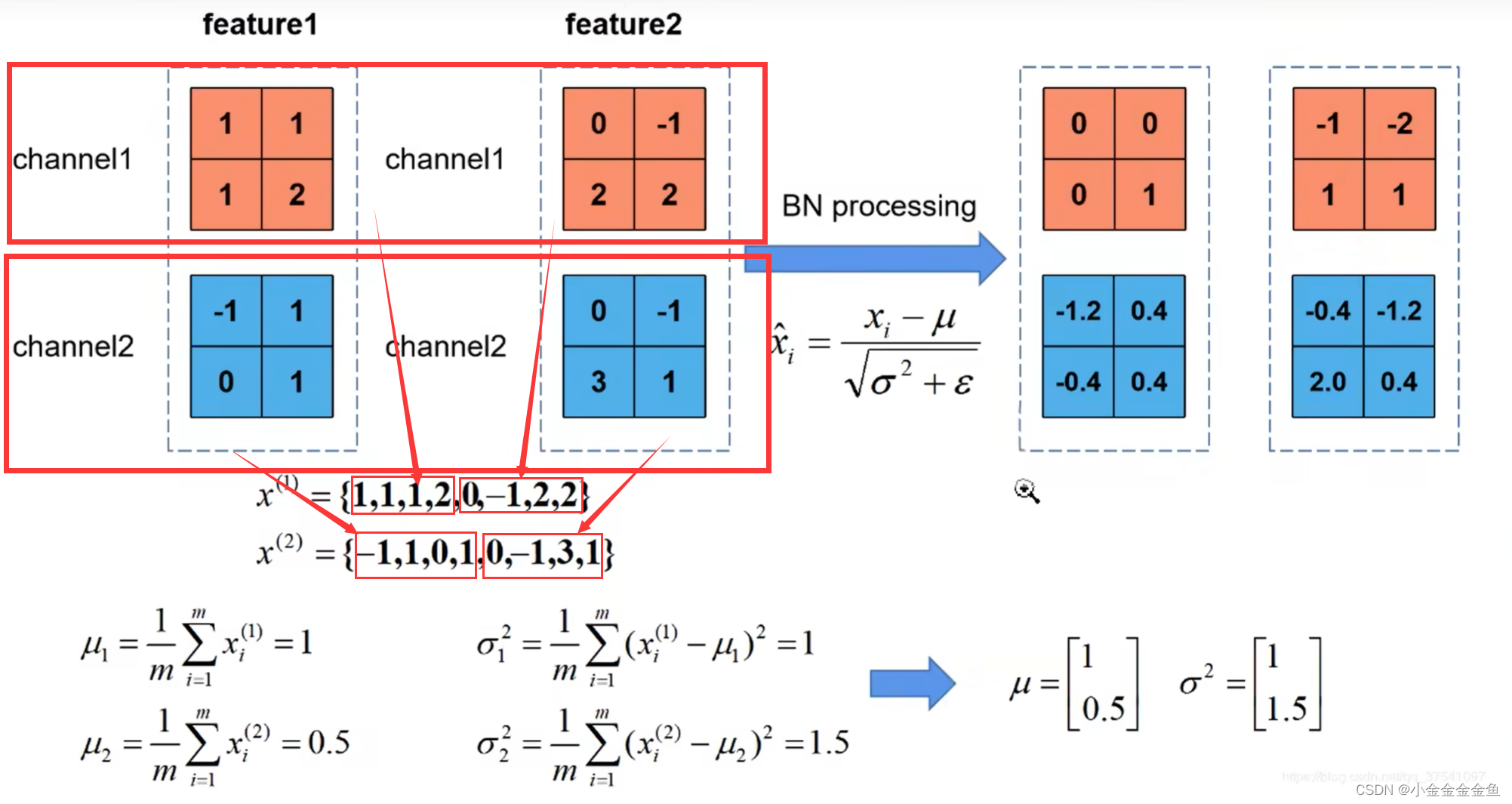
通过求均值、求方差的公式,分别求得均值和方差(都是向量,维度与深度对应)

再通过论文所给的公式计算,就能得到通过BN之后所得到的特征矩阵的值。
使用BN时需要注意的一些问题

1、因为在训练中是要不断统计均值和方差,在验证过程或者预测过程中,使用的是历史统计的方差, 不是使用当前计算的均值和方差。

迁移学习
1、大大减少训练时间。
2、若网络特别大(对应参数多),而数据集又特别小,不足以训练整个网络。—> 出现过拟合。
(
过拟合:数据太少,模型无法充分训练,容易过度拟合的符合少量训练数据的特征
)
**使用别人预训练好的模型参数,一定要注意别人预处理的方式。**改成跟别人一样的与处理方式。
迁移学习简介:
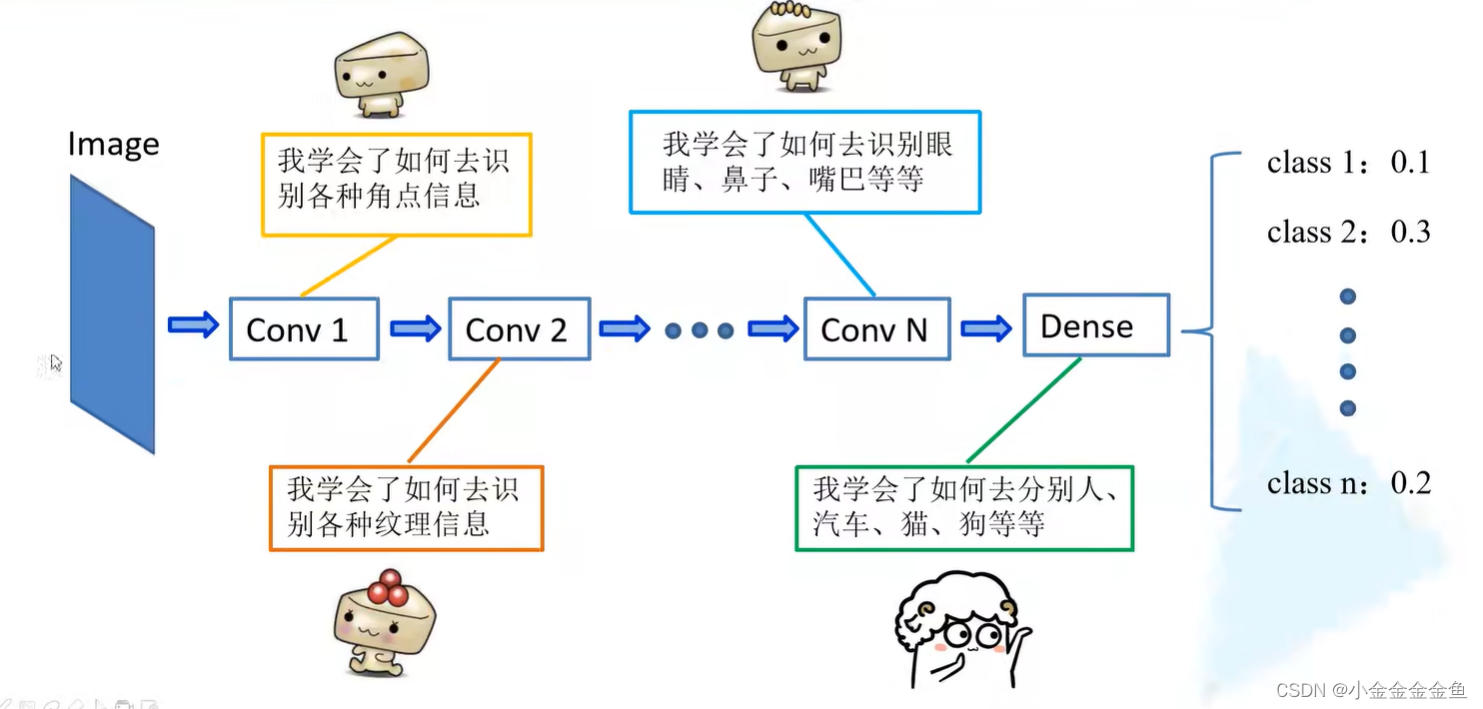
比较通用的信息,在本网络中适用,在其他网络中也适用。
将浅层网络中的一些参数迁移到新的网络中来,则新网络也有了识别底层特征的能力。则新网络可以更加快速地学习数据集的高维特征。
常见的迁移学习方式:

1、载入权重后训练所有的参数。
使用别人预训练好的模型参数,全部载入进来后,针对我们的数据集,去训练所有层的网络参数。
注意最后一层全连接层(途中以VGG为例),要将这一层的全连接节点个数改成我们网络所对应的分类个数。

2、载入后只训练最后几层的参数。
如:固定全连接层之前的所有模型参数,只训练最后的三层全连接层。这样参数会变少,训练速度会变快。
3、载入权重后在原网络的基础上再添加一层新的全连接层,仅训练最后以恶全连接层。这样就可以载入所有的模型参数。
新的全连接层的节点个数就是训练集的分类个数。
在很短时间内得到一个比较理想的结果:2、3都行
硬件参数不受限,想要得到一个最优的结果:1
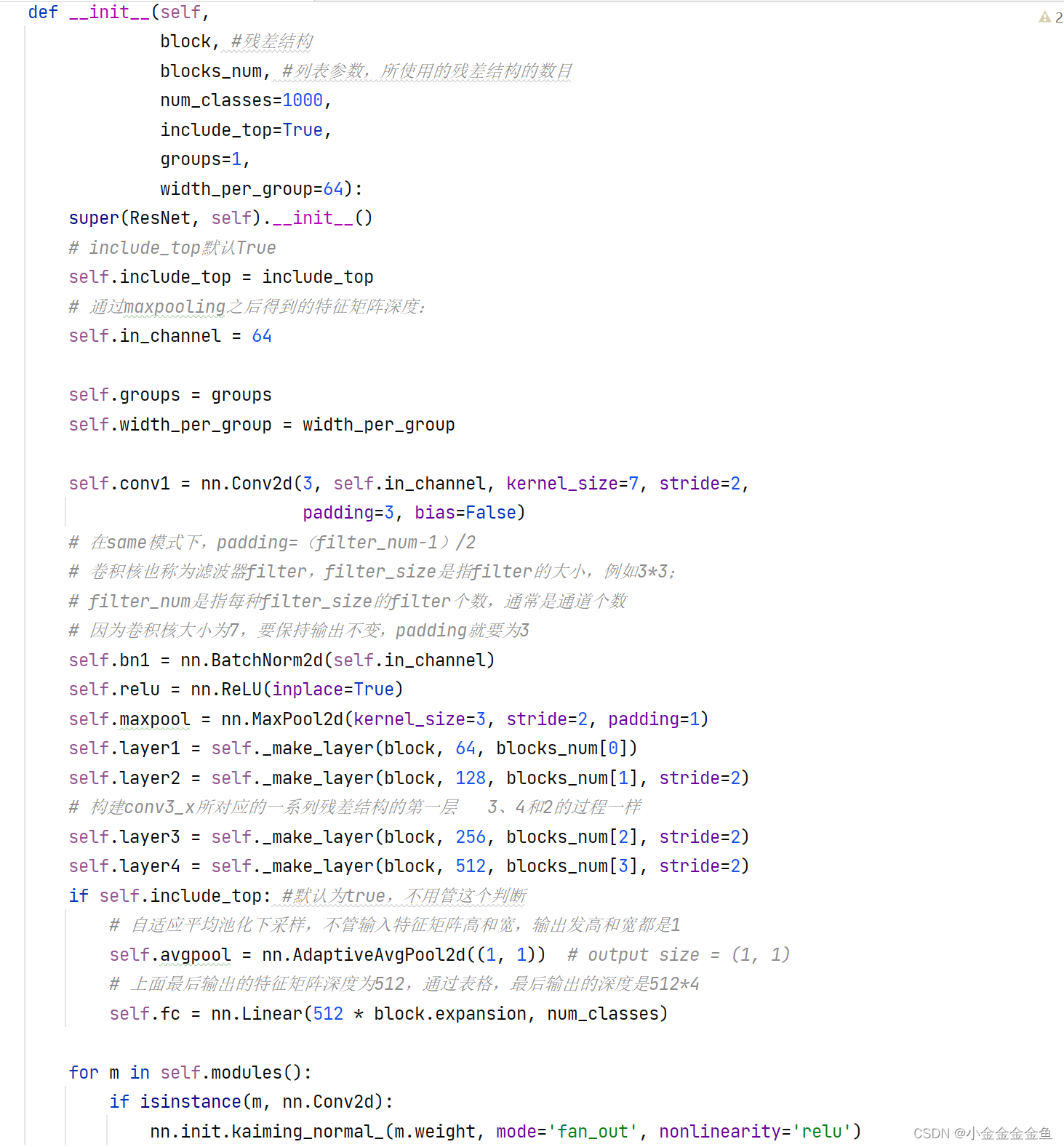
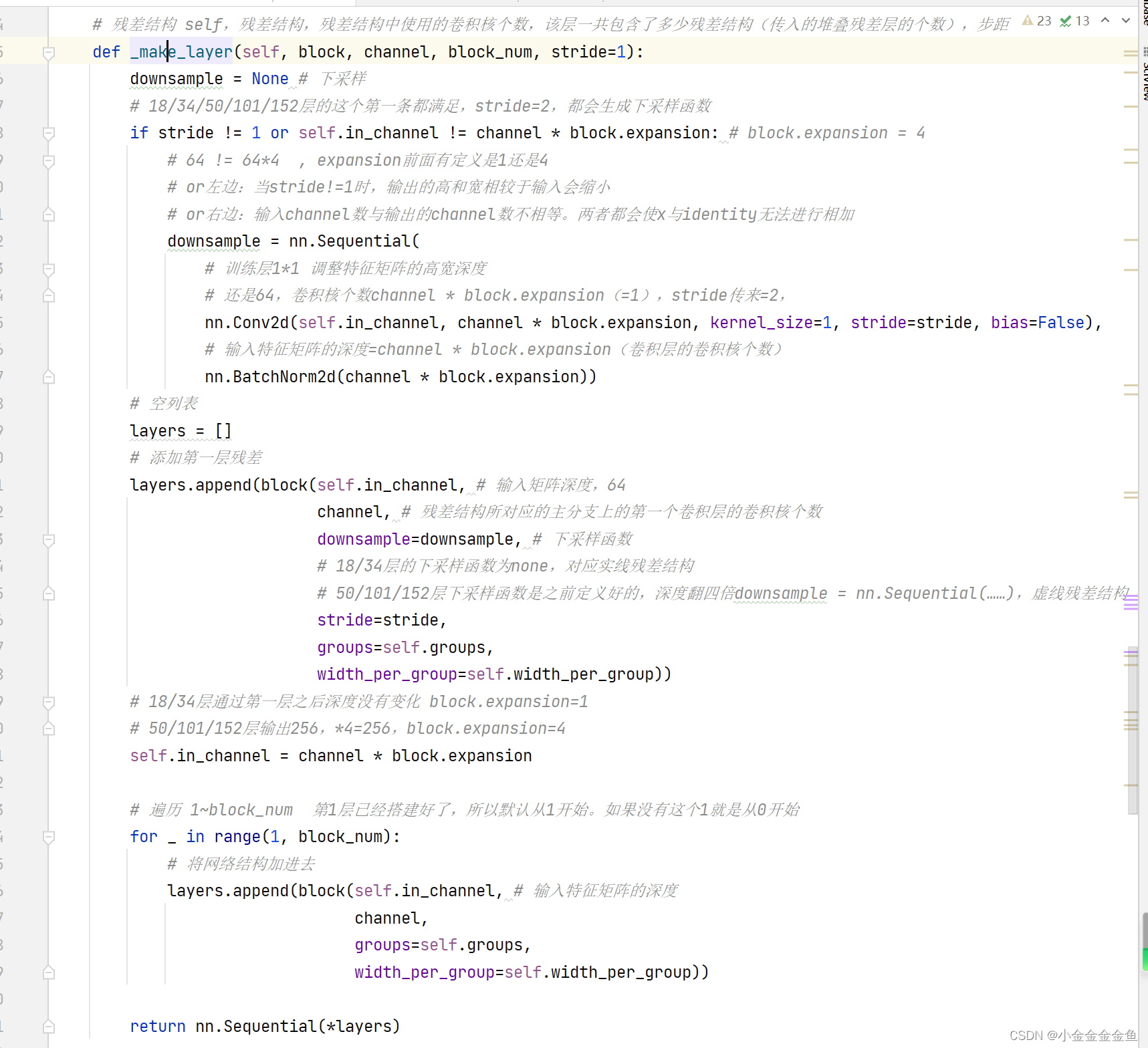
pytorch搭建ResNet
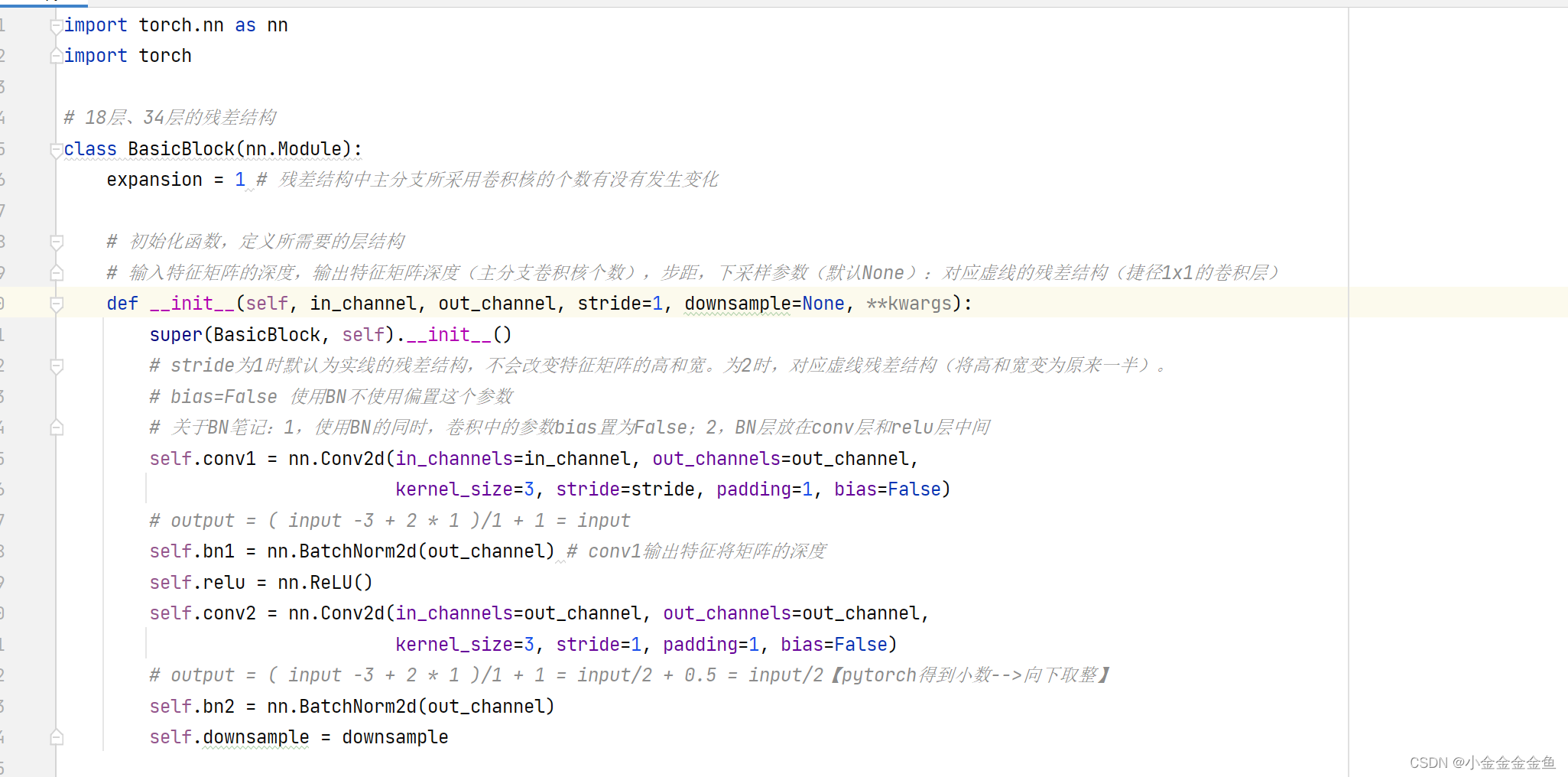
搭建针对18层、34层的残差结构
conv3_x、conv4_x、conv5_x对应的残差结构第一层都是指的虚线残差结构。每一层的第一个残差结构有降维的作用。
BasicBlock既要有实线的残差结构,又要有虚线的残差结构功能。
(
下采样:图像高宽变小。上采样:图像高宽变大。
)

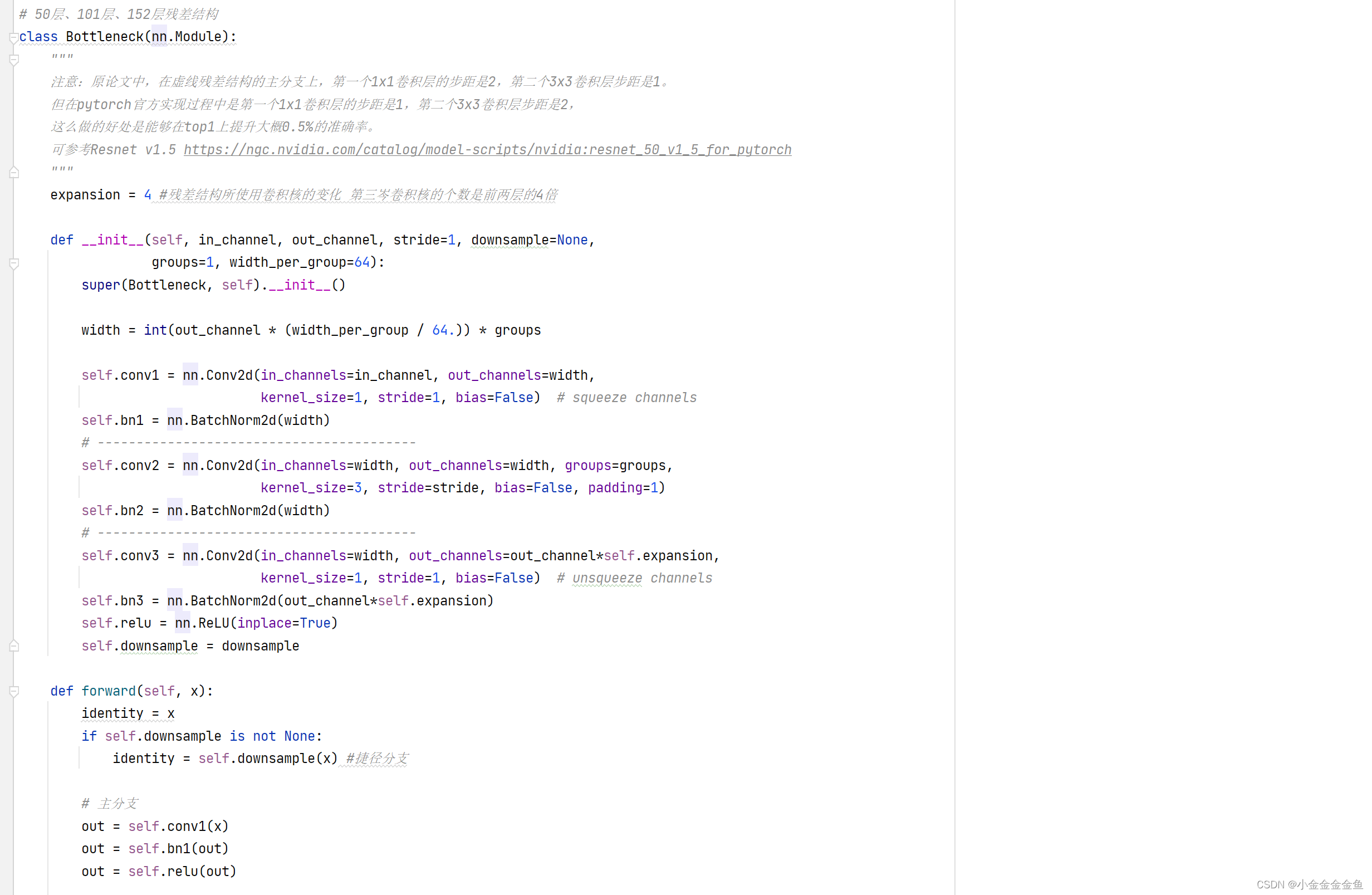
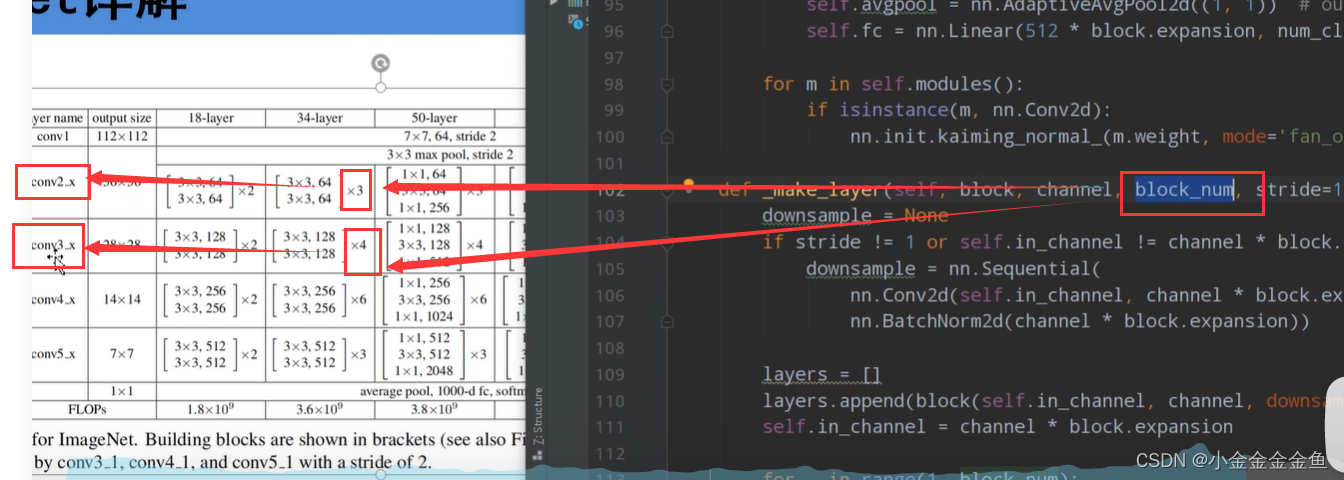
搭建针对50层、101层、152层残差结构。
4倍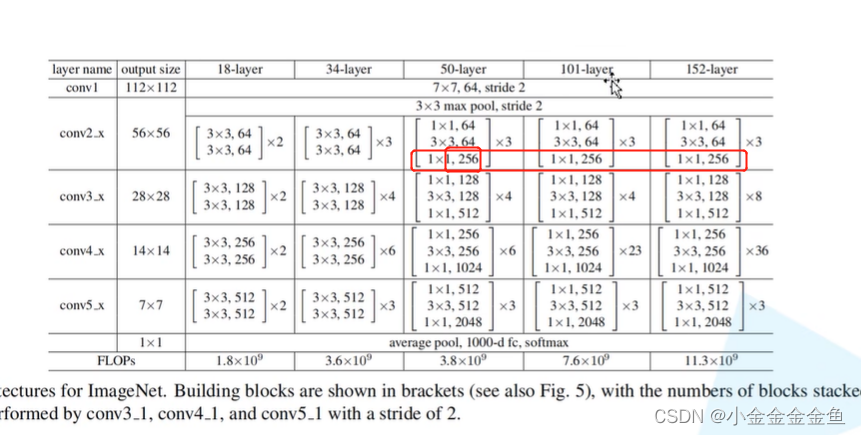

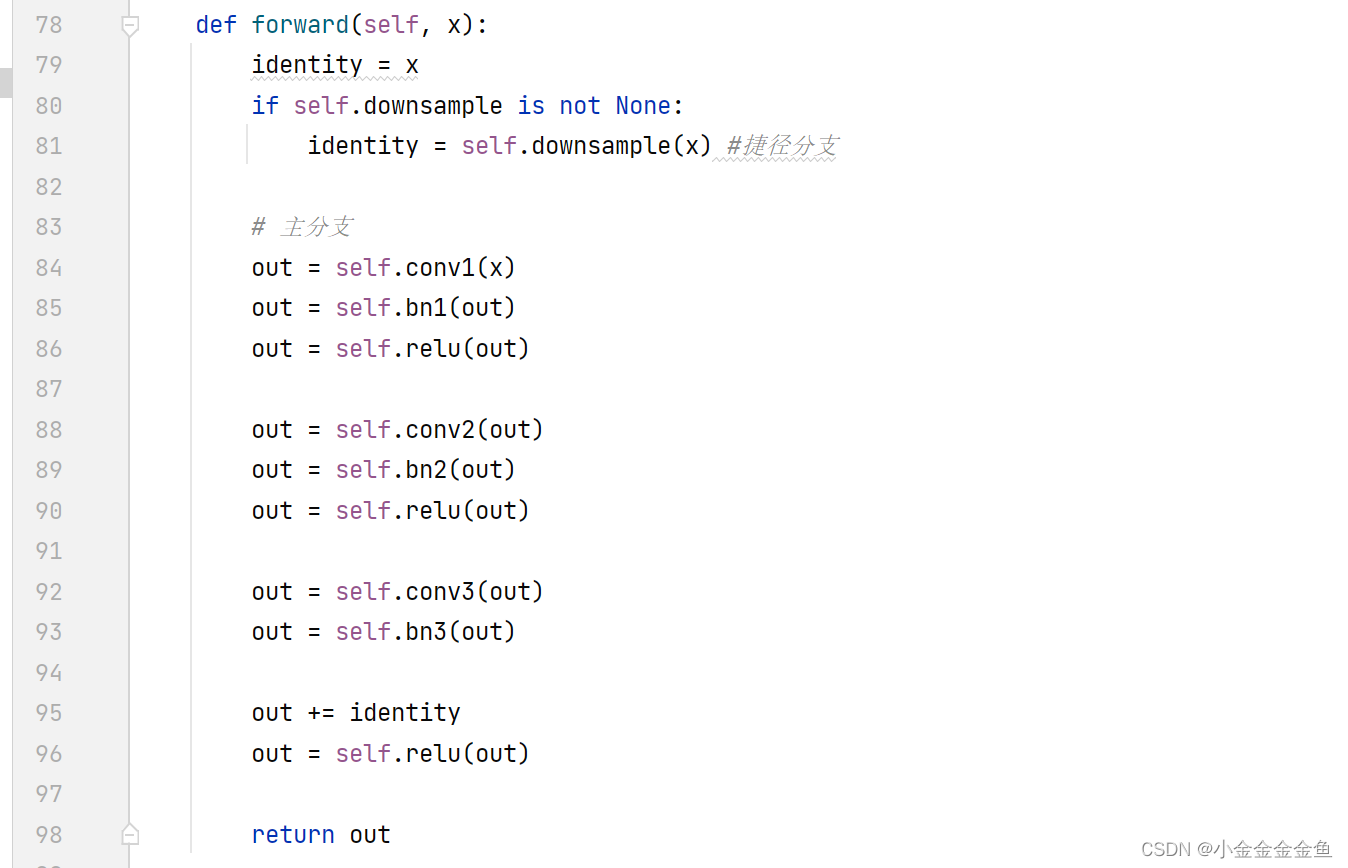
blocks_num


resnet结构


train
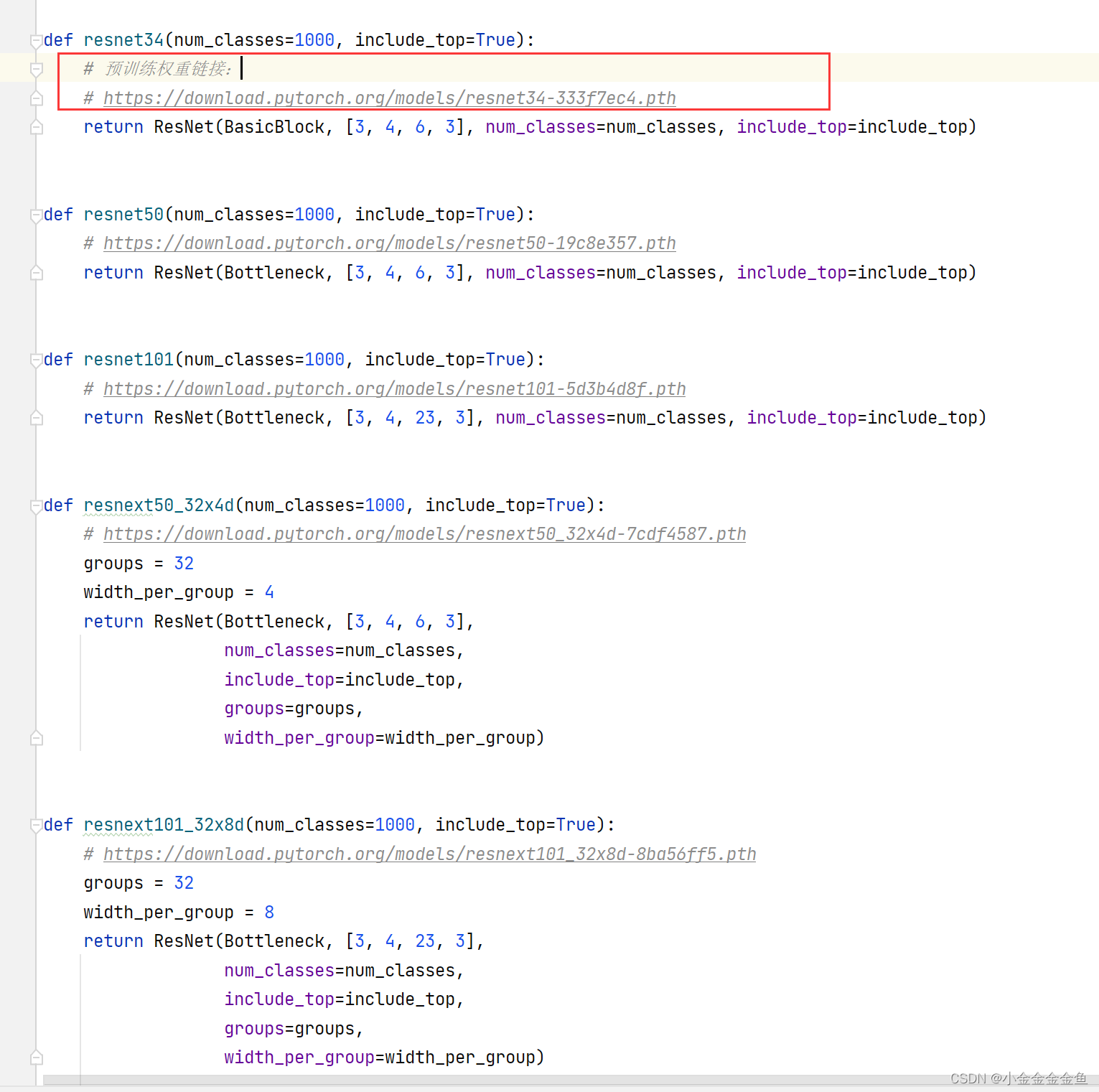
(以34层的为例)
可以把预训练权重的链接复制到迅雷里面下载
放到项目中
训练脚本的大部分代码与之前的AlexNet、VGG……相同,有一些不一样的地方是:
1、训练集:在对图像进行标准化处理的时候,这里的标准化参数都是来自官网所提供的一个教程中,照搬参数。

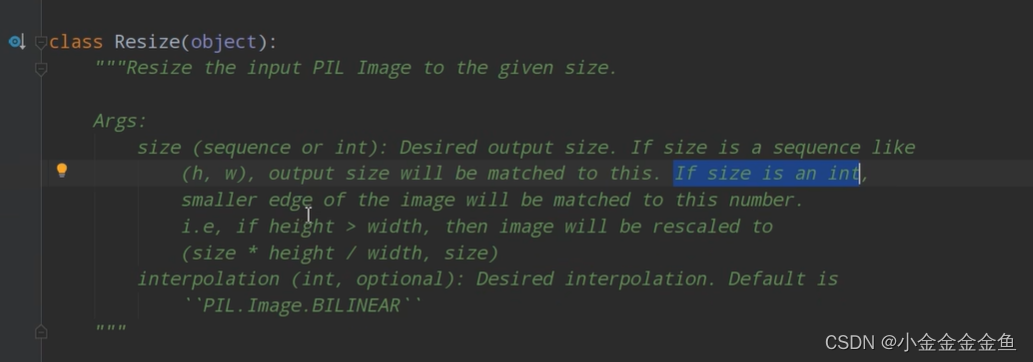
验证集:之前都是把图片resize到224224。
这里:将最小边缩放到256(原图片长宽比对应不动)、
中心裁剪,裁剪出一个224224大小的图片
(如果采用迁移学习,必须跟人家的与处理方式一样,不然训练效果很差。不能直接resize 224)
2、linux将这个线程个数设置成>0的数,加速图像预处理过程
(windows一定记得将num_workers设置为0)

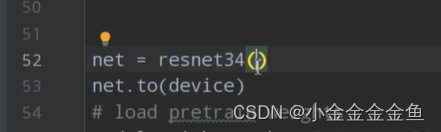
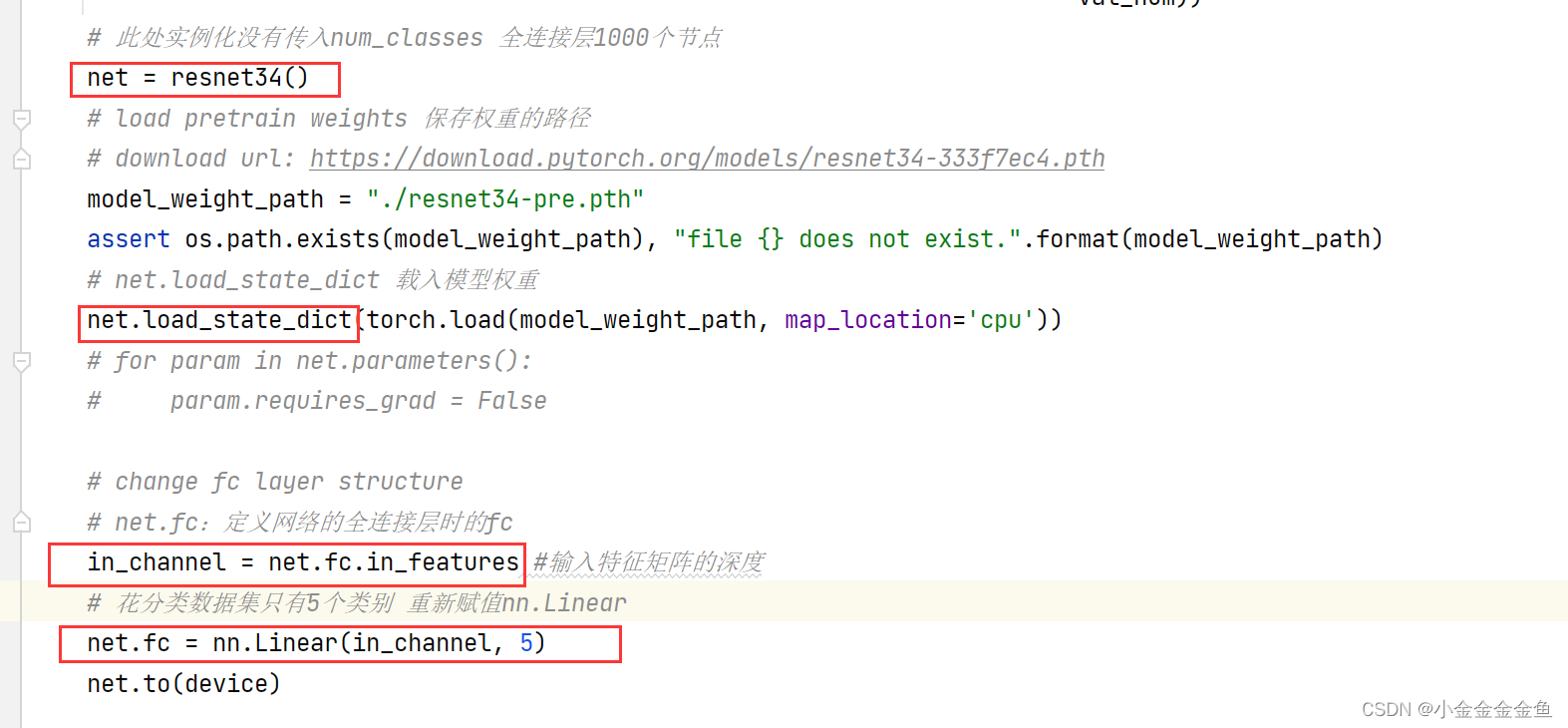
3、此处实例化没有传入num_classes


predict 预测脚本
1、采用和训练方法一样的标准化处理,所以这里的参数与训练中使用的一样。

2、传入num_classes=5
